
발단
배치를 이용해서 오늘 작성된 글 중에서 조회수가 100 이상인 글에 "NEWHIT"라는 뱃지가 달리도록 하는 기능을 작성하고 있었습니다.
코드는 다음과 같았습니다.
[if kakao 2022] Batch Performance를 고려한 최선의 Reader
를 보고 사용하고 있는 배치 코드에 문제가 있음을 알게 되었고 개선하게 되었습니다.
if 카카오 발표에서 볼 수 있듯 한 번에 모든 데이터를 처리할 수는 없습니다.
- 현재 데이터 양에서는 한 번에 읽는게 가능하더라도 늘어나면 불가능해질 수 있다.
- 어플리케이션에서는 가능할 수 있어도 RDBMS에서 한 번에 처리하는 것이 불가능하다.
이 발표를 보기 전에도 배치 기능은 페이징 방식으로 여러번에 나누어 처리하는것으로 되어있었는데, Reader 코드는 다음과 같습니다.
customerItemReader
@Bean
public ItemReader<Article> customerItemReader() {
String date= LocalDate.now().toString();
return new JpaPagingItemReaderBuilder<Article>()
.name("JpaPagingItemReaderJob")
.entityManagerFactory(emf)
.pageSize(100)
.queryString("select a from Article a where a.viewCount > 100 and a.createDate= CURRENT_DATE")
.build();
}Reader에서 실행되는 쿼리
Hibernate: select article0_.id as id1_0_, article0_.body as body2_0_, article0_.create_date as create_d3_0_, article0_.member_id as member_i7_0_, article0_.sticker as sticker4_0_, article0_.title as title5_0_, article0_.view_count as view_cou6_0_
from article article0_
where article0_.view_count>100 and article0_.create_date=CURRENT_DATE limit ?, ?페이지 사이즈가 100으로 아이템을 100개씩 조회해 오는것을 알 수 있습니다.
하지만 두 가지의 문제가 있다고 생각되었습니다.
1. offset을 이용한 페이징 방식은 offset이 뒤로갈수록 성능 저하가 일어난다.
2. 쿼리를 텍스트로 작성해야해서 가독성이 떨어지고 오류를 잡기 번거로워진다.
if카카오 발표와 여러 아티클을 참고해서 두가지 문제를 해결하게 되었습니다.
먼저 제가 선택한 방식은 제로 오프셋 페이징 리더 방식입니다.
이를 선택한 이유는
1. 제로 오프셋 방식은 이전에 경험해본 적 있기 때문에 쿼리에 대한 추가 이해가 필요없어서 빠르게 구현 가능하다고 생각했습니다. 제로 오프셋 쿼리
2. 커서 커스텀 Reader는 쿼리를 텍스트로 구현해야하기 때문에 2번 문제를 해결하기 힘들다고 생각했습니다.
따라서 QueryDsl을 이용한 Zero Offset Reader를 작성하게 되었습니다.
코드 까보기
구글링을 해보니 오픈소스를 제작하신 분도 있어서 가져다 쓰면 되었지만, 공부가 목적이기 때문에 참고만 하도록 하고, 직접 구현해보기로 했습니다.
JpaPagingItemReaderBuilder 살펴보기
먼저 기존 customerItemReader를 다시 살펴보면
@Bean
public ItemReader<Article> customerItemReader() {
String date= LocalDate.now().toString();
return new JpaPagingItemReaderBuilder<Article>()
.name("JpaPagingItemReaderJob")
.entityManagerFactory(emf)
.pageSize(100)
.queryString("select a from Article a where a.viewCount > 100 and a.createDate= CURRENT_DATE")
.build();
}JpaPagingItemReaderBuilder.build()를 통해 ItemReader를 반환하고 있습니다.
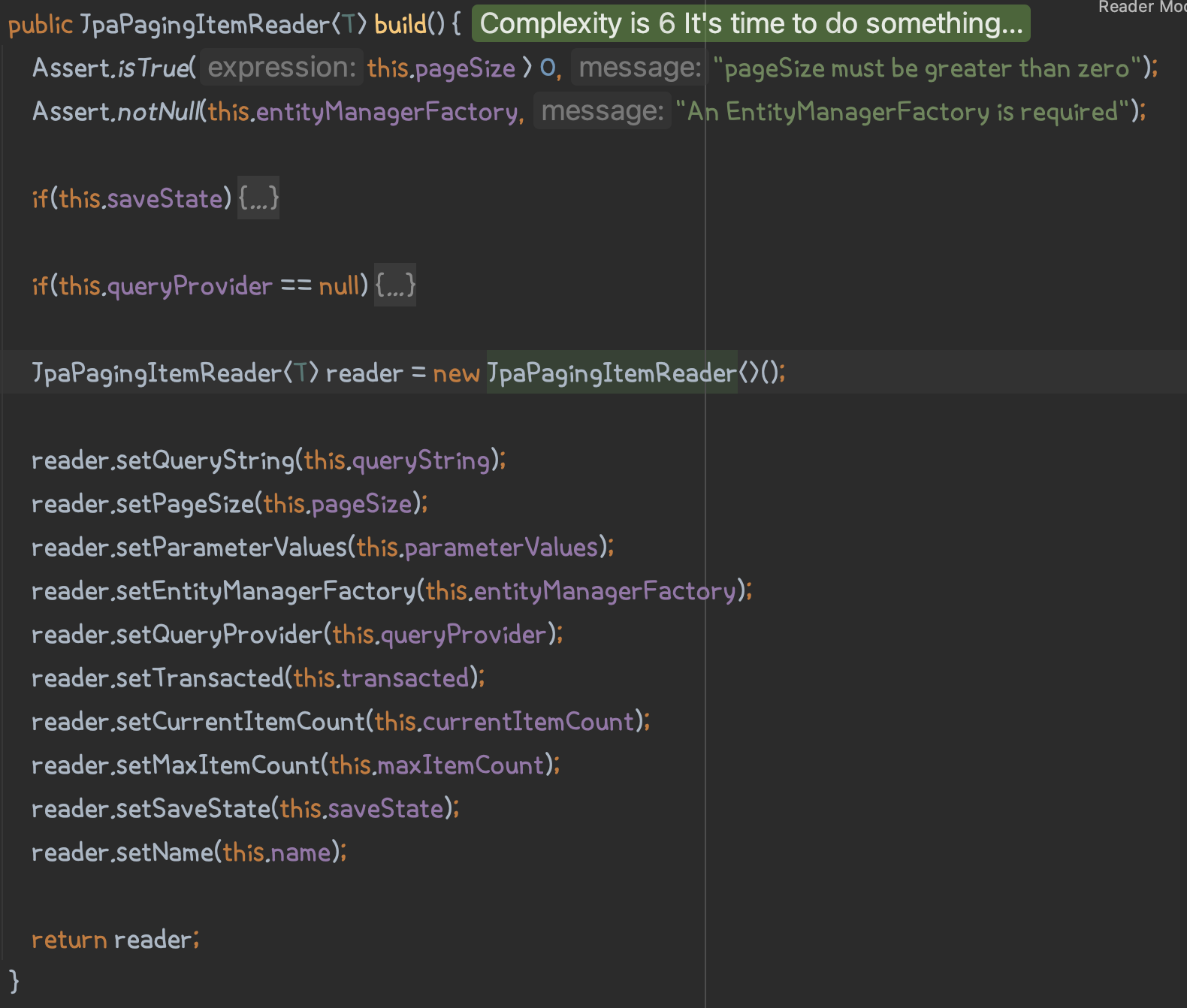 JpaPagingItemReaderBuilder.build()는 .name(), .entityManagerFactory(), .pageSize(), .queryString() 등을 통해 값들을 설정해주고 제네릭한 JpaPagingItemReader를 반환합니다.
JpaPagingItemReaderBuilder.build()는 .name(), .entityManagerFactory(), .pageSize(), .queryString() 등을 통해 값들을 설정해주고 제네릭한 JpaPagingItemReader를 반환합니다.

 이때 queryString은 아직 그냥 String 값임을 알 수 있습니다.
이때 queryString은 아직 그냥 String 값임을 알 수 있습니다.
이렇게 생성된 JpaPagingItemReader에서 문자열로 넘어간 쿼리가 실제 쿼리로 변환되고 실행됩니다.
JpaPagingItemReader 살펴보기
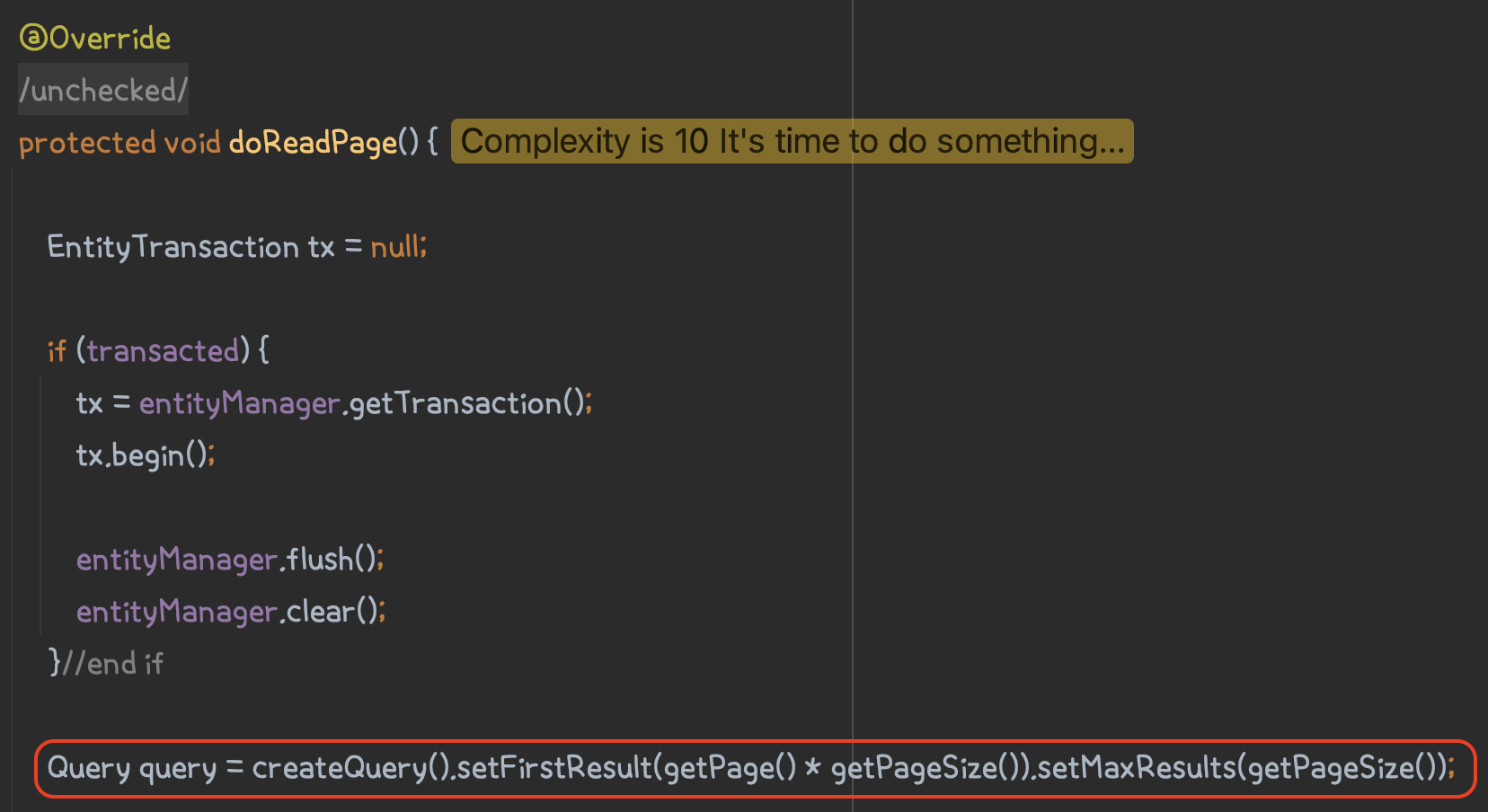 JpaPagingItemReader에서 쿼리를 실행하는 부분은 doReadPage() 이고, 그 안에서 createQuery()를 호출해서 쿼리를 생성합니다.
JpaPagingItemReader에서 쿼리를 실행하는 부분은 doReadPage() 이고, 그 안에서 createQuery()를 호출해서 쿼리를 생성합니다.
이때 페이지 오프셋은 다음과 같이 page*pageSize를 통해 offset을 구하는 것을 알 수 있습니다.
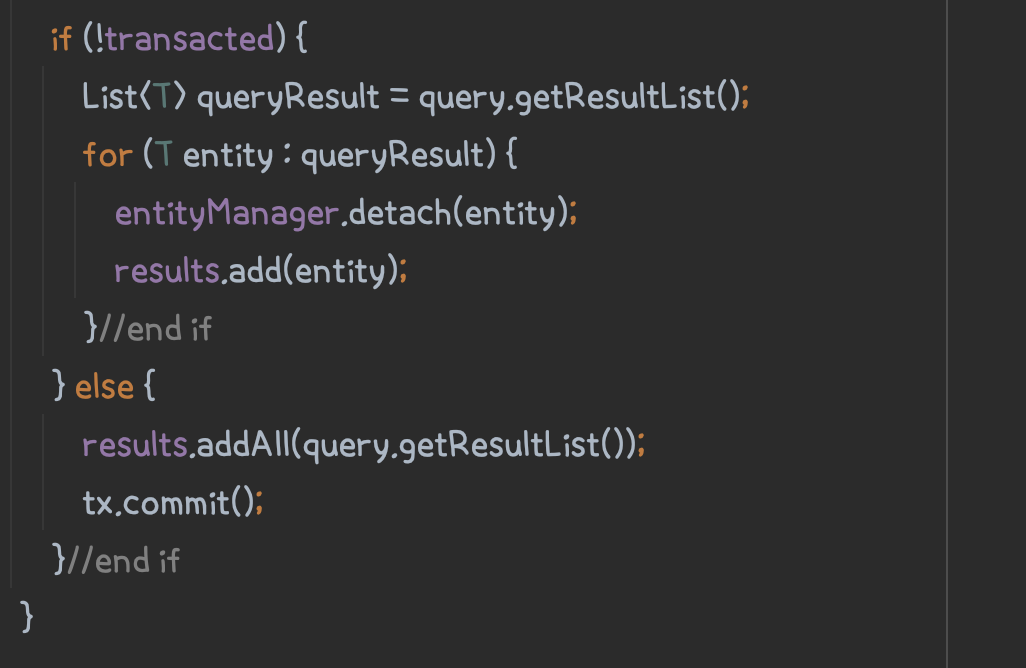
생성된 쿼리는 Query.getResultList()를 통해 실행됩니다.
getResultList()
쿼리가 생성되는 createQuery()는 다음과 같습니다.

따라서 쿼리가 생성되는 createQuery()부분과 실행되는 doReadPage()부분을 잘 바꾸면 될 것 같았습니다.
오프셋을 구할 때 이용되는 page 변수는 어디서 설정되는지 찾아보았습니다.
AbstractPagingItemReader 살펴보기
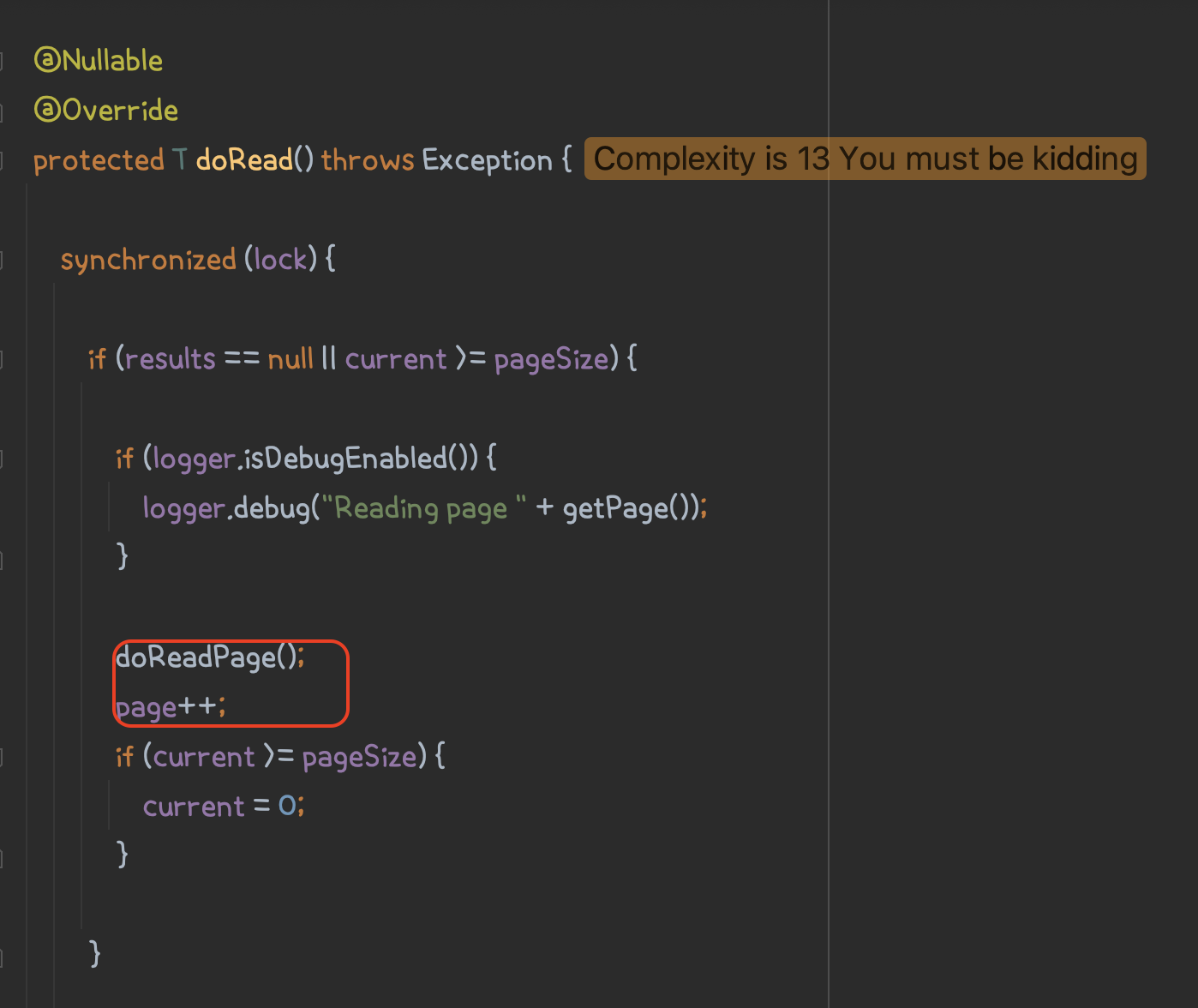
위 사진처럼 doRead()에서 doReadPage()도 호출하고, page도 늘려주는 것을 알 수 있습니다.
JpaPagingItemReader는 쿼리의 결과가 비어있으면 페이지를 다 읽은것으로 간주해서 동작을 멈춘다고 합니다. (이 부분의 코드도 분석해보려 했지만 아직 찾지 못했습니다.)
지금 하려는 일은 오프셋을 쓰지 않고 페이징을 구현하는 것이기에 JpaPagingItemReader에서 오프셋을 계산하는 부분만 바꿔주면 될 것이라 생각했습니다.
page++; 부분을 굳이 건들 필요는 없다고 생각했습니다.
쓰이지 않는 변수일지도 모르지만 ( Reader의 모든 동작을 이해한건 아니어서 확실하지 않습니다.) 수정하려면 JpaPagingItemReader 뿐만 아니라 AbstractPagingItemReader도 수정해야 하는데, 아직 정확하게 알지 못하는 부분도 많고, 개발 비용이 너무 크다고 생각되었습니다.
구현
QueryDslPagingItemReaderBuilder 구현
먼저 JpaPagingItemReaderBuilder를 복사해서 build() 부분만 다른 QueryDslPagingItemReaderBuilder를 만들어주었습니다.
JpaPagingItemReaderBuilder를 상속하지 않은 이유는 JpaPagingItemReaderBuilder.build()의 반환형이 JpaPagingItemReader이었고, 작성하고 있는 QueryDslPagingItemReaderBuilder에서 반환해야 하는 타입은 QueryDslPagingItemReader였기 때문입니다. QueryDslPagingItemReader를 반환하는 메소드를 build가 아닌 다른 이름으로 구현히는 방식도 고민해보았지만, build()가 남아있는 한 사용하다 실수를 범할 수도 있을 것 같아 상속받지 않고 그대로 복사하였습니다.
public class QueryDslPagingItemReaderBuilder<T> {
...생략
private Function<JPAQueryFactory, JPAQuery<Article>> queryFunction;
...생략
public QueryDslPagingItemReader build() {
Assert.notNull(this.entityManagerFactory, "An EntityManagerFactory is required");
if(this.saveState) {
Assert.hasText(this.name,
"A name is required when saveState is set to true");
}
QueryDslPagingItemReader reader = new QueryDslPagingItemReader();
reader.setPageSize(this.pageSize);
reader.setParameterValues(this.parameterValues);
reader.setEntityManagerFactory(this.entityManagerFactory);
reader.setQueryProvider(this.queryProvider);
reader.setTransacted(this.transacted);
reader.setCurrentItemCount(this.currentItemCount);
reader.setMaxItemCount(this.maxItemCount);
reader.setSaveState(this.saveState);
reader.setName(this.name);
reader.setQueryFunction(this.queryFunction);
return reader;
}QueryDslPagingItemReader 구현
JpaPagingItemReader에서 createQuery()가 jpql을 생성하는 부분이어서 이를 바꿔치기해야 했는데, private 메소드여서 override할 수 없어서 QueryDslPagingItemReader 역시 JpaPagingItemReader를 그대로 복사하고 필요한 부분을 변경하는 식으로 구현했습니다.
JpaPagingItemReader와 비교하여 변경된 부분은 다음과 같습니다.
public class QueryDslPagingItemReader extends AbstractPagingItemReader {
...생략
private JPAQuery<Article> createQuery() {
JPAQueryFactory queryFactory = new JPAQueryFactory(entityManager);
return queryFunction.apply(queryFactory);
}
...생략
protected void doReadPage() {
...생략
//쿼리 제로 오프셋 설정
JPAQuery<Article> query = createQuery()
.where(article.id.gt(lastidx))
.limit(getPageSize());
...생략
lastidx = queryResult.get(queryResult.size() - 1).getId();
}
} 쿼리를 실행하고, 결과의 마지막 id를 가져옵니다.
그리고 다음 쿼리엔 이전 쿼리의 마지막 id 이후부터 탐색하는 식으로 zero offset 페이징을 구현하였습니다.
Hibernate: select article0_.id as id1_0_, article0_.body as body2_0_, article0_.create_date as create_d3_0_, article0_.member_id as member_i7_0_, article0_.sticker as sticker4_0_, article0_.title as title5_0_, article0_.view_count as view_cou6_0_
from article article0_
where article0_.create_date=? and article0_.view_count>? and article0_.id>? limit ?위와 같이 오프셋이 제거된 쿼리가 나가는 것을 알 수 있습니다.
제네릭하게 구현하기
하지만 위 코드는 문제가 있었습니다.
JPAQuery<Article> query = createQuery()
.where(article.id.gt(lastidx))
.limit(getPageSize());위 코드는 이전 쿼리의 마지막 id 이후부터 조회하는 쿼리를 생성합니다.
하지만 where절 안의 구문이 article.id로 article에 종속적인 것을 알 수 있습니다.
사실 식별자는 엔티티의 종속적인 값이기 때문에 어떻게 제네릭하게 처리할지 어려움이 있었습니다.
모든 엔티티의 식별자 이름이 id인것도 아니기에 더 어려움이 있었습니다.
변경된 QueryDslPagingItemReader
public class QueryDslPagingItemReader<T> extends AbstractPagingItemReader<T> {
변경된 부분들
private NumberPath<Long> identifier;
private Method method;
//쿼리 제로 오프셋 설정
JPAQuery<T> query = createQuery()
.where(identifier.gt(lastidx))
.limit(getPageSize());
try {
setLastIndex(queryResult.get(queryResult.size() - 1));
}
catch (Exception e) {
throw new RuntimeException();
}
protected void setLastIndex(T entity) throws IllegalAccessException, IllegalArgumentException,InvocationTargetException{
lastidx= (Long) method.invoke(entity);
}
}변경된 queryDslreader()
@Bean
public QueryDslPagingItemReader queryDslreader() throws NoSuchFieldException, NoSuchMethodException ,IllegalAccessException{
String identifierName = "id";
String methodName = "getId";
NumberPath<Long> identifier= (NumberPath<Long>) article.getClass().getDeclaredField(identifierName).get(article);
Method method = Article.class.getMethod(methodName);
return new QueryDslPagingItemReaderBuilder<Article>()
.name("QueryDslZeroOffsetPagingTest")
.entityManagerFactory(emf)
.pageSize(10)
.identifier(identifier)
.method(method)
.queryFunction(queryFactory -> queryFactory
.selectFrom(article)
.where(article.createDate.eq(LocalDate.now()), article.viewCount.gt(100)))
.build();
}기존에
.where(article.id.gt(lastidx))로 표현되어서 엔티티에 종속적으로 작성되던 부분이
.where(identifier.gt(lastidx))위와 같이 변경되었습니다.
NumberPath<Long> identifier= (NumberPath<Long>) article.getClass().getDeclaredField(identifierName).get(article);위와 같은 방법으로 Q엔티티의 식별자를 찾고, 빌더에 넣어서 Reader를 생성하였습니다.
또한 이렇게 식별자를 찾게된 이후에 문제가 하나 생겼는데,
각 쿼리의 마지막 값의 정보를 불러오는 데에 있었습니다.
lastidx = queryResult.get(queryResult.size() - 1).getId();기존에는 위와 같은 방식으로 각 쿼리의 결과의 마지막 엔티티의 id를 불러왔습니다.
하지만 .getId()라는 함수 또한 Article 엔티티의 getter 함수이기에 문제가 되었습니다.
이를 해결하기 위해 식별자를 찾을 때와 마찬가지로 Reader를 생성하기 전에, 사용되는 엔티티의 함수를 찾고, Reader를 만들 때 인자로 넣어주었습니다.
Method method = Article.class.getMethod(methodName);호출되는 부분은 다음과 같습니다. 빌더에서 주입받은 메소드를 invoke로 실행해줍니다.
try {
setLastIndex(queryResult.get(queryResult.size() - 1));
}
catch (Exception e) {
throw new RuntimeException();
}
protected void setLastIndex(T entity) throws IllegalAccessException, IllegalArgumentException,InvocationTargetException{
lastidx= (Long) method.invoke(entity);
}위와 같은 방식으로 Article이 아닌 다른 엔티티에서도 제로 오프셋 페이징 방식으로 배치 기능을 작성할 수 있게 되었다.
결과
다음은 JpaPagingItemReader와 이번에 구현한 QueryDslPagingItemReader의 성능 측정 결과입니다.
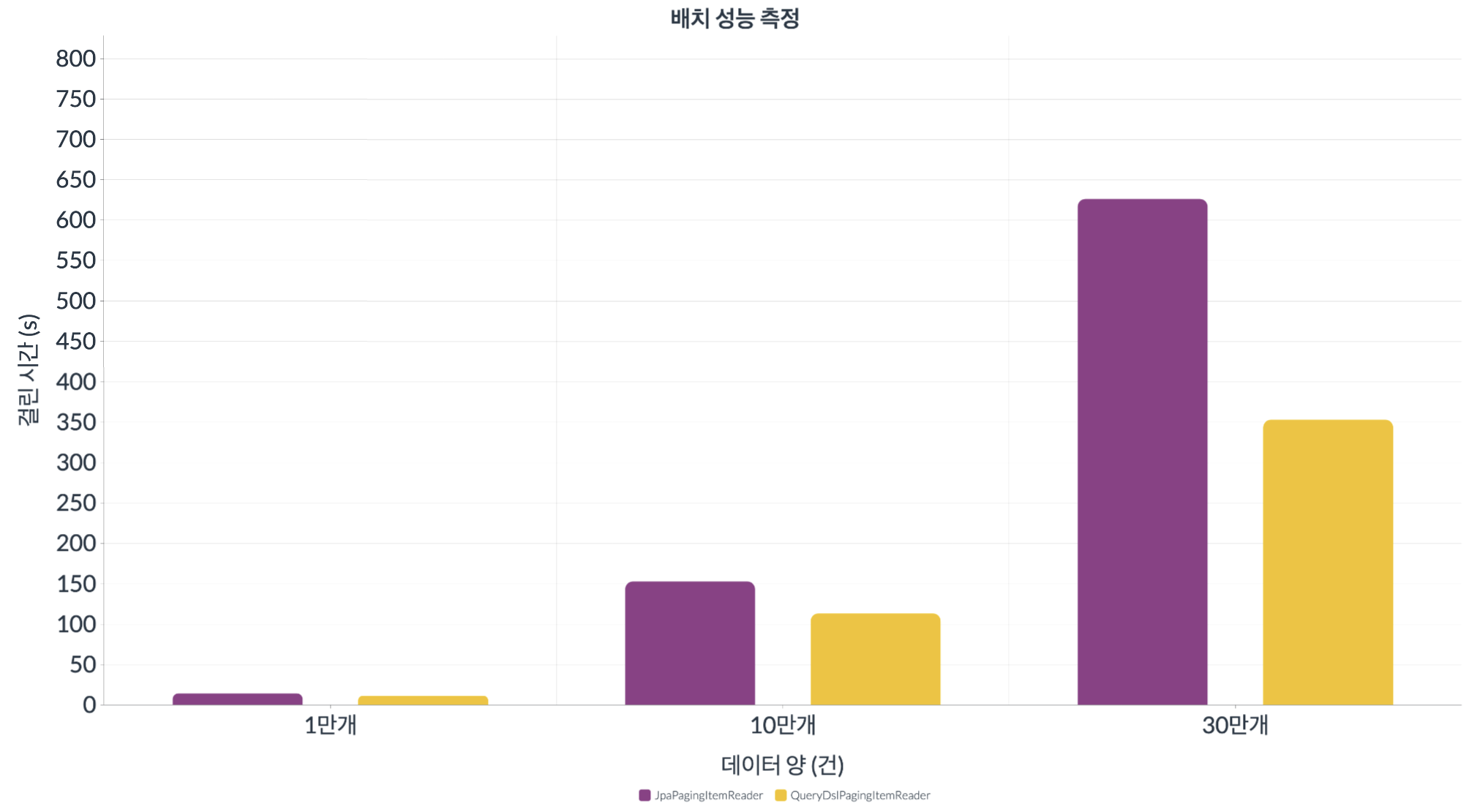
실험은 동일한 네트워크 환경에서 1만, 10만, 30만 개 데이터의 경우에서 진행되었습니다. ChunkSize와 PageSize는 1000개로 동일합니다.
1만개에서 10만개로 데이터가 늘어난 경우
- 데이터는 10배가 증가하였습니다.
JpaPagingItemReader는 11.6배의 시간이 소요되었습니다.
QueryDslPagingItemReader는 10.2배의 시간이 소요되었습니다.
10만 개의 경우 소모시간은 JpaPagingItemReader가 QueryDslPagingItemReader에 비해 1.3배 더 소모되었습니다.
10만개에서 30만개로 데이터가 늘어난 경우
- 데이터는 3배가 증가하였습니다.
JpaPagingItemReader는 4.2배의 시간이 소요되었습니다.
QueryDslPagingItemReader는 3.2배의 시간이 소요되었습니다.
30만 개의 경우 소모시간은 JpaPagingItemReader가 QueryDslPagingItemReader에 비해 1.8배 더 소모되었습니다.
이렇듯 데이터가 늘어날 수록 JpaPagingItemReader가 작업에 필요로 한 시간은 QueryDslPagingItemReader에 비해 월등히 많은 것으로 나타났습니다.
코드에 대한 고찰
제네릭하게 코드를 수정하는 과정에서 복잡도가 조금 올라갔다고 생각되었습니다.
특히 식별자와 메소드를 찾아서 주입해주는 과정이 그러했습니다.
텍스트로 이름이 일치하는 필드와 메소드를 찾아오는 과정이었는데, Reader를 생성할 때 텍스트 형식의 이름만 넣어주고 Reader내에서 각 필드와 메소드를 찾아오게 할까도 싶었지만, 텍스트는 실수가 생길 여지가 있기에 Reader를 생성하기 전으로 코드를 작성하였습니다.
만약 오류가 생겨도 Builder가 실행되기 전에 오류가 생기기 때문입니다. 만약 Reader에서 오류를 내뿜도록 했다면, 쿼리를 날린 후에 오류가 생길지도 모릅니다. 배치 기능이 시작되고 오류를 내는것 보다는 아예 시작이 되기도 전에 오류를 내는 것이 맞다고 생각했습니다.
하지만 추후 조금 더 깔끔하게 수정해보는 단계가 필요하다고 생각됩니다.
Todo
현재 JpaPagingItemReaderBuilder와 JpaPagingItemReader의 코드만 다시 작성해서 구현을 했는데, 추후에 JpaPagingItemReader가 상속하고 있는 AbstractPagingItemReader , AbstractItemCountingItemStreamItemReader 까지 분석을 마치고 QueryDsl에 최적화된 라이브러리를 작성해보고 싶습니다.
