
gpu 없이, 또는 gpu 사양이 좋지 않더라도 로컬에서 LLM을 돌려볼 수 있는 방법을 알아보자.
LLama.cpp란?

opensource LLM 모델들을 순수 C/C++로 추론 가능하게 하는 라이브러리다. LLama.cpp에서는 양자화 및 CPU 최적화 기술(멀티 쓰레딩, 캐시 최적화 등)등을 활용하여 로컬 환경에서 고성능 GPU 없이도 효율적인 추론을 가능하게 한다.
gguf 란?
GGUF(GGML Unified Format/GPT-Generated Unified Format)는 LLM에 최적화된 바이너리 파일 형식으로, 모델의 효율적인 저장/로드/실행을 목적으로 설계되었다.

GGUF 파일 형식은 (1)파일 헤더, (2)메타데이터 블록, (3)텐서 정보 블록으로 구성되어 있다
- (1)에서는 gguf파일을 식별하는 매직 넘버, gguf 포맷의 버전 등을 포함
- (2)에서는 모델명, 아키텍쳐, 문맥 길이, 토크나이저 정보 등을 포함
- (3)에서는 각 텐서에 대한 정보를 포함 (텐서 이름, 차원, 크기, 유형 등)
gguf 포맷은 주로 Llama.cpp, ollama등과 같은 LLM 추론 엔진에서 사용된다.
GGUF vs Safetensor
gguf의 경우에는 단일 파일과 단순한 구조로,로컬 추론 특화 장점이 있으나, 확장성이나 범용성 부분에서 safetensor보다 떨어진다.
safetensor는 로드 속도가 빠르고 보안성이 좋으며, 범용적인 포맷으로 모델 저장 및 공유, pytorch 기반 워크플로우 통합 및 LLM 플랫폼 개발에 용이하다.
llama.cpp에서 gguf 모델 사용해보기
[github] llama.cpp
llama.cpp에서는 기본적으로 빌드하면 cpu만 사용하지만 cuda 컴파일하여 gpu 사용도 가능하다.
# llama.cpp build (cpu only)
git clone https://github.com/ggml-org/llama.cpp.git
mkdir build && cd build
cmake ..
cmake --build . --config Release
make -j$(nproc)
# llama.cpp build (llama-cli only)
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
cmake -B build -DLLAMA_CURL=ON # CURL 지원 활성화 (온라인 모델 다운로드)
cmake --build build -j --target llama-cli# llama.cpp build (cuda compilation)
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release자세한 빌드 방식은 깃허브 참조 (build-llama-cpp)
gpu 메모리 사용량을 확인해 보면 기본 cpu build만 했을 때는 gpu를 사용하지 않지만, cuda compilation으로 빌드하면 llama.cpp 실행 시 gpu도 사용하게 된다.
llama.cpp client 실행
# llama-cli에서 프롬프트 실행
cd ~/llama.cpp
./build/bin/llama-cli -m /path/to/file/model.gguf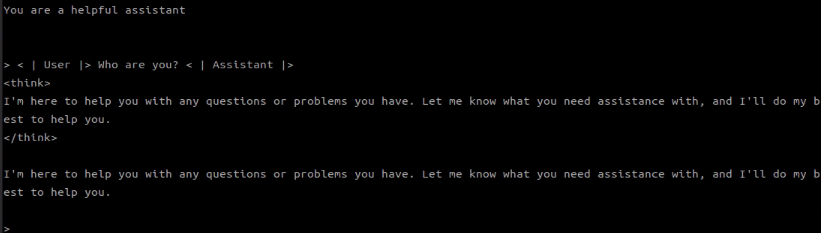
llama-cli를 실행시키면 쉘에서 바로 프롬프트를 주고 응답을 받을 수 있다.
llama.cpp server 실행
# llama-server에서 프롬프트 실행
cd ~/llama.cpp
./build/bin/llama-server -m /path/to/file/model.gguf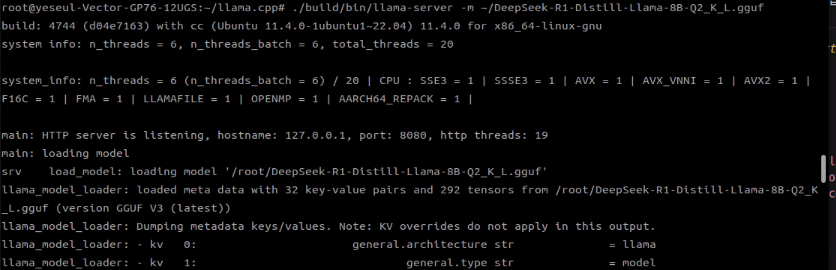
llama-server를 실행시키면 localhost 페이지가 열리고, 챗봇 이용하듯이 프론트에서 프롬프트를 입력하고 제출할 수 있다.
나는 테스트에 deepseek-r1 llama distilled model을 사용했다.
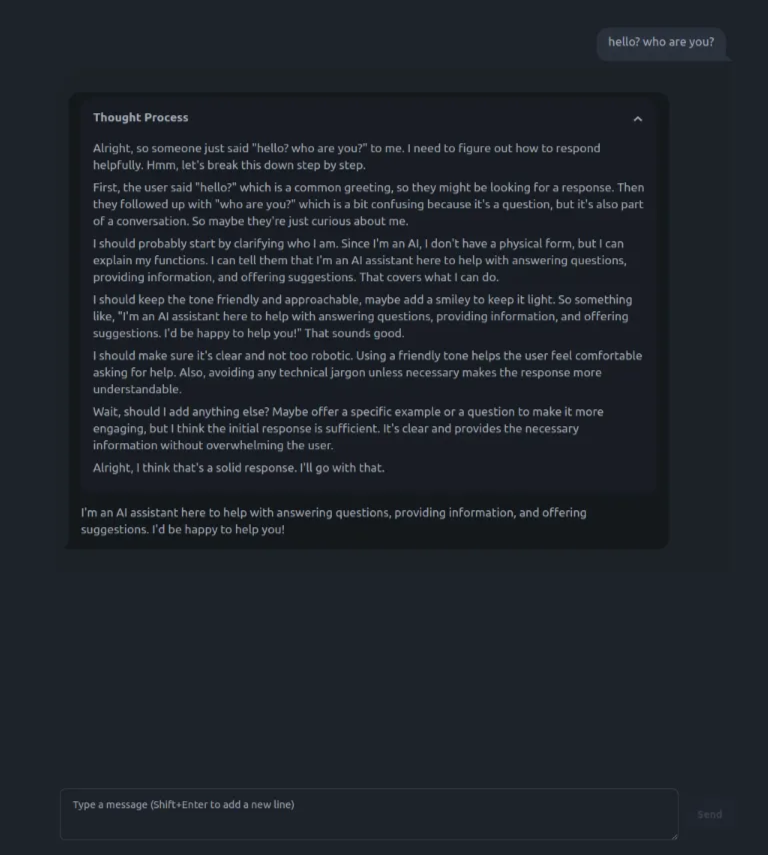
deepseek-R1은 thought process가 제공된다.
safetensor 모델을 gguf 로 변환
llama.cpp에서는 safetytensor 형식의 모델을 gguf로 변환할 수 있다.
방법은 llama.cpp 디렉토리 내 convert-hf-to-gguf.py 를 활용하면 된다.
우선 변환하고자 하는 모델을 huggingface-cli를 통해 다운로드하고(허깅페이스 토큰 발급이 필요하다), gguf 포맷 모델로 변환시켜 보자.
$ python3 convert-hf-to-gguf.py ./ --outfile명령어를 실행하면 아래처럼 safetensor가 bfloat 16의 gguf 포맷으로 변환되는 과정을 볼 수 있다.
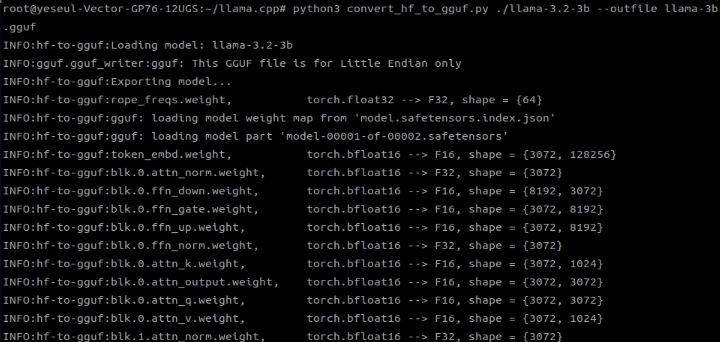

6.4GB 크기의 gguf 포맷 llama 모델이 탄생했다.
위 명령어로 사용하면 기본적으로 FP16(16-bit float)으로 변환되며, 이후 모델을 양자화해 더 작고 효율적인 모델로 만들 수 있다.
cli에서 바로 써봤는데 대답 속도는 무지 느리다.
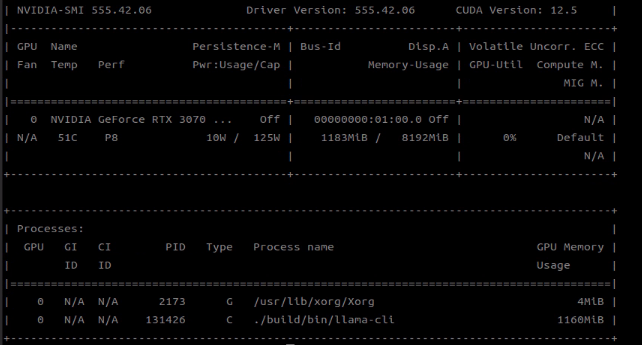
실행했을때 RTX 3070 ti 기준 vram 1gb 정도 먹는걸 볼 수 있었다 (llama.cpp에서 cuda 사용할때의 기준).
llama.cpp로 양자화 모델 만들기 (quantization)
llama.cpp에서는 gguf 모델을 여러 양자화 포맷으로 변환할 수 있다.
Quantization Types 에 대해서는 아래 huggingface(GGUF) 링크를 참조하면 된다.
[huggingface] gguf
# 양자화 예시 : 4비트 (INT4)
./build/bin/llama-quantize ./my_model.gguf ./my_model_q4_k_m.gguf Q4_K_M 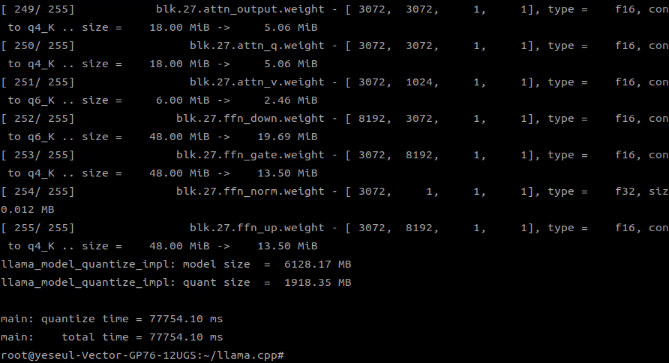
이렇게 양자화를 마치고 나면 새 gguf 파일이 생기고, 같은 방법으로 양자화 모델을 테스트해 봤을 때, 응답 속도가 꽤 향상된게 체감된다.
이런식으로 양자화된 모델을 실제로 서빙할 수 있을지는 좀 더 써봐야 알 것 같다.
[+] LLama-cpp-python
뭐?! llama-cpp는 c++/c에서 효율적으로 쓰라고 만들어놨지만, 그걸 또 파이썬 바인딩으로 누릴 수가 있다고?!
그렇다. 나같은 c++도 모르는 파이썬 개발자들을 위해.. 그리고 언어 모델 쪽 개발에는 대부분 파이썬을 선호하니까.. 파이썬을 쓰는 것이 다른 모듈이나 실행파일과 통합하기도 편할 것이다.
[llama-cpp-python] llama-cpp-python
llama-cpp-python도 cpu, gpu 두가지 버전 다 사용 가능하다. (아래 설치 명령어 참조)
# llama-cpp-python (cpu)
pip install llama-cpp-python
# llama-cpp-python with cuda (cuda 12.1 ~ 12.5)
CMAKE_ARGS="-DGGML_CUDA=on" pip install llama-cpp-python
실행 예제
다음은 llama-cpp-python에서 gguf 모델을 사용하는 예제이다.
from llama_cpp import Llama
llm = Llama(
model_path="/home/yeseul/DeepSeek-R1-Distill-Llama-8B-Q2_K_L.gguf",
chat_format="llama-2"
)
response = llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are an ai assistant who perfectly answer the question."},
{
"role": "user",
"content":
"What is the sum of the first 100 natural numbers? answer in a short form."
}
]
)
print(response['choices'][0]['message']['content'])
