이 내용은 일반적인 chat app의 시스템 디자인이라고 볼 수 있다.
<기능>
- 1:1 채팅
- 그룹 채팅
<메시지 앱의 트래픽 특성>
-> 어떤 데이터베이스 사용할지 결정하는데 중요함
- 엄청난 양의 트래칙 그룹 채팅 : 하루에 600억 메시지
- 오래된 채팅 잘 안봄
- Read / Write 비율 1:1
1:1 채팅
유저 A가 유저 B에게 메시지를 보내는 경우
'A -> backend -> B'
- 클라이언트와 서버는 어떻게 이야기 해야할까? HTTP?
평소에 HTTP를 많이 사용하는데, HTTP의 문제는 클라이언트만 시작할 수 있는 커넥션이라는 것이다.
A가 메시지 보내고싶을 때 백엔드로 HTTP연결해서 보낼수는 있다.
백엔드가 B한테 HTTP리퀘스트를 못한다.
그럼 A가 B에게 보내고싶을 때, 어떻게 B가 그 사실을 알아차릴 수 있을까?
해결하기 위한 몇가지 옵션이 있다.
- Polling
- Long Polling
- WebSocket
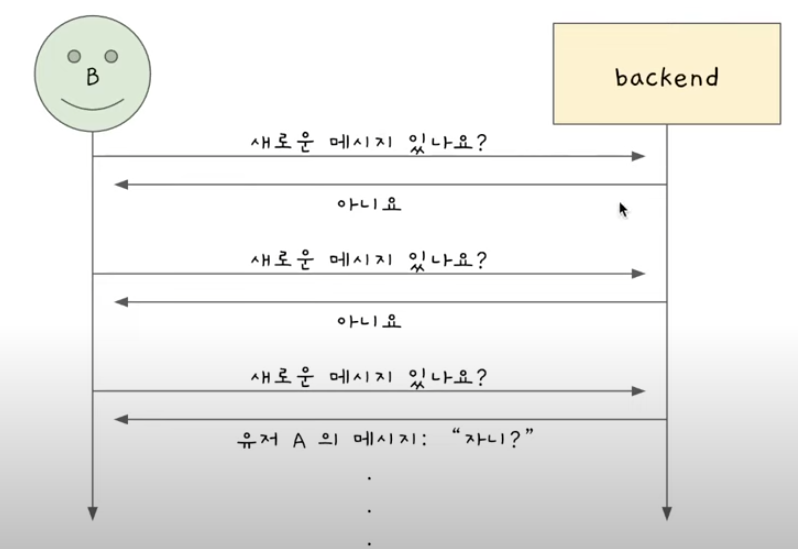
Polling
B가 백엔드한테 새로운 메시지가 있는지 계속 물어보고, 백엔드는 바로 답을 준다.
간격은 마음대로 정할 수 있음
<단점>
-
대부분이 답이 "아니요"일텐데, 리퀘스트를 계속 보내야하므로 리퀘스트 수가 많아진다.
-> 백엔드 인프라스트럭처에 코스트를 높일 수 있다. -
메시지 Latency
-> Polling을 1초마다 한다고 가정하면, B는 A가 보낸 메시지를 1초후에 알 수 있다.
Long Polling
새로운 메시지가 있는지 계속 서버에게 물어보며, 백엔드는 메시지가 있거나 타임아웃 할 때까지 리퀘스트를 잡고있는다.
예를 들어, 백엔드에게 물어봤는데 만약 메시지가 아직 없다면 백엔드가 없다고 응답하지않고 계속 기다린다.
타임아웃을 정해놓고 타임아웃이 될 때까지 기다렸는데도 아무것도 없으면 백엔드가 타임아웃이라고 리스폰스를 보내준다. 이를 받으면 다시 바로 서버에게 새로운 메시지가 있는지 물어본다.
만약 타임아웃되기전에 메시지가 오면 메시지를 리스폰스로 보내준다.
<단점>
- 폴링에 비교하면 리퀘스트 수가 어들지만, 결국 비슷한 테크닉이기 때문에 리퀘스트 수가 많은게 단점이다.
- 메시지 Latency
-> Polling보다 낫겠지만, 유저 A,B가 실시간으로 메시지를 막 주고받는 상황이라면 이게 단점이 될 수 있다.
Web Socket
HTTP는 리퀘스트가 있으면 리스폰스를 받고 끝인데, Web Socket은 오픈 커넥션을 유지한다.
클라이언트와 서버 사이에 Web Socket으로 Connect를 하고나면 오픈 커넥션이 유지된다.
오픈 커넥션이 유지되면 양방향 소통이 가능하다.
1:1 채팅
Web Socket으로 커넥션한다고 가정하고 시스템 디자인을 해보자.
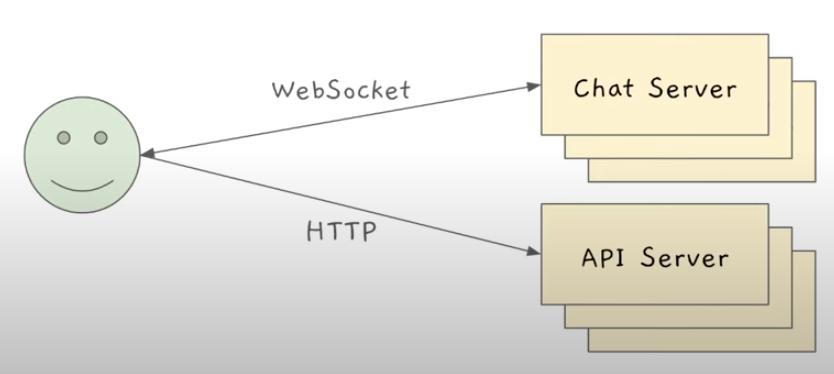
- HTTP 리퀘스트들은 올 때마다 서버가 핸들해서 보내주면 되는데, Web Socket은 오픈 커넥션을 유지해야하기 때문에, 이 오픈 커넥션을 유지해야 될 서버들을 따로 Chat Server로 만들어서 관리하는게 좋다.
- 일반적인 리퀘스트들 (로그인, 프로필 사진 바꾸기...)은 API Server에서 HTTP로 관리
모든것을 다 Web Socket으로 할 필요는 없다.
잠시 메시지 큐에 대해 알아보자!
메시지 큐 (Message Queue) 란?
- Kafka, RabbitMQ : 메시지 큐 예
- 서비스들 간에 데이터를 주고 받는 방법 중 하나
- 메시지 큐를 사용하지않고 두 서비스간 이야기하는 방법 : RestAPI / RPC를 사용하면 Synchronous하게 데이터를 주고 받음
-> Service A가 Service B에게 필요할 게 있을 때, RestAPI 나 RPC 콜을 사용해서 Service B한테 리퀘스트를 보내면 Service B가 처리해서 바로 리스폰스를 synchronous하게 준다. - 메시지 큐를 사용하면 Asynchronous하게 데이터를 처리할 수 있다.
메시지 큐에는 2가지 Entity가 있다.
- Publisher : 어떤 이벤트가 일어났을 때, 이벤트를 메시지 큐에 넣는 사람 (이벤트가 일어났다고 메시지큐에게 알려줌)
- Subscriber : '이벤트가 일어나면 나한테 알려줘'하고 메시지 큐한테 Subscribe하고 있는 서비스들
아래 예시를 보자.
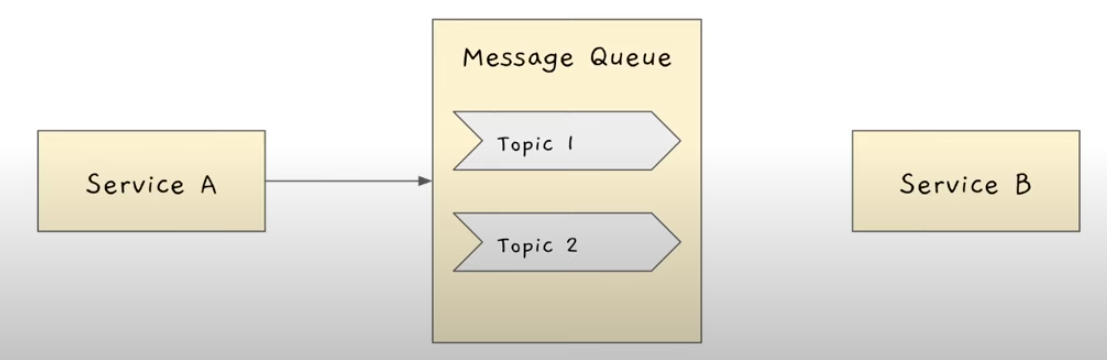
위 예시에서는 Service A가 Publisher이며, Service B가 Subscriber이다.
-
Service A가 지금 이 이벤트가 일어났다며 메시지 큐에게 알려줌
-
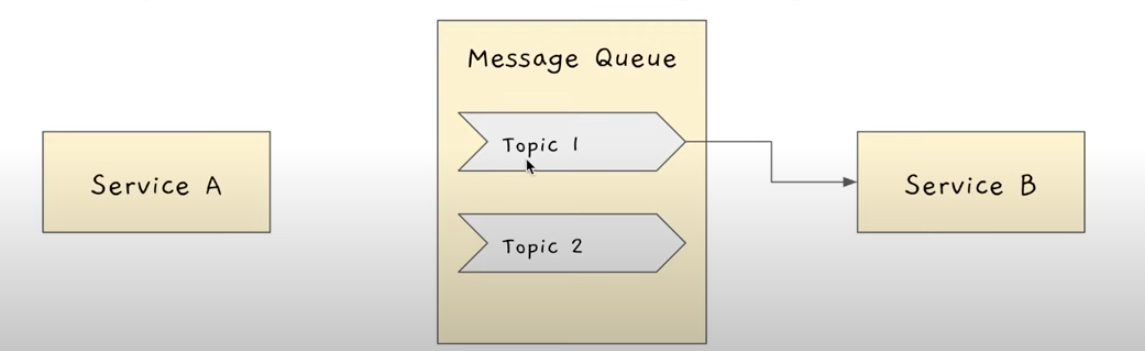
메시지 큐가 해당 이벤트에 Subscribe하고 있었던 모든 서비스들에게 알려줌.
"지금 Topic1에 관련된 이벤트가 새로 들어왔으니까 처리해"
메시지 큐를 왜 쓰냐?
<장점>
- Decoupling
시스템에 마이크로 서비스들이 많아지다보면 Service A에서 어떤 이벤트가 일어났을 때, 거기에 Depend하는 서비스가 많을 수 있다.
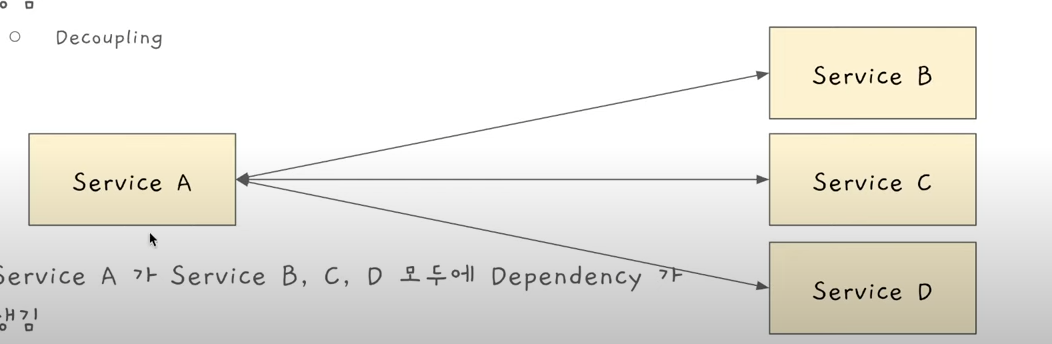
예를 들어,유저가 메시지를 보냈다고 가정해보자.
새로운 메시지가 왔을 때, 이걸 데이터베이스에 저장해야하고 이 메시지를 받는 유저한테 메시지를 포워드 해줘야하고, 만약 받는 유저가 지금 로그인하고있지 않다면 푸쉬 알림을 보내줘야하고, 어떤 경우에는 이메일을 보내줘야하고 ...
여러 의존이 있을 수 있는데, 이걸 Rest API나 RPC 콜로 Synchronous하게 하다보면 그 모든 디펜던시 관련된 코드를 Service A에 넣어야한다.
그러면 Service A가 점점 복잡해지고 테스트하기도 어려워지고, 디펜던시가 많아진다. ('커플링이 많다'라고 이야기하기도 한다) -> 시스템 디자인할 때 좋지않은것이다.
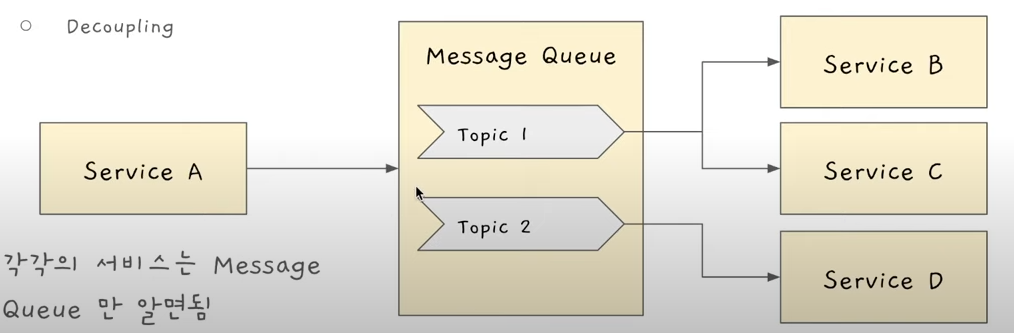
이럴 때 메시지큐를 이 사이에 집어넣으면 디펜던시가 적어진다.
왜냐하면 Service A는 Service B, C, D가 존재한다는 사실을 알 필요가 전혀 없다.
-
그냥 새로운 유저가 메시지를 새로 보내려하면, 메시지 큐에 알려주고 Service A는 끝이다.
-> Service A는 디펜던시가 하나밖에 없는것이다. -
Service B, C, D는 그 이벤트들에 Listen(Subscribe)을 하고있으면 메시지 큐가 알려준다.
-> "유저 A가 유저 B한테 메시지 보내고 싶대 너희들 할거 해"
-> 예를 들어, Service B가 DB에 저장하고,
-> Service C가 푸시 알림을 보내고,
-> Service D가 유저한테 메시지 포워드를 해주는 등...
똑같은 일을 해도 이 경우에는 Service A가 Service B, C, D에 대한 디펜던시가 없다.
따라서 디커플링을 하는데 좋다.
자, 다시 1:1 채팅으로 돌아와서 계속 알아보자.
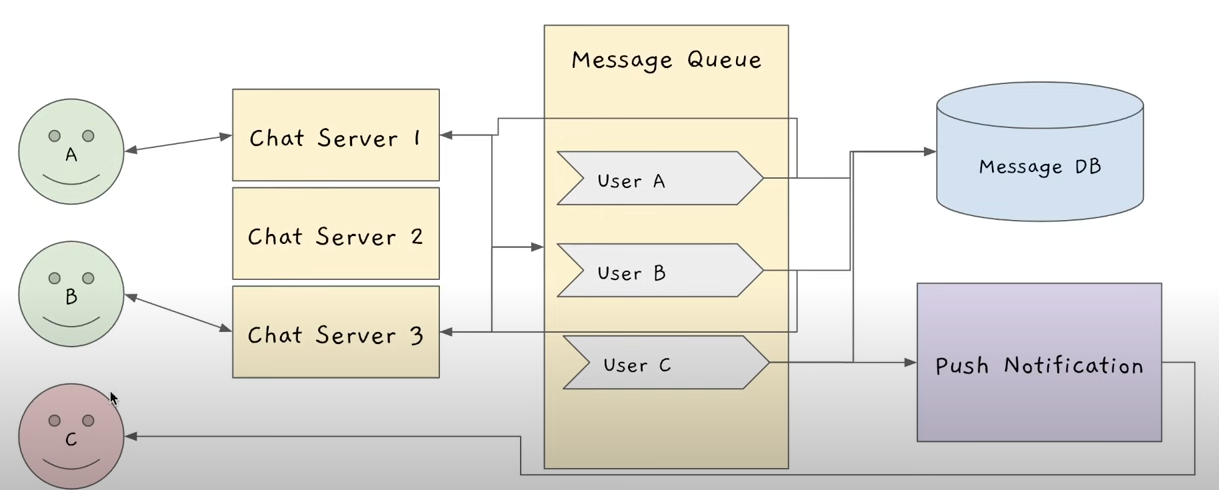
-초록색 유저 : 로그인 한 유저
-빨간색 유저 : 로그아웃 되어있는 유저
로그인 되어있는 유저들은 Chat Server하고 각각 Web Socket으로 오픈 커넥션이 있는 것.
유저A가 유저B한테 메시지를 보내는 상황을 가정해보자.
- 유저 A가 메시지를 써서 보내기를 누른다.
- User A와 WebSocket으로 커넥션 되어있는 chat Server에게 보낸다.
- chat Server가 User B의 큐에 메시지를 넣어준다.
- 이 큐에 Subscribe하고있었던 서비스들한테 알림이 간다.
-> Chat Server 3이 메시지 큐 User B에 Subscribe하고있는데, Chat Server 3에게 새로운 메시지가 왔다는 신호를 메시지 큐가 준다. Chat Server3이 메시지를 User B에게 포워드해주면 유저 B가 메시지를 받게된다.
-> Message DB한테도 새로운 메시지가 왔다는 신호를 준다. DB는 그걸 처리해서 메시지를 저장한다.
데이터베이스는 어떤걸 사용할까?
DB를 그냥 DB로 보고 넘어왔는데, 어떤 DB를 사용하는것이 굉장히 중요하다.
DB를 잘 선택하기 위해서는 트래픽 특성이 중요하다.
<트래픽 특성>
- 엄청난 양의 트래픽 그룹 채팅 - 하루에 600억 메시지
- 오래된 채팅 잘 안봄
- Read / Write 비율 1:1
-> Read, Write 둘 다 효율적으로 되어야한다는 이야기
DB를 잘 선택하기 위해 다른 정보들도 살펴보자.
- 다른 데이터들과 join할 필요가 거의 없다.
- Relational Database 같은 경우 데이터가 많아지고 index가 많아지면 느려진다.
-> 우리같은 경우는 다른 테이블과 조인필요가 많이 없기때문에 Relational Database의 강점이 많이 필요없다.
따라서 Key Value Store을 사용하자!
Key Value Store
- 스케일 하기가 편함
- Read Latency가 낮음
- Facebook 같은 경우 HBase, 디스코드는 Cassandra를 사용
주의해야할 점!
메시지의 Key를 만들 때, Range Scan하기 쉽게 디자인해야한다.
- 최근에 보낸 메시지일수록 Key값이 높게.
-> chat은 시간 순서대로 읽어야 할 경우가 많다. 따라서 Key Range Scan했을 때 채팅된 순서대로 메시지가 나올 수 있게 Key를 디자인
그룹 챗 기능 추가
- 그룹 챗 몇명까지 지원할건지에따라 디자인이 달라질 수 있음
- 그룹 챗 최대 200명까지 지원한다고 가정해보자.
-> 어느정도 Fan-out은 괜찮을것이다.
유저 A가 유저 A,B,C가 있는 그룹챗에서 메시지를 보낸다는 걸 가정해보자.
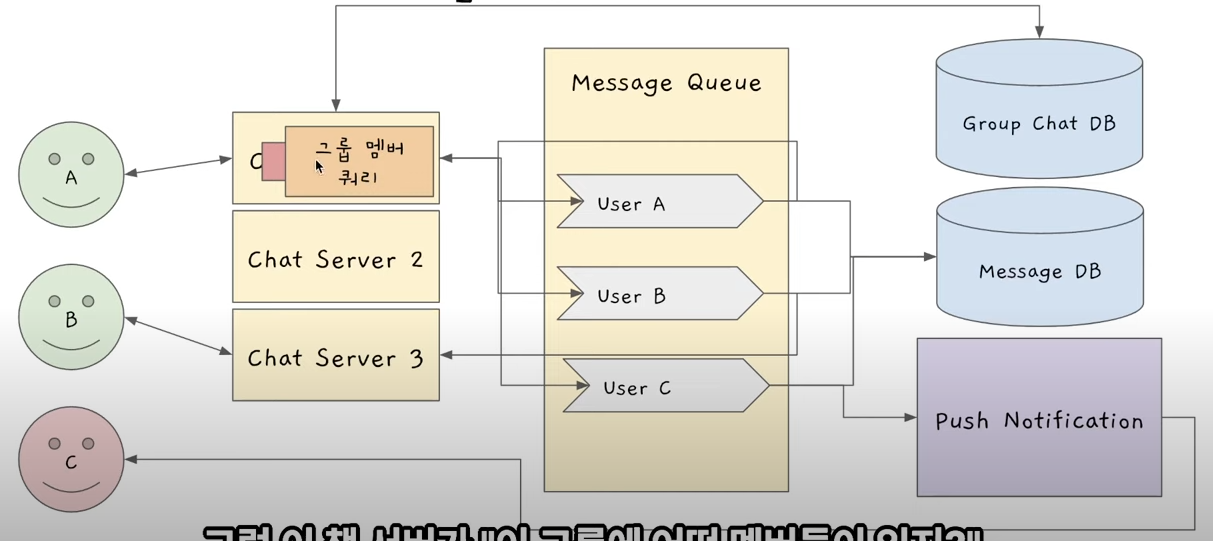
- 유저 A가 chat Server1에 메시지를 보낸다.
- chat Server1이 "이 그룹에 어떤 멤버들이 있지?"를 Group Chat DB에 물어본다.
DB에 그룹 멤버 쿼리를 보냈다가 받아 그룹 멤버들을 알게된다.
(Group Chat DB는 Relational DB가 될 수도 있다) - 받아야 할 유저들의 메시지 큐에 해당 메시지를 넣어준다.
(이 상황같은 경우에는 chat Server가 직접 2개를 넣어준다.)
여기서 Fan out이 발생하는데, 지금은 200명 제한이라 괜찮지만 엄청 큰 규모라면 이 Fan out이 좋지않을 수 있다. - 이후는 1:1 채팅과 동일하다.
