원-핫 인코딩
import re
from konlpy.tag import Okt
from collections import Countertext = "임금님 귀는 당나귀 귀! 임금님 귀는 당나귀 귀! 실컷~ 소리치고 나니 속이 확 뚫려 살 것 같았어."
text'임금님 귀는 당나귀 귀! 임금님 귀는 당나귀 귀! 실컷~ 소리치고 나니 속이 확 뚫려 살 것 같았어.'- 자음의 범위 : ㄱ ~ ㅎ
- 모음의 범위 : ㅏ ~ ㅣ
- 완성형 한글의 범위 : 가 ~ 힣
한글, 공백을 제외한 모든 문자를 표현하는 regex :[^ㄱ-ㅎㅏ-ㅣ가-힣 ]
# 전처리
reg = re.compile("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]")
text = reg.sub('', text)
print(text)임금님 귀는 당나귀 귀 임금님 귀는 당나귀 귀 실컷 소리치고 나니 속이 확 뚫려 살 것 같았어# 한국어 형태소 분석기로 토크나이징
okt=Okt()
tokens = okt.morphs(text)
print(tokens)['임금님', '귀', '는', '당나귀', '귀', '임금님', '귀', '는', '당나귀', '귀', '실컷', '소리', '치고', '나니', '속이', '확', '뚫려', '살', '것', '같았어']# Counter로 단어장 만들기. 빈도수로 저장된다
vocab = Counter(tokens)
print(vocab)Counter({'귀': 4, '임금님': 2, '는': 2, '당나귀': 2, '실컷': 1, '소리': 1, '치고': 1, '나니': 1, '속이': 1, '확': 1, '뚫려': 1, '살': 1, '것': 1, '같았어': 1})vocab['임금님']2# 빈도 수 상위 5개만 단어장으로 저장 (value=빈도수)
vocab_size = 5
vocab = vocab.most_common(vocab_size) # 등장 빈도수가 높은 상위 5개의 단어만 저장
print(vocab)[('귀', 4), ('임금님', 2), ('는', 2), ('당나귀', 2), ('실컷', 1)]# 높은 빈도 수 일수록 낮은 정수 인덱스 부여한 단어장 (value=정수 인덱스)
word2idx={word[0] : index+1 for index, word in enumerate(vocab)}
print(word2idx){'귀': 1, '임금님': 2, '는': 3, '당나귀': 4, '실컷': 5}원-핫 벡터 만들기
# 특정 단어와 단어장을 입력하면 해당 단어의 원-핫 벡터를 리턴
def one_hot_encoding(word, word2index):
one_hot_vector = [0]*(len(word2index)) # 단어장의 길이만큼 영벡터 생성
index = word2index[word] # 단어의 정수 인덱스
one_hot_vector[index-1] = 1
return one_hot_vectorone_hot_encoding("임금님", word2idx)[0, 1, 0, 0, 0]케라스로 원-핫 인코딩 간단히 해보자
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categoricaltext = [['강아지', '고양이', '강아지'],['애교', '고양이'], ['컴퓨터', '노트북']]
text[['강아지', '고양이', '강아지'], ['애교', '고양이'], ['컴퓨터', '노트북']]# 케라스 토크나이저
t = Tokenizer()
t.fit_on_texts(text)
print(t.word_index) # 각 단어에 대한 인코딩 결과 출력.{'강아지': 1, '고양이': 2, '애교': 3, '컴퓨터': 4, '노트북': 5}# 단어장의 크기 저장
vocab_size = len(t.word_index) + 1
vocab_size6여기서 단어장 크기에 +1을 해준 이유는, 0번 단어에 패딩토큰을 넣어줄 수 있도록 비워둔 것
# 정수 시퀀스로 변환
sub_text = ['강아지', '고양이', '강아지', '컴퓨터']
encoded = t.texts_to_sequences([sub_text])
print(encoded)[[1, 2, 1, 4]]# to_categorical()로 원-핫 벡터 시퀀스로 변환
one_hot = to_categorical(encoded, num_classes = vocab_size)
print(one_hot)[[[0. 1. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0.]]]vocab_size = 6 인 벡터로 변환되었다!
원-핫 벡터로 단어장을 만들긴 했으나, DTM, TF-IDF, 원-핫 벡터 모두 희소벡터라는 점에서 데이터를 비효율적으로 쓰게 됨
차원의 저주
1. 데이터의 차원(용량)이 커질수록 모델 학습이 힘들어지도 데이터가 더 많이 필요해진다.
2. 여기서 노이즈가 생기는 만큼 훨씬 악화된다.
게다가 벡터 간 유사도를 구하기 위해 내적을 해도 웟-핫 벡터는 서로 직교벡터이기 때문에 유사도는 0이 되어 구할수 없다.
이를 해결하기 위해, 희소벡터가 아닌 밀집벡터(dense vector)를 학습하는 워드 임베딩을 사용한다. 0과 1이 아닌 다양한 실수값을 가지며, 이 밀집벡터를 임베딩 벡터라 부른다.
워드 임베딩
Word2Vec
Word2Vec 영상
Word2Vec은 단어를 벡터로 표현하는 방법으로써, 저차원으로 이루어져 있고 단어의 의미를 여러 차원에 분산하여 표현한 벡터다.
Word2Vec의 핵심 아이디어는 분포 가설(distributional hypothesis)을 따른다.
You shall know a word by the company it keeps(곁에 오는 단어들을 보면 그 단어를 알 수 있다).
존 루퍼트 퍼스(John Rupert Firth)분포 가설 : ‘비슷한 문맥에서 같이 등장하는 경향이 있는 단어들은 비슷한 의미를 가진다.’
CBoW (Continuous Bag of words)
Word2Vec은 CBow와 Skip-gram이라는 두 가지 방법이 있다.
CBow는 주변에 있는 단어들을 통해 중간에 있는 단어들을 예측하는 방법.
Skip-gram 중간에 있는 단어로 주변 단어들을 예측하는 방법
"I like natural language processing."
이라는 문장에서 CBoW는 {"i", "like", "language", "processing"}으로 부터 중간에 "natural"를 예측하는 것이다.
예측해야하는 단어 "natural"은 중심 단어(center word), 예측에 사용되는 단어들을 주변 단어(context word)라고 한다.
앞 뒤로 몇 개의 단어를 볼지의 범위는 윈도우(window)라고 한다. 위의 그림은 윈도우 크기 1
((주변 단어 set), 중심 단어))
((like), I), ((I, natural), like), ((like, language), natural), ((natural, processing), language), ((language), processing)
위 데이터셋에서 단어 각각은 원-핫 벡터로 만들고 CBow나 Skip-gram의 input이 된다.
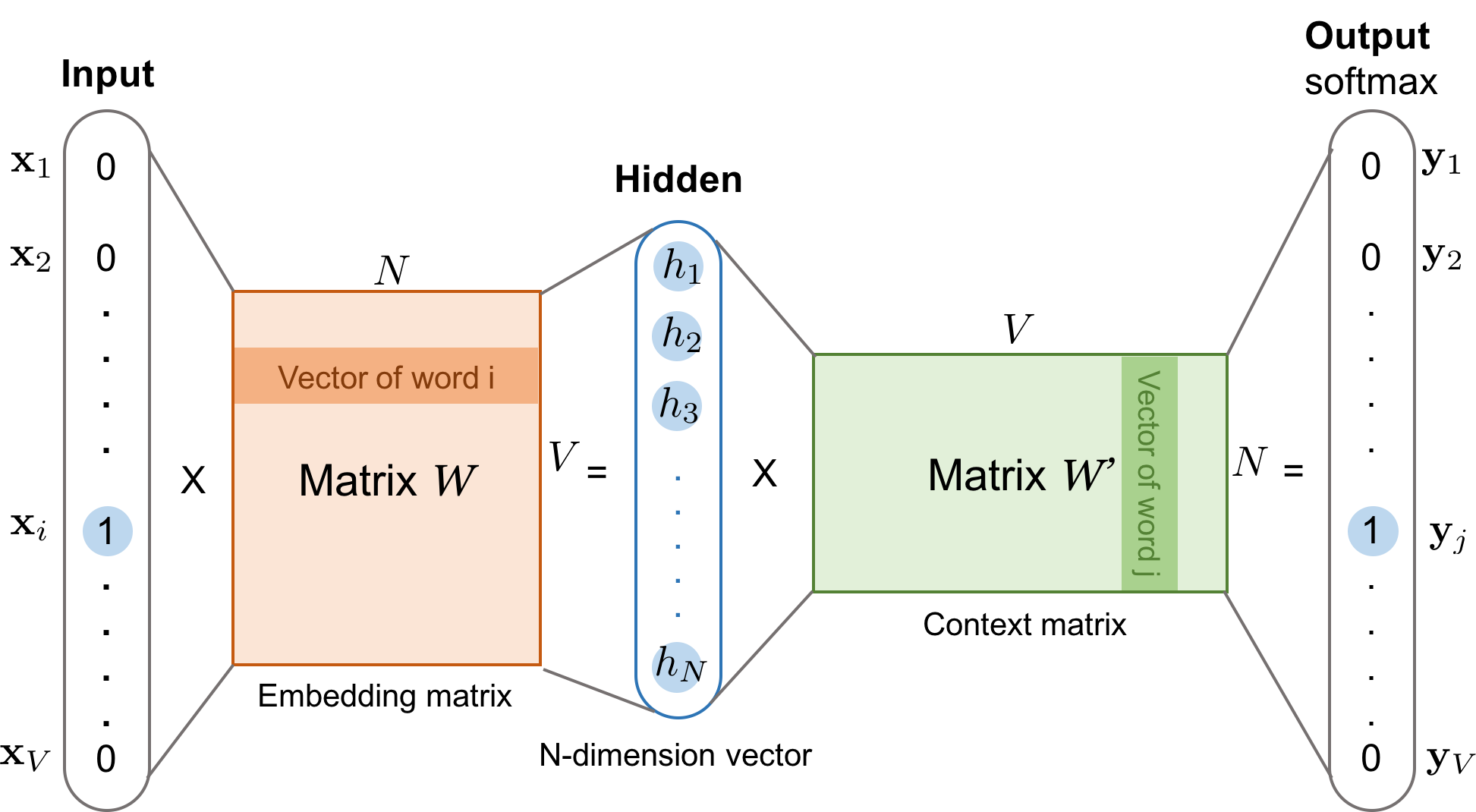
https://lilianweng.github.io/lil-log/assets/images/word2vec-skip-gram.png


원핫 벡터와 가중치 행렬(룩업 테이블)을 곱하여 i행을 벡터를 그대로 가져오고, 이 벡터들을 모두 합하거나, 평균을 구한 값이 hidden layer가 된다. 활성화 함수가 없기 때문에 투사층(projection layer라고 한다.)
이 층을 두 번재 가중치 행렬(context matrix)와 곱하고 활성화 함수를 거쳐 output
이 output 벡터를 중심 단어의 원핫 벡터와의 loss를 최소화 하도록 학습한다.
Skip-gram
중심 단어로부터 주변 단어를 예측한다.
CBow와는 다르게, 은닉층으로 갈 때, 벡터들을 덧셈이나 평균을 구하는 과정이 없다는 것 외에는 모두 동일. 학습 후에는 두 가중치 행렬 중에서 임베딩 벡터 정하거나, 두 행렬의 평균치로 임베딩 벡터를 선택한다.
네거티브 샘플림(negative sampling)
Word2Vec을 사용 시에는 SGNS(Skip-Gram with Negative Sampling)을 사용한다.
Word2Vec의 구조는 연산량이 많아 실제로 사용하기 때문.
출력층에서 소프트맥스 함수를 통과한 VV 차원의 벡터와 레이블에 해당되는 VV차원의 주변 단어의 원-핫 벡터와의 오차를 구하고, 역전파를 통해 모든 단어에 대한 임베딩 벡터을 조정한다. 하지만 단어장이 너무 커진다면 연산량이 너무 늘어난다.
때문에, 네거티브 샘플링은 연산량을 줄이기 위해서 소프트맥스 함수를 사용한 V개 중 1개를 고르는 다중 클래스 분류 문제를 시그모이드 함수를 사용한 이진 분류 문제로 바꾸는 것이다.
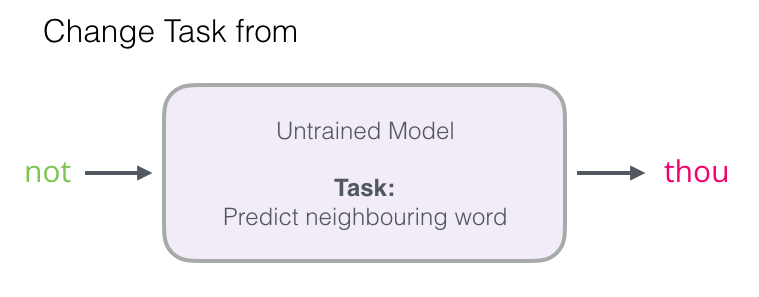

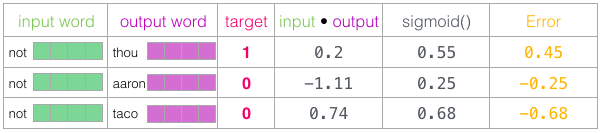
Thou shalt not make a machine in the likeness of a human mind
라는 문장에서
정상적인 데이터 셋에 1 레이블을 달아주고
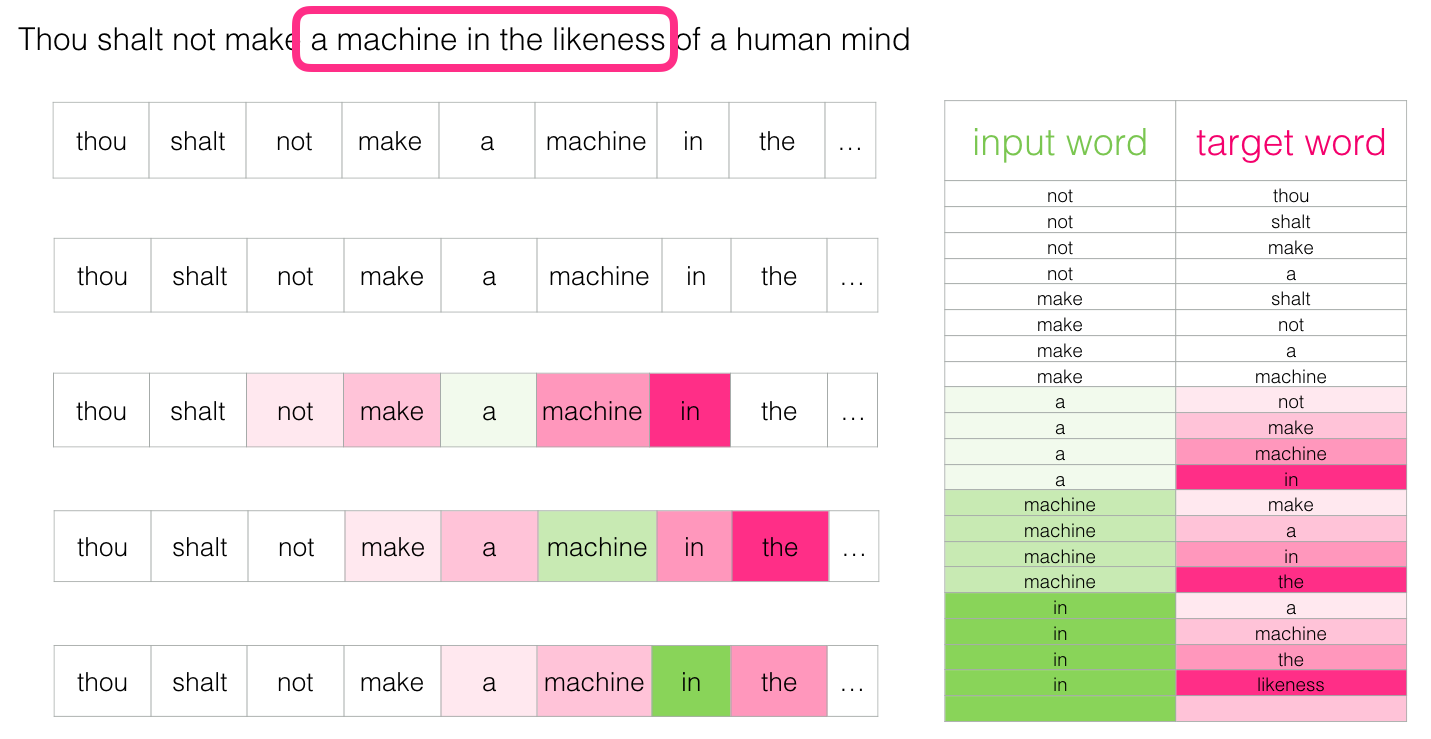
그 외 단어장에서 아무 단어나 가져와서 거짓 데이터셋을 만들어 0으로 레이블링 한다.
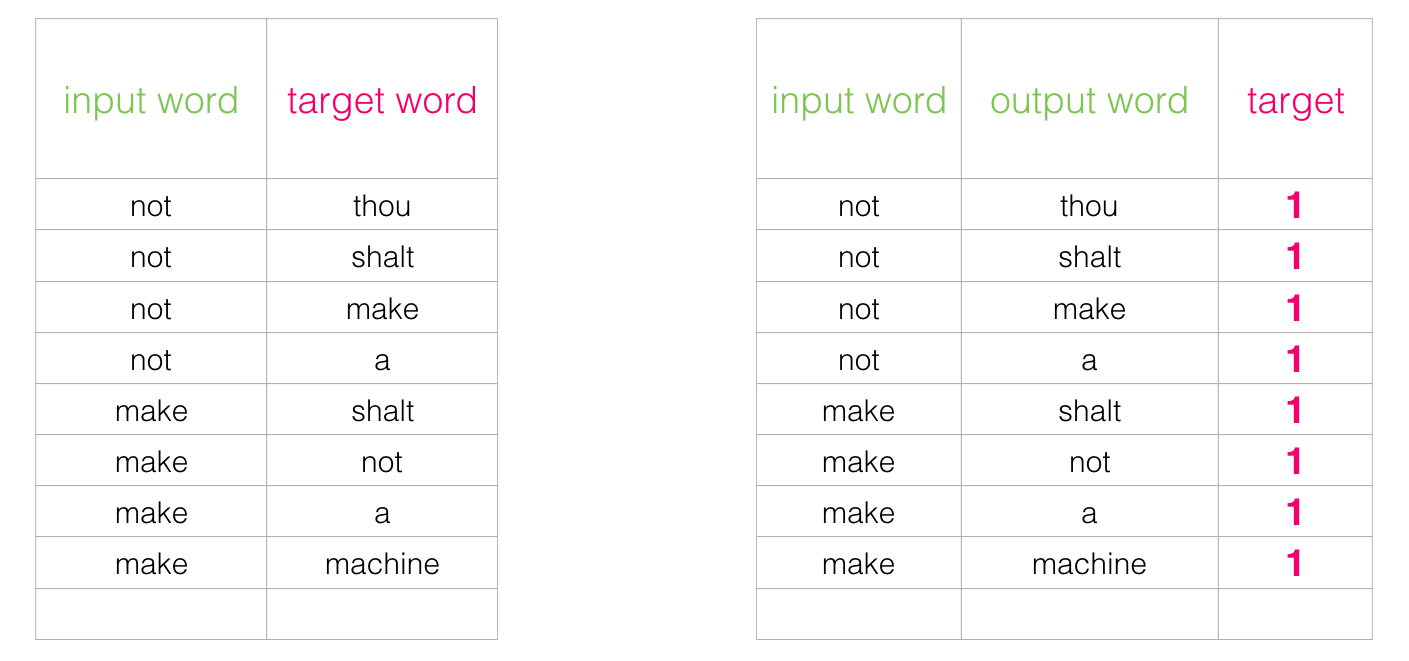
이후 시그모이드 함수를 거치게 하여 이진 분류로써 오차를 구하고 역전파를 수행한다.
Word2Vec 실습
pip install nltk
pip install gensim
nltk에서 훈련 데이터 코퍼스를 가져오고 gensim(토픽 모델링)으로 Word2Vec 모델을 사용한다.
import nltk
nltk.download('abc')
nltk.download('punkt')[nltk_data] Downloading package abc to /aiffel/nltk_data...
[nltk_data] Package abc is already up-to-date!
[nltk_data] Downloading package punkt to /aiffel/nltk_data...
[nltk_data] Package punkt is already up-to-date!
True# NLTK의 코퍼스를 불러와 corpus라는 변수에 저장
from nltk.corpus import abc
corpus = abc.sents()print(corpus[:3])[['PM', 'denies', 'knowledge', 'of', 'AWB', 'kickbacks', 'The', 'Prime', 'Minister', 'has', 'denied', 'he', 'knew', 'AWB', 'was', 'paying', 'kickbacks', 'to', 'Iraq', 'despite', 'writing', 'to', 'the', 'wheat', 'exporter', 'asking', 'to', 'be', 'kept', 'fully', 'informed', 'on', 'Iraq', 'wheat', 'sales', '.'], ['Letters', 'from', 'John', 'Howard', 'and', 'Deputy', 'Prime', 'Minister', 'Mark', 'Vaile', 'to', 'AWB', 'have', 'been', 'released', 'by', 'the', 'Cole', 'inquiry', 'into', 'the', 'oil', 'for', 'food', 'program', '.'], ['In', 'one', 'of', 'the', 'letters', 'Mr', 'Howard', 'asks', 'AWB', 'managing', 'director', 'Andrew', 'Lindberg', 'to', 'remain', 'in', 'close', 'contact', 'with', 'the', 'Government', 'on', 'Iraq', 'wheat', 'sales', '.']]print('코퍼스의 크기 :',len(corpus))코퍼스의 크기 : 29059- vector size = 학습 후 임베딩 벡터의 차원
- window = 컨텍스트 윈도우 크기
- min_count = 단어 최소 빈도수 제한 (빈도가 적은 단어들은 학습하지 않아요.)
- workers = 학습을 위한 프로세스 수
- sg = 0은 CBoW, 1은 Skip-gram.
# 위 코퍼스로 Word2Vec 학습
from gensim.models import Word2Vec
model = Word2Vec(sentences = corpus,
vector_size = 100,
window = 5,
min_count = 5,
workers = 4,
sg = 0)
print("모델 학습 완료!")모델 학습 완료!# 코사인 유사도가 높은 단어들을 출력하는 model.wv.most_similar
model_result = model.wv.most_similar("man")
print(model_result)[('woman', 0.9233418107032776), ('skull', 0.911030113697052), ('Bang', 0.905648946762085), ('asteroid', 0.9052114486694336), ('third', 0.9020071625709534), ('baby', 0.8994219303131104), ('dog', 0.898607611656189), ('bought', 0.8975202441215515), ('rally', 0.8912495374679565), ('disc', 0.8889137506484985)]# 모델 저장 및 로드
from gensim.models import KeyedVectors
model.wv.save_word2vec_format('~/aiffel/word_embedding/w2v')
loaded_model = KeyedVectors.load_word2vec_format("~/aiffel/word_embedding/w2v")
print("모델 load 완료!")모델 load 완료!model_result = loaded_model.most_similar("man")
print(model_result)[('woman', 0.9233418107032776), ('skull', 0.911030113697052), ('Bang', 0.905648946762085), ('asteroid', 0.9052114486694336), ('third', 0.9020071625709534), ('baby', 0.8994219303131104), ('dog', 0.898607611656189), ('bought', 0.8975202441215515), ('rally', 0.8912495374679565), ('disc', 0.8889137506484985)]Word2Vec의 OOV 문제
하지만 여기서도 단어장에 없는 단어로부터는 임베딩 벡터를 얻을 수 없다.
# 에러
loaded_model.most_similar('overacting')---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-30-210c73889f66> in <module>
1 # 에러
----> 2 loaded_model.most_similar('overacting')
/opt/conda/lib/python3.7/site-packages/gensim/models/keyedvectors.py in most_similar(self, positive, negative, topn, clip_start, clip_end, restrict_vocab, indexer)
760 mean.append(weight * key)
761 else:
--> 762 mean.append(weight * self.get_vector(key, norm=True))
763 if self.has_index_for(key):
764 all_keys.add(self.get_index(key))
/opt/conda/lib/python3.7/site-packages/gensim/models/keyedvectors.py in get_vector(self, key, norm)
420
421 """
--> 422 index = self.get_index(key)
423 if norm:
424 self.fill_norms()
/opt/conda/lib/python3.7/site-packages/gensim/models/keyedvectors.py in get_index(self, key, default)
394 return default
395 else:
--> 396 raise KeyError(f"Key '{key}' not present")
397
398 def get_vector(self, key, norm=False):
KeyError: "Key 'overacting' not present"# 오타가 나도 에러난다
loaded_model.most_similar('memorry')---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-31-e6d4a64d6fad> in <module>
1 # 오타가 나도 에러난다
----> 2 loaded_model.most_similar('memorry')
/opt/conda/lib/python3.7/site-packages/gensim/models/keyedvectors.py in most_similar(self, positive, negative, topn, clip_start, clip_end, restrict_vocab, indexer)
760 mean.append(weight * key)
761 else:
--> 762 mean.append(weight * self.get_vector(key, norm=True))
763 if self.has_index_for(key):
764 all_keys.add(self.get_index(key))
/opt/conda/lib/python3.7/site-packages/gensim/models/keyedvectors.py in get_vector(self, key, norm)
420
421 """
--> 422 index = self.get_index(key)
423 if norm:
424 self.fill_norms()
/opt/conda/lib/python3.7/site-packages/gensim/models/keyedvectors.py in get_index(self, key, default)
394 return default
395 else:
--> 396 raise KeyError(f"Key '{key}' not present")
397
398 def get_vector(self, key, norm=False):
KeyError: "Key 'memorry' not present"임베팅 벡터 시각화
구글의 임베팅 벡터 시각화 오픈소스인 임베딩 프로젝터(embedding projector)로 시각화
$ python -m gensim.scripts.word2vec2tensor --input ~/aiffel/word_embedding/w2v --output ~/aiffel/word_embedding/w2v
- 여기서
w2v_metadata.tsv와w2v_tensor.tsv2개의 파일을 준비 - https://projector.tensorflow.org/ 여기서 Load를 통해 두 파일 로드
- 단어를 선택하고 이웃을 몇 개까지, 거리 측정 메트릭도 코사인/유클리드 중에서 선택해보자
FastText
페이스북이 개발한 워드 임베딩 방법
메커니즘은 Word2Vec과 같으나, 문자 단위 n-gram(character-level n-gram) 표현을 학습한다는 점에서 다르다. Word2Vec은 단어를 더 이상 깨질 수 없는 단위로 구분하는 반면, FastText는 단어 내부의 내부 단어(subwords)들을 학습한다는 아이디어를 가지고 있다.
여기서 n은 단어들을 얼마나 분리할지 결정한느 하이퍼파라미터다. n을 3으로 잡은 트라이그램(tri-gram)의 경우, 단어 "partial"은 'par', 'art', 'rti', 'tia', 'ial'로 분리하고 이들을 벡터로 만든다. 여기에 원본 단어까지 포함.
n = 3인 경우
<pa, art, rti, tia, ial, al>,
n은 최솟값과 최댓값으로 설정가능하다. gensim에서는 기본값이 3, 6
n = 3 ~ 6인 경우
<pa, art, rti, ita, ial, al>, <par, arti, rtia, tial, ial>, <part, ...중략... ,
위 단어들 각각에 대하여 Word2Vec을 수행.
각 원소는 벡터임을 가정함
partial = <pa + art + rti + ita + ial + al> + <par + arti + rtia + tial + ial> + <part + ...중략... +
이후엔 네거티브 샘플링을 사용하여 학습. 다만, FastText에서는 학습 과정에서 중심 단어에 속한 문자단위 n-gram 단어 벡터들을 모두 업데이트한다.
FastText는 OOV와 오타에 robust하다.
from gensim.models import FastText
fasttext_model = FastText(corpus, window=5, min_count=5, workers=4, sg=1)
print("FastText 학습 완료!")FastText 학습 완료!# 기존 Word2Vec에는 없는 단어이지만 임베딩 계산 됨
fasttext_model.wv.most_similar('overacting')[('resolving', 0.9405428767204285),
('fluctuating', 0.9394034147262573),
('malting', 0.9363301396369934),
('emptying', 0.936026394367218),
('mounting', 0.9334825873374939),
('shooting', 0.9330668449401855),
('extracting', 0.931989848613739),
('debilitating', 0.9313831925392151),
('declining', 0.9291297793388367),
('overwhelming', 0.928447425365448)]# 오타도 출력된다!
fasttext_model.wv.most_similar('memoryy')[('memory', 0.9456679224967957),
('mechanisms', 0.8653683066368103),
('mechanism', 0.8633589744567871),
('musical', 0.8630186319351196),
('basic', 0.8561415076255798),
('imagine', 0.8527975678443909),
('mechanical', 0.8493632078170776),
('technical', 0.8442971110343933),
('intelligence', 0.8358346819877625),
('intercourse', 0.8355494737625122)]한국어 FastText에 관해서는 아래 글 참고
GloVe (Global Vectors for Word Representation)
스탠포드 대학에서 개발한 워드 임베딩
워드 임베딩의 두 가지 접근 방법인 카운트 기반과 예측 기반 두 가지 방법을 모두 사용
카운트 기반은 DTM와 같은 단어 빈도 수를 행렬로 표현한 것에서 LSA로 특이값 분해.
SVD와 PCA, 그리고 잠재의미분석(LSA)
예측 기반 방법은 Word2Vec과 같은 방법이다. 신경망을 통해 예측한 값으로 실제 레이블과의 오차를 구하고 역전파로 신경망을 학습하는 방식. 이는 벡터 간 유사도를 구하는 능력은 좋으나, LSA처럼 코퍼스의 전체적인 통계 정보를 활용하지는 못한다는 점을 한계로 두어, 이 두 방법을 모두 사용한 것이 GloVe. Word2Vec에 준하는 성능을 보여준다.
윈도우 기반 동시 등장 행렬(Window based Co-occurrence Matrix)

위 세 문장에서, i 단어의 윈도우 크기(window Size) 내에서 k 단어가 등장한 횟수를 i행 k열에 기재한 행렬이다.
(위 이미지는 윈도우 크기 1)
이 행렬은 전치시켜도 동일한 행렬이다.
동시 등장 확률(Co-occurrence Probability)
Glove 설명 영상
WijiDocs
동시 등장 행렬로부터 계산된 동시 등장 확률을 이용해 손실 함수를 설계합니다. 동시 등장 행렬을 사용하고 있으니 코퍼스의 전체적인 통계 정보를 활용하는 '카운트 기반'의 방법론이면서, 손실 함수를 통해 모델을 학습시키므로 '예측 기반'의 방법론이라고 할 수 있다. 즉 GloVe는
전체 코퍼스에서의 동시 등장 빈도의 로그값과 중심 단어 벡터와 주변 단어 벡터의 내적값의 차이가 최소화되도록 두 벡터의 값을 학습하는 것
GloVe 실습
pip install glove_python_binary
pip install nltk
import nltk
nltk.download('movie_reviews')
nltk.download('punkt')
# 71,000개 샘플의 코퍼스[nltk_data] Downloading package movie_reviews to /aiffel/nltk_data...
[nltk_data] Unzipping corpora/movie_reviews.zip.
[nltk_data] Downloading package punkt to /aiffel/nltk_data...
[nltk_data] Package punkt is already up-to-date!
Truefrom nltk.corpus import movie_reviews
corpus=movie_reviews.sents()from glove import Corpus, Glove
# 훈련 데이터로부터 GloVe에서 사용할 동시 등장 행렬 생성
emb = Corpus()
emb.fit(corpus, window=5)
# 벡터의 차원은 100, 학습에 이용할 쓰레드의 개수는 4로 설정, 에포크는 20.
glove = Glove(no_components=100, learning_rate=0.05)
glove.fit(emb.matrix, epochs=20, no_threads=4, verbose=True)
glove.add_dictionary(emb.dictionary)Performing 20 training epochs with 4 threads
Epoch 0
Epoch 1
Epoch 2
Epoch 3
Epoch 4
Epoch 5
Epoch 6
Epoch 7
Epoch 8
Epoch 9
Epoch 10
Epoch 11
Epoch 12
Epoch 13
Epoch 14
Epoch 15
Epoch 16
Epoch 17
Epoch 18
Epoch 19model_result1 = glove.most_similar("man")
model_result2 = glove.most_similar("fiction")
print("model_result1", model_result1)
print("model_result2", model_result2)model_result1 [('woman', 0.9550843952764827), ('young', 0.8903596841426636), ('girl', 0.8895044632772289), ('boy', 0.8859105812096446)]
model_result2 [('science', 0.9834423603722052), ('pulp', 0.9636700838958303), ('blue', 0.7059526446531965), ('rocky', 0.698149561691832)]