지난 시간에는 Spring Batch가 전체적으로 어떻게 동작하는지 알아보는 시간을 가졌습니다.
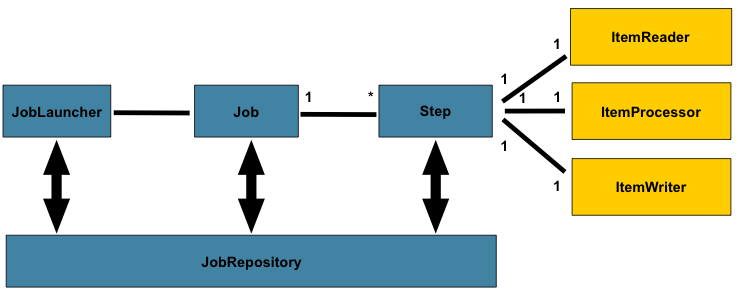
간단하게 정리해보자면, Job을 실행할경우 Job을 구성하고 있는 Step들이 순차적으로, 혹은 조건에 따라서 실행되고, Step이 실행되는 경우에는 Step을 구성하고 있는 Tasklet들이 동작한다고 볼 수 있습니다.

[Reference : https://docs.spring.io/spring-batch/reference/domain.html]
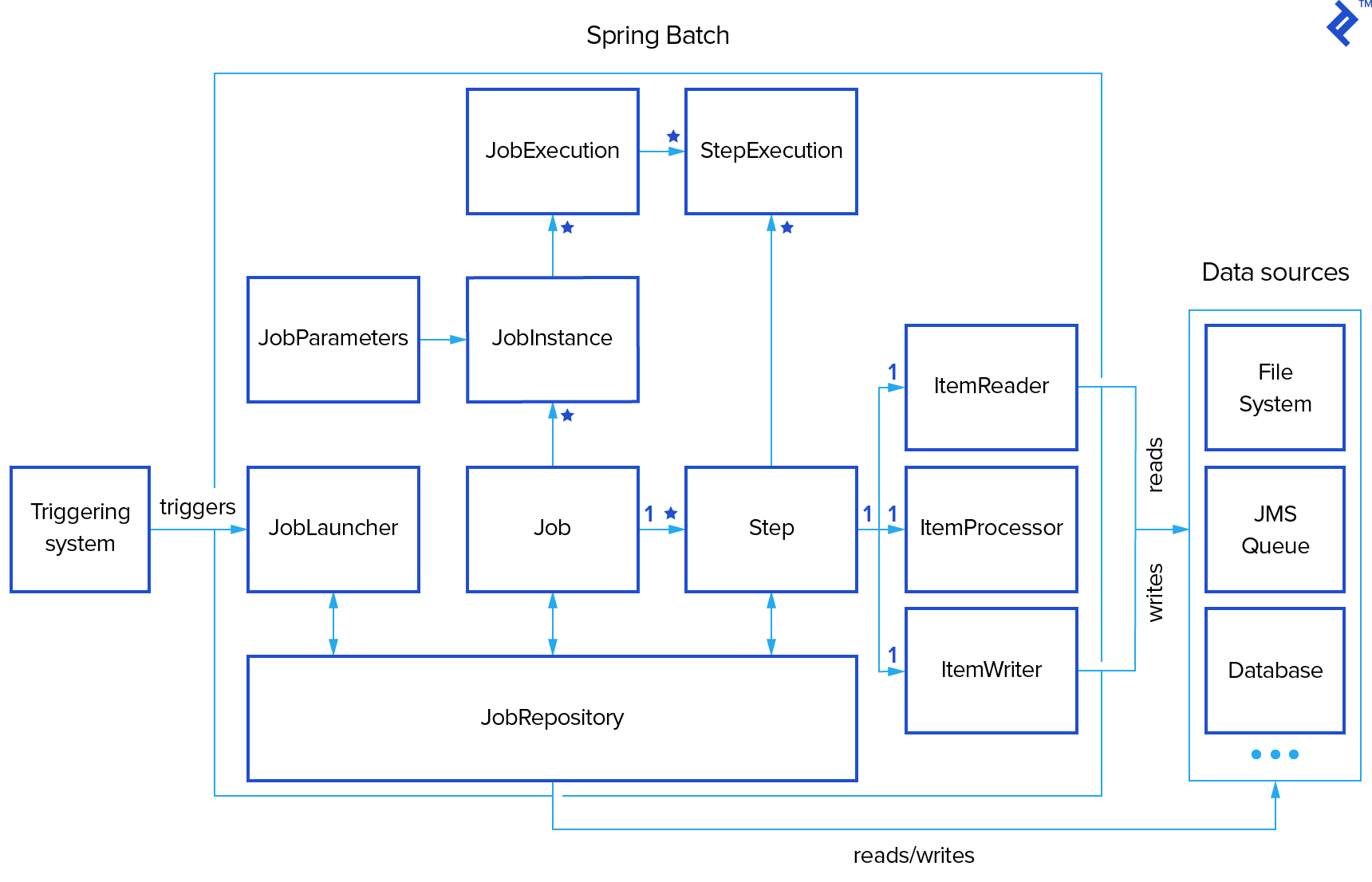
[Reference : https://www.toptal.com/spring/spring-batch-tutorial]
그런데, 공식문서도 그렇고 Spring Batch 동작 과정에 대해서 설명하는 그림도 그렇고 Tasklet에 대하여 명시되어 있지 않다는 것을 확인할 수 있을겁니다.
여러분들은 어떠실지 모르겠지만, 저는 Spring Batch의 구조에 대해서 처음 이해할 때, 이 부분이 가장 이해하기 어려웠습니다.
아니 분명 Step은 Tasklet들에 의하여 구성된다고 배웠는데, ItemReader, ItemProcess, ItemWriter는 무엇이고, 배웠던 Tasklet은 보이지 않는 것인지 궁금했습니다.
이전에 Spring Batch 구성 요소에 대해서 설명하면서 Tasklet 구현 방식과 Chunk 기반 구현 방식에 대하여 간략하게 정리한 적이 있지만, 좀 더 자세하게 정리하는 것이 좋을 것 같다 생각하여 오늘은 이 둘의 차이점에 대해서 알아보는 시간을 갖도록 하겠습니다.
Chunk?
앞에서 Chunk 기반 구현 방식이라고 설명하였는데, 여기서 Chunk가 무엇일까요?
일단 단순하게 단어만 해석해본다면, '큰 덩어리'라고 해석해볼 수 있을 것 같습니다.
지난 시간에 Spring Batch의 장점에 대해서 설명할 때, 대용량의 데이터를 처리할 수 있다는 점이 Spring Batch의 장점이라고 설명한 적이 있습니다.
Spring Batch가 이러한 장점을 가질 수 있는 요인은 바로 데이터를 하나의 묶음 단위로 처리할 수 있기 때문인데, 이러한 묶음이 바로 Chunk입니다.
데이터베이스에 존재하는 수 많은 데이터들 중, 미리 정의된 Chunk 만큼의 데이터를 읽어온 뒤, 이를 변환하고 처리하는 과정을 통해서 Spring Batch는 대용량의 데이터를 효율적으로 처리할 수 있는 것입니다.
일단 자세한 내용들은 뒤에서 살펴보도록하고, Chunk가 무엇을 의미하는지에 대해서 간단하게 알고 넘어가면 좋을 것 같습니다.
Tasklet vs Chunk?

아시는 분들은 아시겠지만, Tasklet은 인터페이스입니다.
'Step이 하나 이상의 Tasklet으로 구성되어있다'라는 말은 좀 더 상세하게 설명하자면 Tasklet 인터페이스의 구현체들로 구성되어 있다라고 정리할 수 있을 것 같습니다.
따라서, 이 Tasklet 인터페이스를 구현하고 있는 구현체가 무엇이냐에 따라서, Step이 Tasklet 기반으로 동작하는지, 혹은 Chunk 기반으로 동작하는지가 결정된다고 볼 수 있을 것 같습니다.
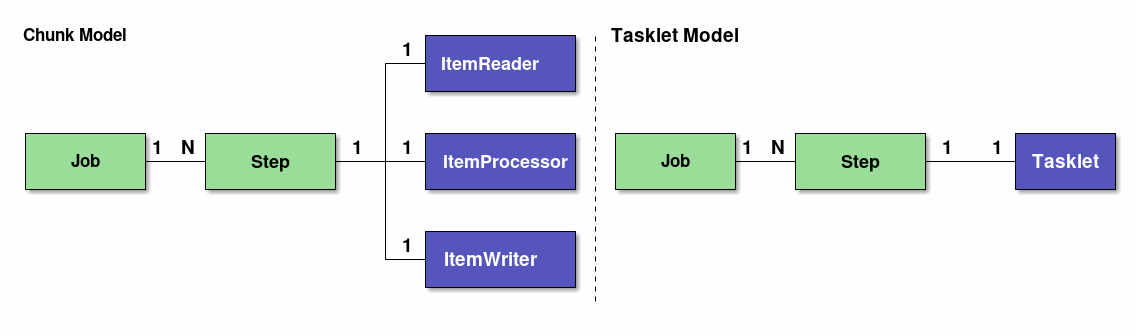
[Reference : https://terasoluna-batch.github.io/guideline/5.1.1.RELEASE/en/Ch02_TerasolunaBatchArchitecture.html]
다음처럼 Tasklet 인터페이스를 어떻게 구현하느냐에 따라서 Chunk Model과 Tasklet Model로 나뉘게되는데,

Chunk Model의 경우에는 다음처럼 Tasklet 인터페이스를 구현하고 있는 ChunkOrientedTasklet으로 구성된 Step을,
Tasklet Model은 우리가 앞에서 살펴보았던 예시처럼 단순하게 execute() 메서드만 구현하고 있는 구현체들로 구성된 Step을 의미합니다.
Chunk Model
그럼 여기서 하나 궁금증이 생깁니다.
갑자기 나타난 ItemReader, ItemProcessor, ItemWriter는 무엇인가?
앞에서 Chunk 용어에 대해서 설명할 때, 우리는 이렇게 정리하였습니다.
데이터베이스에 존재하는 수 많은 데이터들 중, 미리 정의된 Chunk 만큼의 데이터를 읽어온 뒤,
이를 변환하고
처리하는 과정을 통해서
Spring Batch는 대용량의 데이터를 효율적으로 처리한다.사실 용어만봐도 이해하시는 분들이 계실겁니다.
ItemReader는 말 그대로 데이터베이스 혹은 문서 등으로부터 데이터를 읽어오는 역할을 수행합니다.
여기서 읽어올 데이터의 개수인 chunk를 설정할 수 있는데, 정해진 chunk 만큼의 데이터를 읽은 뒤, 이를 ItemProcessor로 넘깁니다.
ItemProcessor는 ItemReader로부터 전달받는 데이터를 가공 혹은 변환하는 역할을 수행합니다.
보통 비즈니스적인 로직이 주로 위치하는 부분이며, 변환된 데이터는 ItemWriter에게 전달됩니다.
ItemWriter는 ItemProcessor가 가공한 데이터를 처리하는 역할을 수행합니다.
여기서의 처리는 데이터를 데이터베이스에 저장하는 과정이 될 수도 있고, 이를 출력하거나 어딘가에 기록하는 작업이 될 수 있습니다.
이 과정을 그림을 통하여 살펴보면 다음과 같습니다.
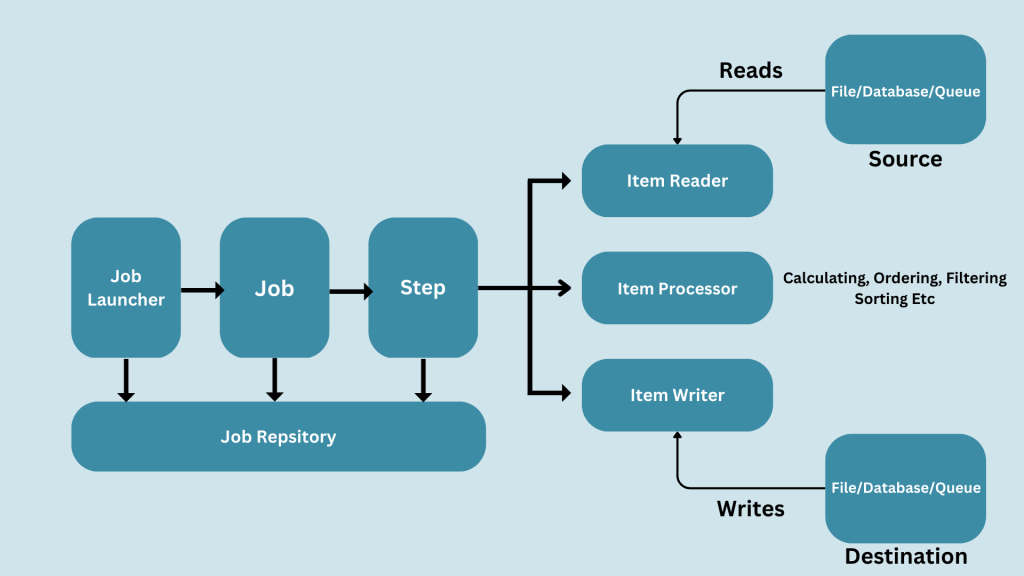
[Reference : https://www.innodeed.com/handling-huge-datasets-with-spring-batch/]
차이점?
일단 Tasklet Model을 사용하는 경우, 메서드를 구현하기만하면 끝이기 때문에 Chunk Model과 비교하였을 때 구현이 쉽다는 장점이 존재합니다.
따라서, 데이터 처리 과정이 비교적 간단하거나 데이터의 양이 얼마 되지 않는 경우에 주로 사용한다는 특징을 가지고 있습니다.
하지만, 데이터의 양이 많아지거나, 데이터 처리 과정이 복잡해지는 경우에는 Tasklet Model로 구현하기가 더 어렵다는 단점이 존재합니다.
반대로 Chunk Model을 사용하는 경우, Tasklet Model과 비교하였을 때 구현이 복잡하다는 단점을 가지고 있지만, 대용량 데이터나 복잡한 로직을 구현하기가 수월하다는 장점을 가지고 있습니다.
이처럼 구현 방식에 따라서 다양한 장단점을 가지고 있기 때문에, 목적에 알맞게 구현체를 사용하는 것이 좋다고 생각합니다.