from 머신러닝, 딥러닝에 필요한 기초수학 with 파이썬
10장. 다시 만나는 선형회귀 : 모두 모아
- 기저함수 모델과 인공신경망 모델
- 경사하강법을 이용한 선형회귀
- 과대적합과 규제
- 확률적 경사하강법
- 노멀 방정식을 이용한 선형회귀
데이터 확인 → 가설 수립(모델) → 목적 함수(loss) → 경사하강법(경사도 → 최적화)
# 데이터 로드
D = np.load('noviceml/data_1d.npz')
x = D['x']
t = D['t']
X_train = D['X_train']
Y_train = D['Y_train']
X_test = D['X_test']
Y_test = D['Y_test']
N = X_train.shape[0]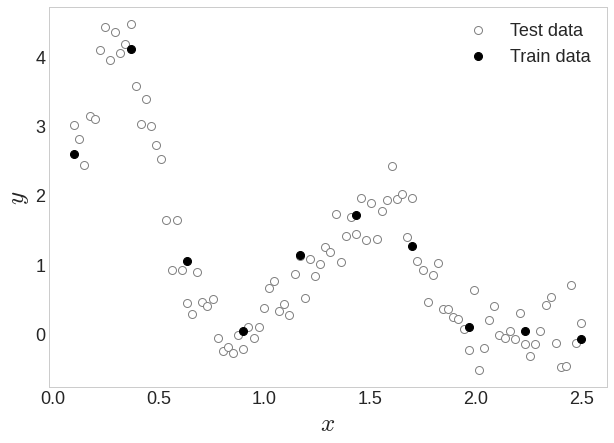
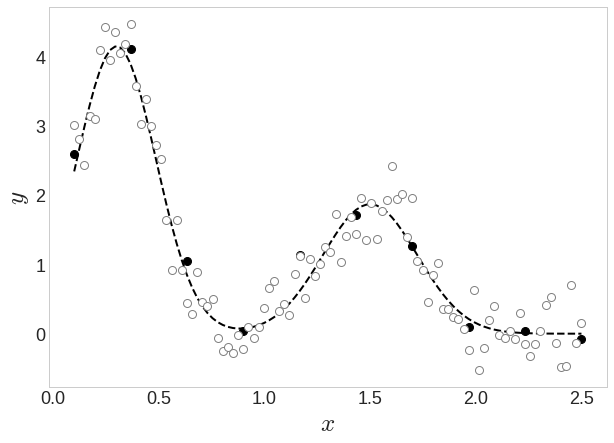
시간에 따른 약물의 반응
Y축은 병 상태를 나타내는 혈액 지표, X축은 약물을 투여한 후 시간

우리 목표는 위와 같은 점선 함수를 찾는 것
X_train 데이터를 뽑는다면
X_train
>> array([0.1 , 0.3667, 0.6333, 0.9 , 1.1667, 1.4333, 1.7 , 1.9667, 2.2333, 2.5 ])x=np.arange(12)
>>array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
#x.reshape(-1,1)
array([[ 0],
[ 1],
[ 2],
[ 3],
[ 4],
[ 5],
[ 6],
[ 7],
[ 8],
[ 9],
[10],
[11]])
#x.reshape(-1,2)
array([[ 0, 1],
[ 2, 3],
[ 4, 5],
[ 6, 7],
[ 8, 9],
[10, 11]])
#x.reshape(-1,3)
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
X_train.reshape(-1,1)
>>
array([[0.1 ],
[0.3667],
[0.6333],
[0.9 ],
[1.1667],
[1.4333],
[1.7 ],
[1.9667],
[2.2333],
[2.5 ]])(10, 1)의 행벡터가 나올 것이다.
❓ 이거 열벡터 아님?
간단한 선형식
입력변수는 , 여기서 결정되는 변수는 . 변수명을 로 바꾼다면
이를 벡터 내적으로 표현하면
스칼라 1 추가한 것을 볼 수 있다
# 첫번째 요소에 1을 추가하고
X = np.array([np.ones_like(X_train), X_train]).T
print("첫 요소에 1을 추가하여 각각을 벡터로 만든 x_train : X")
print(X.shape)
print(X)
print('\n')
>>
첫 요소에 1을 추가하여 각각을 벡터로 만든 x_train : X
(10, 2)
[[1. 0.1 ]
[1. 0.3667]
[1. 0.6333]
[1. 0.9 ]
[1. 1.1667]
[1. 1.4333]
[1. 1.7 ]
[1. 1.9667]
[1. 2.2333]
[1. 2.5 ]]
# 결정해야하는 w 두 개 (적당히 씀)
w1 = 3.5
w2 = -2.0
w = np.array([w1, w2])
#w와 내적을 하면 결과값 10개가 만들어 진다. w^t X
print("w와 X의 내적")
print(np.dot(X,w.reshape(-1,1)))
>>
w와 X의 내적
[[ 3.3 ]
[ 2.7667]
[ 2.2333]
[ 1.7 ]
[ 1.1667]
[ 0.6333]
[ 0.1 ]
[-0.4333]
[-0.9667]
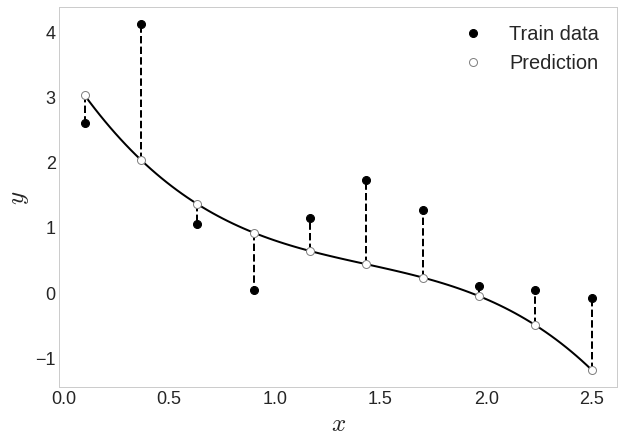
[-1.5 ]]행렬곱한 결과를 직선으로 그어보면

아직은 갈 길이 멀다!

위의 오차값을 최소화 시키자!
여기서 N으로 나누지 않고 2로 나눈 이유는 에러 줄이기 위함이기에 굳이 큰 문제 없어서!
Sqaured error, 오차함수, 이 값을 최소화하는 것이기에 이를 최소제곱법(least sqaure method)라고 부른다.
# 오차 계산
0.5*(((Y_train - Y_pred)**2).sum())
>>
6.171744429866503직선으로 모델을 설명하긴 힘들기에, 곡선(3차식)으로 표현해보자
# 오차 계산
0.5*(((Y_train - Y_pred)**2).sum())
>>
4.965242925784168기저함수
이렇게 어떤 함수를 만들어 내기 위해 조합하는 재료 함수를 기저함수(basis function)이라고 부른다.
기저함수 4개(일변수 스칼라함수)를 사용!
다변수 벡터함수를 넣을 수도 있겠죠?
최종적으로 기저함수 모델을 일반적으로 표현한다면 다음과 같다
넘파이와 사이킷런으로 다항식 회귀를 해보자
#########################################################################
## 넘파이 라이브러리를 사용해서 간단하게 구할 수 있다.
#########################################################################
# 1차 다항식
z_lin = np.polyfit(X_train, Y_train, 1)
# P차 다항식
z_nonlin = np.polyfit(X_train, Y_train, P)
y_lin = np.poly1d(z_lin)
y_nonlin = np.poly1d(z_nonlin)
#########################################################################
## sklearn 라이브러리를 사용해서 간단(?)하게 구할 수 있다.
#########################################################################
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
# 1차 다항식
model = LinearRegression(fit_intercept=True)
model.fit(X_train[:, np.newaxis], Y_train)
y_sk_lin = model.predict(x[:, np.newaxis])
# M차 다항식 (make_pipeline으로 다항 특성 넣어줌)
poly_model = make_pipeline(PolynomialFeatures(P), LinearRegression())
poly_model.fit(X_train[:, np.newaxis], Y_train)
y_sk_nonlin = poly_model.predict(x[:, np.newaxis])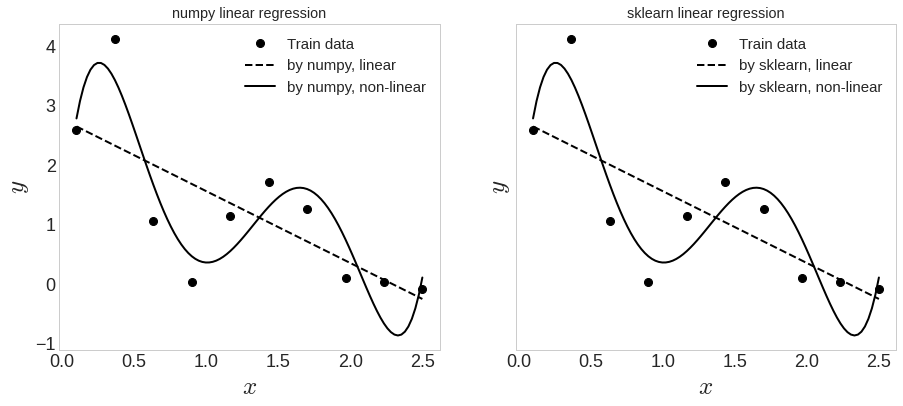
똑같이 잘 나오긴 함. 여기서 결과를 더 개선시켜보자
선형의 의미
선형성이란?
함수 에 대하여
가산성(additivity) : 임의의 수 에 대해 가 항상 성립하고,
동차성(homogeneity) : 임의의 수 에 대해 가 항상 성립할 때,
함수 는 선형이라고 한다.
모델이 곡선으로 되어있음에도 선형회귀라고 부르는 이유는, 계수w에 의해 선형조합 되어있기 때문.
경사하강법을 이용한 선형회귀
y를 구해보자
print(P) # 5차식
>>
5
X = np.array([ X_train**i for i in range(P+1) ])
print(X)
>>
[[1.0000e+00 1.0000e+00 1.0000e+00 1.0000e+00 1.0000e+00 1.0000e+00 1.0000e+00 1.0000e+00 1.0000e+00 1.0000e+00]
[1.0000e-01 3.6667e-01 6.3333e-01 9.0000e-01 1.1667e+00 1.4333e+00 1.7000e+00 1.9667e+00 2.2333e+00 2.5000e+00]
[1.0000e-02 1.3444e-01 4.0111e-01 8.1000e-01 1.3611e+00 2.0544e+00 2.8900e+00 3.8678e+00 4.9878e+00 6.2500e+00]
[1.0000e-03 4.9296e-02 2.5404e-01 7.2900e-01 1.5880e+00 2.9447e+00 4.9130e+00 7.6066e+00 1.1139e+01 1.5625e+01]
[1.0000e-04 1.8075e-02 1.6089e-01 6.5610e-01 1.8526e+00 4.2207e+00 8.3521e+00 1.4960e+01 2.4878e+01 3.9062e+01]
[1.0000e-05 6.6276e-03 1.0190e-01 5.9049e-01 2.1614e+00 6.0497e+00 1.4199e+01 2.9421e+01 5.5561e+01 9.7656e+01]]
w = np.random.rand(P+1)
print(w)
>>
[0.3118 0.4742 0.8433 0.8053 0.9476 0.0544]
Y_pred = (w.reshape(-1,1) * X).sum(axis=0)
print(Y_pred)
>>
[ 0.3685 0.6562 1.313 2.6626 5.1649 9.4243 16.1988 26.4088 41.1458 61.6811]
# sum 없이 하려면?
print(np.dot(X.T, w))
>>
[ 0.3685 0.6562 1.313 2.6626 5.1649 9.4243 16.1988 26.4088 41.1458 61.6811]손실함수도 정의하자
def J(w, P, x, y):
"""
Error function
J(w)= (1/2) * sum_{n=1}^{N} {y(x_n,w) - t_n}^2
y(x_n, w) = w_0*x^0 + w_1*x^1 + w_2*x^2 + ... + w_M*x^M
"""
X = np.array([ x**i for i in range(P+1) ])
y_pred = np.dot(X.T, w) # y_
pred = (w.reshape(-1,1) * X).sum(axis=0)
return 0.5*(( (y - y_pred)**2 ).sum())
print("{:.6f}".format(J(np.random.rand(4), 3, X_train, Y_train)))
>>
86.455903
print("{:.6f}".format(J(np.random.rand(6), 5, X_train, Y_train)))
>>
5637.172231경사도 벡터 함수
def grad_anal(w, P, x, y):
"""
This function computes the analytic gradient of the objective function
x, t : data for error function eval.
"""
N = x.shape[0]
PI = np.hstack( np.array( [np.power(x.reshape(N,1), p) for p in range(P+1)] ) )
# 위 식을 그대로 코딩
# g_ = np.dot(w.T, np.dot(PI.T, PI) ) - np.dot(y.T, PI)
# 식을 정리해서 np.dot 2번으로...
g = np.dot( np.dot(w.T,PI.T)-y.T , PI)
return g
from scipy import optimize
np.random.seed(0)
# P를 1, 3, 6, 12에 대해서 한번씩 피팅
Ps = [1, 3, 6, 12]
# 피팅결과 구해진 파라미터를 W에 저장
W = []
# 학습데이터를 넘기면서 fitting
for P in Ps :
w = np.random.uniform(-1, 1, P+1)
############################################################################
# scipy.optimize.minimize 사용하는 경우
ret = optimize.minimize(J, w, args=(P, X_train, Y_train),
jac=grad_anal, method='SLSQP')
W.append(ret.x)
print(ret)
############################################################################
print('\n')
>>
# 1차식
fun: 3.885207834041835
jac: array([1.4433e-15, 2.5535e-15])
message: 'Optimization terminated successfully.'
nfev: 6
nit: 3
njev: 3
status: 0
success: True
x: array([ 2.7696, -1.2081])
...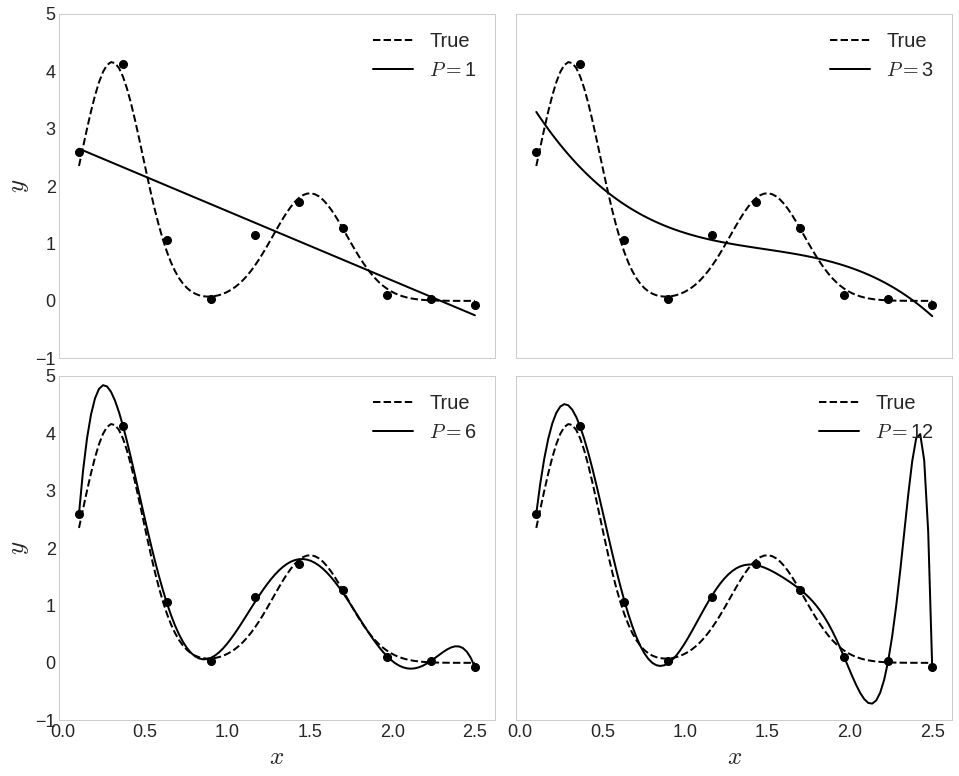
현재 train 데이터에 대해서만 접근했지만, 이후에 test 데이터를 통해 검증한다.
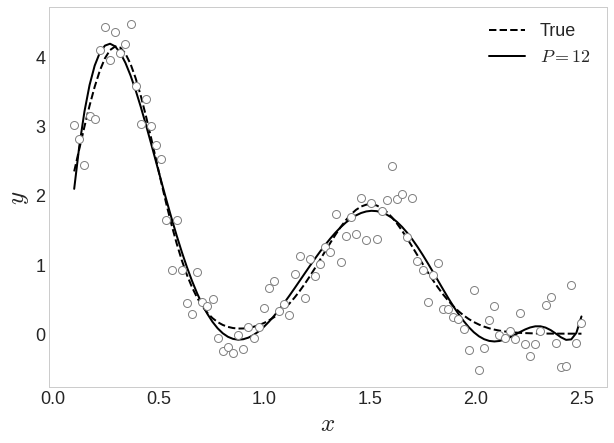
12차식에서 overfitting이 발생했다.
이를 해결할 방법은 2가지.
1. 데이터를 더 많이 모은다!

overfitting되었던 12차식도 데이터를 더 넣으니 해결!
2. 규제(regularization)
12차식의 W값들
array([ -0.5879, 40.3413, -86.4146, 9.233 , 57.0152, 20.8252, -33.4334, -35.1579, 17.1022, 35.4555, -33.7066, 10.9175, -1.2505])w의 절댓값이 훨씬 크다. 예민하게 반응하기 위해서 그런 것. w 절댓값을 줄이기 위해 페널티항을 추가해보자.
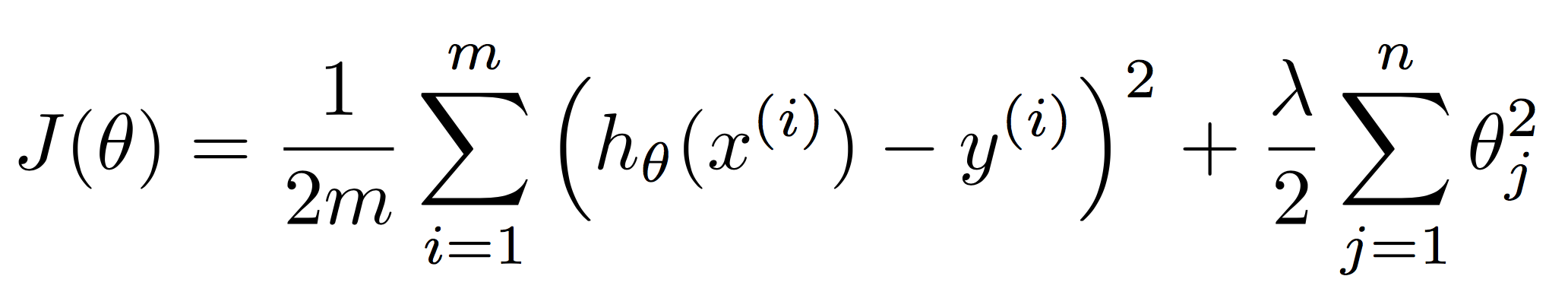
generalization (일반화) 결과
Stochastic Gradient Descent (SGD)
최적화 식
training 데이터에서 랜덤하게 mini-batch로 묶인 데이터를 랜덤하게 선택하여 최적화를 해나간다.
사실 이 mini-batch가 1인 것을 SGD라고 한다. 2개 이상은 미니배치 GD


노멀(정규) 방정식 풀기
위 식을 만족하는(최소화된) 를 구하여
여기까지 도달하는 것이 목표
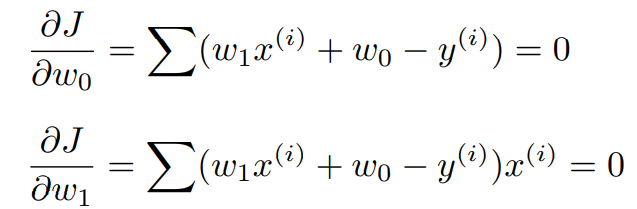
에 대해서 미분한다

위 식을 정리하면
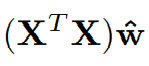
좌측항을 행렬로 표현한다면

즉,

이렇게 표현된다.
이제 우측변 y 부분을 행렬로 표현한다면
여기까지 도달하게 된다!
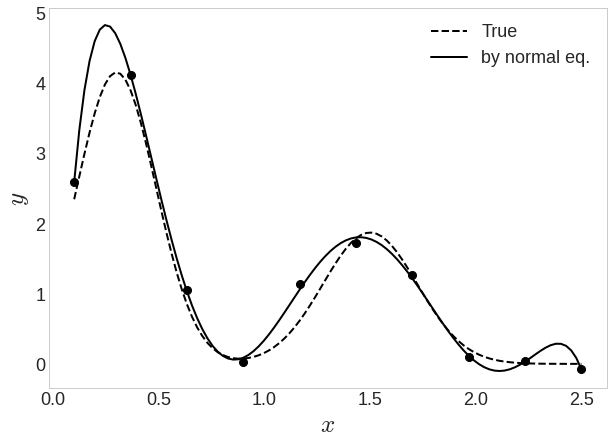
정규 방정식을 이용한 6차 다항식 피팅

페널티항이 있는 정규방정식 12차 다항식 피팅
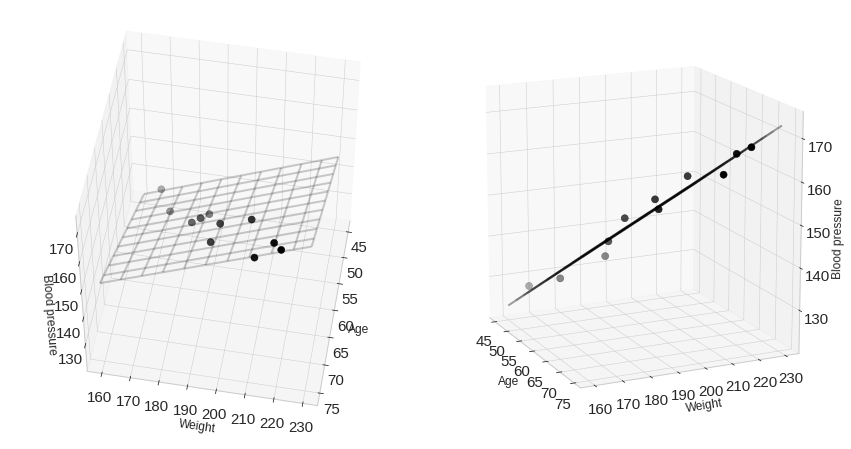
입력이 2개인 선형회귀
인공신경망 모델
import torch
# 데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])
# 모델 초기화
W = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=0.01)
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = x_train * W + b
# cost 계산
cost = torch.mean((hypothesis - y_train) ** 2)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} W: {:.3f}, b: {:.3f} Cost: {:.6f}'.format(
epoch, nb_epochs, W.item(), b.item(), cost.item()
))
>>
Epoch 0/1000 W: 0.093, b: 0.040 Cost: 4.666667
Epoch 100/1000 W: 0.873, b: 0.289 Cost: 0.012043
Epoch 200/1000 W: 0.900, b: 0.227 Cost: 0.007442
Epoch 300/1000 W: 0.921, b: 0.179 Cost: 0.004598
Epoch 400/1000 W: 0.938, b: 0.140 Cost: 0.002842
Epoch 500/1000 W: 0.951, b: 0.110 Cost: 0.001756
Epoch 600/1000 W: 0.962, b: 0.087 Cost: 0.001085
Epoch 700/1000 W: 0.970, b: 0.068 Cost: 0.000670
Epoch 800/1000 W: 0.976, b: 0.054 Cost: 0.000414
Epoch 900/1000 W: 0.981, b: 0.042 Cost: 0.000256
Epoch 1000/1000 W: 0.985, b: 0.033 Cost: 0.000158
##################### Sequential로 간단하게 설계
torch.manual_seed(0)
X_train_torch = torch.Tensor(X_train.reshape(-1,1))
Y_train_torch = torch.Tensor(Y_train)
# 입력특성 1차원, 히든레이어 3차원, 출력 1차원으로
D_in, H, D_out = 1, 3, 1
# torch.nn.Sequential을 사용하여 신경망을 구성한다.
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.Sigmoid(),
torch.nn.Linear(H, D_out)
)
loss_fn = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.Adam(model.parameters(), lr=0.15)
=================================
def train(X, y, model, loss_fn, optimizer, max_iter=5000, log=1000):
for i in range(max_iter):
Y_pred = model(X)
# 손실을 계산하고
loss = loss_fn(Y_pred.view(-1), y)
# 필요하면 출력
if i % log == log-1 :
print("Iter: {:5d}, Loss: {:f}".format(i+1, loss.item()))
# 경사도 벡터를 초기화 시키고
optimizer.zero_grad()
# 역전파 한 후에
loss.backward()
# Optimizer의 step 함수를 호출하면 매개변수가 갱신
optimizer.step()
train(X_train_torch, Y_train_torch, model, loss_fn, optimizer)
>>
Iter: 1000, Loss: 0.011248
Iter: 2000, Loss: 0.038908
Iter: 3000, Loss: 0.008651
Iter: 4000, Loss: 0.008621
Iter: 5000, Loss: 0.008633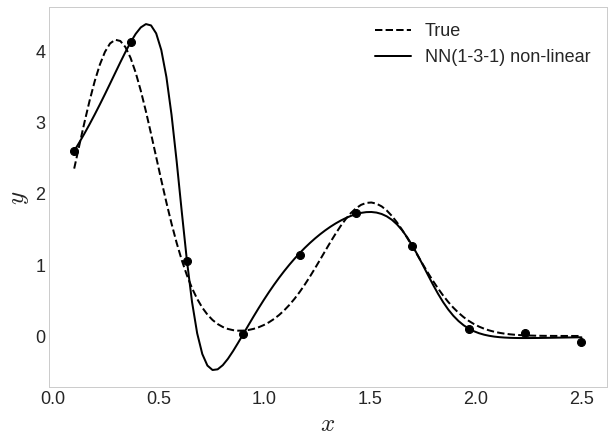
입력-은닉-출력이 1-3-1 구조
위에서 처럼 다항 기저함수로 비선형적 특성을 추가하지 않아도 회귀 결과가 곡선 형태를 띠고 있다
이유는 은닉층 출력에 로지스틱 시그모이드 함수를 적용했기 때문!
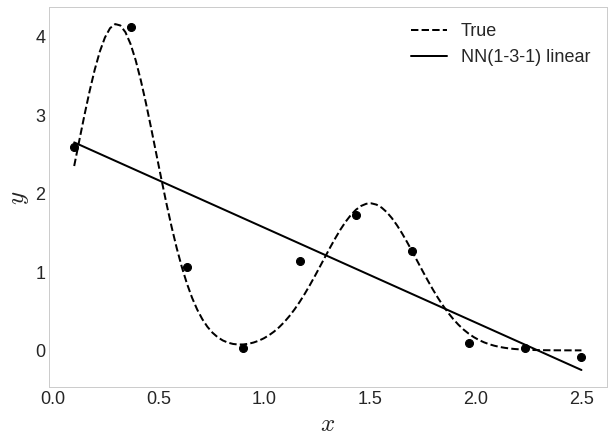
비선형 활성화 함수가 없어서 의 선형모델이 되어버림.
torch.manual_seed(0)
# 여기서 다항 특성을 부여하고 신경망에서 활성화 함수를 빼버림
P = 6
X_poly = np.array([ X_train**i for i in range(0, P+1) ]).T
X_train_torch = torch.Tensor(X_poly)
Y_train_torch = torch.Tensor(Y_train)
D_in, H, D_out = P+1, 3, 1
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.Linear(H, D_out)
)
loss_fn = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, betas=(0.999, 0.9999))
train(X_train_torch, Y_train_torch, model, loss_fn, optimizer, max_iter=70000, log=5000)
>>
Iter: 5000, Loss: 7.258276
Iter: 10000, Loss: 6.155363
Iter: 15000, Loss: 5.367366
Iter: 20000, Loss: 3.863875
Iter: 25000, Loss: 3.692570
Iter: 30000, Loss: 3.470147
Iter: 35000, Loss: 3.185551
Iter: 40000, Loss: 2.803065
Iter: 45000, Loss: 2.298491
Iter: 50000, Loss: 1.709741
Iter: 55000, Loss: 1.134679
Iter: 60000, Loss: 0.680984
Iter: 65000, Loss: 0.367515
Iter: 70000, Loss: 0.191891
7-3-1 구조로 활성화함수 없이 피팅했지만, 곡선형태를 띠운다
