tree
매우 널리 사용하는 자료구조 중 하나로 나무의 계층적 구조를 표현한 자료구조
트리 관련 용어
(1) 노드(node) : 실제로 저장하는 데이터
(2) 루트(root) 노드 : 최상위에 위치한 데이터(시작 노드), 모든 노드와 직간접적으로 연결됨
(3) 리프(leaf) 노드 : 마지막에 위치한 데이터들로 더 이상 가지를 치지 않음
(4) 부모-자식 : 연결된 노드들 간의 상대적 관계(부모는 언제나 1개),
조부모 / 삼촌(uncle) / 형제자매(sibling) 등도 있음
(5) 깊이(depth) : 노드->루트 경로의 길이
(6) 높이(height) : 노드->리프 경로의 최대 길이
트리의 속성
(1) 부모와 자식은 모두 노드
(2) 부모 : 자식 = 1 : 다수
(3) 자식은 언제나 부모로부터 가지를 침 -> 따라서 부모가 자식을 참조하는 방식이 가장 직관적
이진 탐색 트리(BST)
이진 트리에 이분하는 규칙을 추가한 것으로 재귀적으로 읽는 순서만 제대로 지키면 정렬된 트리
(1) 왼쪽 자식은 언제나 부모보다 작다
(2) 오른쪽 자식은 언제나 부모 이상
BST 순서대로 읽기
전위, 중위, 후위는 하위 트리와 비교했을 때 현재 노드의 방문 순서
(1) 전위 순회(pre-order) : 현재 노드 -> 왼쪽 하위 트리 -> 오른쪽 하위 트리
(2) 중위 순회(in-order) : 왼쪽 하위 트리 -> 현재 노드 -> 오른쪽 하위 트리
(3) 후위 순회(post-order) : 왼쪽 하위 트리 -> 오른쪽 하위 트리 -> 현재 노드
// 전위 순회
void traversePreOrder(Node node)
{
if(node == null)
{
return;
}
System.out.printIn(node.data);
traversePreOrder(node.left);
traversePreOrder(node.right);
}
// 중위 순회
void traverseInOrder(Node node)
{
if(node == null)
{
return;
}
traverseInOrder(node.left);
System.out.printIn(node.data);
traverseInOrder(node.right);
}
// 후위 순회
void traversePreOrder(Node node)
{
if(node == null)
{
return;
}
traversePreOrder(node.left);
traversePreOrder(node.right);
System.out.printIn(node.data);
}(참고) 이진 탐색 트리의 시간 복잡도
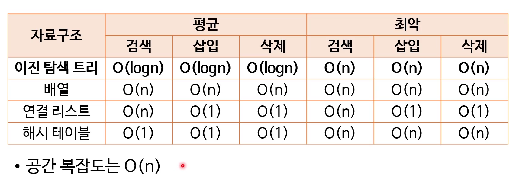
BST 삽입
(1) 새로운 노드를 받아줄 수 있는 부모 노드를 찾음 -> O(logn)
(2) 그 후, 거기에 자식으로 추가 -> O(1)
(참고) 새로운 노드를 받아줄 수 있는 부모
오른쪽 하위 트리로 내려가야 하는데 오른쪽 자식이 없는 부모
왼쪽 하위 트리로 내려가야 하는데 왼쪽 자식이 없는 부모
BST 삭제
BST는 정렬된 배열과 개념상 같으므로 노드를 삭제한 뒤에도 올바른 BST를 유지하기 위해
정렬된 배열에서 값을 하나 삭제하듯이 처리해야 함
- 오른쪽 하위 트리에서 최솟값 (제일 왼쪽 리프) in-order successor
- 왼쪽 하위 트리에서 최댓값 (제일 오른쪽 리프) in-order predecessor
(1) 지울 값을 가지고 있는 노드를 찾음
(2) 그 바로 전 값을 가진 노드를 찾음(왼쪽 하위 트리의 제일 오른쪽 리프(최댓값))
-> (1) ~ (2) 까지 O(log n)
(3) 두 값을 교환 O(1)
(4) 리프 노드를 삭제 O(1)
레드-블랙 트리
각 노드가 레드 혹은 블랙인 트리로 스스로 균형을 잡는 트리
노드에 저장하는 데이터를 의미하는 것이 아닌 1비트짜리 추가 정보 (빨강/검정이 아니어도 됨)
레드-블랙 균형을 잡는 트리이므로 트리 높이를 최소로 보장하므로 탐색 속도가 BST 보다 빠름
레드-블랙 트리의 특성(properties)
(1) 노드는 레드 또는 블랙이다
(2) 루트 노드는 블랙이다
(3) 모든 리프 노드(NIL)는 블랙이다
(4) 레드 노드의 자식은 언제나 블랙이다 (블랙 노드의 자식으로 블랙은 가능)
(5) 어떤 노드와 리프 사이에 있는 블랙 노드 수는 동일하다
-> 블랙 노드에만 있는 제약
-> 이를 통해 블랙과 레드 노드 수의 균형을 맞춤
-> 이걸 위해 삽입 / 삭제 시 트리를 재배치하거나 노드의 색을 바꾸기도 함
레드-블랙 트리가 가진 특성의 영향
(1) 리프 노드는 데이터를 담지 않음(NIL) : 특성의 4번 5번을 보장하기 위해
(2) 다음과 같은 용어 탄생
-> 블랙 깊이(black depth) : 루트와 어떤 노드 사이에 있는 블랙 노드 수
-> 블랙 높이(black height) : 어떤 노드와 리프 사이에 있는 블랙 수
(3) 가장 큰 리프 깊이가 가장 작은 것의 2배를 넘지 않음
-> 레드 블랙 트리가 보장하는 핵심 특성
-> 이진 트리 연산 시간이 O(N)이 되는 최악의 경우를 방지 -> 즉, O(log n) 보장
-> C++의 std::map의 구현으로 일반적으로 사용되는 자료구조
레드-블랙 트리의 삽입
(1) BST와 똑같이 삽입
-> 단 새로 삽입하는 노드는 언제나 레드
(2) 레드-블랙 트리의 조건을 만족하도록 재귀적으로 고침
-> 재귀 방향 : 리프로부터 위로 올라가면서
-> 고칠 때 사용하는 기법 : 트리 회전, 색깔 바꾸기
(참고) 트리 회전의 예
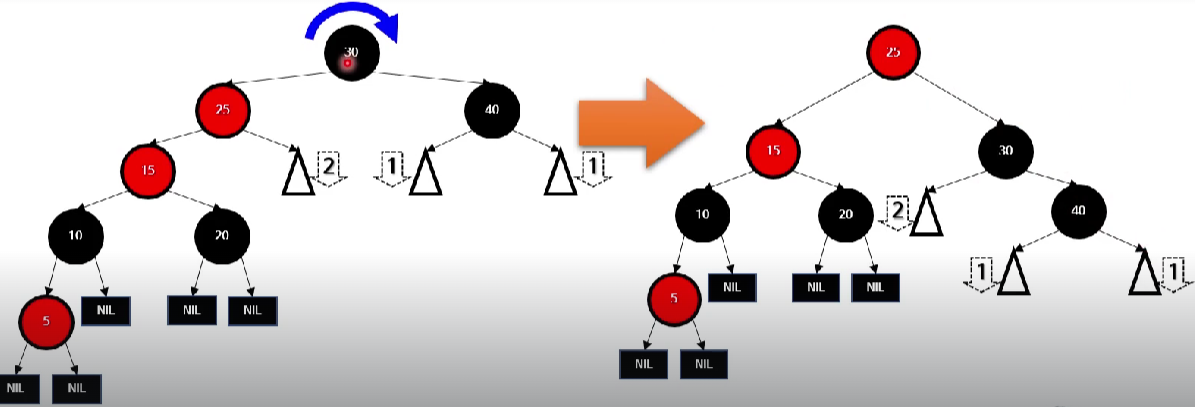
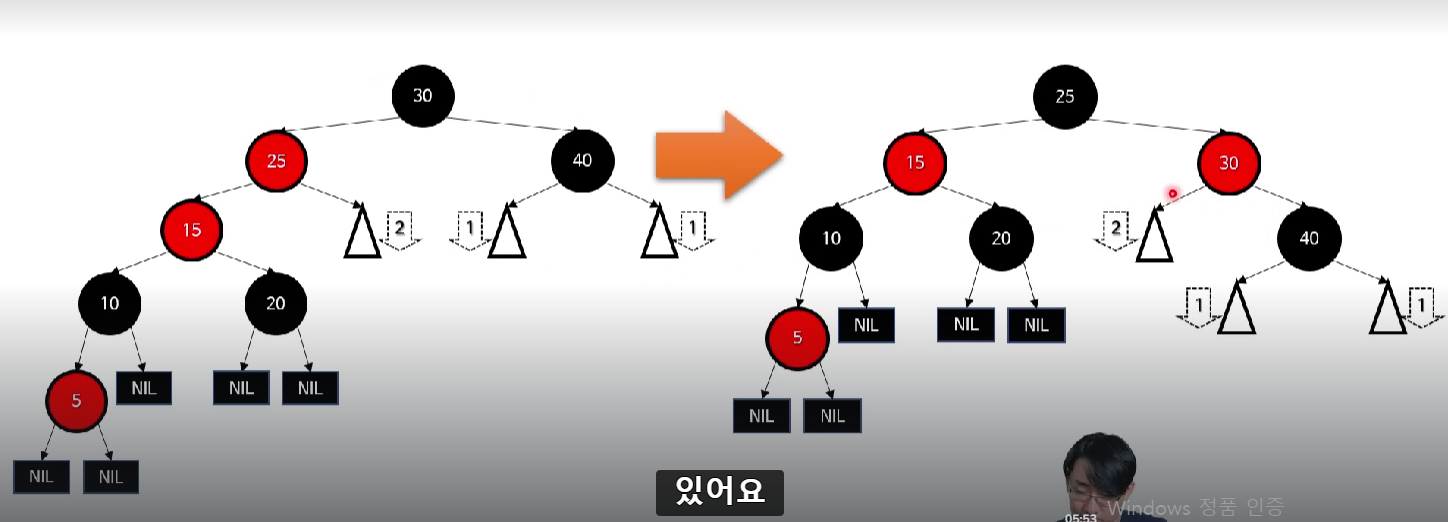
레드-블랙 트리의 삭제
(1) BST에서 삭제하듯이 우선 삭제
-> 지우려는 값을 가진 노드를 찾음
-> 교환할 NIL 아닌 노드 M을 찾음
-> 값을 복사해 옴 (색은 복사 안 함)
-> M을 지움
(2) 레드-블랙 트리의 특성이 망가진 걸 고치려 열심히 노력 (색상 바꾸기, 트리 회전)
(참고)
M은 언제나 오른쪽 하위 트리의 최솟값 (또는 왼쪽 하위 트리의 최댓값)
M이 레드 C가 블랙인 경우 -> 지워도 아무것도 망가지지 않음
M이 블랙 C가 블랙인 경우(MC THE BLACK) -> 색상 바꾸기, 트리 회전 활용
