1. Pros./Cons. of RNN-T
Pros
- Better accuracy: CTC에서 존재하던 Conditional independence assumption을 해소
- Low latency: Streaming ASR Application에 사용 가능
- RNN-T > MoChA in terms of latency, inference time, and training stability. (Comparison study from Kim et al.)
- The industry tends to choose RNN-T as the dominating streaming E2E model.
Cons
- Output prediction tensor takes too much memory (3D tensor) (More detail from Moriya et al.)
- Vanilla RNN-T can delay its label prediction (latency of ASR is critical)
2. RNN-T formulation
Predicting the current token based on:
- Previous output tokens
- Speech sequence .
3. RNN-T Structure
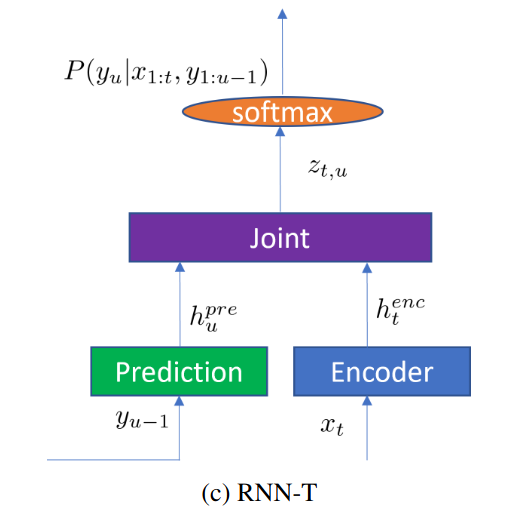
-
Encoder: Generate a high-level feature representation from
-
Prediction network: Generate based on RNN-T's previous output label
-
Joint network: A feed-forward network that combines and as:
Parameters:
- and are weight matrices.
- is a non-linear function (e.g., RELU or Tanh)
- is again multiplied by another weight matrix
- and are bias vectors
3. Shape of output
- is the length of speech sequence
- is the length of the label sequence
- is the number of possible tokens including special symbols.
(e.g., start-of-sentence, , end-of-sentence, and blank symbol) - Thus, 3D tensor that requires much more memory than other E2E models such as CTC and AED.
4. Learnable parameters
- Prediction network parameters
- Encoder network parameters
- , , , , from Joint network
5. Alignment Paths
- Three possible alignment paths from the bottom left corner to the top right corner of the x grid.
- The length of alignment path: +.
- Horizontal arrow: Advance one time step with a blank label.
- Vertical arrow: Advance one time step with a non-block output label.
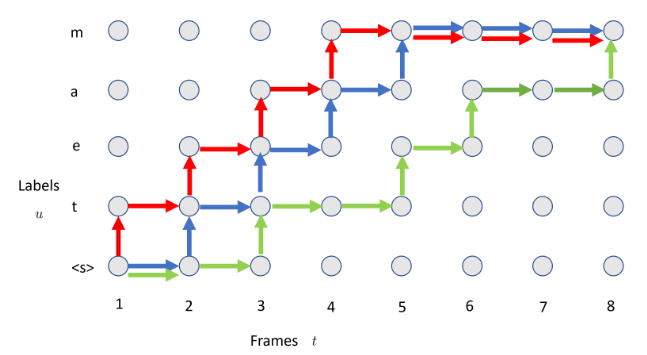
x-axis: Speech sequence
y-axis: Label sequence , where is a token for start-of-sentence.
Delayed decision/prediction: Green path in the image above (Latency is high because of the late prediction. Problem of vanilla RNN-T.)
6. RNN-T Loss
-
RNN-T tries to minimize where
: One of possible alignment paths
: The mapping from the alignment path to the label sequence . . -
The parameters are optimized using
forward-backward algorithm(Alex et al.).
7. Forward-backward Algorithm
7.1 Implementation
(WIP)
7.2 How to improve training efficiency
- Look skewing transformation: forward/backward probabilities can be vectorized. The recursions can be computed in a single loop instead of two nested loops.
- Function merging: Reduce the training memory cost so that larger minibatches could be used.
8. Different Strategies for Alignments
8.1 Constrained alignment
(WIP)
8.2 FastEmit
(WIP)
8.3 Self-alignment
Summary: Self-alignment encourages the model's alignment to the left direction. (lower-latency alignment) This was reported to have better accuracy and latency tradeoff than previous methods
- Blue path indicates a self-alignment path and the red path is one frame left to the self-alignment path.
- During training, the method encourages the left-alignment path, pushing the model's alignment to the left direction.
