(학습 중에 느낀 것을 정리한 것임을 미리 밝힙니다. 내용에 대한 태클 환영이라는 뜻)
🤷♂️ 프론트엔드의 객체 지향
그 유명한 토끼책(객체지향의 사실과 오해)를 읽으면서 객체의 책임과 메시지, 자율성에 대해 배웠다. 그렇다면 프론트엔드의 객체 지향은 어떻게 적용될 수 있을까 고민해보았다.
내가 생각 했을때, 프론트엔드에 토끼책처럼 이상적인 객체지향을 적용하기는 쉽지않다. 그 이유는 다음과 같다.
- UI적인 요소로 객체를 나눈다면, 프론트엔드의 객체는 자율성을 가지기 어렵다. 왜냐하면 UI들은 서로 연결되어 있어서, 책임을 나누기 곤란하다.
- 그렇다면 상태를 중심으로 책임을 갖도록 객체를 나눈다면? 여러군데 UI가 뭉쳐서 모든 개발자들이 한번에 인식할만한 객체를 구분하는게 어렵다.
이처럼 웹 페이지는 상태와 UI가 서로 복잡하게 영향을 주고 받기는 때문에 책임을 나누기 쉽지않다. 그럼에도 불구하고,
- 일관성을 갖는 코드
- 변화에 잘 대응하는 코드
- 예상 가능한 위치에 존재하는 코드
이런 코드를 짜기위한 다양한 패턴들이 제시되어왔다. 객체지향도 결국 원칙을 통해 개발자들이 서로 코드를 이해하기 쉽고 관리하기 쉬운 코드를 짜기 위함이 아니던가?
MVC
MVC 패턴은 모델, 뷰, 컨트롤러로 책임을 나누는 것으로 프론트엔드 뿐만 아니라, 백엔드에서도 사용되는 방법이다. 웹페이지에 상태를 때어내고, UI요소를 뷰들로, 이들은 연결하는 것을 컨트롤러로 나눴다.
모델 = 상태를 관리를 담당
뷰 = 상태를 기반으로 렌더링을 담당
컨트롤러 = 모델과 뷰를 연결시켜주고, 유저 interaction을 담당
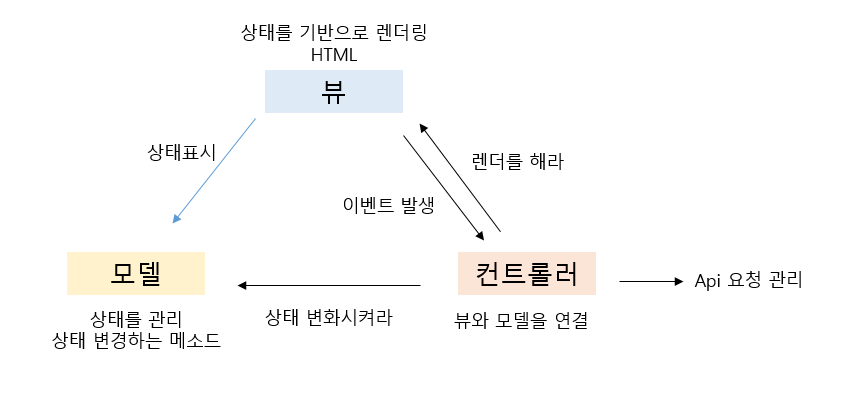
비로소 모든 개발자들이 합리적으로 공감할만한 구조가 되었다. 하지만 조금만 규모가 커진다면 문제점을 야기한다.
첫 번째 문제점, 컨트롤러가 복잡해진다. 모델과 뷰는 역할도 단순할 뿐더러. 규모가 커진다면 모델은 역할별로 분리할 수 있다. (ex. 로그인관련 상태, 검색조건 관련 상태) 뷰도 마찬가지다. (ex. 로그인 관련 UI, 검색 모달 UI). 하지만 컨트롤러는 굉장히 복잡해지고 나누기도 애매하다.
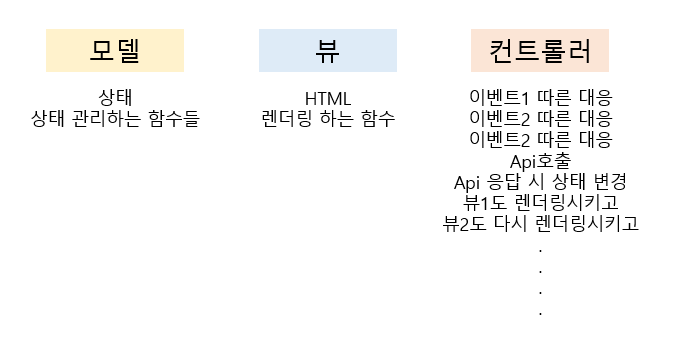
두 번째 문제점, 의존성 관리가 어렵다. 서로 영향을 주는 모델 뷰가 복잡해지면 양방향 데이터흐름에 의해 변화를 예측하기가 어려워진다. 예를들어, 뷰1에서 변화에 의해... 모델1, 모델2가 변화되고 그에 의해 뷰2,뷰3,뷰4 가 변화되고 그로 인해 모델3이 다시... 이렇게 되면 어딜 수정하기가 어렵다...
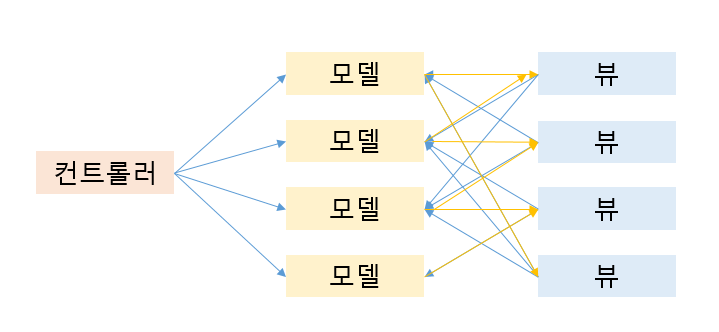
waterfall
공부하면서 알게 된 것이 React != Flux 라는 것이다. 이 후에 Flux 패턴을 살펴보면 차이점을 알 수 있다. flux를 안쓰고도 리액트를 사용할 수 있다는 말이다. 이 리액트 컴포넌트 어떤 패턴이라고 부르는 지 모르겠어서(waterfall 패턴이 제일 근접한 것 같다.) waterfall 방식이라 부르겠다.
(컴포넌트는 재사용될 수 있는 최소한의 단위로 심오한 뜻이 있지만) 이 패턴은 컴포넌트라는 단위로 UI를 구분하고 DOM 트리와 같은 구조를 가지게 한다. 이는 자연스레 트리구조로 "3. 예상 가능한 위치에 존재하는 코드"가 되어 페이지가 복잡해져도 의존성을 파악하기가 쉽다.
사용되는 상태, 이에 대한 메소드를 상위 컴포넌트에 갖게 하고, 상위컴포넌트에 상태 변화가 일어나면 이를 사용하는 자식 컴포넌트에도 렌더링을 연쇄적으로 일으킨다. 이는 단방향 데이터 흐름을 가지게 해 MVC 패턴에서의 양방향 오류를 해결할 수 있다.
아래 예시를 보면 메인페이지 컴포넌트를 수정하면 아래 검색조건UI, 검색조건변경 모달창, 검색버튼이 영향을 받을 거라는 것을 쉽게 알 수 있다. 새로운 검색조건을 추가하고 싶다면 메인 페이지 컴포넌트에 새 컴포넌트를 달아주고 상태를 넘겨주기만 하면 될 것이다. 즉 유지보수가 쉬워진다.
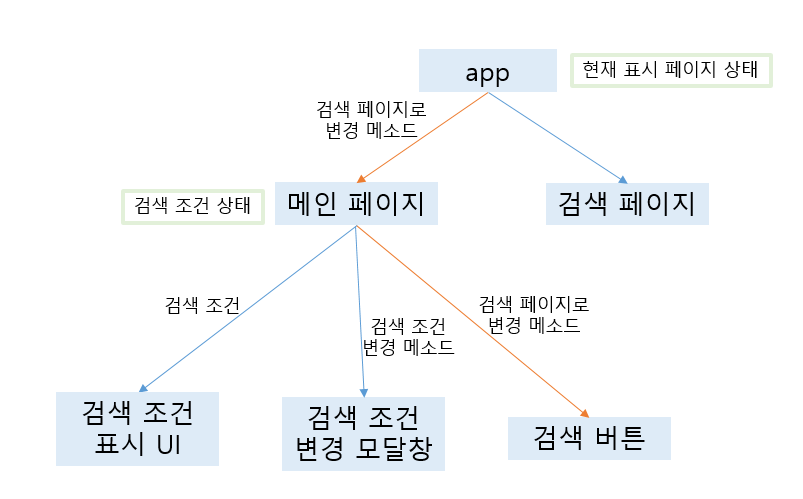
컴포넌트는 보통 다음과 같은 구조를 가지게 될 것이다.
state,props 가 모델, template 이 뷰, 나머지 메소드들이 컨트롤러로 생각하면 된다.
공통되는 상태는 상위 컴포넌트에게 책임을 넘기고 메소드를 props로 전달해 의존성을 관리시킨다 라고 할 수 있겠다.
state = 나와 내 자식 컴포넌트의 변화를 일으키는 상태
props = 부모로부터 받은 상태, 혹은 메소드
template = state, props를 보여줄 view HTML
메소드 = 이벤트 핸들러, api 핸들러

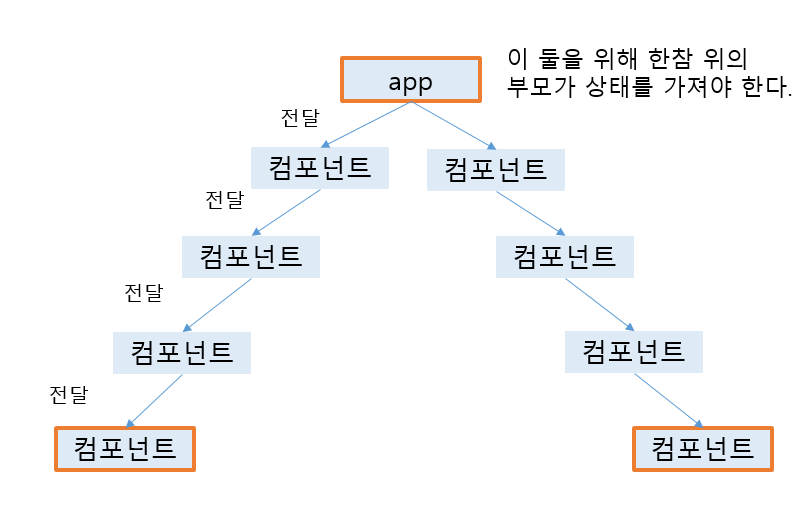
waterfall 패턴의 단점은 공통되는 상태가 위로 올라가기 때문에 특정 부모 컴포넌트가 복잡해지게 된다. 이 중 하나만의 상태만 바뀌어도 자식 랜더링을 다시하기 때문에 불필요한 랜더링이 일어나게 되는데, 랜더링을 최적화 시킨다면, 코드는 더 복잡해질 것이다. 또한 DOM트리에서 먼 UI가 상태를 공유하게 되면 한참 위의 부모까지 거슬러 올라가야한다.
두 번째 단점은 props 전달로 인한 피로감이다. 자식 컴포넌트가 한참 아래 있어도 전달을 위해 계속 props로 전달되어야한다.
Flux
Flux 패턴은 페이스북 팀에서 MVC의 문제점을 해결하고자 만든 것이다. Flux 역시 MVC 패턴의 복잡성을 단방향 데이터 흐름으로 해결하려 했다.
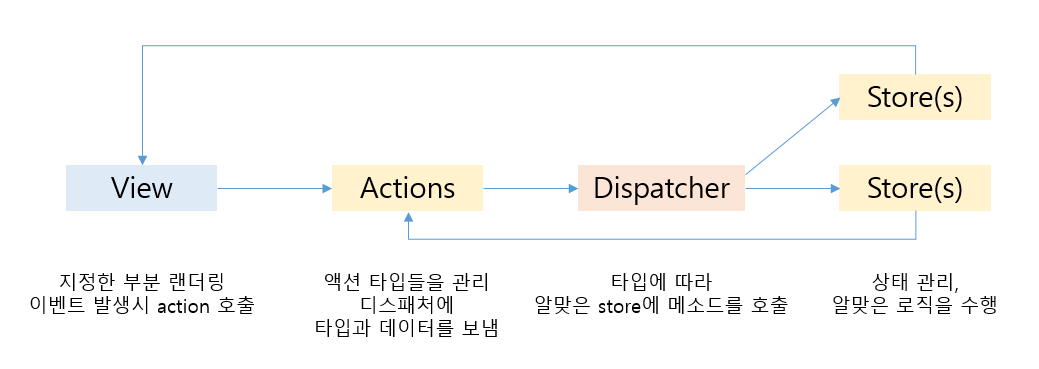
view = 랜더링 담당, 유저 interaction 및 action 호출 (리액트 컴포넌트)
action = 액션 생성, dispatcher에 타입과 데이터를 보냄
dispatcher = 받은 타입과 데이터를 store들에게 전달
store = action에 따라 상태관리 및 로직 수행
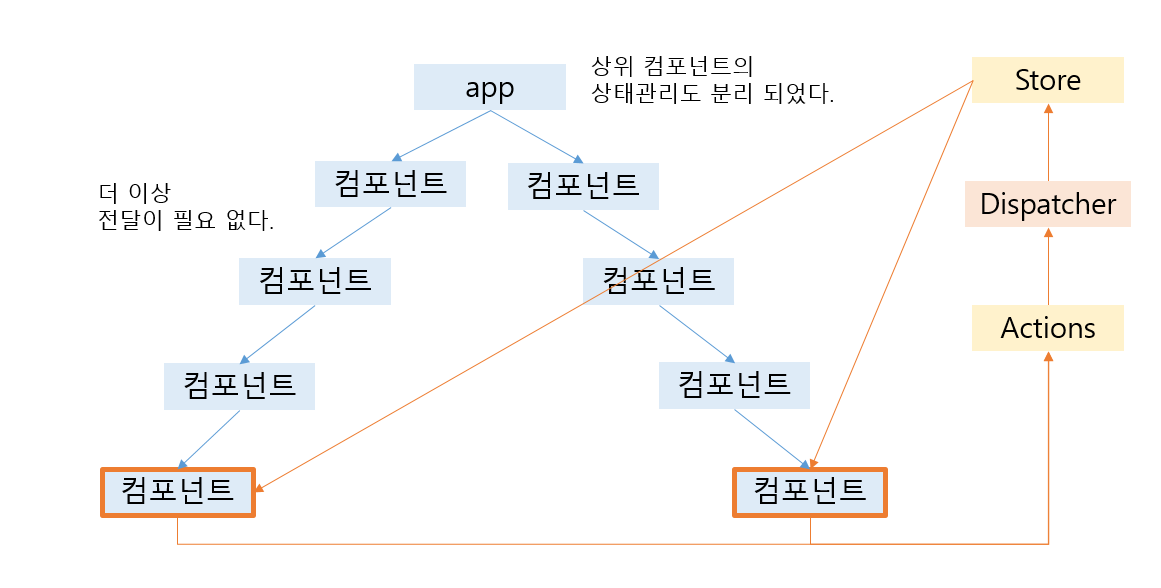
모든 상태 변화가 하나의 dipatcher를 거치므로 의존성를 파악하기 쉽다.
actions들은 컴포넌트 어디에서든 호출될 수 있음으로, 상태 변경에 관련해서 props를 계속해서 전달하지 않아도 된다. 또한, store가 뷰와 분리됨으로서 컴포넌트의 복잡했던 로직들이 global store로 분리가 되고 일종의 옵저버 패턴이 되었다.
Redux
그렇다면 Redux는 무엇일까? Redux는 Flux의 (업그레이드된) 구현체라고 생각할 수 있다. 상태관리 로직을 외부로 분리한다는 점에서는 같고 차이점은 다음과 같다.
- 하나의 스토어만을 가지고, 비즈니스 로직은 reducer에 있다.
- dispatcher가 없고, 여러개의 reducer들을 가진다. 이 reducer들은 순수함수이다
이 두가지 차이점을 통해, Redux는 이전 상태를 변경시키는 것이 아니라 새로운 상태를 만들어 낸다. 이는 테스트와 과거 상태 변화를 추적하는 데 있어서 강력함을 갖는다.
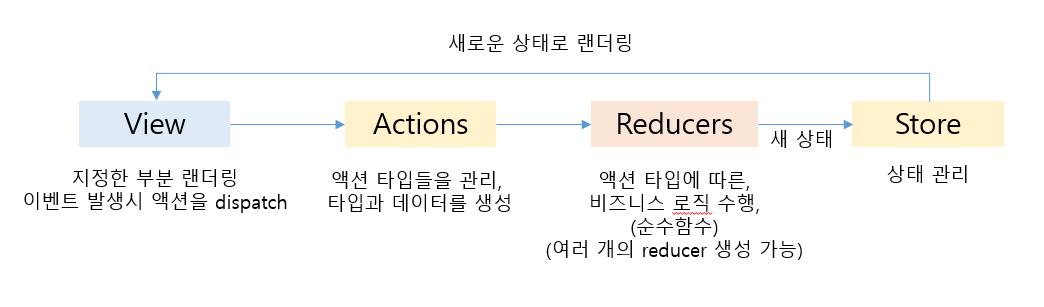
view = 랜더링 담당, 유저 interaction 및 action 호출 (리액트 컴포넌트)
action = 액션 관리, 액션 타입과 데이터로 액션 생성
reducer = 받은 액션에 따른 비즈니스로직 실행
(root reducer) = sub reducer이 생성한 상태를 총합해 store로 전달
(sub reducer) = 액션타입에 따라 순수함수로 새 상태 생성
store = 중앙 상태 관리
하지만 단점으로, 코드량이 많아진다는 불편이 있다. 한 가지 상태를 간단히 변화시키는데에도, action, reducer를 왔다갔다하며 코드를 추가시켜야 하기 때문이겠다.
이게 끝이 아니다.🤨
지금까지 왜 프론트엔드에서 객체지향으로 생각하기가 쉽지않은지, 상태 관리를 중심으로 MVC, waterfall, Flux, Redux의 그 필요성을 짚어보고 비교해보았다.
- 일관성을 갖는 코드
- 변화에 잘 대응하는 코드
- 예상 가능한 위치에 존재하는 코드
어떤 패턴을 사용하더라도 서비스의 규모에 따라서 위 조건을 만족시킬 수도 있다. 또한 계속해서 상태관리에 대한 기술들이 발전되고 있기도 하다. 다음 번에는 기회가 된다면 리액트의 context api, jotai, recoil를 한번 공부해보겠다...
reference
https://facebook.github.io/flux/
https://ko.redux.js.org/
https://www.clariontech.com/blog/mvc-vs-flux-vs-redux-the-real-differences
https://baeharam.netlify.app/posts/architecture/flux-redux
https://jeesoo.work/flux-to-redux
https://www.huskyhoochu.com/flux-architecture/
