DB 모델링기법 중 슈퍼-서브타입 모델링이라는게 있다.
이는 논리모델은 같지만, 실제 물리모델은
- RollUp
- RollDown
- Identity
중 하나로 구현한다.
슈퍼타입-서브타입(확장된 ER 모델)
- 슈퍼타입 = 공통의 부분
- 서브타입 = 공통되는 부분 이외에도 각각 specialize된 속성들을 별도로 구성
슈퍼타입-서브타입 도출
슈퍼타입, 서브타입 엔티티 식별자의 도메인은 반드시 같아야한다.
도출 방법 1
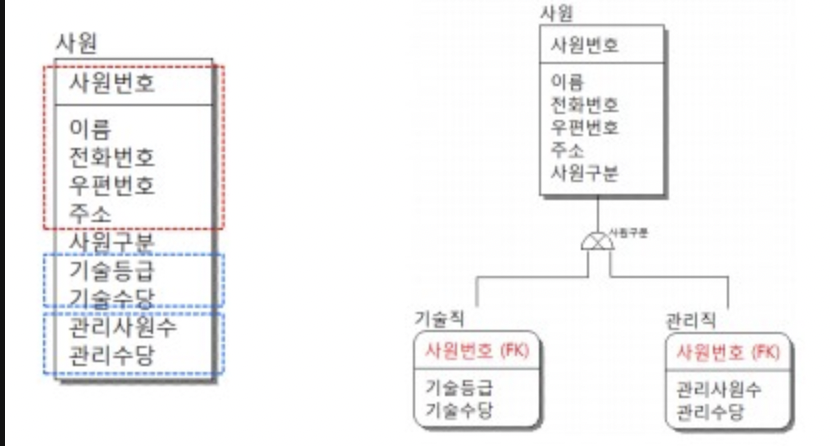
슈퍼타입 = 공통될 데이터만 사원 엔티티에 남김 (빨간 박스)
서브타입 = 기술직, 관리직만의 specialize된 속성들은 별도의 엔티티로 구성 (파란박스 2개)
도출 방법 2
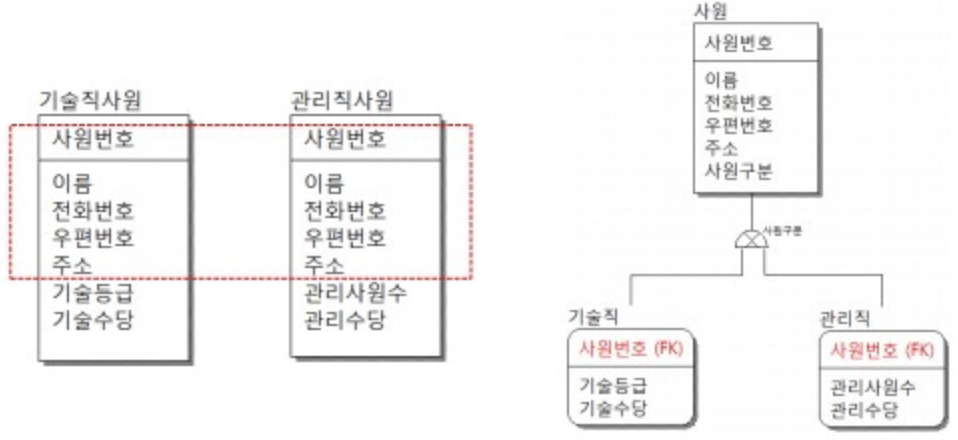
슈퍼타입 = 각 엔티티의 공통된 데이터는 별도의 사원 엔티티로 구성
서브타입 = 기술직, 관리직만의 specialize된 속성들만 각 엔티티에 남김
이렇게 2가지 방식으로 슈퍼타입-서브타입을 구성하는것을 살펴봤다.
그런데 도출된 관계를 보면 슈퍼타입과 서브타입을 이어주는 곳에 특이한 기호가 있다.
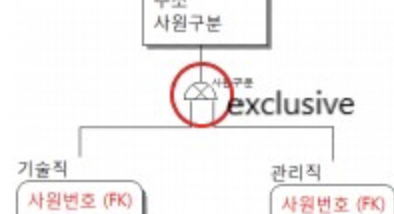
이는 서브타입의 관계를 나타내며 '서브 카테고리'라고 한다.
아래에서 자세히 알아보자.
서브 카테고리
배타적(exclusive) 서브 카테고리
두 서브타입간 교집합이 없을 경우 배타적 서브 카테고리라고 하며 아래와 같이 표기한다.
-> 기술직일 경우, 관리직이 아니다. / 관리직일 경우, 기술직이 아니다.
그림을 보면, 서브 카테고리 표기 옆에 '사원구분'이라는 글자가 있다.
이는 구분자 속성이라고 하는데, 이 속성을 지정해줘야하며 이러한 속성을 설계 속성이라고 한다.
포괄적(inclusive) 서브 카테고리
두 서브타입 간 교집합이 있을 경우 포괄적 서브 카테고리라고 하며 아래와 같이 표기한다.
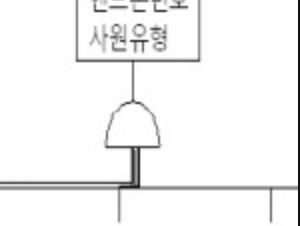 -> 사원은 기술직이면서 관리직일 수 있다.
-> 사원은 기술직이면서 관리직일 수 있다.
자 이제 논리모델과 물리모델에 관해 알아보자.
논리모델
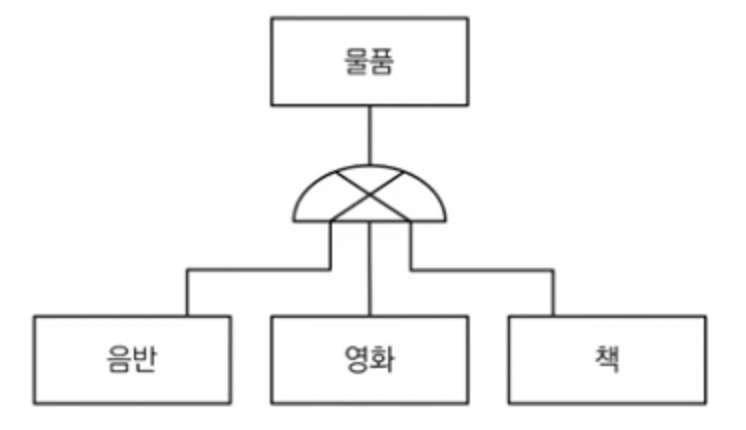
물리모델
슈퍼타입/서브타입 관계의 변환 방법으로 3가지가 있다.
Rollup
하나의 테이블로 통합
: 슈퍼타입에 서브타입의 모든 컬럼을 통합하여 하나의 테이블로 생성

사용에 적절한 상황
- 전체 테이블을 같이 Access처리하는 것이 대부분인 경우
- 서브타입의 속성 개수가 적은 경우(1~2개)
- 서브타입과 관계를 맺은 엔티티가 별로 없는 경우
- 업무적으로 변화가능성이 낮아, 추가적인 서브타입이나 속성의 가능성이 낮은 경우
장점
- 조인할 일이 없으므로 SQL문장 구성이 단순, 수행속도가 빨라지는 경우가 있다
- 서브타입을 구분하지 않고 데이터를 조회할 경우 처리가 용이하다
단점
- 특정 서브타입의 NOT NULL 제한 불가 (NULL값이 많아질 수 있다)
Rolldown
여러 개의 테이블로 분리
: 슈퍼타입을 각각의 서브타입에 추가하여 분리

사용에 적절한 상황
- 공통적인 속성들에만 별도로 Access할 필요가 없는 경우
- 슈퍼타입의 속성개수가 많지 않은 경우
- 슈퍼타입과 관계를 맺은 엔티티가 거의 없는 경우
장점
- 정보를 각 서브타입 별로 조작할 경우, 조인하지 않아도 되며 Full Scan 발생시 유리
- 관계에 의해 발생하는 복잡한 참조 무결성 규칙을 적용할 수 있다
단점
- 고유 식별자(unique identifier) 유지 관리가 어렵다.
Identity (One-To-One Type)
슈퍼타입과 각각의 서브타입을 테이블로 생성
(일부 서브타입은 슈퍼타입에 통합되는 경우도 존재)
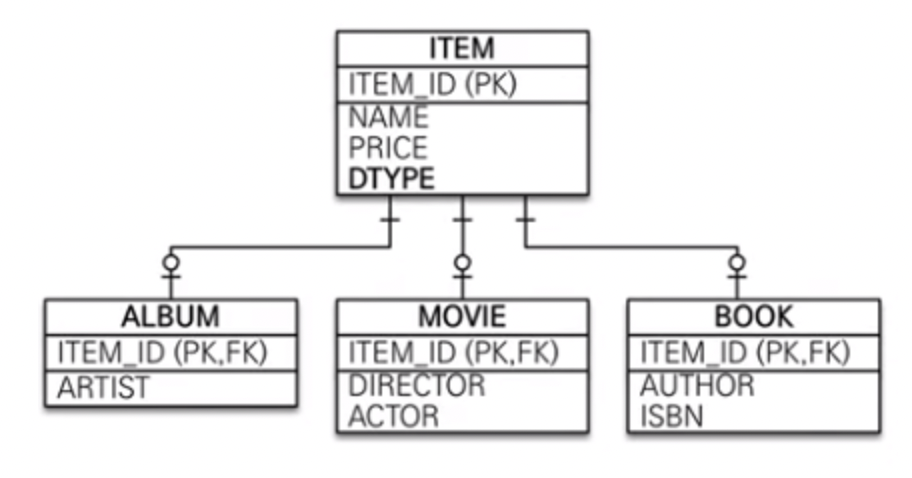
사용에 적절한 상황
- 슈퍼타입과 서브타입을 각각 적절히 Access하는 경우
- 슈퍼타입에 속한 공통속성들만 Access하는 빈도가 높은 경우
- 슈퍼타입과 서브타입 각각 별도 관계를 맺은 엔티티들이 존재하는 경우
- 업무적으로 변화가능성이 높아 유연성을 확보할 필요가 있는 경우
장점
- 각각의 테이블로 처리할 경우, 수행 속도가 빠르다.
- 슈퍼 타입에 속한 정보만 조회하는 경우, 문장 작성이 용이하다.
- 컬럼의 중복이 적으므로, 상대적으로 작은 공간을 차지한다.
- 관계에 의해 발생하는 복잡한 참조 무결성 규칙을 적용할 수 있다.
슈퍼타입-서브 타입 데이터 모델 변환타입 비교
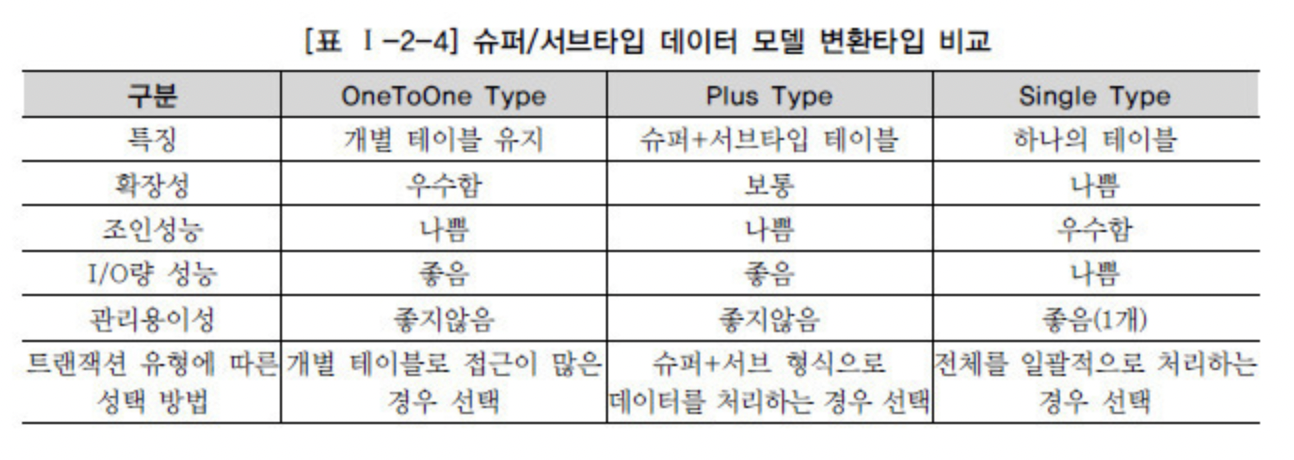
물리모델 결정 기준
데이터의 양과 트랜잭션의 유형에 따라 선택한다.
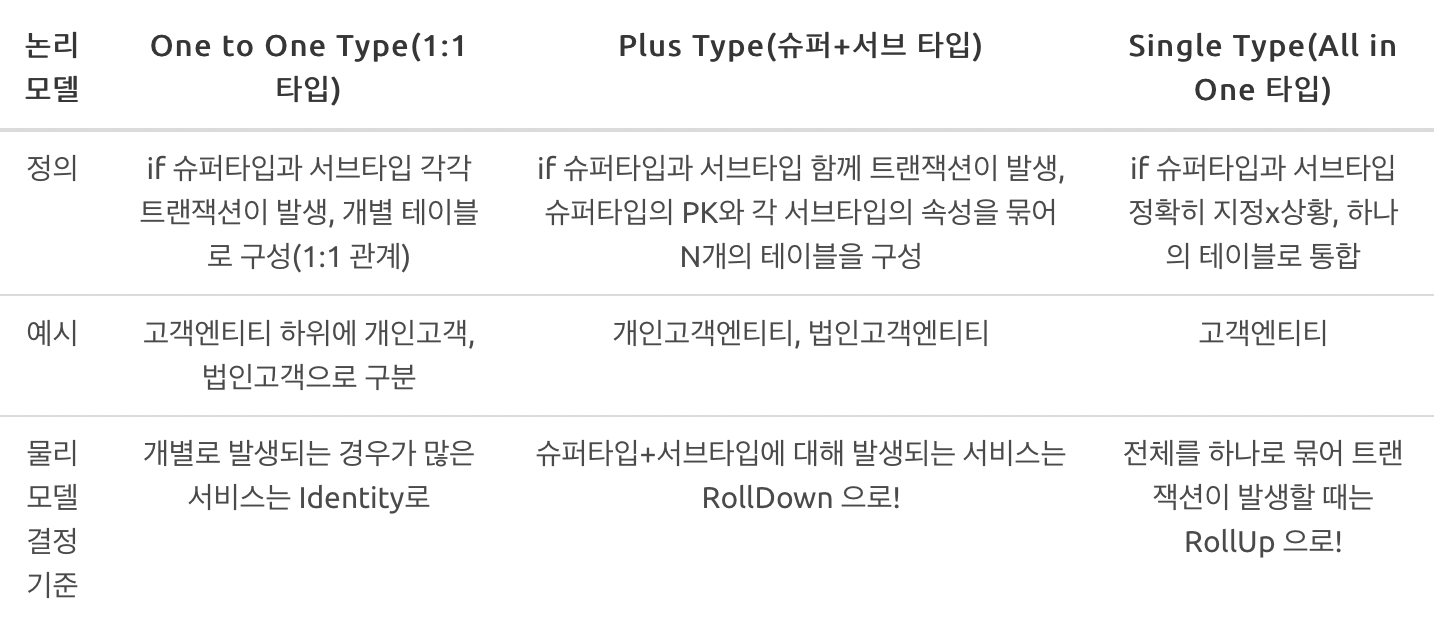
만약
- 10만건도 되지 않는 데이터
- 시스템을 운영하는 도중에도 데이터가 증가하지 않을 경우
-> 위 2가지의 경우에는 트랜잭션의 성격을 고려하지않고, 전체를 하나의 테이블로 묶는 것도 괜찮은 방법이다.
하지만 데이터 양이 이미 많고 지속적으로 증가한다면 슈퍼/서브타입 물리적 데이터 모델로 변환하는 세 가지 유형을 고려해야한다.
1. 개별로 발생되는 경우가 많은 서비스는 Identity로 !
위의 논리모델에서 예를 들자면, 아이템의 가격정보를 먼저 조회하는 경우는 많지만
각 유형의 세부정보는 열람할수도 아닐수도 있을 상황에 안성맞춤! (발생로직이 분리되어있음!)
2. 슈퍼타입+서브타입에 대해 발생되는 서비스는 RollDown 으로!
서브타입(ALBUM, MOVIE, BOOK) 에 각 200만건, 90만건, 10만건 이 있다고 가정하자.
만약 내가 책을 조회하고싶다.
Single 타입(RollUp)으로 구성했을 경우, 300만건 중에 10만건만 조회하는 불필요한 성능저하가 발생한다.
OneToOne 타입으로 구성했을 경우, 계속 조인이 발생한다.
3. 전체를 하나로 묶어 트랜잭션이 발생할 때는 RollUp 으로!
서브타입(ALBUM, MOVIE, BOOK) 에 각 10만건, 20만건, 270만건 이 있다고 가정하자.
비즈니스로직상 항상 앨범과 영화, 책을 같이 통합하여 처리해야한다고 하면
Single 타입(RollUp)이 아닌 경우, 불필요한 조인이나 UNION ALL 이 발생한다.
따라서, RollDown 으로 구성할경우, PK를 하나로 묶어 SEQUENCE로 생성하는게 좋다.
+JPA
지금까지 알아본 모델들은 JPA로 구현한다면 아주 간단하게 구현할 수 있고,
물리모델이 바뀌어도 코드 몇줄로 간단히 물리모델을 바꿔 매핑할 수 있다
JPA 슈퍼-서브타입 모델링
참고
https://sowon-dev.github.io/2022/10/31/221101SQLD-super-sub/
https://velog.io/@mindddi/DB모델링-관계슈퍼-서브타입
https://developer-ping9.tistory.com/293
