[UMC Server(Spring Boot) 5주차] 실전 SQL- 어떤 SQL을 작성하여야 할까?
앞선 4주차에서 우리는 다음과 같은 erd 다이어그램을 설계했다:
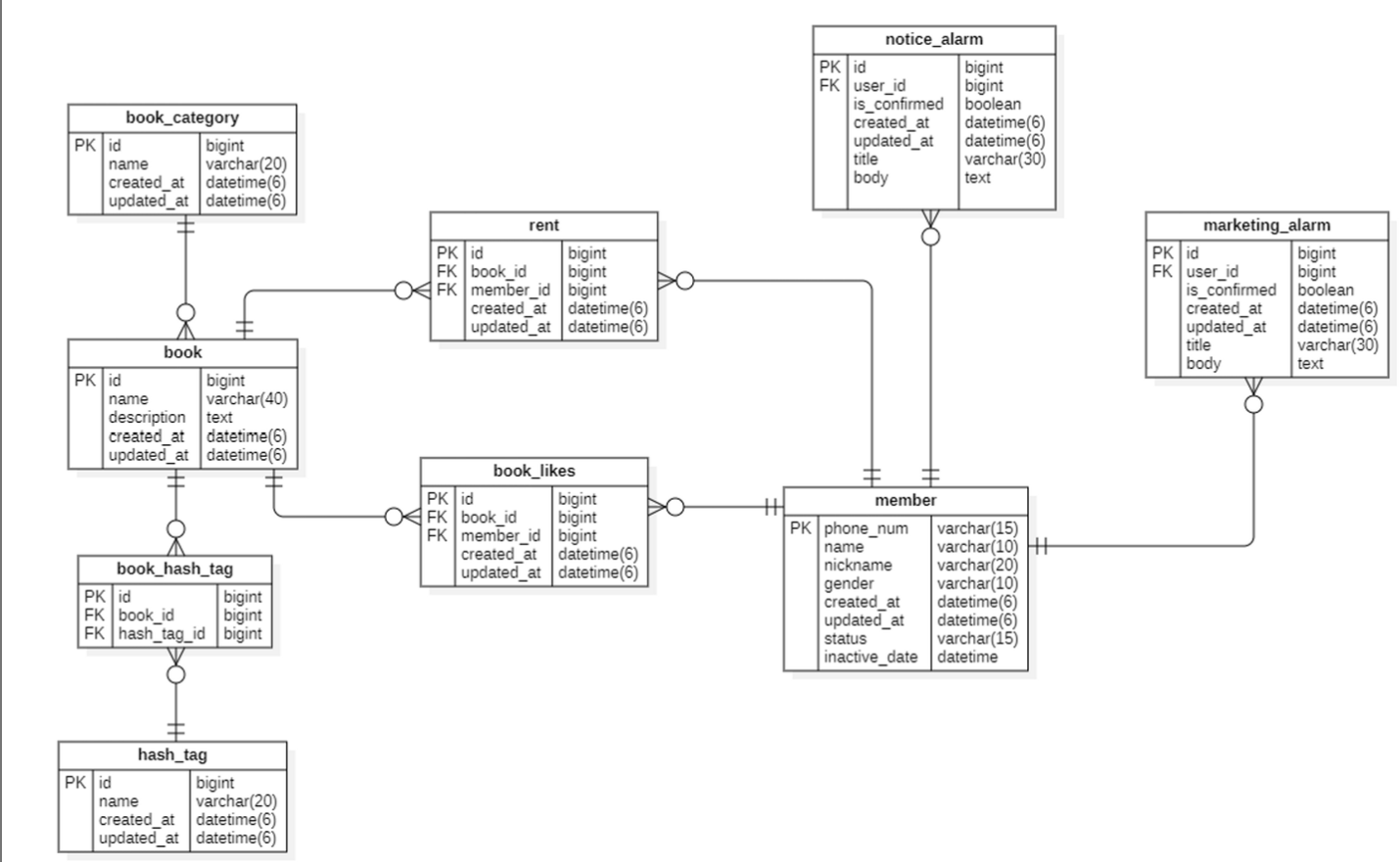
이제 5주차에서는 해당 다이어그램을 바탕으로, 진짜 sql문을 작성해보는 시간을 가지자.
이번주차의 핵심내용을 요약하자면 다음과 같다:
🎯요구사항에 알맞는 SQL 쿼리 설계
(중복처리, 페이징 고려)
📖 학습 내용
백엔드 개발자 A씨! 당신은 PM으로부터 이런 요구사항을 받았다.
책이 받은 좋아요 개수를 보여준다.
해당 요구사항에 대하여 어떤 query문들이 나올 수 있을지 생각해보자.
[1] 책 테이블에 좋아요 개수를 둔다면, 해당 query가 나온다:
select likes
from book;
# book 테이블에서 likes 칼럼에 해당하는 것[2] likes라는 칼럼없이 집계한다면, 조건문을 붙여주어 다음과 같이 설계한다:
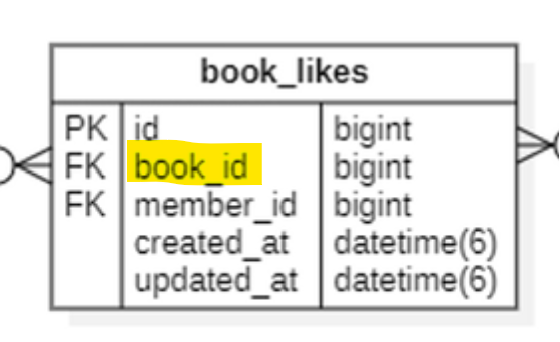
select count(*)
from book_likes
where book_id = {대상 책 아이디};
그런데 만약, 추가적인 요구사항이 주어졌다면 어떻게 할까?
책의 좋아요 개수를 계산하는데, 내가 차단한 사용자의 좋아요 개수는 집계하지 않는다.
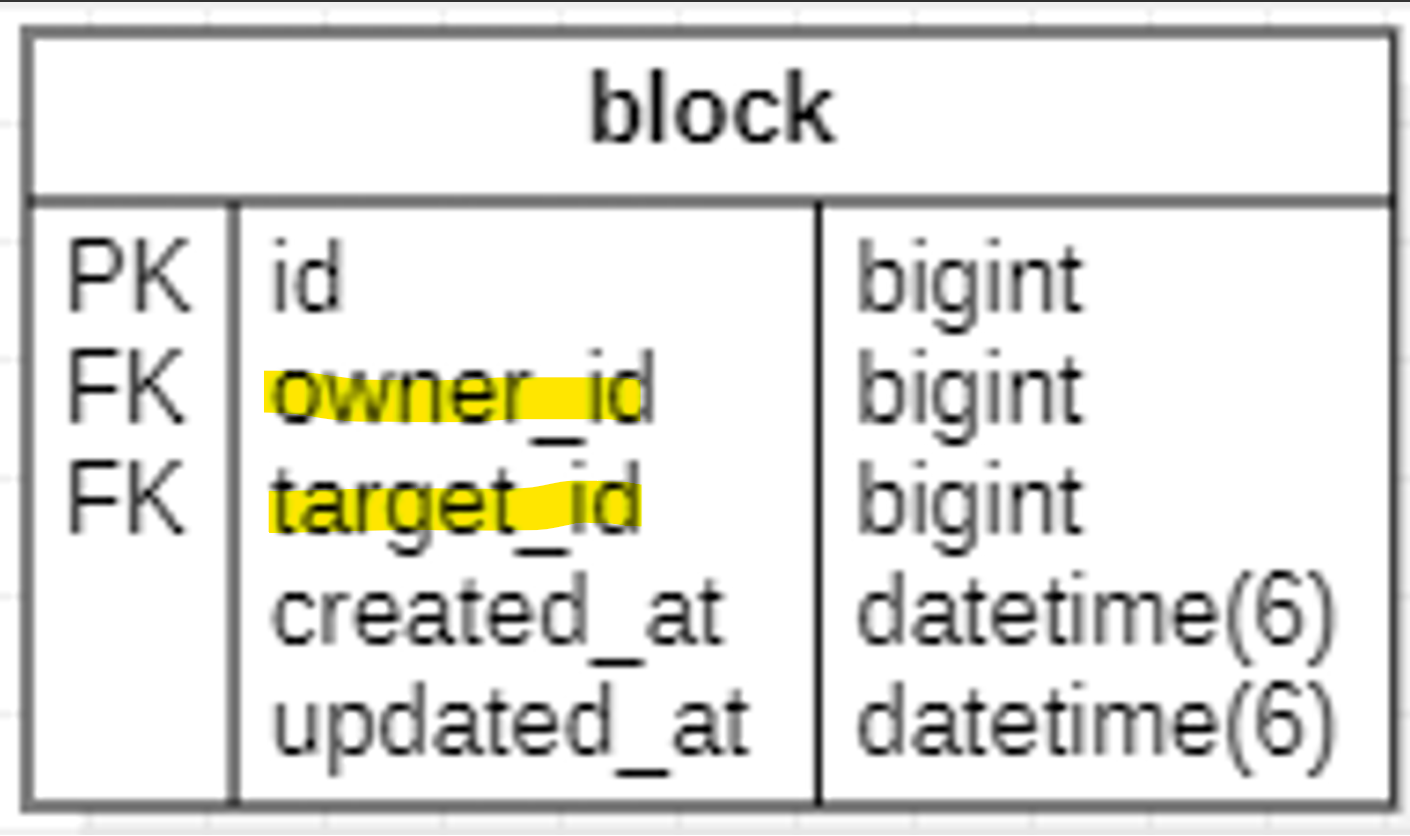
책의 아이디가 sql, 내 아이디가 venew라고 가정했을 때, subquery를 이용한 SQL문은 다음과 같이 나온다:
# sub query 이용 時
select count(*)
from book_likes
where book_id = sql
and user_id not in
(select target_id
and owner_id = venew;)inner join을 이용하여 변경하면:
# inner join 이용
select count(*)
from book_likes as bl
inner join block as b
on bl.user_id = b.target_id
# 좋아요를 누른 사람의 id = 차단당한 사람의 id
and b.owner_id = venew
# 차단한 사람의 id = venew
where bl.book_id = sql
# 해당 책의 id가 sql일때
and b.target_id is null;
해시태그를 이용한 책의 검색
쿼리를 작성할때 N:M 관계로 인해 가운데 매핑 테이블이 추가된 경우, 간단한 쿼리로 데이터를 가져오기가 어려워짐.
가령, BackEnd라는 이름을 가진 해시태그가 붙은 책을 찾도록 해보자.
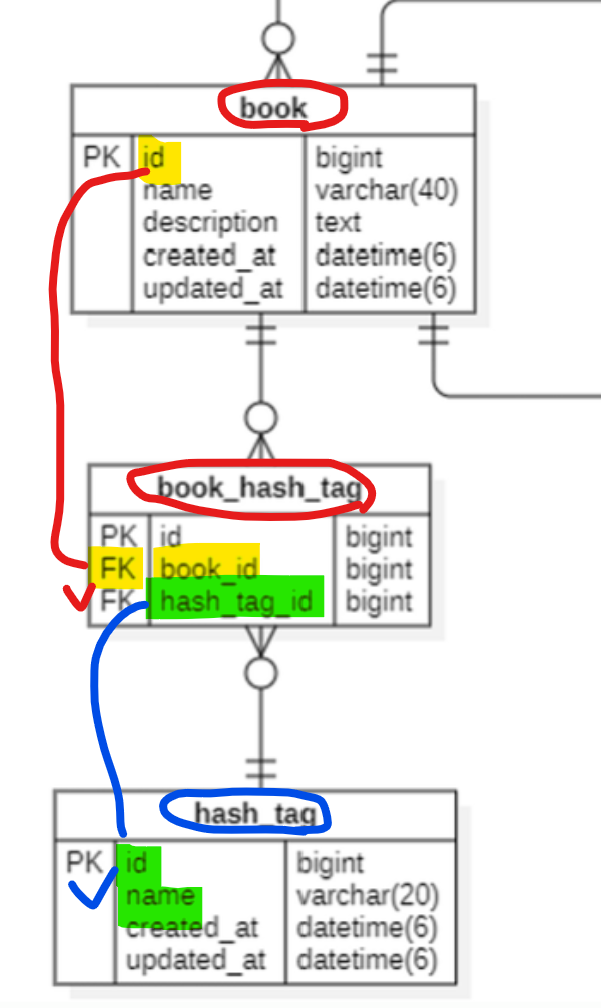
# sub query
select *
from book
where id in
(select book_id
from book_hash_tag
where hash_tag_id = (select id
from hash_tag
where name = 'BackEnd'));책 목록 최신 순, 좋아요 순 조회
☑️ 최신 순 조회 쿼리
ERD에서 created_at을 이용하여 ms단위로 책 등록 시간을 정해놨기 때문에,
created_at을 desc(내림차순)으로 조회하여 데이터를 가져온다.
select * from book
order by created_at desc; # 최신순 정렬(order by)☑️ 인기 순(좋아요 개수 순) 조회 쿼리
book 테이블에는 likes 칼럼이 따로 없으므로 books_likes테이블과 join해주어야 한다.
select * from book as b
join (select count(*) as like_count
from book_likes
group by book_id)
as likes on b.id = likes.book_id
order by likes.like_count desc;문제 발생❌ : solution- 페이징
한번에 데이터를 불러오는 것은 처리에 있어 overflow를 발생할수 있다.
그렇다면 어떻게 처리하여야 할까?
이때, 통상적으로 페이징을 하여 sql문으로 처리한다.
database 자체에서 데이터를 끊어주면서 오버헤드를 줄이고 가독성을 높인다.
📖 offset-based 페이징 쿼리
페이지 번호로 페이징하는 방법이다.
limit: 한 페이지에서 보여줄 데이터의 개수 한도
offset: 처음으로부터 건너뛸 개수를 지정해준다
# 페이지 x번에 대하여 한 페이지에 y개를 보여줌
select *
from book
order by likes desc
limit y offset (x-1) * y;
✅ failing point:
offset-based 페이징 쿼리는 페이지가 뒤로 갈수록 넘어가는 데이터가 많아져 성능 상의 이슈가 발생
사용자가 페이지를 넘어가려는 순간 글이 추가되면 이미 중복된 게시글이 다시 보일 수 있다는 문제점이 있다.
따라서 cursor-based 페이징 쿼리를 사용한다.
🖲️ cursor-based 페이징 쿼리
📌 커서(=마지막으로 조회한 컨텐츠)로 무언가를 가리켜 페이징을 하는 방법
마지막으로 조회한 책의 id를 가져온 후, 커서 페이징 기법으로 그 다음 책의 아이디를 표시해준다.
select *
from book
where book.likes <
(select likes
from book
where id = 4)
order by likes desc limit 15;최신순 조회 cursor-based 페이징 쿼리
책 등록시간에 따른 최신순 조회는 다음과 같다.
책 등록시간인 created_at을 기반으로, 마지막으로 조회한 책의 다음 책을 가져오도록 한다.
select *
from book
where created_at <
(select created_at from book where id = 3)
order by created_at desc limit 15;e.g. 최신순 조회 쿼리와 좋아요 순 조회 쿼리를 다르게 처리해주어야 하는 이유? ⁉️🫠

최신순 조회는 erd에서 설계한 created_at처럼 6자리 밀리초를 기준으로 하기 때문에 중복된 값을 가질 확률이 현저하게 적다.
그러나 좋아요 수를 기반으로 하는 페이징 쿼리는 좋아요 수가 동일한 경우가 발생(!🤯)할 수 있다.
따라서 좋아요 수'만'으로 책 목록을 조회하려면 어렵고, 좋아요 수가 같은 경우에는 최신 순으로 정렬하도록 정렬 조건을 2가지 이상으로 걸어준다.
좋아요 수 조회 cursor-based 페이징 쿼리
따라서,
좋아요 수를 기준으로 책 목록을 조회한다.
좋아요 수가 같다면, 최신 순으로 정렬한다.
block한 유저의 좋아요는 집계하지 않는다.
라는 요구사항이 있을 때의 쿼리는 다음 과 같다:
select b.*
from book as b
join (
select bl.book_id, count(*) as like_count
from book_likes as bl
where not exists (
select target_id
from block as bc
where bc.target_id = bl.user_id and bc_owner_id=3
)
group by bl.book_id
) as likes on b.id = likes.book_id
order by likes.like_count desc, b.created_at desc
limit 15;