함수란
-
함수
- 미리 정의된 기능을 통해 데이터를 좀 더 편리하게 조작할 수 있도록 도와줌
-
함수를 사용하는 목적
- 데이터 값을 계산하거나 조작함
(단일 행 함수 : 한 번에 하나의 데이터를 처리하는 함수) - 행의 그룹에 대해 계산하거나 요약함
(그룹함수 : 여러 건의 데이터를 동시에 처리하여 해당 그룹에 해당하는 결과를 반환
→ GROUP BY와 주로 쓰임) - 열의 데이터 타입을 변환함 (날짜와 숫자 등 데이터 타입을 상호 변환)
- 데이터 값을 계산하거나 조작함
단일 행 함수 : 데이터 값을 하나씩 계산하고 조작하기
- 데이터 타입의 종류
저장 데이터 데이터 타입 설명 문자 CHAR(n) n 크기만큼 고정 길이의 문자 타입을 저장
최대 2000byte까지 저장 가능문자 VARCHAR2(n) n 크기만큼 가변 길이의 문자 타입을 저장
최대 4000byte까지 저장 가능숫자 NUMBER(p, s) 숫자 타입을 저장 (p : 정수 자릿수, s : 소수 자릿수) 날짜 DATE 날짜 타입을 저장
9999년 12월 31일까지 저장 가능
- 단일 행 함수의 종류
종류 설명 문자 타입 함수 문자를 입력받아 문자와 숫자를 반환한다. 숫자 타입 함수 숫자를 입력받아 숫자를 반환한다. 날짜 타입 함수 날짜에 대해 연산한다.
숫자를 반환하는 MONTHS_BETWEEN 함수를 제외한 모든 날짜 타입 함수는 날짜 값을 반환한다.변환 타입 함수 임의의 데이터 타입의 값을 다른 데이터 값으로 변환한다. 일반 함수 그 외 NVL, DECODE, CASE WHEN, 순위 함수 등
- 문자 함수의 종류
함수 설명 예 결과 LOWER 값을 소문자로 변환 LOWER(’ABCD’) abcd UPPER 값을 대문자로 변환 UPPER(’abcd’) ABCD INITCAP 첫 번째 글자만 대문자로 변환 INITCAP(’abcd’) Abcd SUBSTR 문자열 중 일부분을 선택 SUBSTR(’ABC’, 1, 2) AB REPLACE 특정 문자열을 찾아 바꿈
예를 들어 A를 찾아 E로 변환REPLACE(’AB’, ‘A’, ‘E’) EB CONCAT 두 문자열을 연결 (|| 과 같음) CONCAT(’A’, ‘B’) AB LENGTH 문자열의 길이를 구함 LENGTH(’AB’) 2 INSTR 명명된 문자의 위치를 구함 INSTR(’ABCD’, ‘D’) 4 LPAD 왼쪽부터 특정 문자로 자리를 채움 LPAD(’ABCD”, 6, ‘*’) **ABCD RPAD 오른쪽부터 특정 문자로 자리를 채움 RPAD(’ABCD’, 6, ‘*’) ABCD** LTRIM 주어진 문자열의 왼쪽 문자를 지움 LTRIM(’ABCD’, ‘AB’) CD RTRIM 주어진 문자열의 오른쪽 문자를 지움 RTRIM(’ABCD’, ‘CD’) AB
- employees 테이블에서 last_name을 소문자와 대문자로 각각 출력하고, email의 첫 번째 문자는 대문자로 출력하기
SELECT last_name, LOWER(last_name) LOWER적용, UPPER(last_name) UPPER적용, email, INITCAP(email) INITCAP적용 FROM employees;LAST_NAME LOWER적용 UPPER적용 EMAIL INITCAP적용 1 Abel abel ABEL EABEL Eabel 2 Ande ande ANDE SANDE Sande
-
지정한 길이만큼 문자열 추출하기
SUBSTR('문자열' or 열 이름, 시작 위치, 길이) // 시작 위치 : 추출 시작 자리 위치 // 길이 : 추출할 길이
-
employees 테이블에서 job_id 데이터 값의 첫째 자리부터 시작해서 두 개의 문자를 출력하기
SELECT job_id, SUBSTR(job_id, 1, 2) 적용결과 FROM employees;JOB_ID 적용결과 1 AC_ACCOUNT AC 2 AD_MGR AD
-
특정 문자를 찾아 바꾸기
REPLACE('문자열' or 열 이름, '바꾸려는 문자열', '바뀔 문자열')
-
employees 테이블에서 job_id 문자열 값이 ACCOUNT면 ACCNT로 출력하기
SELECT job_id, REPLACE(job_ic, 'ACCOUNT', 'ACCNT') 적용결과 FROM employees;JOB_ID 적용결과 1 AC_ACCOUNT AC_ACCNT 2 AC_MGR AC_MGR
-
특정 문자로 자릿수 채우기
LPAD('문자열' or 열 이름, 만들어질 자릿수, '채워질 문자') // 만들어질 자릿수 : 숫자 지정 // 채워질 문자 : 1, a, abc, &, * 등
-
employees 테이블에서 first_name에 대해 12자리의 문자열 자리를 만들되 first_name의 데이터 값이 12자리보다 작으면 왼쪽부터 *을 채워서 출력하기
SELECT first_name, LPAD(first_name, 12, '*') LPAD적용결과 FROM employees;FIRST_NAME LPAD적용결과 1 Elen ****Elen 2 David ***David
- employees 테이블에서 first_name에 대해 12자리의 문자열 자리를 만들되 first_name의 데이터 값이 12자리보다 작으면 오른쪽부터 *을 채워서 출력하기
SELECT first_name, RPAD(first_name, 12, '*') RPAD적용결과 FROM employees;FIRST_NAME LPAD적용결과 1 Elen Elen**** 2 David David***
- employees 테이블에서 job_id의 데이터 값에 대해 왼쪽 방향부터 ‘F’ 문자를 만나면 삭제하고 또 오른쪽 방향부터 ‘T’ 문자를 만나면 삭제하기
SELECT job_id, LTRIM(job_id, 'F') LTRIM적용결과, RTRIM(job_id, 'T') RTRIM적용결과 FROM employees;JOB_ID LTRIM적용결과 RTRIM적용결과 AC_ACCOUNT AC_ACCOUNT AC_ACCOUN FI_ACCOUNT I_ACCOUNT FI_ACCOUN
- 공백 제거하기
// TRIP('문자열' or 열 이름) SELECT 'start'||TRIM(' - space - ')||'end' 제거된_공백 FROM dual;
근데 왜 - space - 사이에 있는 공백은 제거되지 않을까? 신기하네제거된_공백 1 start - space -end
글자가 하나라도 들어오면 그 안에 있는 빈칸은 공백으로 인식하지 않는걸까?
→ 놀랍게도 그러했다..
- 숫자 타입 함수의 종류
함수 설명 예 결과 ROUND 숫자를 반올림함
0이 소수점 첫째 자리임ROUND(15.351, 0) 15 TRUNC 숫자를 절삭함
0이 소수점 첫째 자리임TRUNC(15.351, 1) 15.3 MOD 나누기 후 나머지를 구함 MOD(15, 2) 1 CEIL 숫자를 정수로 올림함 CEIL(15.351) 16 FLOOR 숫자를 정수로 내림함 FLOOR(15.351) 15 SIGN 양수(1), 음수(-1), 0인지를 구분하여 출력함 SIGN(15) 1 POWER 거듭제곱을 출력 POWER(2, 3) 8 SQRT 제곱근을 출력 SQRT(4) 2
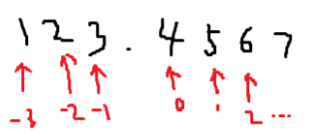
- employees 테이블에서 salary를 30일로 나눈 후 나눈 값의 소수점 첫째 자리, 소수점 둘째 자리, 정수 첫째 자리에서 반올림한 값을 출력하기
SELECT salary, salary/30 일급, ROUND(salary / 30, 0) 적용결과0, ROUND(salary / 30, 1) 적용결과1, ROUND(salary / 30, -1) 적용결과MINUS1 FROM employees;SALARY 일급 적용결과0 적용결과1 적용결과MINUS1 1 17000 566.6666667 567 566.7 570
- 숫자 절삭하기
TRUNC(숫자 or 열 이름, 절식할 자리 값) // 절식할 자리 값은 음수에서 양수까지 지정 // 0이 소수점 첫째 자리를 의미
- employee 테이블에서 salary를 30일로 나누고 나눈 값의 소수점 첫째 자리, 소수점 둘째 자리, 정수 첫째 자리에서 절삭하여 출력하기
SELECT salary, salary / 30 일급, TRUNC(salary/30, 0) 적용결과0 TRUNC(salary/30, 1) 적용결과1 TRUNC(salary/30, -1) 적용결과MINUS1 FROM employees;SALARY 일급 적용결과0 적용결과1 적용결과MINUS1 1 17000 566.666666 566 566.6 560
-
날짜 연산 규칙
-
날짜에 숫자를 더하거나 빼면 날짜 결과를 출력함
-
날짜에서 날짜를 배면 두 날짜 사이의 일수가 출력됨
-
날짜에 시간을 더하거나 빼려면 시간을 24로 나누어서 더하거나 뺌
날짜 연산 설명 반환값 Date + Num 날짜에 일수를 더함 Date Date - Num 날짜에 일수를 뺌 Date Date - Date 날짜에서 날짜를 뺌 일수 Date + Number / 24 날짜에 시간을 더할 때는 시간을 24로 나누어서 날짜에 더함- Date
-
-
오늘 날짜와 시간, 오늘 날짜에서 1을 더한 값, 1을 뺀 값, 2017년 12월 2일에서 2017년 12월 1일을 뺀 값
SELECT TO_CHAR (SYSDATE, 'YY/MM/DD/HH24:MI') 오늘날짜, SYSDATE + 1 더하기1, SYSDATE - 1 빼기1, TO_DATE('20171202') - TO_DATE('20171220') 날짜빼기, SYSDATE + 13/24 시간더하기 FROM DUAL;오늘날짜 더하기1 빼기1 날짜빼기 시간더하기 1 17/10/04/11:00 17/10/05 17/10/03 1 17/10/05
-
날짜 함수의 종류
날짜 함수 설명 예 결과 MONTHS_BLETWEEN 두 날짜 사이의 월 수를 계산 MONTHS_BETWEEN(SYSDATE, HIRE_DATE) 171.758 ADD_MONTHS 월을 날짜에 더한다 ADD_MONTHS(HIRE_DATE, 5) 03/11/17 NEXT_DAY 명시된 날짜부터 돌아오는 요일에 대한 날짜를 출력한다
(SUNDAY:1, MONDAY:2 …)NEXT_DAY(HIRE_DATE, 1) 03/06/22 LAST_DAY 월의 마지막 날을 계산 LAST_DAY(HIRE_DATE) 03/06/30 ROUND 날짜를 가장 가까운 연도 또는 월로 반올림 ROUND(HIRE_DATE, ‘MONTH’) 03/07/01 TRUNC 날짜를 가장 가까운 연도 또는 월로 절삭 TRUNC(HIRE_DATE, ‘MONTH’) 03/06/01
-
두 날짜 사이의 개월 수 계산하기
MONTHS_BETWEEN(날짜, 날짜)
-
employees 테이블에서 department_id가 100인 직원에 대해 오늘 날짜, hire_date, 오늘 날짜와 hire_date 사이의 개월 수를 출력하기
SELECT SYSDATE, hire_date, MONTHS_BETWEEN(SYSDATE, hire_date) 적용결과 FROM employees WHERE department_id = 100; // MONTHS_BETWEEN 함수를 사용할 때 큰 날짜가 앞에 위치해야 결과가 정수 이상으로 출력됨SYSDATE HIRE_DATE 적용결과 1 17/10/04 02/08/17 181.599152 2 17/10/04 02/08/16 181.631411
-
월에 날짜 더하기
ADD_MONTHS(날짜, 숫자)
-
employees 테이블에서 employee_id가 100과 106 사이인 직원의 hire_date에 3개월을 더한 값, hire_date에 3개월을 뺀 값을 출력하기
SELECT hire_date, // (3) 해당 내용 출력하기 ADD_MONTHS(hire_date, 3) 더하기_적용결과, ADD_MONTHS(hire_date, -3) 빼기_적용결과 FROM employees // (1) employees 테이블에서 WHERE employee_id BETWEEN 100 AND 106; // (2) employee_id가 100 ~ 106인 데이터 중에HIRE_DATE 더하기_적용결과 빼기_적용결과 1 03/06/17 03/09/17 03/03/17 2 05/09/21 05/12/21 05/06/21
- 돌아오는 요일의 날짜 계산하기
NEXT_DAY(날짜, '요일' or 숫자) // 요일은 '일요일', '월요일'과 같이 기술하거나 1(일요일), 2(월요일)과 같이 기술할 수도 있음
-
employees 테이블에서 employee_id가 100과 106 사이인 직원의 hire_date에서 가장 가까운 금요일의 날짜가 언제인지 문자로 지정해서 출력하고, 숫자로도 지정해서 출력하기
SELECT hire_date, NEXT_DAY(hire_date, '금요일') 적용결과_문자지정, NEXT_DAY(hire_date, 6) 적용결과_숫자지정, FROM employees WHERE employee_id BETWEEN 100 AND 106;HIRE_DATE 적용결과_문자지정 적용결과_숫자지정 1 03/06/17 03/06/20 03/06/20 2 05/09/21 05/09/23 05/09/23
-
돌아오는 월의 마지막 날짜 계산하기
LAST_DAY (날짜)
-
employees 테이블에서 employee_id가 100과 106 사이인 직원의 hire_date를 기준으로 해당 월의 마지막 날짜를 출력하기
SELECT hire_date, LAST_DAY(hire_date) 적용결과 FROM employees WHERE employee_id BETWEEN 100 AND 106;HIRE_DATE 적용결과 1 03/06/17 03/06/30 2 01/01/13 01/01/31
- 날짜를 반올림하거나 절삭하기
// ROUND : 지정된 값을 기준으로 반올림하는 함수 // TRUNC : 지정 값을 기준으로 월 또는 연도로 절삭하는 함수 // ROUND 함수를 사용하면 날짜를 가장 가까운 월 또는 연도로 반올림할 수 있음 // 예를 들어 2017년 10월 4일에 대해 값을 'MONTH'로 지정하면 10월 31일 기준 // 총 날짜 개수인 31의 절반에 미치지 못하기 때문에 2017년 10월 1일이 출력됨 // 2017년 10월 16일은 절반이 넘기 때문에 2017년 11월 1일이 출력됨 // 즉, 기준 날짜(MONTH)의 하위 단계에서 따져보면 이해하기 쉬움 ROUND(날짜, 지정 값) TRUNC(날짜, 지정 값)
- employees 테이블에서 employee_id가 100과 106 사이인 직원의 hire_date에 대해 월 기준 반올림, 연 기준 반올림, 월 기준 절삭, 연 기준 절삭을 적용하여 출력하기
SELECT hire_date, ROUND(hire_date, 'MONTH') 적용결과_ROUND_M, ROUND(hire_date, 'YEAR') 적용결과_ROUND_Y, TRUNC(hire_date, 'MONTH') 적용결과_TRUNC_M, TRUNC(hire_date, 'YEAR') 적용결과_TRUNC_Y FROM employees WHERE employee_id BETWEEN 100 AND 106;HIRE_DATE 적용결과_ROUND_M 적용결과_ROUND_Y 적용결과_TRUNC_M 적용결과_TRUNC_Y 1 03/06/17 03/07/01 03/01/01 03/06/01 03/01/01 2 05/09/21 05/10/01 06/01/01 05/09/01 05/01/01
- 변환 함수
- 오라클 데이터베이스 시스템은 각 열에 대해 데이터 타입을 규정하고 있음
따라서 SQL 문을 실행 하기 위해 데이터 타입을 변환해야 할 때가 있음
→ 이럴 때 쓰는 게 변환 함수!
데이터 타입 변환은 암시적 변환(시스템에 의해 자동으로 변경)과 명시적 변환(수동으로 변경)이 있음
- 오라클 데이터베이스 시스템은 각 열에 대해 데이터 타입을 규정하고 있음
- 자동 데이터 타입 변환 유형
FROM TO VARCHAR2 혹은 CHAR NUMBER(숫자) VARCHAR2 혹은 CHAR DATE(날짜) NUMBER VARCHAR2(문자) DATE VARCHAR2(문자)
- 예제
SELECT 1+'2' FROM DUAL;1+‘2’ 1 3 - ‘2’는 작은따옴표로 묶여 있으므로 숫자가 아닌 문자임
- 그럼에도 불구하고 결과는 3이라고 바르게 연산되어 출력됨
- 수동 데이터 타입 변환 함수
함수 설명 TO_CHAR 숫자, 문자, 날짜 값을 지정 형식의 VARCHAR2 타입으로 변환 TO_NUMBER 문자를 숫자 타입으로 변환 TO_DATE 날짜를 나타내는 문자열을 지정 형식의 날짜 타입으로 변환
- TO_CHAR : 날짜, 숫자, 문자 값을 지정한 형식의 VARCHAR2 타입 문자열로 변환하는 함수
TO_CHAR(날짜 데이터 타입, '지정 형식')지정 형식 설명 예 결과 CC 세기 TO_CHAR(SYSDATE, ‘CC’) 21 YYYY or YYY or YY or Y 연도 TO_CHAR(SYSDATE, ‘YYYY’) 2017, 017, 17, 7 Y, YYY 콤마가 있는 연도 TO_CHAR(SYSDATE, ‘Y, YYY’ 2,017 YEAR 문자로 표현된 연도 TO_CHAR(SYSDATE, ‘YEAR’) TWENTY SEVENTEEN BC or AD BC/AD 지시자 TO_CHAR(SYSDATE, ‘AD’) 서기 Q 분기 TO_CHAR(SYSDATE, ‘Q’) 4 MM 두 자리 값의 월 TO_CHAR(SYSDATE, ‘MM’) 10 MONTH 아홉 자리를 위해 공백을 추가한 월 이름 TO_CHAR(SYSDATE, ‘MONTH’) 10월 RM 로마 숫자 월 TO_CHAR(SYSDATE, ‘RM’) 10월 WW or W 연, 월의 주 TO_CHAR(SYSDATE, ‘WW’) 40, 1 DDD or DD or D 연, 월, 주의 일 TO_CHAR(SYSDATE, ‘DD’) 280, 07, 7 DAY 아홉 자리를 위해 공백을 추가한 요일 이름 TO_CHAR(SYSDATE, ‘DAY’) 토요일 DY 세 자리 약어로 된 요일 이름
(영문 설정일 경우)TO_CHAR(SYSDATE, ‘DY’) 토 J Julian day, BC 4713년 12월 31일 이후의 요일 수 TO_CHAR(SYSDATE, ‘J’) 2458034
- 예제
SELECT TO_CHAR(SYSDATE, 'YY'), TO_CHAR(SYSDATE, 'YYYY'), TO_CHAR(SYSDATE, 'MM'), TO_CHAR(SYSDATE, 'MON'), TO_CHAR(SYSDATE, 'YYYYMMDD') 응용적용1, TO_CHAR(TO_DATE('20171008'), 'YYYYMMDD') 응용적용2 // 수동으로 날짜 데이터 타입으로 변환 FROM dual;TO_CHAR(SYSDATE, 'YY') TO_CHAR(SYSDATE, 'YYYY') TO_CHAR(SYSDATE, 'MM') TO_CHAR(SYSDATE, 'MON’) 응용적용1 응용적용2 1 17 2017 10 10월 20171007 20171008
- 시간 지정 형식
지정 형식 설명 AM or PM 오전 또는 오후 표시 HH / HH12 or HH24 시간 표현(1~12시 또는 0~23시) MI 분(0~59) SS 초(0~59) SELECT TO_CHAR(SYSDATE, 'HH:MI:SS PM') 시간형식, TO_CHAR(SYSDATE, 'YYYY/MM/DD HH:MI:SS PM') 날짜와시간조합 FROM dual;시간형식 날짜와시간조합 1 07:52:09 오후 2017/10/08 07:52:09 오후
- 기타 형식
요소 설명 /, ., - 사용 문자를 출력 결과에 표현 “문자” 큰따옴표 안의 문자를 출력 결과에 표현
- 예시
SELECT TO_CHAR(SYSDATE, 'HH-MI-SI PM') 시간형식, TO_CHAR(SYSDATE, ' "날짜:" YYYY/MM/DD "시각:" HH:MI:SS PM') 날짜와시각표현 FROM dual;시간형식 날짜와시각표현 1 08-06-31 날짜:2017/10/08 시각:08:06:31 오
- 숫자 형식 변환하기
TO_CHAR(숫자 데이터 타입, '지정 형식')
- 숫자 지정 형식
지정 형식 설명 예 결과 9 9로 출력 자릿수 지정 TO_CHAR(salary, ‘99999999’) 24000 0 자릿수만큼 0을 출력 TO_CHAR(salary, ‘09999999’) 00024000 $ 달러 기호 TO_CHAR(salary, ‘$9999999’) $24,000 L 지역 화폐 기호(원) TO_CHAR(salary, ‘L9999999’) \24,000 . 명시한 위치에 소수점 TO_CHAR(salary, ‘999999.99’) 24000.00 , 명시한 위치에 쉼표 TO_CHAR(salary, ‘9,999,999’) 24,000
- 예시
SELECT TO_NUMBER('123') FROM dual;TO_NUMBER(’123’) 1 123
- 날짜를 나타내는 문자열을 명시된 날짜로 변환
TO_DATE(문자열, '지정 형식')
- 예시
SELECT TO_DATE('20171007', 'YYMMDD') FROM dual;TO_DATE(’20171007’, ‘YYDDMM’) 1 17/10/07
- 일반 함수
- NULL
- 할당되지 않았거나 알려져 있지 않아 적용이 불가능한 값
- 0이나 공백(space)과는 다름
- null 값을 포함하는 산술 연산자의 결과는 null
- NOT NULL 값 처리하기
SELECT salary * commision_pct FROM employees ORDER BY commision_pct;SALARY*COMMISION_PCT 32 3500 33 3325 34 3150 35 5600 36 (null) 37 (null) 38 (null)
- NULL
- NVL 함수
NVL(열 이름, 치환 값) // 열 이름 : null이 포함된 열이나 표현 값 // 치환 값 : null에서 변환하고자 하는
- employees 테이블에서 salary commission_pct를 곱하되 commission_pct가 null일 때는 1로 치환하여 commision_pct를 곱한 결과를 출력하기
SELECT salary * NVL(commission_pct, 1) // commission_pct가 null이면 1로 치환 FROM employees ORDER BY commission_pct;
- NVL2 함수
NVL2(열 이름1, 열 이름2, 열 이름3) // 열 이름1이 null이 아니면 열 이름2를 출력 // 열 이름1이 null이면 열 이름3을 출력
- 데이터 값과 조건 값이 일치하면 치환 값을 출력하고 일치하지 않으면 기본값 출력하기
DECODE (열 이름, 조건 값, 치환 값, 기본 값) // 치환 값 : 조건 값에 해당할 경우 출력 값 // 기본 값 : 조건 값에 해당하지 않을 경우 출력 값
- employees 테이블에서 first_name, last_name, department_id, salary를 출력하되 department_id가 60인 경우에는 급여를 10% 인상한 값을 계산하여 출력하고 나머지 경우에는 원래의 값을 출력하기 그리고 department_id가 60인 경우에는 ‘10% 인상’을 출력하고 나머지 경우에는 ‘미인상’을 출력하기
SELECT first_name, last_name, department_id, salary 원래급여, DECODE(department_id, 60, salary*1.1, salary) 조정된급여, DECODE(department_id, 60, '10%인상', '미인상') 인상여부 FROM employees;FIRST_NAME LAST_NAME DEPARTMENT_ID 원래급여 조정된급여 인상여부 1 Steven King 90 24000 24000 미인상 2 Alexander Hunold 60 9000 9900 10%인상
- CASE 표현식 : 복잡한 조건 논리 처리하기 복잡한 조건식을 여러 개 적용해야 할 때는 DECODE 함수보다 CASE 표현식을 이용하는 것이 유용할 수 있음 DECODE 함수는 데이터 값이 정확히 맞거나 틀린 조건을 처리하기 쉬운 반면 CASE 함수는 조건의 범위가 다양한 경우에 쉽게 처리할 수 있음
CASE WHEN 조건 1 THEN 출력 값 1 WHEN 조건 2 THEN 출력 값 2 ... ELSE 출력 값 3 END
- employees 테이블에서 job_id가 IT_PROG라면 employee_id, first_name, last_name, salary를 출력하되 salary가 9000 이상이면 ‘상위 급여’, 6000과 8999 사이면 ‘중위급여’, 그 외는 ‘하위급여’라고 출력하기
// 데이터 값의 범위를 모르는 상태에서 특정 조건에 맞춰 출력하거나 조작해야 한다면 // CASE 표현식이 유용할 수 있음 SELECT employee_id, first_name, last_name, salary CASE WHEN salary >= 9000 THEN '상위급여' WHEN salary BETWEEN 6000 AND 8999 THEN '중위급여' ELSE '하위급여' END AS 급여등급 FROM employees WHERE job_id = 'IT_PROG';EMPLOYEE_ID FIRST_NAME LAST_NAME SALARY 급여등급 1 103 Alexander Hunlod 9000 상위급여 2 104 Bruce Ernst 6000 중위급여
- RANK, DENSE_RANK, ROW_NUMBER : 데이터 값에 순위 매기기
-
순위 함수의 출력 방법 차이
| 함수 | 설명 | 순위 예 | | --- | --- | --- | | RANK | 공통 순위를 출력하되 공통 순위만큼 건너뛰어 다음 순위를 출력 | 1, 2, 2, 4 … | | DENSE_RANK | 공통 순위를 출력하되 건너뛰지 않고 바로 다음 순위를 출력 | 1, 2, 2, 3 … | | ROW_NUMBER | 공통 순위 없이 출력 | 1, 2, 3, 4 |RANK () OVER([PARTITION BY 열 이름] ORDER BY 열 이름) // PARTITION BY 열 이름 : 그룹으로 묶어서 순위를 매겨야 할 때 사용 // ORDER BY 열 이름 : 순위를 매길 열
-
- RANK, DENSE_RANK, ROW_NUMBER 함수를 각각 이용해 employees 테이블의 salary 값이 높은 순서대로 순위를 매겨 출력하기
SELECT employee_id, salary, RANK() OVER(ORDER BY salary DESC) RANK_급여, DENSE_RANK() OVER(ORDER BY salary DESC) DENSE_RANK_급여, ROW_NUMBER() OVER(ORDER BY salary DESC) ROW_NUMBER_급여 FROM employees;EMPLOYEE_ID SALARY RANK_급여 DENSERANK급여 ROWNUMBER급여 1 100 24000 1 1 1 2 101 17000 2 2 2 3 102 17000 2 2 3 4 145 14000 4 3 4 5 146 13500 5 4 5
- RANK, DENSE_RANK, ROW_NUMBER 함수를 각각 이용해 employees 테이블 직원이 속한 department_id 안에서 salary 값이 높은 순서대로 순위를 매겨 출력하기
SELECT A.employee_id, A.department_id, B.department_name, salary, RANK() OVER(PARTITION BY A.department_id ORDER BY salary DESC) RANK_급여, DENSE_RANK() OVER(PARTITION BY A.department_id ORDER BY salary DESC) DENSE_RANK_급여, ROW_NUMBER() OVER(PARTITION BY A.department_id ORDER BY salary DESC) ROW_NUMBER_급여 FROM employees A, departments B WHERE A.department_id = B.department_id ORDER BY B.department_id, A.salary DESC;EMPLOYEE_ID DEPARTMENT_ID DEPARTMENT_NAME SALARY RANK_급여 DENSERANK급여 ROWNUMBER급여 1 200 10 Administration 4400 1 1 1 2 201 20 Marketing 13000 1 1 1 3 202 20 Marketing 6000 2 2 2 4 114 30 Purchasing 11000 1 1 1 56 103 60 IT 9000 1 1 1 57 104 60 IT 6000 2 2 2 58 105 60 IT 4800 3 3 3 59 106 60 IT 4800 3 3 4 60 107 60 IT 4200 5 4 5 61 204 70 Public Relations 10000 1 1 1 62 145 80 Sales 14000 1 1 1 63 146 80 Sales 13500 2 2 2
그룹 함수 : 그룹으로 요약하기
그룹 함수는 단일 행 함수와 달리 여러 행에 대해 함수가 적용되어 하나의 결과를 나타내는 함수임
집계 함수라고 부르기도 함
기준 열에 대해 같은 데이터 값끼리 그룹으로 묶고 묶은 행의 집합에 대해 그룹 함수 연산이 필요하다면 GROUP BY 절을 이용하여 처리할 수 있음
묶은 그룹에 대해 조건이 필요하다면 HAVING 절을 이용
- 그룹 함수의 종류와 사용법
SELECT 그룹 함수(열 이름) FROM 테이블 이름 [WHERE 조건식] [ORDER BY 열 이름];
- 그룹 함수의 종류
함수 설명 예 null 처 COUNT 행 개수를 셈 COUNT(salary) (*)의 경우 null 값도 개수로 셈 SUM 합계 SUM(salary) null 값을 제외하고 연산 AVG 평균 AVG(salary) null 값을 제외하고 연산 MAX 최댓값 MAX(salary) null 값을 제외하고 연산 MIN 최솟값 MIN(salary) null 값을 제외하고 연산 STDDEV 표준편차 STDDEV(salary) null 값을 제외하고 연산 VARIANCE 분산 VARIANCE(salary) null 값을 제외하고 연산
- COUNT 함수 지정한 열의 행 개수를 세는 함수
COUNT(열 이름) // 열 이름 : 열 이름 대신 *를 사용하면 열의 모든 행 개수를 셈
- employees 테이블에서 salary의 행 수가 몇 개인지 세어서 출력하기
SELECT COUNT(salary) salary행수 FROM employees;
(참고) 문법에 열 이름을 지정할 수 있는 대부분의 그룹 함수는 null을 제외하고 연산함 하지만 COUNT 함수는 COUNT(*)의 경우 null 값도 행으로 셀 수 있음salary행수 1 107
- SUM, AVG 함수 SUM : 열의 합계를 구하는 함수 AVG : 열의 평균을 구하는 함수
SUM(열 이름) AVG(열 이름)
- employees 테이블에서 salary의 합계와 평균을 구하기. 또한 AVG 함수를 사용하지 말고, salary의 평균을 구하기
SELECT SUM(salary) 합계, AVG(salary) 평균, SUM(salary)/COUNT(salary) 계산된평균 FROM employees;합계 평균 계산된평균 1 691416 6461.83178 6461.83178
- MAX, MIN 함수 MAX : 최댓값을 출력하는 함수 MIN : 최솟값을 출력하는 함수
MAX(열 이름) MIN(열 이름)
- employees 테이블에서 salary의 최댓값과 최솟값, first_name의 최댓값과 최솟값을 출력하기
SELECT MAX(salary) 최댓값, MIN(salary) 최솟값, MAX(first_name) 최대문자값, MIN(first_name) 최소문자값 FROM employees;최댓값 최솟값 최대문자값 최소문자값 1 24000 2100 Winston Adam
- GROUP BY : 그룹으로 묶기
기준 열을 지정하여 그룹화하는 명령어
SELECT 절에 열 이름과 그룹 함수를 함께 기술했다면 GROUP BY절을 반드시 사용해야 함SELECT 기준 열, 그룹 함수(열 이름) // 열 이름과 그룹 함수가 같이 지정되었으므로 GROUP BY절이 필수 FROM 테이블 이름 // (1) 테이블에 접근 [WHERE 조건식] // (2) 조건식에 맞는 데이터 값만 골라냄 GROUP BY 열 이름 // (3) 기술된 기준 열을 기준으로 같은 데이터 값끼리 그룹화함 [ORDER BY 열 이름]; // 결과를 오름차순 또는 내림차순으로 정렬
-
GROUP BY 절의 특징
- SELECT 절에 기준 열과 그룹 함수가 같이 지정되면 GROUP BY 절에 기준 열 이름이 반드시 기술되어야 함
(SELECT 절에 그룹 함수만 기술되고 열 이름이 기술되지 않으면 GROUP BY 절을 반드시 기술할 필요는 없음)
- WHERE 절을 사용하면 행을 그룹으로 묶기 전에 앞서 조건식이 적용됨
- SELECT 절에 그룹 함수를 사용하지 않아도 GROUP BY 절만으로도 사용할 수 있음
-
employees 테이블에서 employee_id가 10 이상인 직원에 대해 job_id별로 그룹화하여 job_id별 총 급여와 job_id별 평균 급여를 구하고, job_id별 총 급여를 기준으로 내림차순 정렬하기
SELECT job_id 직무, SUM(salary) 직무별_총급여, AVG(salary) 직무별_평균급여 FROM employees WHERE employee_id >= 10 GROUP BY job_id ORDER BY 직무별_총급여 DESC, 직무별_평균급여;직무 직무별_총급여 직무별_평균급여 1 SA_REP 250500 8350 2 SH_CLERK 64300 3215 employee_id가 10 이상인 값에 대해 job_id를 기준 열로 GROUP BY 절로 그룹화함
salary에 대해 SUM 함수와 AVG 함수를 사용해 직무별 총 급여와 평균 급여를 출력함
정렬 순서는 직무별 총 급여를 기준으로 내림차순 정렬함
SELECT job_id job_id_대그룹,
manager_id manager_id_중그룹,
SUM(salary) 그룹핑_총급여,
AVG(salary) 그룹핑_평균급여
FROM employees
WHERE employee_id >= 10
GROUP BY job_id, manager_id
ORDER BY 그룹핑_총급여 DESC, 그룹핑_평균급여;- HAVING : 연산된 그룹 함수 결과에 조건 적용하기 그룹화된 값에 조건식을 적용할 때 사용함 WHERE 절에서는 그룹 함수를 사용할 수 없으므로 HAVING 절을 사용해 그룹 함수의 결과값에 대해 조건식을 적용 일반적으로 HAVING 절은 GROUP BY 절 다음에 기술하는 것이 논리적이고 가독성도 좋음
SELECT 열 이름, 그룹 함수(열 이름) // (5) 결과 출력 FROM 테이블 이름 // (1) 테이블에 접근 [WHERE 조건식] // (2) WHERE 조건식에 맞는 데이터 값만 골라냄 GROUP BY 열 이름 // (3) 기술된 기준 열을 기준으로 같은 데이터 값끼리 그룹화함 [HAVING 조건식] // (4) 그룹화된 값에 대해 조건식 적용 [ORDER BY 열 이름]; // (6) 오름차순(기본, ASC) 혹은 내림차순(DESC)으로 정렬
- employees 테이블에서 employee_id가 10 이상인 직원에 대해 job_id별로 그룹화하여 job_id별 총 급여와 job_id별 평균 급여를 구하되, job_id별 총 급여가 30000보다 큰 값만 출력하기 출력 결과는 job_id별 총 급여를 기준으로 내림차순 정렬하기
SELECT job_id 직무, SUM(salary) 직무별_총급여, AVG(salary) 직무별_평균급여 FROM employees WHERE employee_id >= 10 GROUP BY job_id HAVING SUM(salary) > 30000 ORDER BY 직무별_총급여 DESC, 직무별_평균급여;직무 직무별_총급여 직무별_평균급여 1 SA_REP 250500 8350 2 SH_CLERK 64300 3215
