1. 기본 개념
1.1 CPU 스케줄링이란
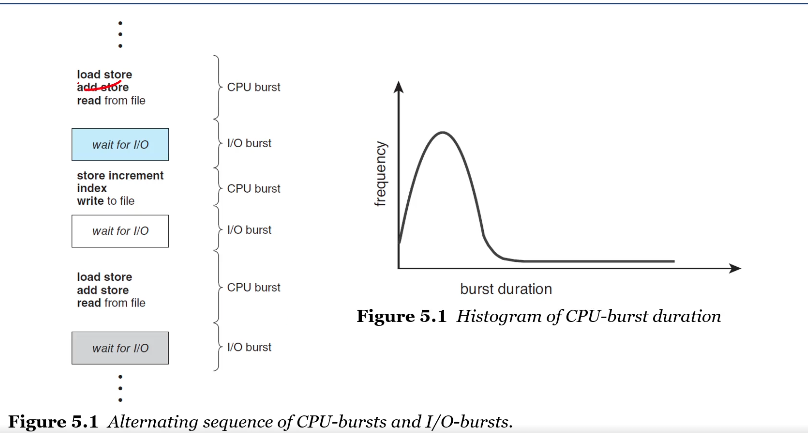
멀티 프로그래밍 운영체제의 기본이다. 멀티 프로그래밍의 목적은 여러 프로세스를 동시에 실행해서 CPU의 유틸을 증가시키기 위함이다.
1.2 CPU 스케줄러
CPU 스케줄러는 메모리 내의 ready 상태인 프로세스들 중 한 프로세스를 선택하고 CPU를 할당해주는것이다.
How? Linked list or Binary Tree?
-
FIFO Queue
-
Priority Queue : 그러면 우선순위를 어떻게 정하는 거지?
1.3 선점형 vs 비선점형
비선점형 스케줄링은 프로세스가 CPU를 선점하면 자발적으로 종료 혹은 대기 상태로 전환되기까지 내버려 둔다.
선점형 스케줄링에서는 선점된 CPU를 가져올 수 있다.CPU 스케줄러의 의사결정 과정은 4가지 경우로 나눌 수 있다.
(1) running -> waitng state
(2) running -> ready state
(3) waiting -> ready state
(4) process terminates(1)&(4) 는 비선점형이다.
(2)&(3) 은 선점형일수도 비선점형일수도 있다.1.4 디스패처(Dispatcher)
CPU 스케줄러에의해 선택된 프로세스에게 CPU 코어의 제어를 주는 것을 디스패처라고 한다.
디스패처의 함수는
(1) 문맥 교환(Context switch)
(2) 유저모드 전환(Usermode switch)
(3) 유저 프로그램을 계속 실행하기위한 적절한 위치로의 jump하지만 이 디스패처는 반드시 될 수 있는한 빨라야한다.
디스패치 지연시간은 프로세스를 정지하고 다른 프로세스를 시작하는데 걸리는 시간을 말한다.

2. 스케줄링 기준
스케줄링 목표는 다음과 같다.
CPU utilization: 유틸의 증가다.
Throughput: 단위시간당 완료되는 프로세스의 수를 증가시킨다.
Turnaround time: 어떤 프로세스를 실행-제출-종료의 시간을 줄이는 것
Waiting time: 어떤 프로세스가 ready queue에서 대기하는 시간을 줄이는 것이다.
responsive time: 응답하는데 걸리는 시간을 줄이는 것
3. 스케줄링 알고리즘
3.1 개요
ready queue에 있는 어떤 프로세스에게 CPU를 할당해주느냐가 문제다.
(1) FCFS:First Come, First-Served
(2) SJF: Shortest Job First(SRTF: Shortest Remaining Time First)
(3) RR: Round-Robin(시분할 관련)
(4) Priority-based
(5) MLQ: Multi-Level Queue
(6) MLFQ: Multi-Level Feedback Queue
3.2 FCFS
CPU에게 먼저 요청하는 프로세스에게 CPU를 먼저 할당한다. 이는 FIFO 큐를 통해 쉽게 구현이 가능하다.
FCFS 정책하의 Average Waiting Time는 일반적으로 CPU burst times이 커지면 매우 커진다. 최소화를 보장해주지 않는다.
FCFS는 비선점형이다.
CPU-bound 프로세스 하나와 많은 I/O-bound 프로세스들을 가지고 있다고 생각해보자.(Convoy 효과, 호송 효과)
3.3 SJF
SJF는 각 프로세스의 next CPU burst길이와 관련있다.
CPU가 가용상태일때, 가장 작은 next CPU burst를 가진 프로세스에게 할당해준다. 만약 그 크기가 같다면 그때는 FCFS를 사용한다.

SJF는 부분적으로 최적이다. SJF를 통해 average waiting time을 최소화 할 수 있기 때문이다.
하지만 next CPU burst의 크기를 알 수 있는 방법이 없는게 문제다. 따라서 예측을 통해 SJF를 근사적으로 적용하게 된다. 예측하는 방법은 다음과 같다. 먼저 이전에 측정된 CPU burst 크기의 지수평균을 낸다. 하지만 여전히 현실적으로 사용은 많지 않다.
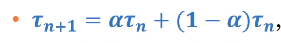
SJF는 선점형일수도, 비선점형일수도 있다. 선점형이 최적의 해에 더 가깝지만 남은 burst time을 구하는 것 또한 쉽지가 않다.
3.4 SRTF
SRTF에서, 새로 도착한 프로세스가 실행중인 프로세스보다 remaining time이 짧으면 CPU를 선점한다.
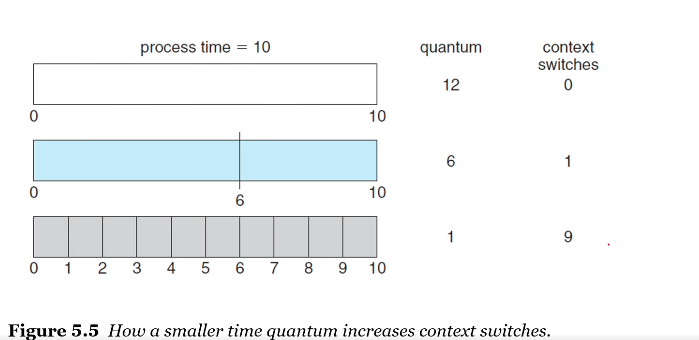
3.5 RR
RR은 선점형 FCFS(with time quantum)이다.
time quantum은 아주 작은 단위 시간이며 일반적으로 10에서 100밀리세컨드다.
ready queue는 순환 큐로 다뤄진다.
다음 두 개중 하나가 발생한다.
(1) 프로세스가 단위시간보다 작은 CPU burst를 가지는 경우, 프로세스는 자발적으로 종료한다.
(2) 프로세스가 단위시간 보다 큰 CPU burst를 가지는 경우, OS에 인터럽트를 생성하고, context switch가 발생한다. 그리고 실행중이던 프로그램은 ready queue에 들어간다.
평균 대기시간은 RR 정책하에서 종종 길어진다. RR은 선점형이다. 만약 프로세스의 CPU burst가 단위시간보다 크다면 다음 프로세스가 선점하게 된다.
RR 알고리즘의 성능은 time quantum(단위시간)의 크기에 크게 의존한다. turnaround time도 마찬가지.
3.6 Priority-based
각 프로세스에 우선순위를 부여하고, 높은 우선순위를 가진 프로세스에 CPU를 우선적으로, 동등하다면 FCFS를 적용해서 CPU를 우선적으로 할당한다. 사실 이는 특수한 SJF(predited)에서 한 것과 원리는 비슷하다.(여기에서는 burst time이 작게 예상되는 프로세스에 우선순위를 높게 부여했다)
우선순위에 따라 스케줄링을 할 때에는 선점형/비선점형을 선택해야한다. 문제는 이때 기아 문제(indefinite blocking)가 발생 할 수 있다. 우선순위가 낮은 프로세스는 자칫하면 계속 ready queue에 머물 수 있다. 이를 해결하는 방법은 시스템 내 대기시간이 길어질수록 우선순위를 높여주는 정책을 적용하는 것이다.(aging)
단일 알고리즘만 적용하는 것이 아닌 RR과 Priority-based를 결합할 수도 있다.
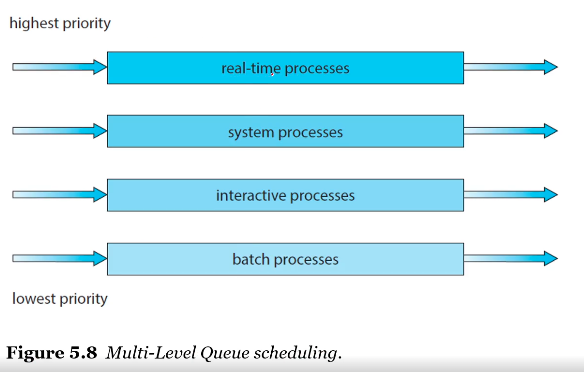
3.7 MLQ: Multi-Level Queue

3.8 MLFQ: Multi-Level Feedback Queue
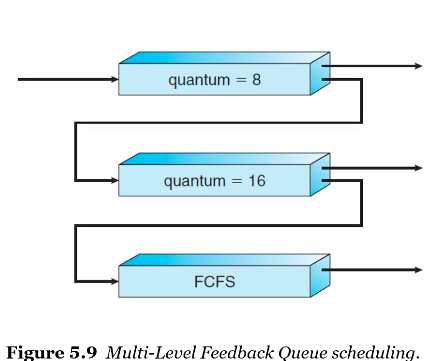
4. 스레드 스케줄링
현실에서는 스레드를 지원하므로 스레드 스케줄링을 더 많이 한다. 스레드는 커널 스레드가 스케줄 대상이 된다. 유저 스레드는 스레드 라이브러리에 의해 관리되지, 커널은 유저 스레드를 인지하지 않으며, 연결되어있는 커널 스레드와 매핑만 시켜줄 뿐이다.
5. real-time 스케줄링
여기서 실시간이란, 주어진 시간 내에 task를 완수할 수 있어야 한다.
(1) soft real-time
중요한 실시간 프로세스가 정해진 시간 내에 수행될 것을 보장하지는 못하나 중요하지 않은 다른 프로세스보다 먼저 수행될 것을 보장한다.
(2) hard real-time
주어진 task는 반드시 기한 내에 수행되어야 한다.
이와 관련된 일화로, 화성 패스파인더 미션의 우선순위 역전 버그가 있다.
