[BOJ 1920] 수 찾기
💡 문제
N개의 정수 A[1], A[2], …, A[N]이 주어져 있을 때, 이 안에 X라는 정수가 존재하는지 알아내는 프로그램을 작성하시오.
💻 입력
첫째 줄에 자연수 N(1 ≤ N ≤ 100,000)이 주어진다. 다음 줄에는 N개의 정수 A[1], A[2], …, A[N]이 주어진다. 다음 줄에는 M(1 ≤ M ≤ 100,000)이 주어진다. 다음 줄에는 M개의 수들이 주어지는데, 이 수들이 A안에 존재하는지 알아내면 된다. 모든 정수의 범위는 -2^31 보다 크거나 같고 2^31보다 작다.
💻 출력
M개의 줄에 답을 출력한다. 존재하면 1을, 존재하지 않으면 0을 출력한다.
🤔 내가 생각한 로직 이라고 쓰고 삽질이라 읽는다
처음에는 이게 왜 브론즈가 아니지? 정답률은 왜 이렇게 낮지?? 하며 무지성으로 linear search(선형 탐색)방법으로 신나게 자판 두드리고 답변 제출했다.
그 결과...
//1920 수 찾기
#include <iostream>
using namespace std;
int n, m;
int a[100004];
int b[100004];
int main() {
ios_base::sync_with_stdio(false); cin.tie(0);
cin >> n;
for(int i = 0; i < n; i++) cin >> a[i];
cin >> m;
for(int i = 0; i < m; i++) cin >> b[i];
for(int i = 0; i < m; i++) {
bool flag = false;
for(int j = 0; j < n; j++) {
if(b[i]==a[j]) flag = true;
}
if(flag) cout << 1 << "\n";
else cout << 0 << "\n";
}
}
Uh...Oh... 역시나 무대를 뒤집어놓으신 결과가 나왔다.

나 같은 무지성 탐색러를 잡아내기 위한 문제였나보다.
선형 탐색이 시간 초과가 떴다면 빠른 이진 탐색으로 구현하는 건가? 싶어서 이제 이진 탐색으로 구현해봤다.
🚩이진 탐색(binary search)
- [전제 조건] 요소들이 작→큰 순서대로 정렬되어있어야 한다.
전제 조건에 의하여, 우선 요소들을 예쁘게 오름차순으로 정렬해준다.
//c++ algorithm 헤더에 있는 sort함수를 이용하여 정렬해준다.
sort(a, a+n);- 탐색 범위
start와end를 설정한 후,mid을 중심으로 우리가 찾는key값이mid보다 큰지 작은지 따져서 탐색범위인start와end값을 조정한다. - 탐색은 범위
start와end가 같아지면 종료한다.
bool binary_search(int key, int a[]) {
int start = 0;
int end = n-1;
int mid;
while(start <= end) {
mid = (start+end)/2;
if(a[mid] == key) { //찾았따!
return true;
} else if(a[mid] < key) { //key가 mid보다 오른쪽에 있으니까, start를 증가시켜준다.
start = mid+1;
} else { //key가 mid보다 왼쪽에 있으니까, end값을 감소시켜준다.
end = mid-1;
}
}
return false;
}💻 정답 코드
//1920 수 찾기
#include <iostream>
#include <algorithm>
using namespace std;
int n, m;
int a[100004];
int b[100004];
bool binary_search(int key, int a[]) {
int start = 0;
int end = n-1;
int mid;
while(start <= end) {
mid = (start+end)/2;
if(a[mid] == key) {
return true;
} else if(a[mid] < key) {
start = mid+1;
} else {
end = mid-1;
}
}
return false;
}
int main() {
ios_base::sync_with_stdio(false); cin.tie(0);
cin >> n;
for(int i = 0; i < n; i++) cin >> a[i];
cin >> m;
for(int i = 0; i < m; i++) cin >> b[i];
sort(a, a+n); //이진탐색의 전제조건에 의하여 오름차순으로 일단 배열을 정렬해준다.
for(int i = 0; i < m; i++) {
if(!binary_search(b[i], a)) cout << 0 << "\n";
else cout << 1 << "\n";
}
}🥲 사실 이미 라이브러리 구현되어있다.
사실 이진탐색 알고리즘은 <algorithm> 헤더에 구현되어있다고 한다.
/* 이진 탐색 함수 템플릿 */ binary_search(이터레이터 시작 주소, 이터레이터 종료 주소, key값);
예를 들어 크기가 N인 arr배열에 10이 있는지 없는지 알아보기 위해서는,
binary_search(arr, arr+N, 10); ← 이렇게 사용하면 된다.
✨ 만약 key(찾으려고 하는)값이 여러 개라면?!
이진 탐색이 데이터 내에서 특정 값을 정확히 찾는 것이라면, lower_bound upper_bound는 중복된 자료가 있을 때 유용하게 탐색할 수 있는 알고리즘이다.
또한, 특정 자료값이 몇번 나왔는지 구하는 데에도 유리하다.
lower_bound(K): 데이터 내 특정 K값과 같거나 큰 값이 처음 나오는 위치를 리턴upper_bound(K): 데이터 내 특정 K값과 같거나 처음으로 큰 값이 나오는위치를 리턴
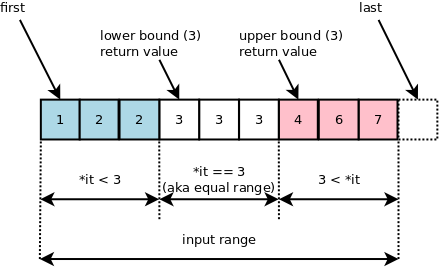
위의 그림과 같이 중복된 값이 있는 배열이 정렬된 상태에서, lower_bound(3)은 index=2를 리턴해주고, upper_bound(3)은 index=6을 리턴해준다.
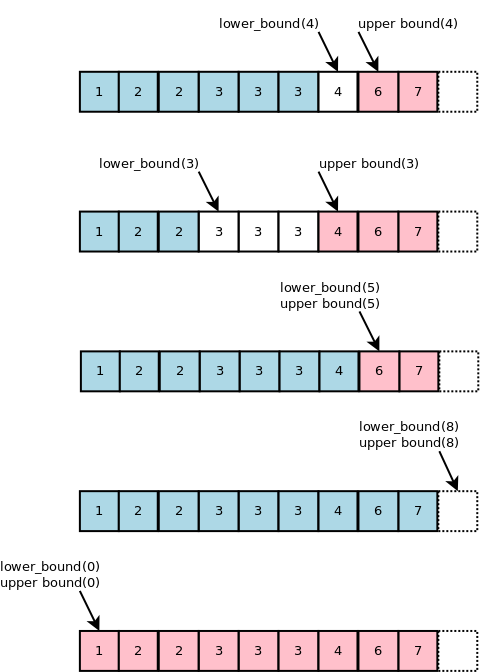
다음과 같으므로 중복된 값 포함하여 이진 탐색값을 출력하려고 할 때는,
/* upper_bound랑 lower_bound 활용하기 */
upper_bound(arr, arr+N, key)-lower_bound(arr, arr+N, key);이렇게 이용하면 된다.
이를 이용한 문제는 다음 문제를 풀어보자!
BOJ 10816 숫자카드 2>>
💻 정답 코드
#include <iostream>
#include <algorithm>
#include <vector>
#include <cmath>
using namespace std;
int n, m;
int a[500001];
int main() {
ios_base::sync_with_stdio(false); cin.tie(0);
cin >> n;
for(int i = 0; i < n; i++) cin >> a[i];
sort(a, a+n);
cin >> m;
while(m--) {
int key;
cin >> key;
binary_search(a, a+n, key);
cout << upper_bound(a, a+n, key)-lower_bound(a, a+n, key)<< " ";
}
return 0;
}