DataBase
여러 사람이 공유하여 사용할 목적으로 체계화해 통합,관리하는 데이터 집합
여러 응용 시스템들의 통합된 정보들을 저장하여 운영할 수 있는 공용 데이터들의 묶음
- 통합된 데이터 : 자료의 중복을 배제한 데이터 모임
- 저장된 데이터 : 컴퓨터가 접근할 수 있는 저장 매체에 저장된 자료
- 운영 데이터 : 조직의 고유한 업무를 수행하는 데 반드시 필요한 자료
- 공용 데이터 : 여러 응용 시스템들이 공동으로 소유하고 유지하는 자료
DB 특징
- 실시간 접근성 : 사용자 요청에 즉시 처리하여 응답
- 지속적인 변화 : 항상 최신 데이터 동적으로 유지
- 동시 공유 : 여러 명의 사용자나 응용 프로그램이 동시에 같은 내용의 데이터 이용가능
- 내용에 대한 참조 : 데이터 참조 시, 주소가 아닌 내용에 따라 참조
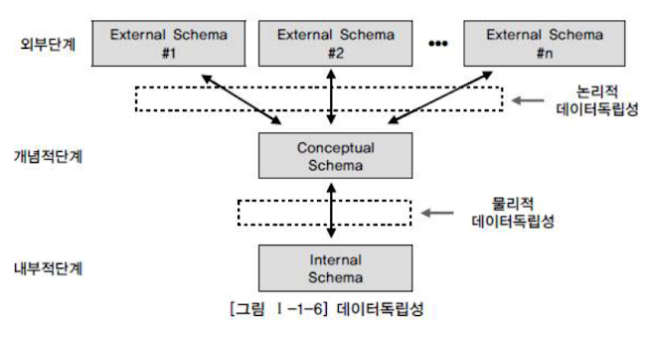
- 데이터 독립성 : 논리적 독립성 + 물리적 독립성
+ 논리적 독립성 vs 물리적 독립성
-
물리적 독립성
-응용 프로그램이나 데이터베이스의 논리적 구조에 영향을 미치지 않고, 데이터의 물리적 구조를 변경할 수 있는 능력
-내부 스키마가 변경되어도, 개념 스키마는 영향을 받지 않음 (관련된 개념/내부 사상만 정확히 수정) -
논리적 독립성
-응용 프로그램에 영향을 주지않고, 데이터베이스 논리적 구조를 변경할 수 있는 능력
-개념 스키마가 변경되어도 외부 스키마는 영향 받지 않음(관련된 외부/개념 사상만 정확히 수정)
DB 장단점
장점
- 데이터 중복 최소화
- 데이터 공유
- 일관성, 무결성, 보안성 유지
- 최신 데이터 유지
- 데이터 표준화 가능
- 데이터의 논리적, 물리적 독립성
- 용이한 데이터 접근
- 데이터 저장 공간 절약
단점
- 데이터베이스 전문가 필요
- 많은 비용 부담
- 데이터 백업과 복구가 어려움
- 시스템 복잡
- 대용량 디스크로 액세스가 집중되면 과부하 발생
Database가 왜 필요할까?
- 이전에는 파일 시스템을 이용하여 데이터를 관리하였는데, 이는 응용프로그램과 데이터가 상호 밀접하게 연관되어있어 데이터 종속성, 중복성, 무결성 문제가 발생.
이를 해결하기위해 자료항목의 중복을 없애고 자료를 구조화 한 집합체를 사용한 데이터베이스 시스템이 등장! - 프로그램에는 필연적으로 많은 데이터들이 생성되어지는데, 프로그램을 종료하는 순간 데이터를 날아가게 하지 않기위해 데이터들을 DB에 넣고 보관한다.
DB 성능
디스크 I/O를 어떻게 줄일까?에서 시작!
데이터를 읽는데 걸리는 시간 = 디스크 헤더를 움직여서 해당 위치로 옮기는 단계에서 결정!
-> 디스크 성능 = 디스크 헤더의 이동을 최소화하여 얼마나 많은 데이터를 한 번에 기록하느냐에 결정!
따라서 순차 I/O가 랜덤 I/O보다 빠를 수 밖에 없다. 하지만 현실은 대부분 랜덤 I/O이다.
'과연 랜덤I/O를 순차 I/O로 바꿀 수 없을까?' 이런 생각에서 시작되는 데이터베이스 쿼리 튜닝은 랜덤I/O를 줄여주는것이 목적이다.
데이터베이스 시스템
데이터베이스를 이용하여 자료를 저장하여 관리해 정보를 얻어내는데 필요한 컴퓨터 중심의 시스템
데이터베이스 시스템 구성요소
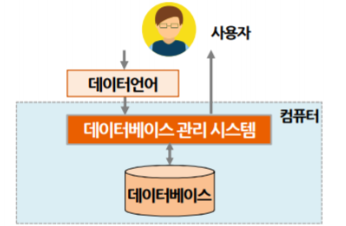
- 데이터베이스
- 스키마
- DBMS
- 데이터베이스 언어
- 데이터베이스 컴퓨터
- 데이터베이스 사용자
DBMS(Database Management System)
데이터 베이스를 관리하고 운영하는 소프트웨어
DB를 사용하기 위해서 소프트웨어, 즉 DBMS를 설치해야하는데 대표적으로 MySQL, Oracle, SQL 서버, MariaDB 등이 있다.
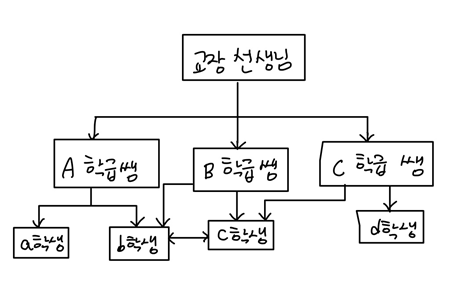
계층형 DBMS(Hierarchical DBMS)
tree 형태
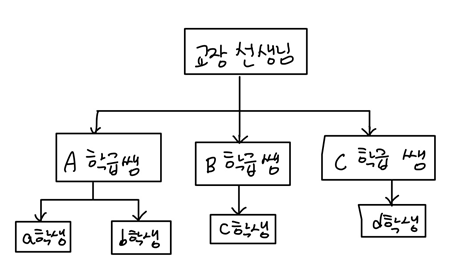
처음 구성을 완료한 후 변경이 까다롭다.
다른 구성원을 찾아가는 것이 비효율적이다. 예) b학생에서 c학생으로 연결하려면, A학급쌤 -> 교장선생님 -> B학급쌤 -> c학생과 같이 여러 단계를 거쳐야 한다.
지금은 사용하지 않는다.
망형 DBMS (Network DBMS)
계층형 DBMS의 문제점 개선
하위의 구성원끼리도 연결된 유연한 구조
이를 잘 활용하려면 프로그래머가 모든 구조를 이해해야만 프로그램 작성이 가능하다는 단점
지금은 거의 사용하지 않는다.
관계형 DBMS (Relation DBMS)
RDBMS
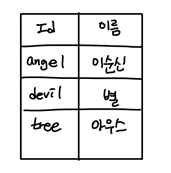
대부분의 DBMS가 이 형태로 사용 된다.
테이블이라는 최소 단위로 구성되며, 이 테이블은 하나 이상의 열과 행으로 이루어져 있다.
모든 데이터가 테이블에 저장된다.
SQL(Structured Query Language)
관계형 데이터베이스에서 사용되는 언어
데이터 언어
DDL(데이터 정의어)
데이터베이스 구조, 데이터 형식, 접근 방식 등을 설정
데이터베이스 논리적,물리적 구조 정의 및 변경 및 스키마 제약조건 정의
- Create, Alter, Drop...
DML(데이터 조작어)
데이터 처리를 위해 사용자와 DBMS 사이의 인터페이스를 위한 언어
데이터의 검색, 삽입, 삭제, 갱신
- Select, Insert, Delete, Update ...
DCL(데이터 제어어)
데이터 보안 : 권한이 없는 접근으로부터 DB 보호
데이터 무결성 : 사용자가 제약 조건을 정의하면 데이터 삽입, 갱신, 삭제마다 검사
데이터 회복 : 시스템 오류로부터 데이터베이스 회복
병행 제어 : 여러 사용자가 동시에 DB를 공유하도록 지원
- Grant, Revoke, Commit, Rollback ...
스키마
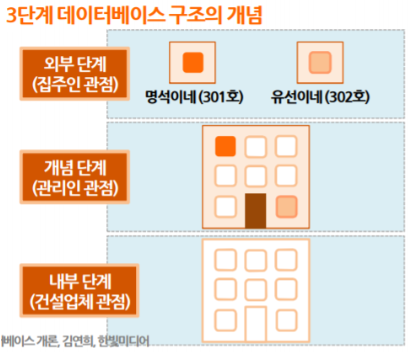
외부 스키마(서브 스키마)
DB 사용자 그룹별 뷰 기술. 즉, 개개인 사용자가 보는 개인적 DB 스키마
사용자 그룹이 관심있는 DB 부분만 기술하고 나머지 DB 부분은 감춘다.
하나의 DBMS에는 여러개의 외부 스키마 존재
사용자나 응용 프로그래머에 의해 정의
개념 스키마
DB에 저장되는 데이터와 그들간의 관계를 표현하는 스키마
외부 스키마의 각 뷰들을 통합한 전체적인 DB의 개념적 묘사
하나의 DBMS에 하나만 존재
DB관리자에 의해 정의
제약 조건, 접근 권한, 보안 정책, 무결성 규정에 관한 명세 정의
내부 스키마
DB의 물리적 구조 정의
물리적 장치에서 데이터가 실제적으로 저장되는 방법을 표현하는 스키마
물리적 저장장치의 시점으로 단 하나만 존재
시스템 프로그래머나 시스템 설계자에 의해 설계
사상(Mapping)
상호 독립적인 개념을 연결시켜주는 다리
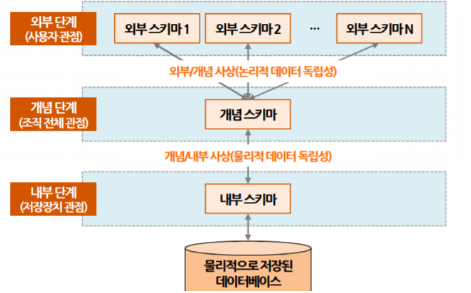
외부적/개념적 사상 = 논리적 사상
응용 인터페이스
외부 화면이나 사용자에게 인터페이스를 제공하기 위한 외부 스키마는 전체가 통합된 개념적 스키마와 연결된다
개념적/내부적 사상 = 물리적 사상
저장 인터페이스
통합된 개념적 스키마 구조와 물리적으로 저장된 구조의 물리적인 테이블 스페이스와 연결되는 구조
