0. 서론
이번 장에서는 수, 문자, 문자열과 관련된 지원을 제공하는 가장 중요한 라이브러리 다섯 가지를 살펴볼 것이다.
1. <float.h> 헤더
<float.h> 헤더는 float, double, long double 자료형의 범위와 정확성에 대해 매크로 정의를 재공하고 있다.
두 개의 매크로가 모든 부동소수점 자료형에 적용된다. FLT_ROUNDS 매크로는 부동소수점의 반올림 방식을 나타낸다 밑의 표는 FLT_ROUNDS에서 선택 가능한 옵션을 나타낸다.
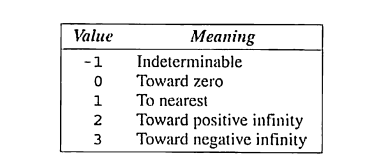
같은 헤더 내의 다른 매크로와 다르게 FLT_ROUNDS는 실행 중에 변경될 수 있다. 다른 매크로 FLT_RADIX(지수의 기수를 나타냄)는 최소 2의 값을 가져야한다.
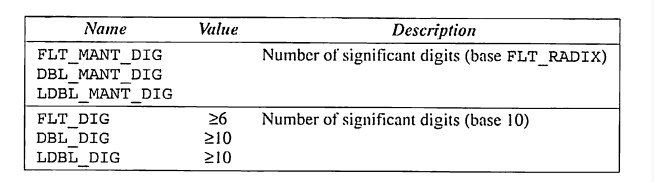
아래 표는 같은 헤더 내의 나머지 매크로들을 나타낸다. 이해를 돕기 위해 정확하진 않아도 쉽게 말해보자면, 아래 표는 표준에서 정의된 바에 따른 최소 혹은 최대 값을 보여준다.
아래 표는 지수와 함께 사용해야하는 매크로를 보여준다.
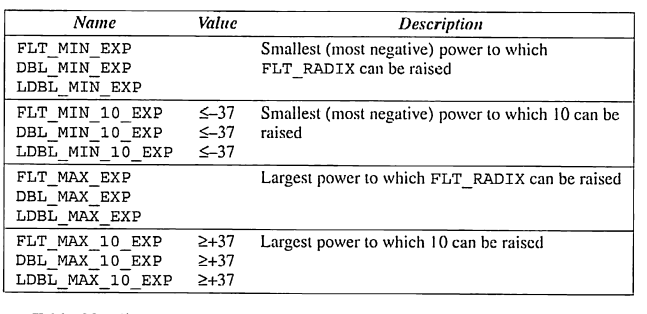
아래 표는 수가 얼마나 커질 수 있는지, 0에 얼마나 가까워 질 수 있는지 혹은 일련의 두 수가 얼마나 가까운지를 나타내는 매크로를 보여준다.

C99는 DECIMAL_DIG와 FLT_EVAL_METHOD 을 추가적으로 가지고 있다.
DECIMAL_DIG는 유효숫자 자리수를 나타낸다. FLT_EVAL_METHOD는 부동소숫점의 연산에서 더 큰 범위와 정확성을 구현할 지 여부를 나타낸다. 만약 이 매크로가 0으로 설정 되어있는경우. 두 개의 float 자료형을 더하는데 특별한 일은 없을것이다. 하지만 1의 값을 가진다면 double 형의 결과가 나올 것이다.

<float.h>의 헤더 대부분은 수를 분석하는 전문가들의 관심만을 끌것이다.내가 이걸 쓸 일이 있을까?
2. <limits.h> 헤더
<limit.h> 헤더는 각 정수형의 범위를 정의하는 매크로를 제공한다.(문자형도 포함) 한 매크로 집합은 문자형들을 다룬다.(char, signed char, unsigned char) 아래 표는 이러한 매크로를 보여주며, 최대 혹은 최솟값을 보여준다.
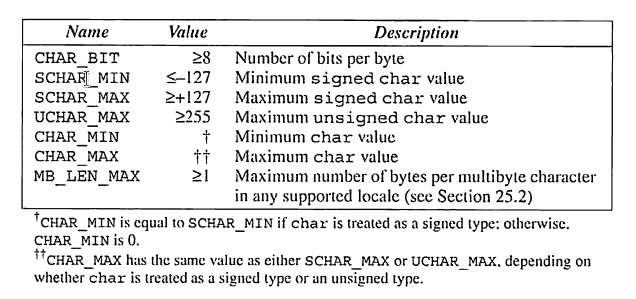
같은 헤더 내의 다른 매크로들은 나머지 정수형들을 다룬다. 아래 표는 이들을 다루는 매크로를 보여준다.
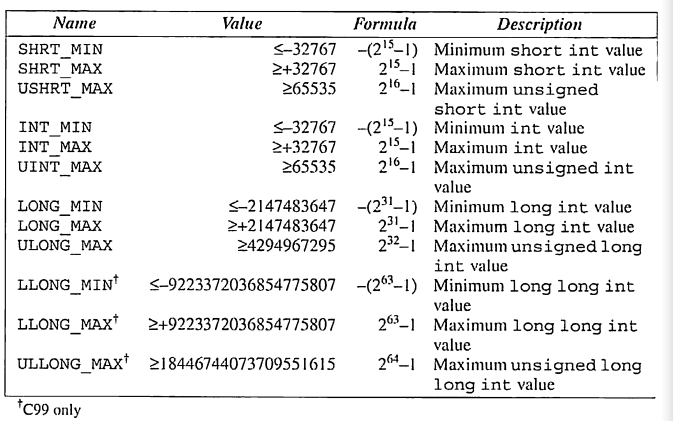
<limits.h> 내의 매크로들은 컴파일러가 특정 크기의 정수형을 지원하는지 여부를 검사할 때 유용하다. 예를들어 int 형이 100,000을 저장할 수 있는지 알아보기 위해 우리는 다음과 같은 전처리 지시자를 사용하면 된다.
#if INT_MAX < 100000
#error int type is too small
#endif만약 int 형이 적절하지 않은 경우 #error 지시자가 전처리 과정에서 에러 메시지를 띄울 것이다.
더 나아가, 우리는 <limits.h>의 매크로를 프로그램이 형을 어떻게 나타낼지를 정하는데 쓸 수 있다.
#if INT_MAX >= 100000
typedef int Quantity;
#else
typedef long int Quantity;
#endif3. <math.h> 헤더(C89)
<math.h> 헤더(C89 기준)의 함수는 5 종류로 나눌 수 있다.
(1) 삼각 함수
(2) 쌍곡선 함수
(3) 지수 및 로그함수
(4) 제곱 함수
(5) 최근값, 절대값, 나머지 값 함수
C99는 여기에 더 많은 함수들을 추가했다. C99는 <math.h>에 상당한 변화를 주었으며 이는 따로 아래에서 다룰 것이다. 일단 먼저 error에 대해 간략히 살펴보도록 하자.
Errors
<math.h>의 함수는 다른 라이브러리의 함수들과 다른 방식으로 오류(error)를 다룬다. 오류가 발생하면 대부분의 <math.h> 함수들은 에러 코드를 errno라는 특별한 변수에 저장한다.(이 변수는 <errno.h>에서 선언된다.) 추가적으로, 함수의 반환값이 double보다 더 큰 경우에, <math.h> 함수는 특별한 값을 반환하는데, 이는 HUGE_VAL이라는 매크로로 표현된다.(같은 헤더에서 정의됨) HUGE_VAL은 double 형이지만, 평범한 수가 아니다.(부동소숫점 연산에 관한 IEEE 표준은 "infinyty"로 정의했다.) <math.h> 함수는 두 종류의 오류를 탐지한다.
(1) Domain error: 입력변수가 함수 도메인 바깥에 있음. 이 경우 EDOM을 반환한다.
(2) Range error: 반환 값이 double 범위를 초과한 경우. 양수 혹은 음수의 HUGE_VAL을 반환한다. 그리고 ERANGE가 errno에 저장된다. 언더플로우의 경우 0을 반환한다. 몇몇의 경우 앞선 경우와 동일하다.
삼각함수
cos, sin, tan 함수는 코사인, 사인, 탄젠트를 각각 계산해준다.
참고로 이들은 입력값을 라디안(radian)으로 받는다.
acos, asin, atan 역삼각함수다.
acos의 반환 값을 cos에 넣었을때, 반드시 원래 값이 반환될 것이라는 보장이 없다. 왜냐하면 acos는 항상 0과 PI 사이의 값을 반환하기 때문이다. asin과 atan은 -PI/2에서 PI/2의 값을 반환한다.
atan2는 y/x의 역 탄젠트 값을 계산한다. y는 첫 번째, x는 두 번째 입력변수다.
쌍곡선 함수
double cosh(double x);
double sinh(double x);
double tanh(double x);cosh, sinh 그리고 tanh 함수는 쌍곡선 삼각함수를 계산해준다. 이들의 입력변수는 반드시 라디안이다.
지수/로그 함수
double exp(double x);
double frexp(double value, int *exp);
double ldexp(double x, int exp);
double log(double x);
double log10(double x);
double modf(double value, double *iptr);exp 함수는 자연상수 e의 지수제곱을 계산한다.
log는 exp의 역이다. log10은 10을 밑으로 하는 로그를 구한다.
자연상수 e 혹은 10을 제외한 수를 밑으로하는 로그계산은 어렵지 않다. 다음 함수는 b를 밑으로하는 x의 로그값을 구할 수 있다.
double log_base(double x, double b)
{
return log(x)/log(b);
}modf와 frexp 함수는 double 형을 두 부분으로 나누어버린다. modf는 첫 입력변수를 정수와 소수 부분으로 나누어버린다. 소수부분을 반환하고, 정수부분은 두 번째 입력변수에 저장한다.
int_part는 반드시 double 형을 가지지만, 우리는 int 혹은 long int로 캐스팅 해줄수있다.
frexp 함수는 부동소수를 소수부분 f와 지수부분 n으로 나누어버린다.
ldexp는 frexp의 역을 계산한다.
제곱 함수
double pow(double x, double y);
double sqrt(double x);pow 함수는 x의 y제곱을 반환한다. sqrt는 x의 제곱근을 계산해준다. sqrt를 통해 제곱근을 구하는 것이 pow를 사용하는 것보다 선호되는데, sqrt의 계산속도가 더 빠르기 때문이다.
최근값, 절대값, 나머지 함수
double ceil(double x);
double fabs(double x);
double floor(double x);
double fmod(double x, double y);ceil은 해당 값보다 큰 정수중 가장 작은 값을 반환한다. floor는 해당 값보다 작은 정수 중 가장 큰 값을 반환한다. 즉 각각, 올림과 내림을 수행한다. C89는 가장 가까운 정수에 대해 반올림을 하는 표준 함수가 없다. 하지만 우리는 ceil과 floor을 통해 이를 구현할 수 있다.
fabs는 절대값을 계산한다. fmod는 나머지를 반환해준다. C는 % 연산자를 부동소수점에 대해 사용할 수 없다. 하지만 fmod는 사용 가능하다.
4. <math.h> 헤더(C99)
C99에서는 C89 전체를 포함함과 동시에 더 많은 자료형, 매크로, 함수를 담고 있다.내용이 엄청 많다, 오늘 분량의 절반은 이 놈 혼자서 차지한다.
C99에 와서 수많은 변경사항이 생긴것은 몇가지 이유가 있는데
(1) IEEE 표준 지원
(2) 부동소수점 연산에 대한 통제 제공
(3) 포트란(Fortran) 프로그래머 친화
C99를 따로 다루는 다른 이유는 대부분의 평균적인 C 프로그래머들에게는 해당되지 않는다. 아마 대부분의 경우 C99에서 추가된 기능을 이용할 필요가 없을것이다. 하지만 엔지니어링, 수학, 응용과학에서는 이 함수들이 유용할 것이다.
[해당 부분은 너무 전문적인 부분이기에 넘어가겠습니다. 자세한 내용은 여기를 참고해주시기 바랍니다]
5. <ctype.h> 헤더
<ctype.h> 헤더는 두 종류의 함수를 지원해준다. 문자-분류 함수와, 문자-메핑 함수다. C가 문자를 검사하고 변환하는데 <ctype.h> 의 함수를 필요로 하는 것은 아니지만, 활용하면 더 좋다. 첫째로, 이 함수들은 속도측면에서 최적화가 이뤄져 있다. 두 번째는 호환성인 높은 프로그램을 만들 수 있다는 것이다. 세 번째는 <ctype.h> 함수는 로케일이 변경되었을 때에도 기능한다는 점이며, 프로그램이 다른 지역에서도 잘 실행되게 해준다.
이 헤더의 함수는 모두 int 입력변수를 받고 int 를 반환한다. 많은 경우에 입력변수는 이미 int 변수에 저장되어있다. 만약 입력변수가 char 형인 경우에는 주의를 기울여야한다. C는 자동적으로 char 입력변수를 int 형으로 전환한다. 만약 char이 무부호형이거나, ASCII같은 7비트 문자를 사용하는 경우, 이런 전환은 문제없이 이뤄질 것이다. 문제는 char가 부호를 가지거나 8비트 문자를 쓰는 경우다. 이 경우 좋지 않은 결과가 나타날 수 있다. 그러므로 무부호형을 캐스팅을 반드시 수행해줘야한다.
문자 분류 함수
int isalnum(int c);
int isalpha(int c);
int isblank(int c);
int iscntrl(int c);
int isdigit(int c);
int isgraph(int c);
int islower(int c);
int isprint(int c);
int ispunct(int c);
int isspace(int c);
int isupper(int c);
int isxdigit(int c);문자 매핑 함수
int tolower(int c);
int toupper(int c);대소문자 변환을 수행해주는 함수다. 입력변수가 문자가 글자가 아닌경우, 그대로 반환한다.
6. <string.h> 헤더
우리는 앞서 <string.h>를 사용한 적이 있다. 문자열 복사, 병합, 비교 그리고 문자열의 길이를 구할 때 사용했었다. 여기서는 Null 종결을 필요로하지 않는 문자열의 연산을 다루는 함수를 소개할 것이다.
<string.h>는 다섯 종류의 함수를 지원한다.
(1) 복사 함수
(2) 병합 함수
(3) 비교 함수
(4) 검색 함수
(5) 기타 등등..
복사 함수
void *memcpy(void * restrict s1,
const void * restrict s2, size_t n);
void *memmove(void *s1, const void *s2, size_t n);
char *strcpy(char * restrict s1,
const char * restrict s2);
char *strncpy(char * restrict s1,
const char * restrict s2, size_t n);이 분류의 함수들은 한 메모리 내에서 다른 곳으로 문자를 복사한다. 각 함수는 첫 입력변수로 목적지를 받으며, 두 번째로 source를 받고 있다. 모든 복사 함수는 첫 입력변수를 반환한다.
memcpy는 n개의 문자를 source로부터 목적지로 복사한다. source와 목적지가 겹치는 경우는 정의되지 않았다. memmove는 memcpy와 같지만 overlap의 경우에 대해서도 문제없이 기능한다.
strcpy는 null 종결 문자열을 목적지로 복사한다. strcpy와 비슷해보이지만 n개의 문자만을 복사한다. n이 너무 작으면 null 문자가 포함되지 않을 수 있다. source에서 null 문자를 만나는경우, strncpy는 null 문자로 나머지를 채운다. overlap의 경우 기능이 보장되지 않는다.
병합 함수
char *strcat(char * restrict s1,
const char * restrict s2);
char *strncat(char * restrict s1,
const char * restrict s2, size_t n);strcat은 두 번째 입력변수를 첫 번째 입력변수 끝에다 붙인다. 두 입력변수는 반드시 null 종결이 이뤄져야 한다. strcat은 병합된 문자열 끝에 null 문자를 붙인다.
strncat는 strcat와 기능은 같지만 n 개의 문자로 제한을 둔다.
비교 함수
int memcmp(const void *s1, const void *s2, size_t n);
int strcmp(const char *s1, const char *s2);
int strcoll(const char *s1, const char *s2);
int strncmp(const char *s1, const char *s2,
size_t n);
size_t strxfrm(char * restrict s1,
const char * restrict s2, size_t n);비교 함수는 다시 두 종류로 나뉜다. 첫 번째는 두 문자 배열을 비교하고, 두 번째는 로케일(locale)을 고려해야하는 경우 사용한다.
memcmp, strcmp, strncmp 함수는 자주 쓰인다. 이 세개는 문자 배열을 가리키는 포인터를 입력변수로 전달받는다. 첫 배열에 있는 문자는 두 번째 배열에 있는 문자와 하나씩 비교가 이뤄진다.
세 함수의 차이점은 배열간에 다른점이 없는 경우 비교를 중단하는 시점과 관련있다. memcmp 함수는 세 번쨰 입력변수 n을 전달받으며 이는 비교가 이뤄지는 글자 수를 제한한다. strcmp는 글자수 제한을 걸지 않으며 null 문자가 올때까지 비교를 수행한다. strncmp는 strcmp와 memcmp가 섞인 버전이다. strncmp는 n개의 문자를 비교하거나, null 문자를 만날때까지 비교를 수행한다.
strcoll 함수는 strcmp와 유사하다. 하지만 비교 결과는 현재 로케일에 의존한다.
strcoll은 대부분의 경우, 로케일 의존 문자열 비교에서 문제가 없다. 하지만 가끔씩, 비교를 두 번 이상 수행하거나, 비교 결과에 영향을 주지 않고 로케일을 변경해야하는 경우가 있다. 이런 경우에, strxfrm(string transform) 함수가 좋은 대체방안이 된다.
strxfrm 은 두 번째 입력변수(string)을 첫 번째 입력변수가 가리키는 배열에 변환 결과를 위치시킨다. 세 번째 입력변수는 글자 수를 제한한다.(null 문자 포함 기준) strxfrm은 변환된 string의 길이를 반환한다. 그 결과, 다음과 같은 예시로 쓰인다.
size_t len;
char *transformed;
len = strxfrm(NULL, original, 0);
transformed == malloc(len + 1);
strxfrm(transformed, original, len);검색 함수
void *memchr(const void *s, int c, size_t n);
char *strchr(const char *s, int c);
size_t strcspn(const char *s1, conast char *s2);
char *strpbrk(const char *s1, conast char *s2);
char *strrchr(const char *s1, int c);
size_t strspn((const char *s1, conast char *s2);
char *strstr(const char *s1, const char *s2);
char *strtok(char * restrict s1,
const char * restrict s2);strchr 함수는 특정 문자를 스트링에서 검색한다.
char *p, str[] = "Form follows funtion.";
p = strchr(str, 'f');strchr은 f가 처음 등장하는 포인터를 반환한다.
memchr은 strchr과 비슷하다. 하지만 memchr은 null 문자가 처음 등장하는 시점이 아닌 문자 집합을 검색한 이후에 검색을 종료한다. memchr의 세 번째 입력변수는 검사할 문자의 수를 제한한다. 다음은 memchr을 통해 null 문자 종결이 아닌 배열을 검사하는 예시다.
char *p, str[22] = "Form follows function.";
p = memchr(str, 'f', sizeof(str);strrchr은 strchr과 비슷하지만, 역순으로 검색을 수행한다.
strpbrk는 strchr의 일반화 버전이다. strpbrk는 두 번째 입력변수와 조금이라도 일치하는 문자의 포인터를 반환한다.
char *p, str[] = "Form follows funtion.";
p = strpbrk(str, "mn");strspn, strcspn 함수는 다른 함수들과 달리 한 스트링 내에서의 위치를 정수형으로 반환한다. strspn은 검색하려는 문자가 등장하지 않는 위치의 인덱스를 반환하고, strcspn은 검색하려는 문자가 처음으로 등장하는 위치의 인덱스를 반환한다.
strstr은 두 번째 입력변수와 일치하는 첫번째 입력변수의 위치를 포인터로 반환한다.
strtok는 검색함수 중 가장 복잡한 함수다. 이 함수는 스트링을 위치를 찾을 수 없으면 널 포인터를 반환한다. 이 함수는 '토큰'을 검색하기 위한 목적으로 만들어졌다. 이 함수는 문자열을 지정된 구분자를 기준으로 토큰이라고 불리는 부분 문자열로 분리하는 데 사용된다. 첫 호출에서는 분리할 문자열(s1)과 구분자를 인자로 전달받는다. 그 이후의 호출에서는 이전의 상태를 유지하며 NULL과 구분자를 인자로 받아 계속해서 다음 토큰을 반환한다. 토큰이 더 이상 없을 때에는 NULL을 반환한다. 구분자는 호출마다 다르게 설정해도 된다.
기타 함수
void *memset(void *s, int c, size_t n);
size_t strlen(const char *s);memset은 메모리 내 특정 구역 내에 있는 한 문자에 대한 복수의 복사본을 저장한다. 만약 p가 N바이트의 블록을 가리키는 경우,
memset(p,' ', N);은 해당 블록의 모든 바이트 마다. ' '을 저장할 것이다. memset의 또다른 활용은 배열을 0으로 초기화 하는 것이다.
memset(a, 0, sizeof(a));memset은 첫 번째 입력변수를 반환한다.
strlen은 string의 길이를 반환한다.(null 문자는 제외한다.) 그 밖에도 strerror가 있지만 이는 나중에 <error.h> 헤더를 다룰때 소개할 것이다.
