Abstract
- 문제점: Ability to access and precisely manipulate knowledge is still limited, 이해하기로는 생성하는 것이 아닌 "지식" 자체를 이해하고 조작하는데 무리가 있다.
- 해결 방안: retrieval-augmented generation (RAG) — models which combine pre-trained parametric and non-parametric memory for language generation.
- 이때 parametric memory 는 pre-trained 된 seq2seq model 이며, non-parametric memory 는 Wikipedia dataset 의 dense vector 이다.
1. Introduction
- pre-trained lm 은 data 의 심층적인 이해 및 학습으로 이루어진다고 생각되었다.
- 이때 data 의 심층적인 이해 및 학습은, externel memory 에서 가져오는 것이 아닌, implicit knowledge base 에 parameterized 되어져 있다.
- 이러한 pre-trained implicit model 의 단점은, memory update 가 제한적이면서, 환각을 생성할 가능성이 있다.
- Hybrid model (parametric + non-parametric model) 들은 이러한 지식을 수정, 확장 가능하게 하고, knowledge 를 검사하는 방법을 통해서 이러한 문제를 해결할 수 있다. 이러한 model 을 ODQA 에 국한하지 않고, seq2seq model 에 접목시킨 방법이 RAG 라고 한다.
- 본 논문에서는 Prametric memory가 사전 학습된 seq2seq transformer이고 non-parametric memory가 사전 학습된 neural retriever를 통과한 Wikipedia의 dense vector index인 RAG 모델을 구축한다.
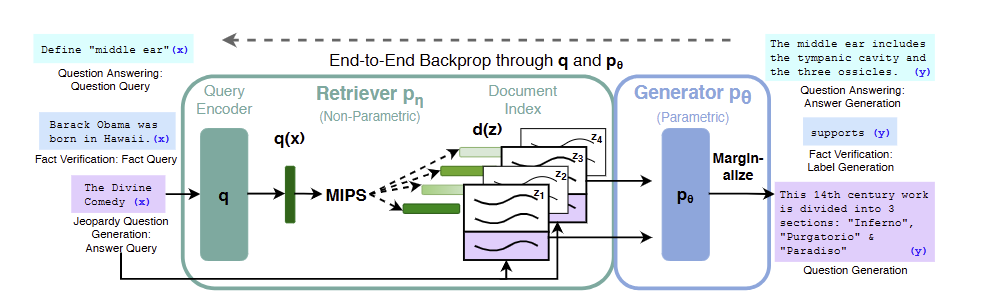
- RAG model 만의 방법으로는, parametric 과 non-parametric 모두 사전학습되고, pre-loaded 되는 방법론을 사용한다.
- 즉, 독창적인 방법만으로, 지식의 update 를 위해서는 non-parametric memory update 를 통해 지식의 update 를 가능하게 하였다.
2. Methods
- input sequence 를 사용하여 text passage (논문의 경우 wikipedia 의 dense vector) 를 검색하고, target sequence 를 생성한다.
- RAG 에는 크게 두가지의 components 들로 이루어져 있는데,
- query 에 대해서 distribution 을 반환하는 parametrer 를 가지는 retriever
- previous token , origin input , retrieved passage 의 context 를 통한 현재 token 로 parameterized 된 generator
- 본 논문에서는 retriever 과 generator 를 end-to-end 로 학습시키기 위해서 검색된 document 를 "잠재적인 변수" 로 취급한다. 이러한 생성된 텍스트에 대한 분포를 생성하기 위한 latent document 를 취급하는 방식이 두가지이다.
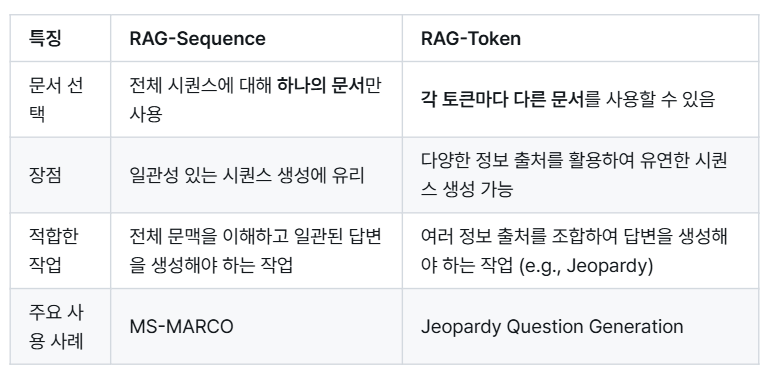
- RAG-Sequence : 모델이 동일한 문서를 사용하여 각 target token 예측
- RAG-Token : 모델이 다른 문서를 사용하여 각 target token 예측
2.1 Models
-
RAG-Sequence Model : RAG-Sequence model 의 경우 동일하게 검색된 문서를 사용하여 target sequence 를 생성한다. top-K approximation 을 통해 seq2seq prob 를 얻기 위해서 검색된 passage 자체를 marginalized 시켜서 사용한다.
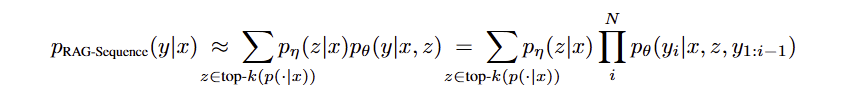
-
RAG-Token Model : RAG-Token Model은 각 target token에 대해 다른 latent passage를 사용한다. 이를 통해 generator는 답변을 생성할 때 여러 document에서 내용을 선택할 수 있다.
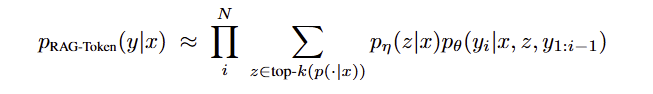
-
2.2 Retriever: DPR
- 검색의 구성요소 는 DPR 을 기준으로 하고, DPR 은 bi-encoder architecture 를 사용한다.
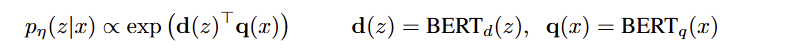
- 여기서 는 BERT-BASE transormer 에 생성된 document 의 dense representation 이고, 는 다른 매개변수를 가진 BERT-BASE transformer 에 의해 생성된 query representation 이다.
- 본 논문에서는 가장 높은 prob 를 갖는 top-K 의 document 를 효율적으로 계산하기 위해서 FAISS 내 MIPS index 를 사용했다.
2.3 Generator: BART
- retrieve 이후 BART를 통해 생성할때 input 와 document 를 concat 해서 사용한다.
2.4 Training
- 검색된 문서쌍 는 unsupervised 되고, Retriever와 Generator를 공동으로 학습한다. 입력/출력 쌍인 가 주어지면 Adam optimizer 를 사용해서 loss function 를 최소화 하는 stochastic gradient descent 를 사용한다.
2.5 Decoding
-
Test 및 Decoding 하는 방법에서 각 모델에 따라서 각각 를 근사하는 방법이 다르다.
-
RAG-Token
- RAG-Token Model은 transition probability를 가진 auto-regressive seq2seq generator로 볼 수 있다.
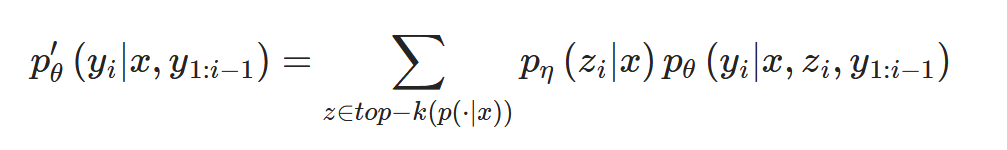
- Decoding 단계에서 해당 확률값을 standard beam decoder를 사용하여 구할 수 있다.
-
RAG-Sequence
- 각 candidate document 에 대해서 beam search 를 사용해서 에 대해 각각의 beam 을 scoring 한다.
- 이때 모든 beam 에 대한 가설 의 확률을 추정하기 위해서 beam 에 없는 document 에 대해 추가적인 forward pass 를 수행하고, 이러한 문서에 대해서 generator 확률을 계산하여 검색 확률과 곱해준다. 이를 "Thorough Decodig" 이라고 한다.
- Thorough Decoding은 출력 시퀀스가 길어질수록 계산량이 많아지므로, 더 효율적인 디코딩을 위해 = 0 이라는 추가적인 근사치를 적용한다. (이때 y 는 x,z 에 대한 beam search 로부터 없는 값) 이러한 근사치가 적용된 후, candidate set 가 생성된 후에는 추가적인 forward pass를 실행할 필요가 없고, 이를 "Fast Decoding" 이라고 한다.

개인적으로 저는 golden retriever 선호합니다