이 전 글에서 mysql like 쿼리로 작성했던 검색기능을 엘라스틱 서치로 바꾸는 과정을 회고했습니다.
엘라스틱 서치를 이용한 검색 기능 성능 개선 (1)
엘라스틱 서치를 적용하기 전 검색 기능은 제목을 기반으로 한 기능이었습니다.
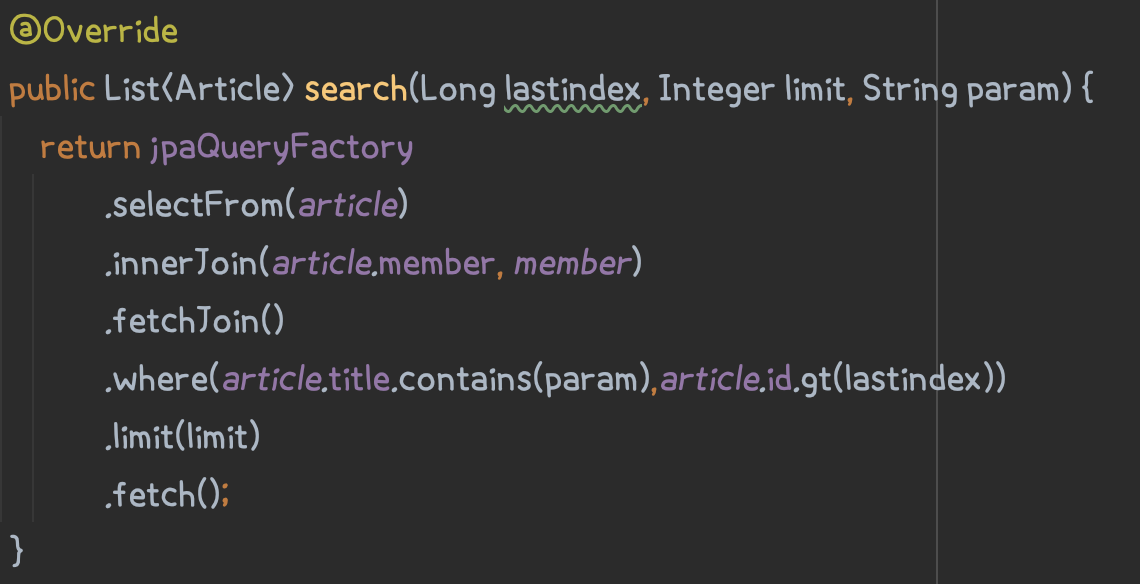
queryDsl을 이용해서 like쿼리를 날리고, 파라미터에 넘긴 문자열이 제목에 포함되어 있는 글을 불러옵니다.
엘라스틱 서치를 적용한 이후에도 ElasticsearchRepository를 통해서 같은 방식으로 구현을 했습니다.
문제
하지만 이러한 방식은 다음과 같은 문제가 발생합니다.

만약 사용자가 "손흥민"에 관해서 검색을 하고 싶은 상황인데, 게시글의 title에는 검색하고자 하는 내용이 담겨있지 않지만 body에는 담겨있는 상황입니다.
이러한 경우에는 title을 기준으로 쿼리를 날리면 조회할 수가 없습니다.
대신 body를 기준으로 검색을 해야합니다.
하지만 다음과 같은 경우도 있을것입니다.

위의 경우 반대로 body에는 검색하고자 하는 내용이 없고 title에는 "손흥민"이라는 검색하고자 하는 파라미터가 존재합니다. 따라서 기존의 방식으로 title을 기준으로 검색해야 합니다.
따라서 우리는 title과 body 모두를 대상으로 검색을 하도록 지정했습니다.
또한 "손흥민 골" 과 같이 여러개의 단어로 이루어져 있는 검색인 경우, 파라미터 자체 뿐만 아니라 파라미터의 부분집합인 "손흥민", "골", "손흥민 골" 세 경우 모두를 포함하는 경우를 검색하도록 작성하였습니다.
구현
먼저 ArticleDocCustomRepository 인터페이스를 작성을 한 후,
public interface ArticleDocCustomRepository {
List<ArticleDoc> find(String parameter);
}ArticleDocCustomRepositoryImpl에서 메소드를 구현하였습니다.
public class ArticleDocCustomRepositoryImpl implements ArticleDocCustomRepository {
@Autowired
private ElasticsearchOperations elasticsearchOperations;
@Override
public List<ArticleDoc> find(String parameter) {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
for (String term : inputList(parameter)) {
boolQueryBuilder.should(QueryBuilders.multiMatchQuery(term, "title", "body"));
}
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.build();
return elasticsearchOperations.search(searchQuery, ArticleDoc.class).getSearchHits()
.stream()
.map(hit -> hit.getContent())
.collect(Collectors.toList());
}
public static List<String> inputList(String input) {
String[] words = input.split(" ");
List<String> combinations = new ArrayList<>();
for (int i = 0; i < words.length; i++) {
StringBuilder sb = new StringBuilder();
for (int j = i; j < words.length; j++) {
sb.append(words[j]);
combinations.add(sb.toString());
if (j != words.length) sb.append(" ");
}
}
return combinations;
}
}
inputList
public static List<String> inputList(String input) {
String[] words = input.split(" ");
List<String> combinations = new ArrayList<>();
for (int i = 0; i < words.length; i++) {
StringBuilder sb = new StringBuilder();
for (int j = i; j < words.length; j++) {
sb.append(words[j]);
combinations.add(sb.toString());
if (j != words.length) sb.append(" ");
}
}
return combinations;
}inputList 에서는 입력으로 들어온 파라미터 값을 분해해서 조합들을 만들어냅니다. 예를 들어 입력이 "손흥민 골 좋다" 라면 반환되는 List에는 "손흥민", "골", "좋다", "손흥민 골", "골 좋다", "손흥민 골 좋다" 라는 요소들이 담기게 됩니다. "골 좋다"의 경우 사실 빠져야하는것 처럼 보입니다. 예를 들어
- 제목: 호날두 오늘 골 좋다
- 내용: ㅈㄱㄴ
같은 내용은 검색하고자 하는 내용과는 상관없기 때문입니다.
하지만 "골 좋다" 이외에도 다른 항목(ex: "손흥민","손흥민 골")들을 같이 검사를 하고, 엘라스틱 서치에서는 BM25라는 알고리즘을 이용하여 연관도를 계산하기 때문에, 그 과정에서 걸러지거나 후순위로 밀려날 것이라고 생각됩니다.
find
public List<ArticleDoc> find(String parameter) {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
for (String term : inputList(parameter)) {
inputList로 생성한 단어 집합으로 쿼리 추가
boolQueryBuilder.should(QueryBuilders.multiMatchQuery(term, "title", "body"));
}
쿼리 빌드
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.build();
쿼리 실행 후, 엔티티로 변환하는 과정
return elasticsearchOperations.search(searchQuery, ArticleDoc.class).getSearchHits()
.stream()
.map(hit -> hit.getContent())
.collect(Collectors.toList());
}위 메소드는 inputList으로 생성한 단어 조합으로 쿼리를 만들어 실행합니다.
실제 실행된 쿼리
실제 실행된 쿼리는 다음과 같습니다.
{
"bool" : {
"should" : [
{
"multi_match" : {
"query" : "손흥민",
"fields" : [
"body^1.0",
"title^1.0"
],
"type" : "best_fields",
"operator" : "OR",
"slop" : 0,
"prefix_length" : 0,
"max_expansions" : 50,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"fuzzy_transpositions" : true,
"boost" : 1.0
}
},
{
"multi_match" : {
"query" : "손흥민 골",
"fields" : [
"body^1.0",
"title^1.0"
],
"type" : "best_fields",
"operator" : "OR",
"slop" : 0,
"prefix_length" : 0,
"max_expansions" : 50,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"fuzzy_transpositions" : true,
"boost" : 1.0
}
},
{
"multi_match" : {
"query" : "손흥민 골 영상",
"fields" : [
"body^1.0",
"title^1.0"
],
"type" : "best_fields",
"operator" : "OR",
"slop" : 0,
"prefix_length" : 0,
"max_expansions" : 50,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"fuzzy_transpositions" : true,
"boost" : 1.0
}
},
{
"multi_match" : {
"query" : "골",
"fields" : [
"body^1.0",
"title^1.0"
],
"type" : "best_fields",
"operator" : "OR",
"slop" : 0,
"prefix_length" : 0,
"max_expansions" : 50,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"fuzzy_transpositions" : true,
"boost" : 1.0
}
},
{
"multi_match" : {
"query" : "골 영상",
"fields" : [
"body^1.0",
"title^1.0"
],
"type" : "best_fields",
"operator" : "OR",
"slop" : 0,
"prefix_length" : 0,
"max_expansions" : 50,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"fuzzy_transpositions" : true,
"boost" : 1.0
}
},
{
"multi_match" : {
"query" : "영상",
"fields" : [
"body^1.0",
"title^1.0"
],
"type" : "best_fields",
"operator" : "OR",
"slop" : 0,
"prefix_length" : 0,
"max_expansions" : 50,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"fuzzy_transpositions" : true,
"boost" : 1.0
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}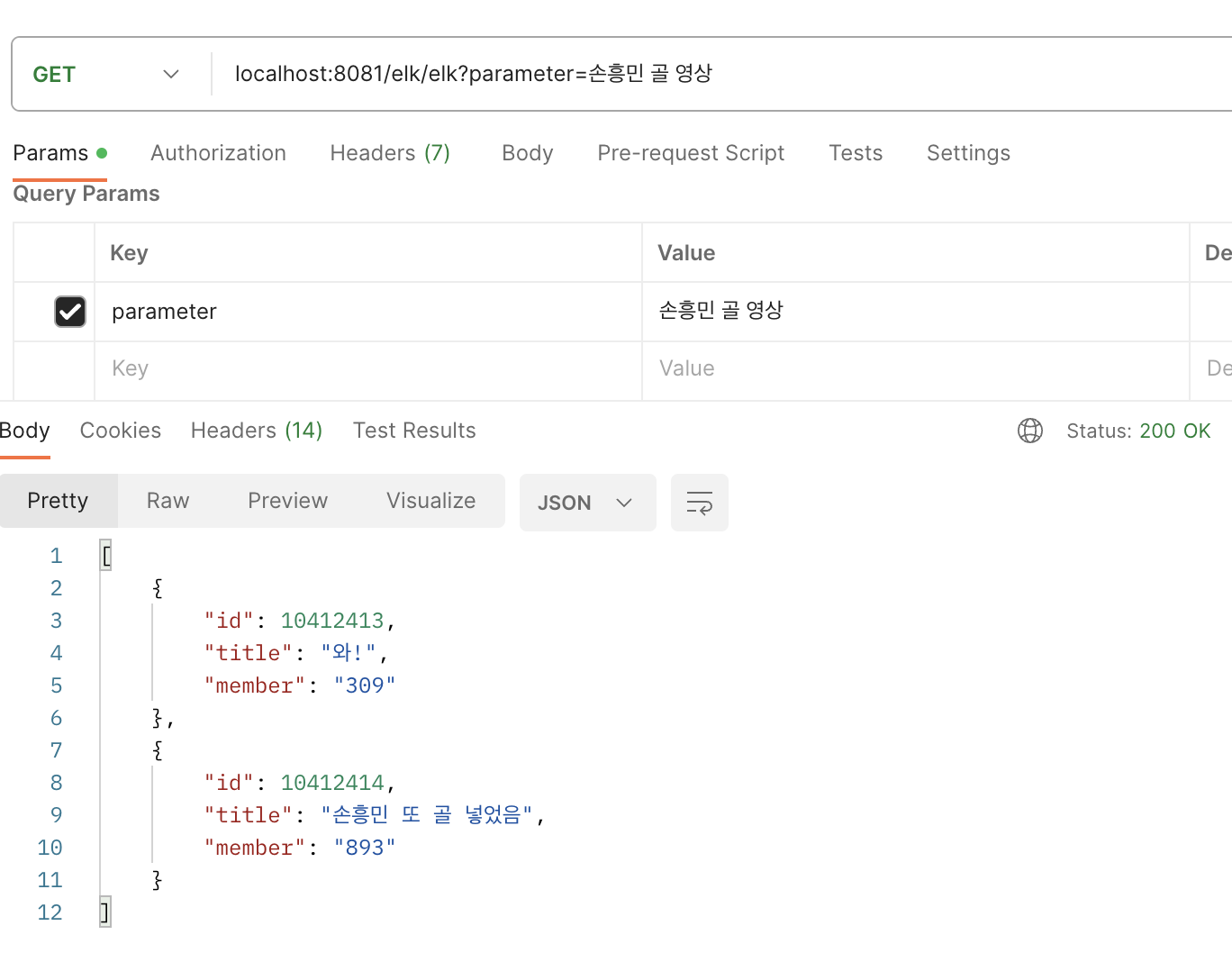
실행결과에서 첫번째 결과를 살펴보면 제목인 "와!"에는 입력으로 준 인자와 매칭되는 단어가 하나도 없음에도 결과로 반환되는 것을 알 수 있습니다.
이는 title이 아닌 body에 인자와 매칭되는 단어가 존재하기 때문입니다.
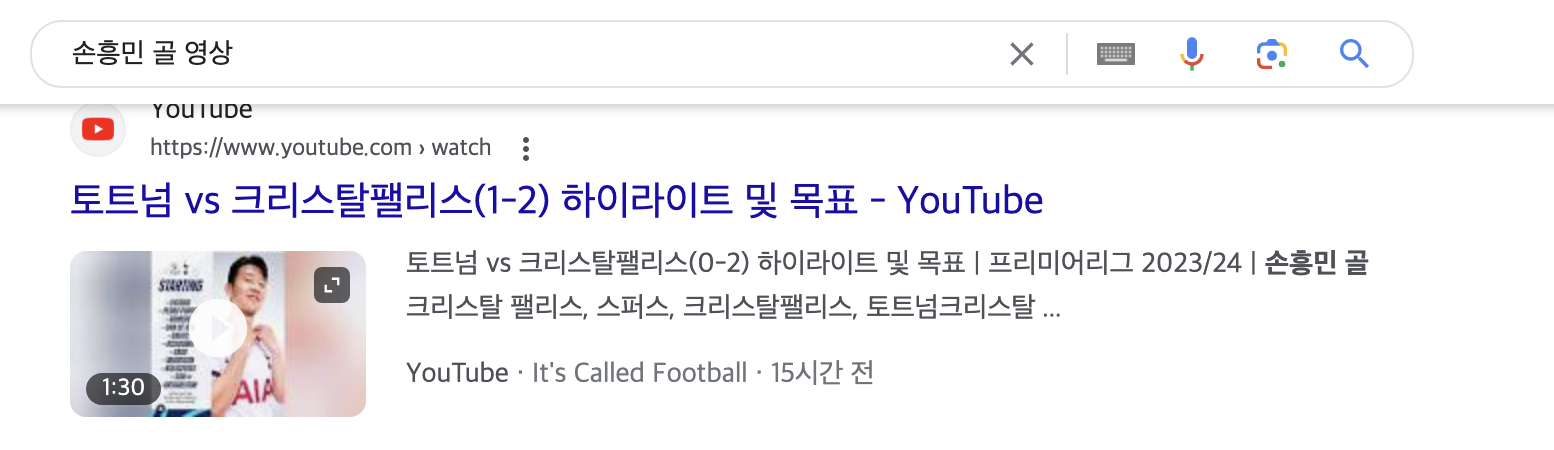
실제로 구글에 검색을 해보면, 제목에는 검색 인자와 일치하는 단어가 하나도 들어가지 않는 결과도 보여주는 것을 알 수 있습니다. (물론 대부분은 제목에 이미 검색 인자가 포함되어 있습니다.)
이처럼 제목 뿐만 아니라 내용까지 살펴보고, 사용자가 인자로 넣은 String 그대로가 아닌 인자를 쪼개서 검색결과를 반환하는 것이 보다 올바른 검색 기능이라는 생각이 들었습니다.
검색 기능에서 엘라스틱 서치가 가진 장점을 이용해서 mysql과는 다른, 조금 더 "검색 기능다운 검색기능"을 구현할 수 있었습니다.
