애자일 협력툴로 마인드맵의 데이터 베이스를 설계 중이다.

🧙♂️ 요구사항 분석
설계를 위한 요구사항을 분석해보면 다음과 같다.
- 자식 노드의 개수는 일정하지 않다.
자식이 없을 수도 10개가 될 수도 있다.
- 수정이 빈번하다.
실시간 협업툴이기 때문에 추가,수정,삭제가 빈번하다.
- 과거 히스토리 기능이 필요하다.
수정이 일어나도 이전 데이터를 기억해야한다.
- depth는 깊지 않다.
root,epic,story,task로 최대 4 레벨이다.
🧙♂️ 설계
후보로 생각나는 방법을 적어보고 장단점을 생각해보았다. 예시로는 기존 트리에 1번 노드에 3번 노드를 넣는 것으로 들겠다.
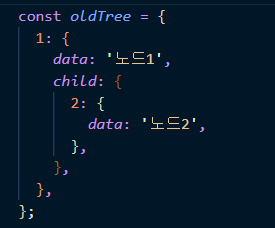
1. 하나의 Json으로 스냅샷마다 저장한다.
요구사항을 보며 Git을 떠올렸다. Git은 트리구조로 데이터를 저장하고, 커밋마다 스냅샷을 찍는다.
장점:
-
로직이 간단하다.
수정이 일어나면 새 Json을 만들어서 보내면 된다. -
join이 필요없다.
노드간의 관계가 필요없고, 한 번의 쿼리만 필요하다.
단점:
-
일부분 수정에도 큰 payload가 발생한다.
트리의 한 노드에서의 변화에도 전체 트리를 전송해야한다. -
중복 데이터가 발생한다.
변경이 일어나지 않은 부분에 대해서도 저장이 되기때문에 DB에 중복데이터가 발생한다.
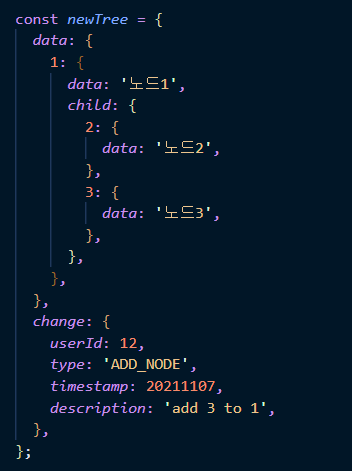
2. 변경이 일어난 노드에 새 노드를 생성한다.
Git은 사실 전체 데이터를 통째로 저장하지는 않는다. 변경 부분에 대하여 새 blob을 생성하여 효율적으로 데이터를 보관한다.(+ sha1 hash 알고리즘) 그러다면, 변경이 일어난 부분에 대해서만 새 노드를 생성하는 방법은 어떨까. 일단, 루트 노드는 매번 새로 생성되어야 할 것이다.
장점:
- payload가 줄어든다.
수정이 일어나면 수정이 일어난 부분에 대해서만 서버에 보낼 수 있다.
단점:
-
join이 많이 필요하다.
계층적 노드에 대한 join이 많이 일어난다. 서버에서 30개의 히스토리를 보내줘야한다면, 30번의 재귀적인 join이 일어날 것이다. -
변경 알고리즘이 복잡하다.
변경된 노드에 대해 새 노드를 생성하는 것과 더불어, 상위 노드도 자식노드에 대한 변경이 있음으로 새 노드를 생성하다 보면, 재귀적으로 root까지 새 노드를 생성하는 알고리즘이 필요하다.
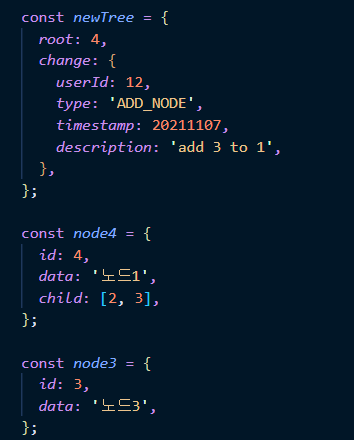
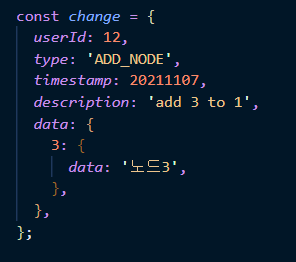
3. 최신 노드와 변경사항을 저장한다.
마치 데이터베이스를 롤백하듯이, 트리의 변경을 논리적 단위로 저장한다면, 변경사항만으로도 과거의 히스토리를 만들어낼 수 있다.
장점:
-
payload가 작다.
정말 순수히 바뀐 부분에 대해서만 전송하고 저장할 수 있다. -
join이 필요없다.
노드간의 관계가 필요없고, 서버에서는 최신 노드만 저장할 수 있다.
단점:
- 변경에 대한 알고리즘이 복잡하다.
노드의 추가, 삭제, 수정에 대한 로직이 필요하고, 거꾸로 롤백할 수 있는 순수하고 atomic한 로직이 필요하다.
🧙♂️ 고려할 부분
RDB vs NoSQL
RDB와 NoSQL 중 어떤 것이 유리할지 고려해보았다.
수정은 빈번하나 과거 데이터를 기억해야함으로 DB에서의 수정은 거의 없을 것이고. 계층적인 데이터를 저장하기 위해 RDB에서는 Adjacency List, Nested Set, Closure Table 같은 기법을 써야하고, NoSQL이라면 MongoDB(Document DB), Neo4j(Graph DB)가 고려 대상이 될 수 있겠다.
RDB
장점:
- ACID (atomicity, consistency, isolation, durability) 트랜잭션을 보장
- 데이터의 탐색, 수정 속도가 비교적 빠름
단점:
- 반드시 스키마가 필요
- 수평 확장에 불리
NoSQL
장점:
- 대부분의 상황에서 관계, join이 불필요
- 스키마가 정해져있지 않아 자유로움
- 수평확장에 유리
- json 형식으로 저장이 가능
단점:
- 중복데이터에 의해 RDB보다 용량이 큼
- 데이터 수정이 비교적 느림
https://www.slideshare.net/billkarwin/models-for-hierarchical-data
https://db-engines.com/en/system/CouchDB%3BElasticsearch%3BMongoDB%3BNeo4j
https://www.mongodb.com/scale/nosql-vs-relational-databases
https://www.mongodb.com/nosql-explained/nosql-vs-sql
https://www.lesstif.com/dbms/rdb-hierarchical-data-28606798.html
데이터 row 사이즈의 크기와 DB 퍼포먼스
데이터 row의 크기는 데이터베이스의 성능에 영향을 미친다. 큰 row를 가지게되면 메모리에 올라가는 데이터가 적어지고, 이는 캐쉬 성능을 떨어트리고 더 많은 disc I/O를 일으킨다.
Bigger Row Size = Less Rows Per Page = More data pages per table = More I/O operations = Performance degradation
https://stackoverflow.com/questions/842791/mysql-duplicating-data-vs-join
https://aboutsqlserver.com/2010/08/25/why-row-size-matters/
데이터 사이즈와 크기와 소켓통신 퍼포먼스
실시간 데이터 반영을 위해 서버와 소켓간에 socket.io를 활용할 계획이다. 혹시 전해줘야할 데이터가 커진다면 영향이 있지 않을까? (물론 json 데이터에 대한 크기이긴 하지만 말이다.)
조사해보니, Node.js와 socket.io 지정된 limit은 없고, 서버와 클라이언트가 수용할수 있는 bandwidth에 달려 있다고 한다. 데이터와 사이즈, 전송 주기, 서버의 네트워크 bandwidth를 통해 계산을 할 수 있는데, 그렇다면 패킷이 작은게 유리하다고는 할 수 있겠다.
https://stackoverflow.com/questions/12977719/how-much-data-can-i-send-through-a-socket-emit
https://stackoverflow.com/questions/47275123/how-f requently-can-i-send-data-using-socket-io
중복데이터 vs 여러번의 join
역정규화라는 좋은 단어가 있었다. 잦은 join으로 인해 퍼포먼스가 떨어지는 것을 방지하기 위해 관계를 제거하고 하나의 구조로 만드는 것이다.
트리의 depth 자체는 낮지만 자식 노드의 개수가 정해져있지 않기 때문에 mySQL에서의 역정규화는 json을 stringfy 시키는 방법이 유일해 보인다.
https://en.wikipedia.org/wiki/Denormalization
https://dba.stackexchange.com/questions/461/duplicate-column-for-faster-queries
https://stackoverflow.com/questions/842791/mysql-duplicating-data-vs-join
🧙♂️ 결론
결론적으로 선택한 방법은, 3번 최신 노드와 변경사항을 저장하는 방법이다. 그 이유는 중복된 데이터가 최소한이면서도, join의 횟수도 적기 때문이다. join이 필요한 경우도 최신 노드를 저장할 때 뿐인데 이 또한 비정규화를 통해 방지할 수 있다. 저장되고 전송되는 data도 변경사항 뿐임으로 효율적이다. 구체적인 규격은 다음과 같다.
1. RDB와 Redis를 활용한다.
최신노드를 서버에서 보관을 해야한다. 이때 Redis를 통해 메모리에서 최신노드를 관리하고, 비동기로 최신노드를 DB에 저장시켜 성능을 향상시킨다.
mySQL을 사용하는 이유는 noSql에 비해 비정형 데이터를 저장하기에는 불편하나, Adjacency List로 저장한 뒤 redis에 최신 모델을 올려놓는 방식으로 극복한다. 또한, 변경사항을 저장할 때 timeStamp를 index로 사용해 빠르게 정렬하고 응답하게 한다.
2. 하향식으로 자식을 저장한다.
상향식으로 parent를 기억한 뒤 맵을 만든다면, 노드간의 순서를 변경시킬시 3번의 쿼리가 필요하다. (부모, 나, 형제 모드)
하향식으로 child를 관리한다면, 1번의 쿼리로 가능하다.
3. 옵저버패턴으로 동시성을 유지한다.
모든 맵의 변경은 서버에 요청하고, 서버에서 처리 후 broadcast 하는 방식으로 동시성을 보호한다. 먼저 도착한 요청 순으로 낮은 timeStamp를 부여 받는다.
모든 변경 요청은 순수한 작업이고 롤백이 가능해야 한다.
구체적인 변경 타입과 필요한 데이터는 다음과 같다.
| type | nodeFrom | nodeTo | dataFrom | dataTo | 비고 |
|---|---|---|---|---|---|
| node 추가 | 상위 nodeId | null | null | node데이터 | (id는 서버에서 추가) |
| node 삭제 | 상위 nodeId | null | node데이터 | null | |
| node 이동 | nodeId | nodeId | node데이터 | nodeId | 새 백로그 넘버 부여 |
| node 합체 | nodeId | nodeId | node데이터 | nodeId[] | 새 백로그 넘버 부여 |
| node 다중 삭제 | nodeId | null | node데이터 | null | |
| node 순서 변경 | nodeId | null | nodeId[] | nodeId[] | |
| 마감시간 변경 | nodeId | null | Date | Date | |
| 이름 변경 | nodeId | null | string | string | |
| 스프린트 추가 | nodeId | null | null | sprintId | |
| 스프린트 삭제 | nodeId | null | sprintId | null | |
| 스프린트 변경 | nodeId | null | sprintId | sprintId | |
| 라벨 추가 | nodeId | null | null | labelId | |
| 라벨 삭제 | nodeId | null | labelId | null | |
| 중요도 변경 | nodeId | null | number | number | |
| 댓글 추가 | nodeId | null | null | 댓글데이터 | (id는 서버에서 추가) |
| 댓글 삭제 | nodeId | null | 댓글데이터 | null |
