Abstract
Agentic 한 작업들이 복잡해짐에 따라, tool call 즉 API call 이 점점 복잡해지고 각각을 식별하고 호출하는 것에 대한 어려움이 존재한다.
따라서, 단순한 텍스트 형태의 API 문서 대신, 구조화 된 API Graph 형태로 변환할 것을 제안한다.
이 그래프는 API 간의 파라미터(매개변수) 관계를 명확히 보여줘야 한다. (예: API A의 출력이 API B의 입력으로 들어가야 함을 구조적으로 표현)
이를 벤치마킹하는, In-N-Out 데이터 셋은 API 벤치마크와 문서를 바탕으로 전문가가 직접 주석을 단 최초의 API 그래프 벤치마킹 데이터셋이다.
API 그래프를 사용했을 때, Tool retrieval 및 다중 도구 쿼리 생성 성능이 단순히 문서만 사용했을 때보다 거의 2배 가까이 향상되었다.
1. Introduction
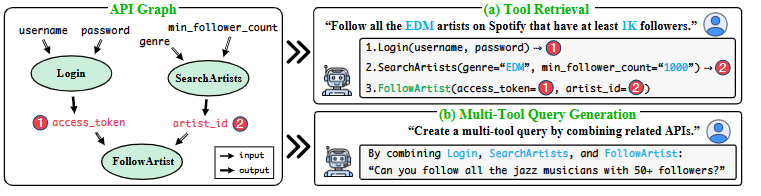
다음 그림을 확인해 보면, 도구 에이전트는 Tool Retrieval 을 적절하게 실행하기 위해서, 계층적인 구조의 파악이 필수적이다. (종속성의 파악) 하지만 이러한 파라미터 연결에 대한 명시적인 말이 없다면, 올바르게 연결하지 못하는 경우가 대다수이다.
이에 대해 대규모 Tool 이 존재하는 작업 환경에서 agent 를 훈련시키는 것보다 일반화가 가능하고, 확장 가능한 방법으로 그래프 API 는 Multi Tool Query Generation 도 촉진 시킬 수 있다.
이에 대해 데이터셋의 구축의 이유가 발생한다. 그래프를 그리는 것이 필수적이지만, 모든 API 에 대해서 사람이 일일이 그래프를 그리는 작업이 불가능하다. 따라서, 문서를 보고 자동으로 그래프를 그려주는 변환 모듈 이 필수적이다. 이러한 변환 모듈을 제작하기 위한 fine-tune 하는 고품질 셋으로써, 전문자가 검증한 데이터셋인 In-N-Out 을 만든 것이다. In-N-Out 데이터셋은 노드 (각각의 API 와 파라미터) 와 엣지 로 이루어져 있다.
이러한 In-N-Out 데이터셋을 사용하였을 때의 효과는 다음과 같다.
-
In-N-Out 데이터를 사용하였을 때, Tool Agent 의 Tool Retrieval 성능 향상에는 그래프 형태의 API 가 문서 형태 API 보다 효과적이다.
-
In-N-Out 데이터 셋을 사용하여 학습시킨 LLM 을 통하여 생성된 그래프 API 역시, 문서 API 보다 Tool Retrieval 에 효과적이다.
2. Related Work
2.1 Tool Retrieval and Planning
복잡한 Tool Call 순서를 유지하기 위해서 기존 접근 법은 다음과 같다.
- API 문서화를 개선
- 질문과 API 호출 쌍을 학습시켜 미세조정하는 방식
- 도구 별 임베딩을 만들어서 학습시키는것
이것들의 근본적인 문제점은, API 와 API 간의 근본적인 종속성을 파악하기 어렵다는 문제점이 있다. 즉, 일반화 능력이 떨어진다.
이에 대해, In-N-Out 데이터 셋은 API 관계성을 그래프로 표현하려는 시도는 있었지만, 실제 API 를 대상으로 하는 전문가의 주석이 달린 데이터 셋으로써의 의의를 지닌다.
2.2 Multi-Tool Query Generation
Agent 를 학습시키거나, 평가하기 위해서는 여러 API 를 사용하여 해결 가능한 복잡한 query, 즉 Multi-Tool Query 가 필요하다. 이때 기존 접그넙과 기존 그래프 기반 생성법과 다르게 In-N-Out 에서는 전문가가 파라미터 수준에서 직접 연결 가능 여부를 확인하여 의미적으로 정확하고 실행 가능한 쿼리를 생성할 수 있다.
3. In-N-Out Dataset
In-N-Out 데이터 셋은 매개변수 수준의 API 그래프를 구성하기 위해서 특정 API의 출력 변수가 다른 API 의 입력에 해당하는 경우를 포착하는 것을 목표로 한다.
이러한 API 간의 파라미터 수준 연결을 필터링하고 주석을 달기위해서 특정한 파이프라인을 설계하였다. 문서 개선 - 후보 쌍 필터링 - 사람(전문가) 주석 의 형태의 파이프라인으로 진행된다.
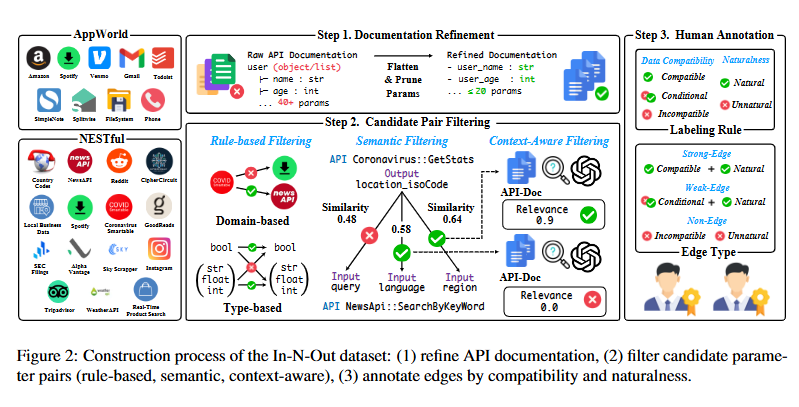
3.1 Document Refinement
원본 API 문서에는, 각각의 형식이 제각각이고, 불필요한 정보가 많다. 예를 들어 실행 상태 플래그, 타임 스탬프 등등은 이후에 타 API 와 연결될 가능성이 적다.
따라서 이를 해결하기 위해, 평탄화 작업을 거치게 된다. 평탄화 작업이란, API 응답이 ObjectID 또는 List 형태인 경우 쪼개어 펼쳐 bool, int, str, float 와 같은 기본 유형만으로 유지한다.
다음으로는, 타 API 와 연결될 가능성이 적인 output 값들, status flag, timestamp 등등을 pruning 시킨다. 이는 API 의 핵심 기능을 유지하면서, 현실적인 Tool 사용 맥락에서 다른 API 의 입력으로 사용될 때 노이즈가 될 만한 후보를 제거하는데에 의의가 있다.
마지막으로, 파라미터에 대한 설명이 부족한 경우 GPT-4o mini를 사용해 간결한 설명을 자동으로 생성하여 보완했다.
3.2 Candidate Pair Filtering
문서 개선 이후, 모든 API 의 출력과 입력을 1:1 로 매칭하여 확인하기에는, 경우의 수가 너무 많다. 이를 사람이 모두 검토할 수 없으므로, 우선 후보 쌍을 필터링 하여 가능성이 없는 Input-Output 쌍을 걸러낸다.
-
Rule-based Filtering : 규칙 기반으로, API가 호환되지 않는 도메인에 속하거나 유형이 일치하지 않아 불가능한 쌍을 제거한다. 예를 들어서 코로나 바이러스 정보 와 Spotify API 간의 연결성은 제외하였다. 또한, Input 으로 str 를 받아오는데 Output 이 int 인, 즉 입력 API 와 출력 API 간의 데이터 형식의 매칭이 맞지 않은 경우를 제외하였다.
-
Semantic Filtering : 의미론적 필터링으로, SBERT 를 사용하여 각 파라미터를 이름과 설명을 기반하여 벡터 임베딩으로 인코딩 하고, 각 임베딩 간의 코사인 유사도 값이 threshold 값인 0.5 값을 넘지 않을 경우 제외하였다. 이 0.5 라는 값은 NESTful 및 AppWorld의 주석이 달린 호출 시퀀스에 나타나는 모든 API 파라미터 쌍이 유지되도록 선택된 값이다.
-
Context-aware Filtering : 임베딩 유사도만으로는 어휘적으로는 관련 있어 보이지만 실제 의미는 다른 쌍이 유지 될 수 있다. 따라서, 단어의 실제 Semantic 한 유사도가 아닌, 문맥적인 유사도가 필요하다. 따라서 두 API 의 전체 문서를 GPT-4o mini에 프롬프트로 제공하고 각 쌍의 관련성을 0–1 척도로 평가하도록 요청한다.
3.3 Human Annotation
다음 과정을 통해서 진행된 필터링 후 남은 파라미터 쌍에 대해서 인간이 주석을 다는 프로세스를 진행했다. 각 후보 쌍에 대해서는 데이터 호환성과, 자연스러움 두가지 기준에 따라 평가된다.
데이터 호환성 은 앞의 API 의 출력이 뒤의 API 의 입력에 기술적으로 문제없이 들어가는가에 대해서 평가한다.
자연스러움 은 실제 개발자가 코드를 짜게 될 때 연결성이 자연스러운가를 평가한다.
이러한 두가지의 기준에 따라서, 필터링 된 후보 쌍들을 모두 레이블링 하였다. 3가지의 형태로 레이블링되었는데, 레이블들은 다음과 같다.
- Strong-Edge: 호환도 되고 자연스러운, 가장 확실한 연결.
- Weak-Edge: 조건부로 호환되지만(값에 따라 다름) 자연스러운 연결.
- Non-Edge: 호환되지 않거나, 억지로 연결한 부자연스러운 경우.
이러한 레이블링을 통해 tool-agent 추론을 위해 유효한 파라미터 level 의 API graph 를 생성하게 된다.
3.4 Data Statistics
이렇게 레이블링된 데이터셋의 특징은, 희소성 이다. 수백만개의 가능한 1대1 조합중에, 실제로 유효한 (Strong Edge or Weak Edge) 는 1~2% 에 불과하다. 즉 문서 API 로는, 수많은 오답 중에 정답 연결을 찾기가 어려웠던 것이다.
기반 데이터 셋인 AppWorld 와 NESTful 을 비교하면
- AppWorld: API 간 연결이 촘촘하고 도메인을 넘나드는 연결(Cross-domain)이 많다.
- NESTful: 상대적으로 연결이 드문드문하고(Sparse) 파편화되어 있다.
두 데이터 셋을 모두 포함함으로써, In-N-Out 은 다양한 상황에서 Tool Use 능력을 파악할 수 있다.
4. Experiments
연구진은 구축한 In-N-Out 데이터셋의 효용성을 입증하기 위해 "LLM이 API 그래프를 스스로 만들 수 있는가?"와 "이렇게 만든 그래프가 실제 도구 사용 능력을 향상시키는가?"를 검증하는 데 초점을 두어 4가지 실험을 진행했다.
4.1 Benchmarking API Graph Construction
LLM이 API 문서만 보고 파라미터 간의 연결 관계(Strong, Weak, Non-edge)를 얼마나 잘 예측하는지 평가한 실험이다. 이후에는 In-N-Out 데이터 셋을 사용하여 fine-tune 시킨 이후 평가하였다.
GPT-4o 같은 고성능 모델조차도 사전 학습 없이 문서만 보고 예측했을 때는 정확도가 낮았다. 오픈소스 모델은 이보다 더 낮았는데, 이는 문서만으로는 복잡한 의존성을 파악하기 어렵다는 것을 보여준다.
이후 In-N-Out 데이터셋으로 학습시킨 모델(Qwen2.5-32B 등)은 성능이 비약적으로 상승하여, 정답률이 76%~94% 수준까지 도달했다.
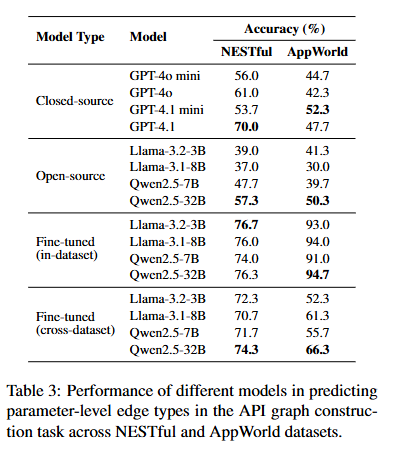
AppWorld 에서의 파인튜닝이 전반적으로 큰 성능향상을 보여주는 이유는, AppWorld의 그래프가 NESTful 보다 많은 API 와 Edge 를 포함하여 학습 중 모델이 더 풍부한 의존성 다양성이 노출될 가능성이 높기 때문이다.
여기서 추가 실험 결과로, Cross dataset, 즉 AppWorld 를 파인튜닝 시킨 모델은 NESTful 을 validate 하고, NESTful 을 파인튜닝 시킨 모델은 AppWorld 를 validate 시켰을 때도 성능이 크게 향상되었다.
4.2 Tool Retrieval with API Graphs
현실적인 Tool 사용 시나리오에서 복잡한 작업을 해결하려면 종종 여러 API를 순차적으로 호출해야한다. 이때, 특정 API 를 실행하기 위해서 필요한 재료를 제공하는, 선행 API 를 찾는 능력을 측정한다.
이때 Tool Retrieve 를 진행할때, LLM 의 입력으로 전체 API 세트, 즉 문서에 대한 입력은 컨텍스트 길이 제한으로 인해, query 에 대한 SBERT 코사인 유사도를 사용하여 순위를 매긴다.
그래프를 활용하는 경우, 기본 검색 결과에서 API 그래프 상 타겟 API 와 연결된, 즉 입력으로 줄 수 있는 API 가 있다면 그 API 의 순위를 맨 위로 올려 Re-ranking 을 진행한다.
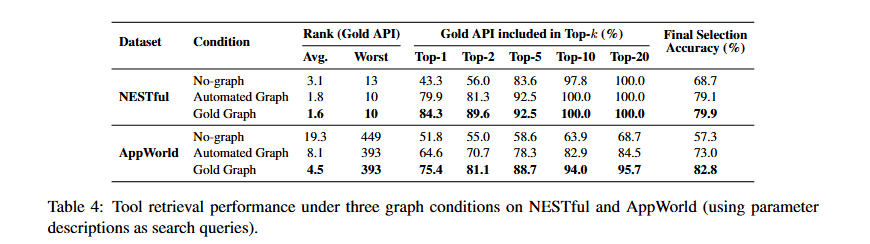
대조군은 다음과 같다.
- No-graph: 그래프 정보 없이 텍스트 유사도만 사용한 것
- Gold Graph: 전문가가 만든 정답 그래프 사용한 것.
- Automated Graph: 4.1절에서 만든 파인 튜닝 모델이 예측한 그래프 사용한 것.
실험을 평가하는 방법은 다음과 같다.
- 임베딩 유사도로 순위가 매겨진 모든 후보 중에서 올바른 API의 평균 순위 및 최악 순위
- Top-k 정확도
- GPT-4o mini가 상위 5개 목록에서 올바른 API를 선택하는 최종 선택 정확도
결과적으로, 더 정확하게 그래프를 구성하게 될 수록 Tool Retrieve 에서 추가적인 이득을 볼 수 있고, 이는 그래프 기반 검색이 Tool Agent 를 발전시키는 방향이 될 것이다.
4.3 Structured API Subset Selection for Multi-Tool Query Generation
단순히 필요한 하나의 API 를 찾는 것이 아닌, 복잡한 작업을 해결하기 위해서 여러 도구를 병렬적으로, 혹은 직렬적으로 연결해야할 때 API 그래프의 효용성을 탐구한다.
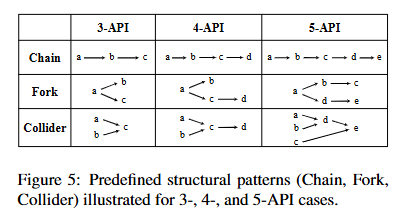
모델은 주어진 API 문서를 바탕으로 다음 조건을 만족하는 API 부분집합 5개를 찾아내야한다.
- API 개수 (): 3개, 4개, 또는 5개의 API로 구성된 세트.
- 구조적 패턴 (): API들이 서로 연결되는 방식이 미리 정의된 3가지 패턴 중 하나여야 한다.
이러한 실험 구조로 부터, 3-API, 4-API, 5-API 케이스에 대해 각각 15,20,25 개의 전체 API 풀을 제공한다.
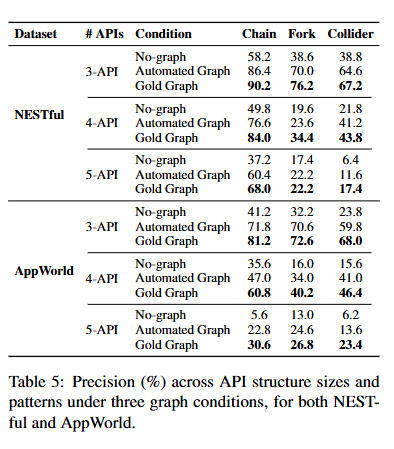
해당 Table 의 결과는 그래프 정보에 대한 접근이 구조적 패턴과 부분 집합 크기에 걸쳐 정밀도를 크게 향상 시킨다는 사실을 보여주게 된다.
4.4 End-to-End Performance Evaluation
실제 상황에서 End-to-End 를 평가 하기 위해서, Multi-Turn Tool use 를 실제 사용자-Agent 에 대해서 평가하는 τ - bench 에 대해서 평가를 수행한다. 이는 모델이 각 턴마다 사용자에게 응답할지, 도구(API)를 호출할지 자율적으로 결정하는 에이전트 사용을 평가한다.
이때 τ - bench 에는 출력 매개변수 정보가 없기 때문에, 각 API 호출 결과를 검사하여 확장한 문서를 수동 생성한다. 이후 모두 가능한 입력-출력 매개변수 쌍에 대해서 파인 튜닝된 Qwen-2.5-32B 모델을 사용하여 Strong-Edge 로 분류되는 것만 유지하였다. 이후 API 간의 의존성 정보를 힌트로 문서에 추가한다.
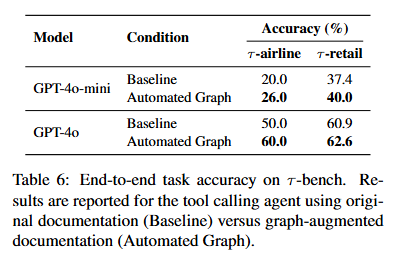
결과는, 그래프 정보를 추가하면 성능이 일관되게 향상한다. 특시 airline 에서 GPT-4o 사용 시 50% → 60% 정확도 상승하는 의미 있는 결과가 있었다.
5. Conclusion
결론적으로, 해당 논문은 현실적인 입력-출력 API 간 의존성을 그래프화 시킨 데이터셋인 In-N-Out 의 소개이다. 이러한 연결을 명시적으로 Edge 화 시킴으로써, LLM 을 해당 데이터 셋을 통해 파인 튜닝 시킬 때 API 문서의 이해도의 상승을 꾀했다.

인앤아웃버거보다맛있네요