트위터 앱은 하루에 1억 3천만명이 이용
❓어떻게 시스템 디자인을 했길래 그 많은 유저들이 느리다고 느끼지 않을까?
좋은 시스템 디자인을 하기위해!
- 앱의 트래픽 특성 이해하는게 중요
예) 트위터 트래픽 특성
트위터는 대표적으로 유저들이 할 수 있는 2가지 액션이 있다.
- 트윗 포스트 하기
Write Operation
1초에 12k 리퀘스트 - 피드 보기
Read Operation
1초에 300k 리퀘스트
트위터의 챌린지는 Fan-out에서 온다.
- Fan-out 이란?
한 명의 유저가 여러명의 유저를 팔로우하고 팔로우 받고있는데서 나오는 문제
-> 이 문제를 해결하기위한 시스템 디자인방법 2가지
- 트윗 포스트하는 것을 간단하게 하고, 피드를 만들 때 Fan-out의 복잡성 처리
- 피드 리퀘스트를 간단하게 만들고, 트윗 포스트할 때 Fan-out의 복잡성 처리
그럼 각 방법을 자세히 보자!
방법 1. 트윗 포스트를 간단히
-
트윗 포스트
leo가 새로 포스트를 쓴다면?
아래 이미지 처럼 새로운 트윗에 대해 Tweet Table에 데이터가 새로 추가된다
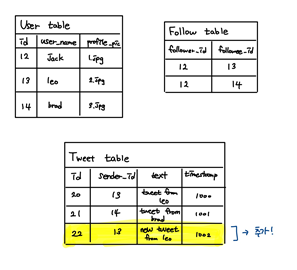
-
피드 리퀘스트는 어떻게 핸들되냐?
jack이 리퀘스트라면
jack이 팔로우하고 있는 유저들의 트윗을 조인해서 피드 작성 -> jack에게 보여주기
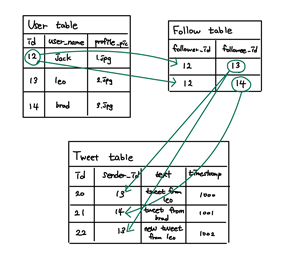
SQL로 쓰면 아래와 같이!

포스트는 간단하지만, 피드 리퀘스트 핸들하는게 약간 복잡
방법 2. 피드 리퀘스트를 간단히
모든 유저의 피드를 Redis같은걸로 항상 캐시해서 관리
- 트윗 포스트
leo가 새로 포스트를 썼다면, Tweet Table에 데이터 추가
Follow table 통해 leo를 팔로우하고있는 유저 알아냄 : user_id = 12
id가 12인 jack의 jack's feed 캐시에 새로 추가된 22번 id의 tweet게시글을 넣어줌
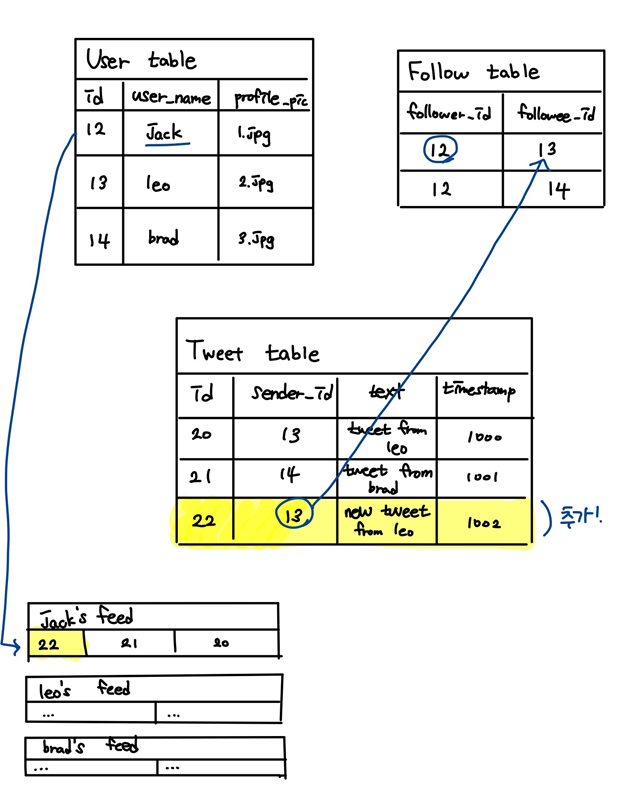
이 모든 과정이 트윗을 포스트 할 때 발생!
- 피드 리퀘스트
jack이 리퀘스트라면
캐시해둔 jack's feed를 그대로 준다.

리퀘스트가 훨씬 쉬워진다!
그래서 트위터는 어떤 방식으로 했을까?
처음에는 방법 1로! : 그게 더 간단(방법2는 캐시관리해야하기때문에)
유저가 많아지며 피드 리퀘스트 로드가 커져서 방법 2로 옮김
-> 트위터의 특성을 보면 말이됨!
피드 리퀘스트가 트윗 포스트 리퀘스트보다 30배정도 더 많음
따라서 트윗 포스트할 때 더 많은 일을 하고, 훨씬 더 자주 일어나는 피드 리퀘스트를 간단하게 만드는 시스템이 더 말이됨
🤔 하지만, 방법 2도 문제가 있다..!
앞서 살펴본 Fan-out문제를 생각해보자.
소수의 트위터 인플루언서들은 엄청난 양의 팔로워를 가지고있음.
예를 들어, 오바마는 1억 3천만명의 팔로워를 가지고있는데, 오바마가 새로운 포스트를 업데이트하면 1억 3천만개의 캐시를 업데이트해줘야함 -> 굉장히 느려질 수 있음 : 인플루언서가 트윗 업로드하는데 5분이 걸릴 수 있음
유저 입장에서는 이상한 현상이 생길 수 있음
- 오바마가 트윗한게 나한테는 아직 안보이는데, 다른 사람한테는 먼저 보일 수 있음
- 다른 사람이 오바마 트윗에 답장하면, 내 입장에서는 오바마 트윗이 아직 안보이는데 답장한 사람의 트윗이 먼저 보이게 되는 경우 발생
-> 이 문제 해결하기 위해 현재 트위터에서는 방법 1,2를 섞은 디자인을 사용중
현재 디자인
인플루언서와 인플루언서가 아닌 사람을 다르게 처리!
우선, User table에 influencer 컬럼 추가
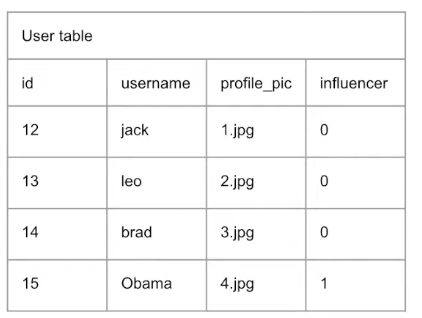
- 트윗 포스트
인플루언서가 아닌 사람이 포스트를 쓰면 방법2와 똑같은 일이 발생
인플루언서가 포스트를 쓰면 해당 포스트데이터를 Tweet table에 한 줄 넣고 끝
- 피드 리퀘스트
jack의 리퀘스트라면
jack's feed + 인플루언서의 Tweet 합쳐서 리턴
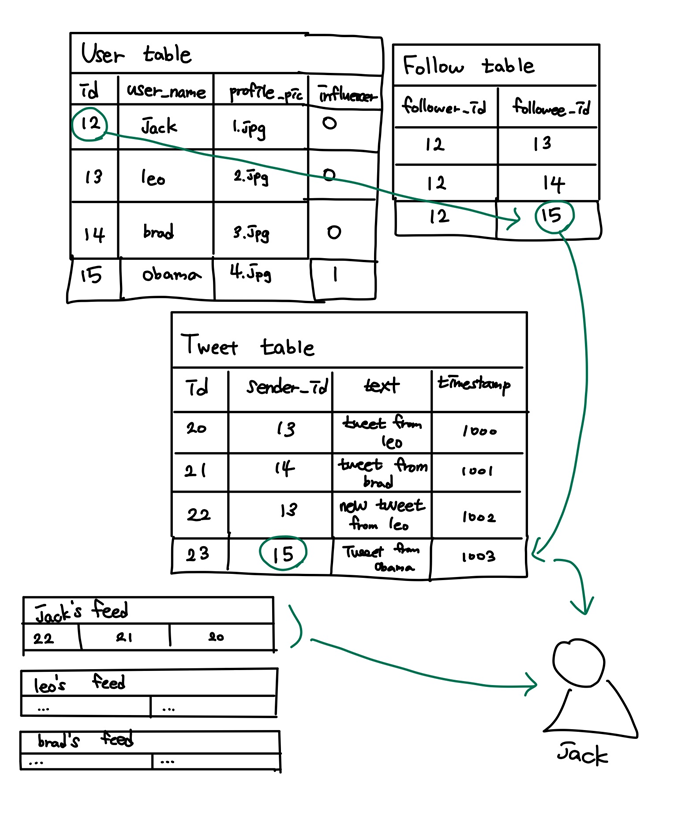
그림은 DB처럼 설명되어있지만, 실제로는 인플루언서들의 트윗을 저장해주는 인메모리가 따로 있을것
중요한점은 인플루언서들의 트윗과 인플루언서가 아닌 사람들의 트윗을 다르게 처리한다는것이다.
