결론부터 살펴보겠습니다.
ThreadLocalRandom을 써야 하는 이유
java.util.Random
멀티 쓰레드 환경에서 하나의 인스턴스에서도 전역적으로 의사 난수(pseudo random)를 반환합니다. 따라서 같은 시간에 동시 요청이 들어올 경우 경합 상태에서 성능에 문제가 생길 수 있습니다.
java.util.concurrent.ThreadLocalRandom
java.util.Random를 상속하여 멀티 쓰레드 환경에서 서로 다른 인스턴스들에 의해 의사 난수를 반환하므로 동시성 문제에 안전합니다.
- 의사난수
: 처음에 주어지는 초기값을 이용하여 이미 결정되어 있는 메커니즘(의사 난수 생성기)에 의해 생성되는 수- 경합 상태
: 다중 프로그래밍 시스템 또는 다중 처리기 시스템에서 두 명령어가 동시에 같은 기억 장소에 접근하려고 하는 상황. 이 두 개의 명령어는 내부적으로 몇 개의 마이크로 명령어로 세분되는데, 이 명령어들이 뒤섞여 수행되면 이 두 개의 명령어 수행 결과를 예측할 수 없게 된다. 따라서 이러한 경쟁 현상을 방지하기 위하여 상호 배제 방법을 사용하여 경쟁 상태에 있는 연산이 순서대로 실행되도록 하여야 한다.
: 여러 스레드 간에 공유되는 변수의 예기치 않은 값이 발생할 수 있다.
Java가 난수를 생성하는 원리 (Random)
기본적으로 컴퓨터는 수학적으로 완전한 난수를 생성할 수 없다. 컴퓨터는 동일 입력에 동일 출력이 보장되어야 하기 때문입니다.
따라서 Java와 같은 언어는 시드(Seed)와 그에 해당하는 난수의 대응으로 난수를 결정합니다. 해쉬 함수의 원리와 유사하다고 생각하면 됩니다. 이는 같은 시드가 주어질 경우 생성되는 난수는 같다는 것을 의미하고, 설계적으로 의도한 난수 생성을 위해서는 서로 다른 시드가 주어져야 한다는 것을 의미합니다.
Java는 Seed를 지정하지 않으면, 컴퓨터의 현재 시간을 이용하여 난수에 대응합니다.
🧐 코드를 살펴보겠습니다.
java.util.Random 코드
1.

이 코드는 Random 클래스의 생성자입니다.
- seedUniquifier() 메소드가 호출되며, 고유한 값(시드 값)을 생성하고 반환합니다.
- System.nanoTime() 메소드는 현재 시간을 나노초 단위로 반환합니다.
seedUniquifier() ^ System.nanoTime(): seedUniquifier() 메소드에서 반환된 값과 System.nanoTime()에서 반환된 값을 XOR 연산합니다.- XOR 연산의 결과는 Random 클래스의 다른 생성자에게 전달됩니다. 이렇게 하여 랜덤 객체의 초기 시드 값이 설정됩니다.
이 코드가 랜덤 객체의 초기 시드 값을 더 유니크하게 만들어줍니다.
- XOR (exclusive OR)
비트 연산자입니다. 이 연산자는 두 비트가 서로 다를 때 결과 비트를 1로 설정합니다.
위 코드에서 XOR 연산 과정
실제로 seedUniquifier() 메소드와 System.nanoTime() 메소드는 1 또는 0이 아닌, 더 큰 숫자 값을 반환합니다. XOR 비트 연산은 이런 더 큰 정수 값에 대해서 비트 단위로 수행됩니다.
정수는 이진수로 표현될 수 있고, 이진수는 0과 1로 구성된 비트의 시퀀스입니다. XOR 연산은 이러한 비트 단위로 수행되며, 각 비트는 독립적으로 연산됩니다.
예를 들어, 다음과 같이 두 정수가 있다고 가정해 보겠습니다.
seedUniquifier()가 5를 반환하고, 이는 이진수로 101입니다.
System.nanoTime()이 3을 반환하고, 이는 이진수로 011입니다.
이 두 값을 XOR 연산하면 110 (이진수로 6을 나타냅니다)이 됩니다.
이런 방식으로, 두 메소드에서 반환된 두 정수 값은 비트 단위로 XOR 연산되어, 새로운 정수 값을 생성합니다.
2.
두번째 코드를 살펴보겠습니다.
고유한 seed 값을 생성하는데 사용됩니다.
seedUniquifier.get(); : 현재의 seed 값을 가져옵니다.
long next = current * 1181783497276652981L; : 현재의 seed 값에 큰 long 값을 곱하여 새로운 seed 값을 생성합니다. 이 연산은 seed 값을 변조하는데 사용됩니다.
compareAndSet() : seedUniquifier의 현재 값이 current와 같은 경우 next로 값을 설정합니다. 만약 값이 성공적으로 설정되면, true를 반환하고 그렇지 않으면 false를 반환합니다.
return next; : compareAndSet() 메소드가 true를 반환하면, 새로운 seed 값이 반환됩니다. 그렇지 않다면, 루프는 계속됩니다.
위 로직을 통해 여러 스레드에서 안전하게 고유한 seed 값을 생성하고 업데이트합니다. AtomicLong의 compareAndSet() 메소드를 사용하여 이 작업을 원자적으로 수행하고, 여러 스레드가 동시에 같은 seed 값을 가져오지 않도록 합니다.
3.
마지막 코드를 살펴보겠습니다.
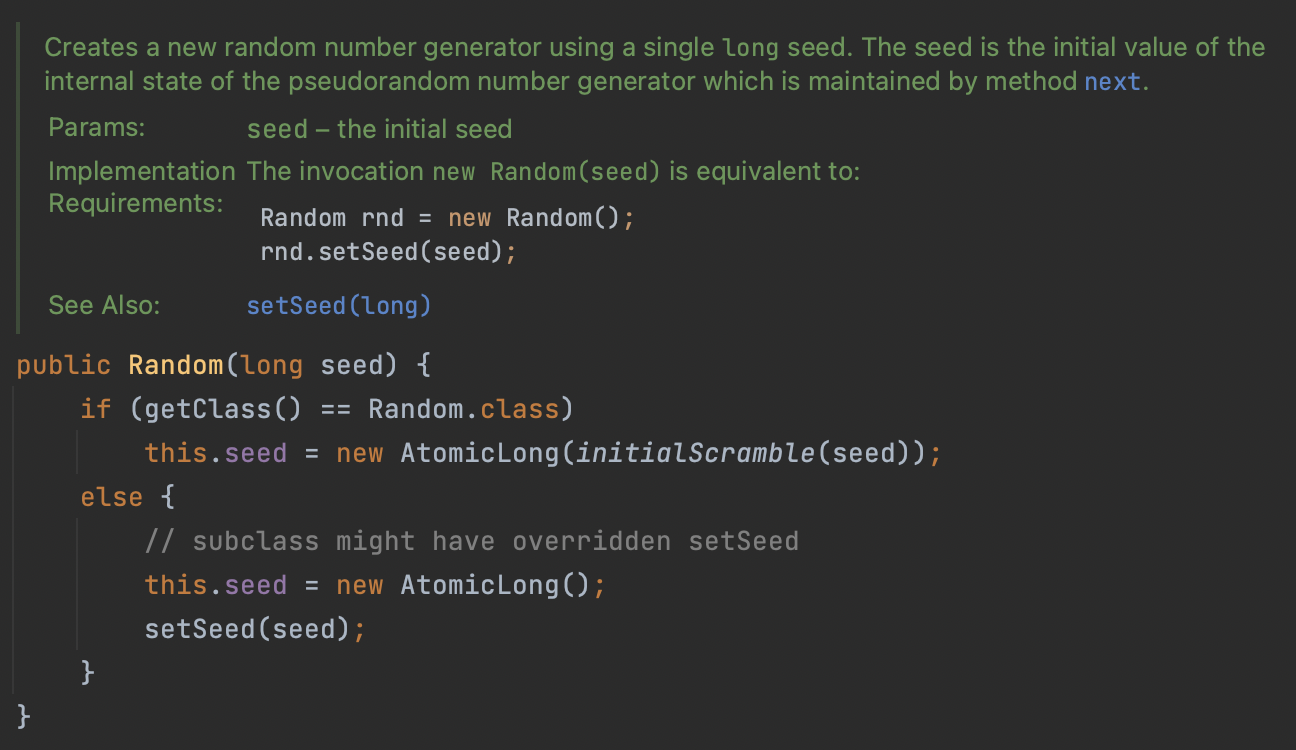
매개변수로 long 타입의 seed 값을 받습니다. 이 값은 난수 생성의 초기 시드 값으로 사용됩니다.
현재 객체의 클래스가 Random 클래스인지 Random의 하위 클래스인지 확인합니다.
만약 객체가 Random 클래스의 인스턴스라면, seed 값은 initialScramble(seed) 메소드를 통해 변조됩니다. 변조된 시드 값은 AtomicLong 객체로 감싸져, 저장됩니다.
만약 객체가 Random의 하위 클래스인 경우, 새로운 AtomicLong 객체가 생성되어 this.seed에 할당됩니다.
즉, Random 객체를 초기화하고 시드 값을 설정하는 역할을 합니다.
- AtomicLong
: Long 자료형을 갖고 있는 Wrapping 클래스이다.
Thread-safe로 구현되어 멀티쓰레드에서 synchronized 없이 사용할 수 있다.
Random이 멀티 쓰레드에서 위험한 이유
java.util.Random은 멀티 쓰레드에서 하나의 Random 인스턴스를 공유하여 전역적으로 동작합니다.
이때 같은 nanoTime에 멀티 쓰레드에서 요청이 들어오면 어떻게 될까? 같은 난수를 반환할까요? 🧐
다행히 그렇게 동작하지는 않습니다.
Random의 의사 난수 생성은 선형 합동 생성기(Linear Congruential Generator)알고리즘으로 동작하는데, 하나의 쓰레드가 동시 경합에서 이기면 다른 쓰레드는 자신이 이길 때까지 계속 같은 동작을 반복하며 경합합니다.
이 함수는 주어진 비트 수에 대해 다음 랜덤 값을 생성하는 역할을 합니다.
AtomicLong seed = this.seed; : 현재 객체의 seed 필드를 가져와서 로컬 변수 seed에 할당합니다.
do-while 루프는 새로운 seed 값을 계산하고 업데이트하는 작업을 원자적으로 수행합니다.
seed.compareAndSet(oldseed, nextseed) : 현재 seed 값이 oldseed와 동일한 경우 nextseed로 업데이트합니다. 만약 업데이트에 성공하면 true를 반환하고, 그렇지 않으면 false를 반환합니다.
이 메소드는 주어진 비트 수에 대해 새로운 랜덤 값을 생성하고 seed 값을 안전하게 업데이트하는 역할을 합니다. AtomicLong의 compareAndSet 메소드를 사용하여 멀티스레드 환경에서도 seed 값이 안전하게 업데이트되도록 합니다.
이때 이 과정을 여러 쓰레드가 동시에 '경합 - 패배 - 재도전'을 반복할 경우, 성능상의 심각한 문제가 발생할 수 있습니다.
ThreadLocalRandom을 써야하는 이유
java.util.concurrent.ThreadLocalRandom은 똑같이 Random API의 구현체이며, java.util.Random를 상속받습니다.
ThreadLocalRandom은 위의 동시성 문제를 해결하기 위해 각 쓰레드마다 생성된 인스턴스에서 각각 난수를 반환합니다. 따라서 Random과 같은 경합 문제가 발생하지 않아 안전하며, 성능상 이점이 있습니다. Random대신 ThreadLocalRandom을 쓰도록 합시다!
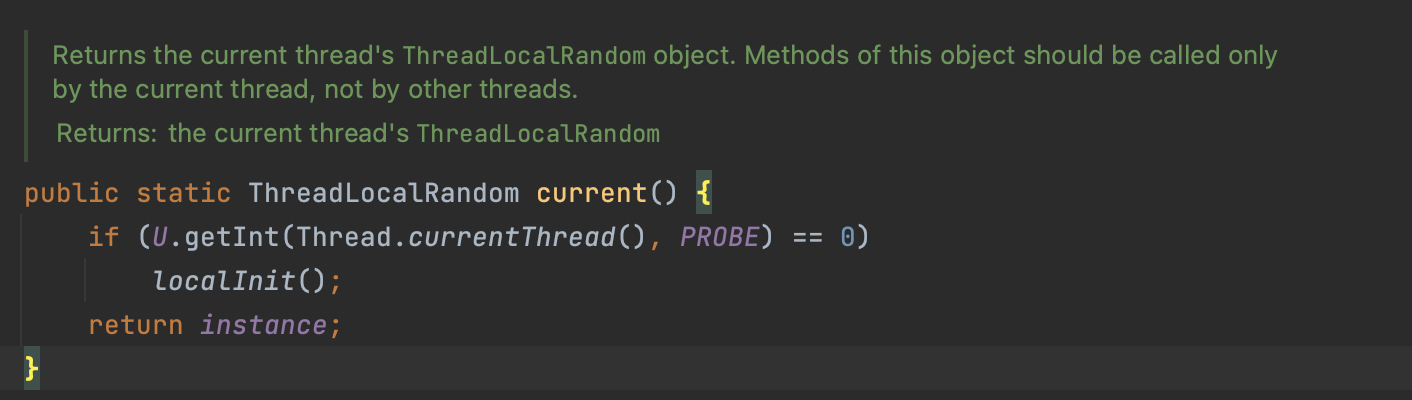
if (U.getInt(Thread.currentThread(), PROBE) == 0) localInit();
: U.getInt(Thread.currentThread(), PROBE)는 현재 스레드에 연결된 특정 값(여기서는 PROBE)을 가져옵니다.
: 가져온 값이 0이면, localInit() 메소드가 호출돼, 현재 스레드에 필요한 초기화 작업을 수행합니다.
return instance;
: instance는 ThreadLocalRandom 인스턴스를 참조하는 변수입니다.
이 인스턴스를 반환하여, 호출자가 현재 스레드의 ThreadLocalRandom 인스턴스를 사용할 수 있도록 합니다.
이 current() 메소드는 현재 스레드에 대한 ThreadLocalRandom 인스턴스를 반환하는 역할을 하며, 필요한 경우 초기화 작업도 수행합니다. 이 방법을 통해, 각 스레드는 자체 ThreadLocalRandom 인스턴스를 안전하게 사용할 수 있습니다.
