인터넷 네트워크
인터넷 통신
Http를 위해 네트워크 기본 지식 필요
클라이언트와 서버가 바로 옆에 붙어있으면 상관없는데, 중간에 인터넷망이 있어 데이터를 안전하게 전송하기 위한 방법을 생각해야 한다. 그것을 이해하기 위해 먼저 IP에 대해 알아본다.
IP(Internet Protocol)
클라이언트와 서버에 IP 주소를 부여
- 지정한 IP 주소(IP Address)에 데이터 전달
- 패킷(Packet)이라는 통신 단위로 데이터 전달
IP패킷 정보: 출발지 IP, 목적지IP, 전송 데이터, 기타...
클라이언트와 서버 사이에 있는 인터넷 망은 수많은 노드로 구성되어 있다.
그중에서 목적지IP로 갈 수 있는 노드들을 통해 데이터가 전송된다.
클라이언트와 서버의 패킷 전달 경로는 서로 다를 수 있다.
IP 프로토콜의 한계
- 비연결성 : 패킷을 받을 대상이 없거나 서비스 불능 상태여도 패킷 전송
클라이언트는 대상 서버가 패킷을 받을 수 있는 상태인지 모른다. 그리고 서버가 서비스 불능상태여도 일단 패킷을 전송하고 사라진다. - 비신뢰성 : 중간에 패킷이 사라지면? 패킷이 순서대로 안오면?
중간에 노드가 꺼지거나 문제가 생기면 패킷이 소실된다. - 프로그램 구분 : 같은 IP를 사용하는 서버에서 통신하는 애플리케이션이 둘 이상이면?
패킷의 용량이 크면 여러패킷으로 끊어서 보내는데 (문자의 경우 1500바이트 정도), 최단노드를 찾아서 보내므로 순서가 바껴서 도착할수도 있다.
예) 클라이언트 1: Hello, 2: world! -> 서버 1: world!, 2: Hello
이 문제들을 TCP가 해결해 준다.
TCP, UDP
인터넷 프로토콜 스택의 4계층
애플리케이션 계층 - HTTP, FTP
전송 계층 - TCP, UDP
인터넷 계층 - IP
네트워크 인터페이스 계층
예) 채팅프로그램 사용시
1. 프로그램이 Hello world! 메시지 생성
2. SOCKET 라이브러리를 통해 전달
3. TCP 정보 생성, 메시지 데이터 포함
4. IP 패킷 생성, TCP 데이터 포함
5. LAN카드로 서버에 보냄(Ethernet frame)
TCP/IP 패킷 정보: IP 패킷 정보 안에 TCP 패킷 정보가 있다.
TCP 세그먼트: 출발지 port, 목적지 port, 전송 제어, 순서, 검증 정보
TCP 특징
전송 제어 프로토콜 (Transmission Control Protocol)
- 연결지향 - TCP 3way handshake(가상 연결): 진짜 연결이 된게 아니고 개념적으로만 연결됨
- 데이터 전달 보증: 클라이언트가 서버로 데이터 전송을 하면 서버는 클라이언트로 데이터 잘 받았다고 보낸다.
- 순서 보장: 순서 안맞으면 다시보내라고 요청보냄
- 신뢰할 수 있는 프로토콜
- 현재는 대부분 TCP 사용
TCP 3way handshake
1. 클라이언트에서 서버로 SYN 보냄
2. 서버에서 클라이언트로 SYN+ACK 보냄
3. 클라이언트에서 서버로 ACK 보냄
4. 클라이언트에서 서버로 데이터 전송
1,2,3: connect 과정
SYN: 접속 요청, ACK: 요청 수락
UDP 특징
사용자 데이터그램 프로토콜 (User Datagram Protocol)
- 하얀 도화지에 비유(기능이 거의 없음)
- 연결지향 - TCP 3 way handshake X
- 데이터 전달 보증 X
- 순서 보장 X
- 데이터 전달 및 순서가 보장되지 않지만, 단순하고 빠름
- 정리
IP와 거의 같다. PORT, 체크섬 정도만 추가
애플리케이션에서 추가 작업 필요
port: 하나의 IP에서 여러 애플리케이션을 사용할때(게임, 음악 등등) 어떤게 게임용이고 어떤게 음악용 패킷인지 구분하는 역할
체크섬: 이 메세지에 대해 맞는지 검증해주는 데이터 정도 추가되어있음
TCP는 좋지만 전송속도를 빠르게할 수 없고 데이터 양도 많아진다. 그리고 TCP는 손을 못대기 때문에 UDP위에 내가원하는것을 만들 수 있다. http3에서 udp protocol 사용.
PORT
영어 뜻은 항구
클라이언트에서 한번에 둘 이상의 서버와 연결 할때 구분하기 위해 사용한다.
TCP/IP 패킷 정보에는 출발지 port와 목적지 port가 포함되어있다.
예) 클라이언트 100.100.100.1 게임(8090), 화상통화(21000), 웹브라우저 요청(10010)
서버 200.200.200.2 게임(11220), 화상통화 (32202), 서버 200.200.200.3 웹 브라우저 요청(80)
100.100.100.1 게임(8090)- 200.200.200.2 게임(11220)
100.100.100.1 화상통화(21000)- 200.200.200.2 화상통화(32202)
100.100.100.1 웹브라우저 요청(10010)- 200.200.200.3 웹브라우저 요청(80)
- 0~65535 할당 가능
- 0~1023 잘 알려진 포트, 사용하지 않는 것이 좋음
FTP - 20,21
TELNET - 23
HTTP - 80
HTTPS - 443
DNS
- IP는 기억하기 어렵다. IP: 100.100.100.1
- IP는 변경될 수 있다. -> IP: 100.100.100.2
DNS
도메인 네임 시스템 (Domain Name System)
- 전화번호부
- 도메인 명을 IP주소로 변환
인터넷 네트워크 정리
IP의 한계를 극복하기 위해 TCP 도입, UDP는 IP와 비슷한데 port가 추가됐고, 필요하면 애플리케이션에서 기능확장 가능
port는 같은 IP 안에서 동작하는 애플리케이션을 구분하기 위해서 사용, IP가 아파트라면 port는 동호수
DNS는 변경될 수 있고 외우기 힘든 IP를 대신해서 사용
URI와 웹 브라우저 요청 흐름
URI
URI(Uniform Resource Identifier)
resource를 식별하는 통합된 방법
URI는 locator, name 또는 둘 다 추가로 분류될 수 있다.
URI 안에 URL, URN이 있다.
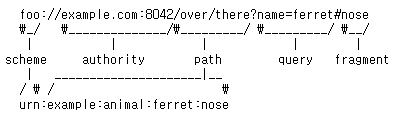
https://www.ietf.org/rfc/rfc3986.txt
위가 URL, 아래가 URN인데 보통 URL을 주로 쓴다.
URI 단어 뜻
- Uniform : 리소스 식별하는 통일된 방식
- Resource: 자원, URI로 식별할 수 있는 모든 것(제한없음)
- Identifier: 다른 항목과 구분하는데 필요한 정보
URL, URN 단어 뜻
- URL - Locator : 리소스가 있는 위치를 지정
- URN - Name : 리소스에 이름을 부여
- 위치는 변할 수 있지만, 이름은 변하지 않는다.
- urn:isbn:8960777331 (어떤 책의 isbn URN)
- URN 이름만으로 실제 리소스를 찾을 수 있는 방법이 보편화 되지 않음
- 앞으로 URI를 URL과 같은 의미로 이야기 하겠음
URL 분석
https://www.google.com/search?q=hello&hl=ko
전체문법
scheme://[userinfo@]host[:port][/path][?query][#fragment]
https://www.google.com:443/search?q=hello&hl=ko
- 프로토콜(https)
- 호스트명(www.google.com)
- 포트 번호 (443)
- 패스(/search)
- 쿼리 파라미터(q=hello&hl=ko)
scheme
scheme://[userinfo@]host[:port][/path][?query][#fragment]
https://www.google.com:443/search?q=hello&hl=ko
- 주로 프로토콜 사용
- 프로토콜: 어떤 방식으로 자원에 접근할 것인가 하는 약속 규칙
예) http, https, ftp 등등 - http는 80포트, https는 443 포트를 주로 사용, 포트는 생략 가능
- https는 http에 보안 추가 (HTTP Secure)
userinfo
scheme://[userinfo@]host[:port][/path][?query][#fragment]
htps://www.google.com:443/search?q=hello&hl=ko
- URL에 사용자정보를 포함해서 인증
- 거의 사용하지 않음
host
scheme://[userinfo@]host[:port][/path][?query][#fragment]
htps://www.google.com:443/search?q=hello&hl=ko
- 호스트명
- 도메인명 또는 IP주소를 직접 사용가능
port
scheme://[userinfo@]host[:port][/path][?query][#fragment]
htps://www.google.com:443/search?q=hello&hl=ko
- 포트(PORT)
- 접속 포트
- 일반적으로 생략, 생략시 http는 80, https는 443
path
scheme://[userinfo@]host[:port][/path][?query][#fragment]
htps://www.google.com:443/search?q=hello&hl=ko
- 리소스 경로(path), 계층적 구조
- 예) /home/file1.jpg, /members, /members/100, /items/iphone12
query
scheme://[userinfo@]host[:port][/path][?query][#fragment]
htps://www.google.com:443/search?q=hello&hl=ko
- key=value 형태
- ?로 시작, &로 추가 가능 ?keyA=valueA&keyB=valueB
- query parameter, query string 등으로 불림, 웹서버에 제공하는 파라미터, 문자 형태
fragment
scheme://[userinfo@]host[:port][/path][?query][#fragment]
https://docs.spring.io/spring-boot/docs/current/reference/html/getting-started.html#getting-started-introducing-spring-boot
- fragment
- html 내부 북마크 등에 사용
- 서버에 전송하는 정보 아님
웹 브라우저 요청 흐름
https://www.google.com:443/search?q=hello&hl=ko
DNS조회, HTTPS PORT 생략, 443
웹브라우저에서 http 요청 메시지 생성한다
HTTP 요청 메시지
GET /search?q=hello&hl=ko HTTP/1.1
Host: www.google.com- 웹브라우저가 http 메시지 생성
- SOCKET 라이브러리를 통해 전달
-A:TCP/IP 연결(IP,PORT)
-B:데이터 전달 - TCP/IP 패킷 생성, http 메시지 데이터 포함
- LAN카드로 인터넷을 통해 http 메시지를 서버에 전송
구글 서버에서는 TCP/IP 패킷은 까서 버리고 http 메시지만 해석을 한다.
HTTP 응답 메시지
HTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Content-Length: 3423
<html>
<body>...</body>
</html>
클라이언트의 웹 브라우저가 http 응답 메시지를 렌더링 해서 결과를 볼 수 있다.
HTTP 기본
모든 것이 HTTP
HTTP (Hyper Text Transfer Protocol)
html을 전송하는 프로토콜로 처음 시작됐는데 지금은 모든 것을 전송할 수 있다.
- HTML, TEXT
- IMAGE, 음성, 영상, 파일
- JSON, XML (API)
- 거의 모든 형태의 데이터 전송 가능
- 서버간에 데이터를 주고 받을 때도 대부분 HTTP 사용
- 지금은 HTTP 시대!
HTTP 역사
- HTTP/0.9 1991년: GET 메서드만 지원, HTTP 헤더X
- HTTP/1.0 1996년: 메서드, 헤더 추가
- HTTP/1.1 1997년: 가장 많이 사용, 우리에게 가장 중요한 버전
RFC2068 (1997) -> RFC2616 (1999) -> RFC7230~7235 (2014) - HTTP/2 2015년: 성능 개선
- HTTP/3 진행중: TCP 대신에 UDP 사용, 성능 개선
기반 프로토콜
- TCP: HTTP/1.1, HTTP/2
- UDP: HTTP/3
- 현재 HTTP/1.1 주로 사용
- HTTP/2, HTTP/3도 점점 증가
HTTP 특징
- 클라이언트 서버 구조로 동작한다
- 무상태 프로토콜(Stateless) 지향, 비연결성
- HTTP 메시지를 통해서 통신한다
- 단순하고 확장 가능하다
클라이언트 서버 구조
- Request Response 구조이다
- 클라이언트는 서버에 요청을 보내고, 응답을 대기한다
- 서버가 요청에 대한 결과를 만들어서 응답한다
- 응답 결과를 열어서 클라이언트가 동작한다
옛날에는 클라이언트와 서버가 통합되어 있었는데, 지금은 분리해서 비즈니스로직과 데이터 등은 서버에 밀어넣고 클라이언트는 ui,사용성 등에 집중한다. 그러면 클라이언트와 서버가 각각 독립적으로 진화할 수 있다.
Stateful, Stateless
무상태 프로토콜(stateless)
- 서버가 클라이언트의 상태를 보존X
- 장점: 서버 확장성 높음 (스케일 아웃)
- 단점: 클라이언트가 추가 데이터 전송
상태 유지 - Stateful
고객: 이 노트북 얼마인가요?
점원: 100만원 입니다. (노트북 상태 유지)
고객: 2개 구매하겠습니다.
점원: 200만원 입니다. 신용카드, 현금 중에 어떤 걸로 구매 하시겠어요? (노트북, 2개 상태 유지)
고객: 신용카드로 구매하겠습니다.
점원: 200만원 결제 완료되었습니다. (노트북, 2개, 신용카드 상태 유지)
무상태 - Stateless
고객: 이 노트북 얼마인가요?
점원: 100만원 입니다.
고객: 노트북 2개 구매하겠습니다.
점원: 노트북 2개는 200만원 입니다. 신용카드, 현금중에 어떤 걸로 구매 하시겠어요?
고객: 노트북 2개를 신용카드로 구매하겠습니다.
점원: 200만원 결제 완료되었습니다.
Stateful, Stateless 차이
정리
- 상태 유지: 중간에 다른 점원으로 바뀌면 안된다. -> 중간에 서버 장애나면 클라이언트 일을 처음부터 다시 해야한다.
(중간에 다른 점원으로 바뀔 때 상태 정보를 다른 점원에게 미리 알려줘야 한다.) - 무상태: 중간에 다른 점원으로 바뀌어도 된다.
-갑자기 고객이 증가해도 점원을 대거 투입할 수 있다.
-갑자기 클라이언트 요청이 증가해도 서버를 대거 투입할 수 있다. (스케일아웃) - 무상태는 응답 서버를 쉽게 바꿀 수 있다. -> 무한한 서버 증설 가능
Stateless
실무한계
- 모든 것을 무상태로 설계할 수 있는 경우도 있고 없는 경우도 있다
- 무상태 예) 로그인이 필요 없는 단순한 서비스 소개 화면
- 상태 유지 예) 로그인
- 로그인한 사용자의 경우 로그인 했다는 상태를 서버에 유지
- 일반적으로 브라우저 쿠키와 서버 세션 등을 사용해서 상태 유지
- 상태 유지는 최소한만 사용
비 연결성(connectionless)
클라이언트와 서버는 요청을 주고 받을때만 연결을 유지해서 최소한의 자원을 사용한다.
- HTTP는 기본이 연결을 유지하지 않는 모델
- 일반적으로 초 단위 이하의 빠른 속도로 응답
- 1시간 동안 수천명이 서비스를 사용해도 실제 서버에서 동시에 처리하는 요청은 수십개 이하로 매우 작음
예) 웹 브라우저에서 계속 연속해서 검색 버튼을 누르지는 않는다. - 서버 자원을 매우 효율적으로 사용할 수 있음
한계와 극복
- TCP/IP 연결을 새로 맺어야 함 - 3 way handshake 시간 추가
- 웹 브라우저로 사이트를 요청하면 HTML뿐만 아니라 자바스크립트, css, 추가 이미지 등 수 많은 자원이 함께 다운로드
- 지금은 HTTP 지속 연결 (Persistent Connections)로 문제 해결
- HTTP/2, HTTP/3에서 더 많은 최적화
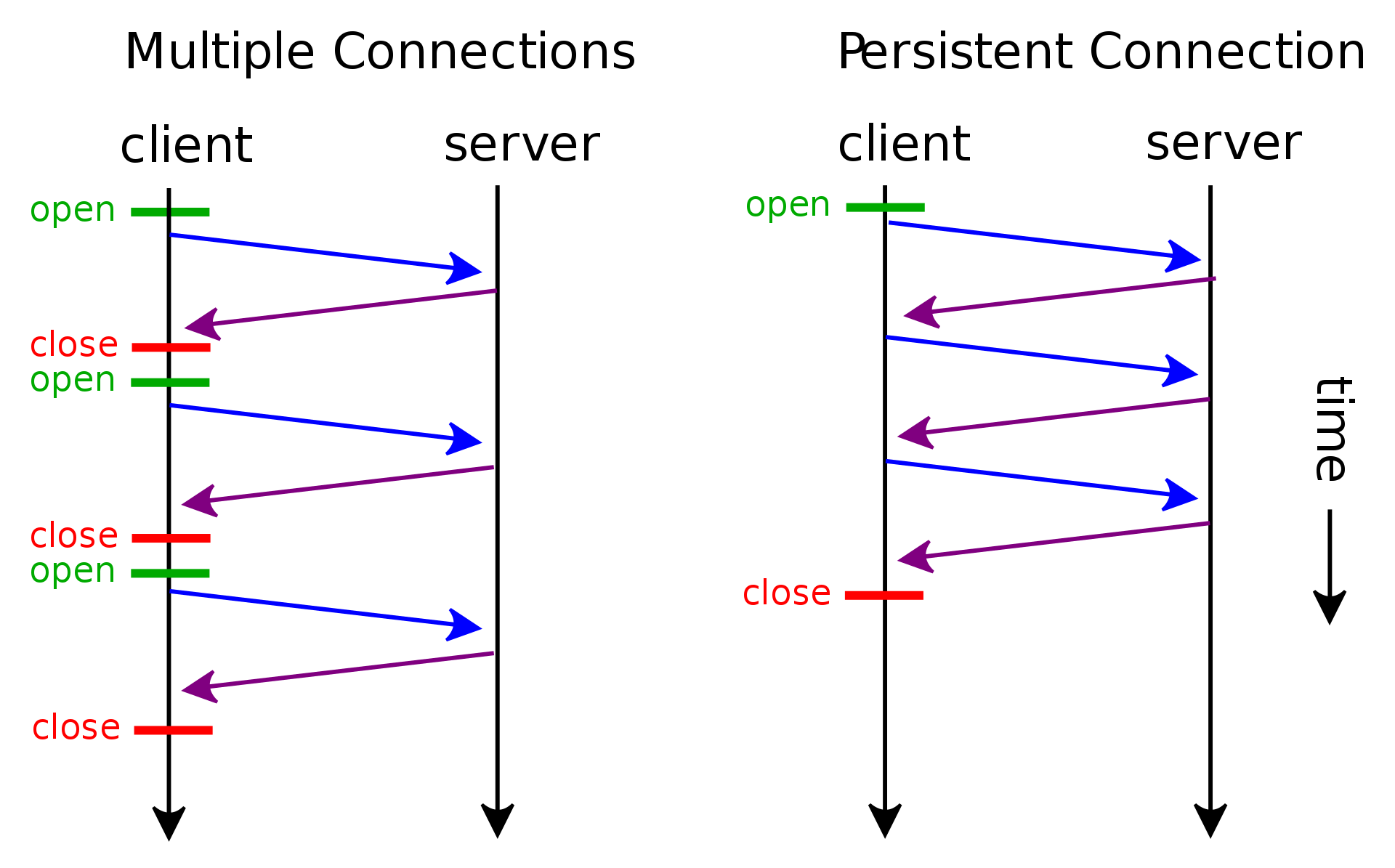
Stateless를 기억하자
서버개발자들이 어려워하는 업무
- 정말 같은 시간에 딱 맞추어 발생하는 대용량 트래픽
- 예) 선착순 이벤트, 명절 KTX 예약, 학과 수업 등록
- 예) 저녁 6:00 선착순 1000명 치킨 할인 이벤트 -> 수만명 동시 요청
HTTP 메시지
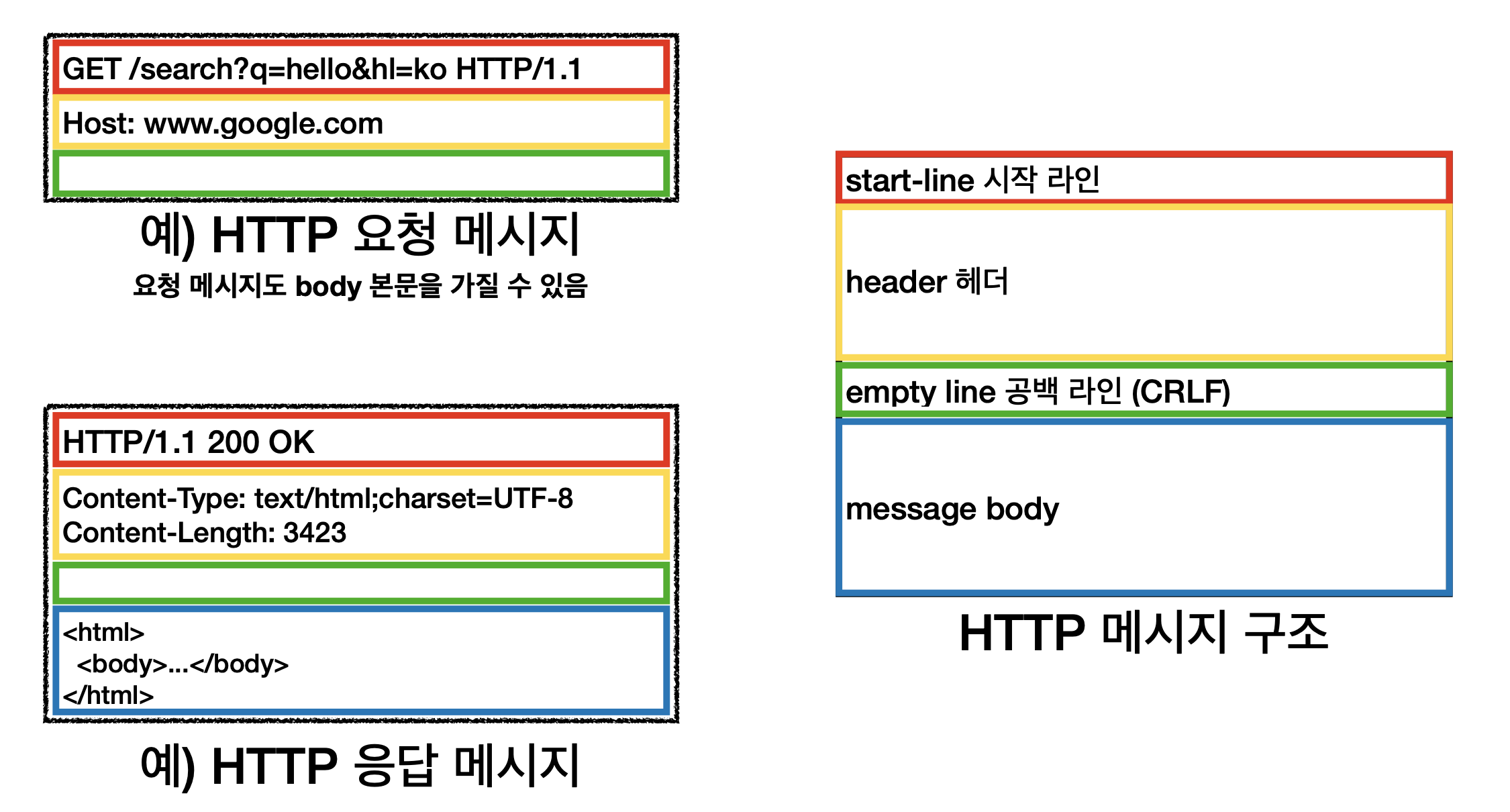
시작라인
요청 메시지
-
start-line = request-line / status-line
-
request-line = method SP(공백) request-target(PATH=요청하는대상) SP HTTP-version CRLF (엔터)
-
HTTP 메서드 (GET:조회)
종류: GET, POST, PUT, DELETE...
서버가 수행해야 할 동작 지정
GET: 리소스 조회
POST: 요청 내역 처리 -
요청 대상 (/search?q=hello&hl=ko)
absolute-path[?query] 절대경로[?쿼리]
절대경로 = "/"로 시작하는 경로
참고: *, http://...?x=y 와 같이 다른 유형의 경로지정 방법도 있다. -
HTTP version
응답 메시지
-
start-line = request-line / status-line
-
status-line = HTTP-version SP status-code SP reason-phrase CRLF
-
HTTP 버전
-HTTP 상태 코드: 요청 성공, 실패를 나타냄
200: 성공
400: 클라이언트 요청 오류
500: 서버 내부 오류 -
이유 문구: 사람이 이해할 수 이쓴 짧은 상태 코드 설명 글
HTTP 헤더
header-field = field-name ":" OWS field-value OWS (OWS:띄어쓰기 허용)
field-name은 대소문자 구분 없음
HTTP 요청 메시지
GET /search?q=hello&hl=ko HTTP/1.1
Host: www.google.com
HTTP 응답 메시지
HTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Content-Length: 3423
용도
- HTTP 전송에 필요한 모든 부가정보
- 예) 메시지 바디의 내용, 메시지 바디의 크기, 압축, 인증, 요청 클라이언트(브라우저) 정보, 서버 애플리케이션 정보, 캐시 관리 정보...
- 표준 헤더가 너무 많음
- 필요시 임의의 헤더 추가 가능
예) heeloworld: hihi
HTTP 메시지 바디
용도
- 실제 전송할 데이터
- HTML문서, 이미지, 영상, JSON 등등 byte로 표현할 수 있는 모든 데이터 전송 가능
단순함 확장 가능
- HTTP는 단순하다. 스펙도 읽어볼만..
- HTTP 메시지도 매우 단순
- 크게 성공하는 표준 기술은 단순하지만 확장 가능한 기술
HTTP 정리
- HTTP 메시지에 모든 것을 전송
- HTTP 역사 HTTP/1.1을 기준으로 학습
- 클라이언트 서버 구조
- 무상태 프로토콜(Stateless)
- HTTP 메시지
- 단순함, 확장 가능
- 지금은 HTTP 시대
HTTP 메서드
HTTP API를 만들어보자
요구사항
회원 정보 관리 API를 만들어라.
가장 중요한 것은 리소스 식별
- 리소스의 의미는 뭘까?
회원을 등록하고 수정하고 조회하는게 리소스가 아니다!
예) 미네랄을 캐라 -> 미네랄이 리소스
회원이라는 개념 자체가 바로 리소스다. - 리소스를 어떻게 식별하는게 좋을까?
회원을 등록하고 수정하고 조회하는 것을 모두 배제
회원이라는 리소스만 식별하면 된다. -> 회원 리소스를 URI에 매핑
API URI 설계
URI(Uniform Resource Identifier)
리소스 식별, URI 계층 구조 활용
- 회원 목록 조회 /members
- 회원 조회 /members/{id} -> 어떻게 구분하지?
- 회원 등록 /members/{id} -> 어떻게 구분하지?
- 회원 수정 /members/{id} -> 어떻게 구분하지?
- 회원 삭제 /members/{id} -> 어떻게 구분하지?
- 참고: 계층 구조상 상위를 컬렉션으로 보고 복수단어 사용 권장(member -> members)
리소스와 행위를 분리
가장 중요한 것은 리소스를 식별하는 것
- URI는 리소스만 식별!
- 리소스와 해당 리소스를 대상으로 하는 행위를 분리
리소스: 회원
행위: 조회, 등록, 삭제, 변경
-리소스는 명사, 행위는 동사 (미네랄 을 캐라) - 행위(메서드)는 어떻게 구분?
HTTP 메서드 종류
주요 메서드
- GET: 리소스 조회
- POST: 요청 데이터 처리, 주로 등록에 사용
- PUT: 리소스를 대체, 해당 리소스가 없으면 생성
- PATCH: 리소스 부분 변경
- DELETE: 리소스 삭제
기타 메서드
- HEAD: GET과 동일하지만 메시지 부분을 제외하고, 상태 줄과 헤더만 반환
- OPTIONS: 대상 리소스에 대한 통신 가능 옵션(메서드)을 설명(주로 CORS에서 사용)
- CONNECT: 대상 자원으로 식별되는 서버에 대한 터널을 설정
- TRACE: 대상 리소스에 대한 경로를 따라 메시지 루프백 테스트를 수행
GET
- 리소스 조회
- 서버에 전달하고 싶은 데이터는 query(쿼리 파라미터, 쿼리 스트링)를 통해서 전달
- 메시지 바디를 사용해서 데이터를 전달할 수 있지만, 지원하지 않는 곳이 많아서 권장하지 않음
POST
- 요청 데이터 처리
- 메시지 바디를 통해 서버로 요청 데이터 전달
- 서버는 요청 데이터를 처리
- 메시지 바디를 통해 들어온 데이터를 처리하는 모든 기능을 수행한다.
- 주로 전달된 데이터로 신규 리소스 등록, 프로세스 처리에 사용
POST /members HTTP/1.1
Content-Type: application/json
{
"username": "hello",
"age": 20
}요청 데이터를 어떻게 처리한다는 뜻일까? 예시
-
스펙: POST 메서드는 대상 리소스가 리소스의 고유한 의미 체계에 따라 요청에 포함된 표현을 처리하도록 요청한다. (구글번역)
-
예를 들어 POST는 다음과 같은 기능에 사용된다.
- HTML 양식에 입력된 필드와 같은 데이터 블록을 데이터 처리 프로세스에 제공
예) HTML FORM에 입력한 정보로 회원 가입, 주문 등에서 사용 - 게시판, 뉴스 그룹, 메일링 리스트, 블로그 또는 유사한 기사 그룹에 메시지 게시
예) 게시판 글쓰기, 댓글 달기 - 서버가 아직 식별하지 않은 새 리소스 생성
예) 신규 주문 생성 - 기존 자원에 데이터 추가
예) 한 문서 끝에 내용 추가하기
- HTML 양식에 입력된 필드와 같은 데이터 블록을 데이터 처리 프로세스에 제공
-
정리: 이 리소스 URI에 POST 요청이 오면 요청 데이터를 어떻게 처리할지 리소스마다 따로 정해야함 -> 정해진 것이 없다
정리
1. 새 리소스 생성(등록)
- 서버가 아직 식별하지 않은 새 리소스 생성
- 요청 데이터 처리
- 단순히 데이터를 생성하거나, 변경하는 것을 넘어서 프로세스를 처리해야 하는 경우
- 예) 주문에서 결제 완료-> 배달 시작-> 배달 완료 처럼 단순히 값 변경을 넘어 프로세스의 상태가 변경되는 경우
- POST의 결과로 새로운 리소스가 생성되지 않을 수도 있음
- 예) POST /orders/{orderId}/start-delivery(컨트롤URI)
- 다른 메서드로 처리하기 애매한 경우
- 예) JSON으로 조회 데이터를 넘겨야 하는데, GET 메서드를 사용하기 어려운 경우
- 애매하면 POST
PUT
- 리소스를 대체
- 리소스가 있으면 대체
- 리소스가 없으면 생성
- 쉽게 이야기해서 덮어버림
- 중요! 클라이언트가 리소스를 식별
- 클라이언트가 리소스 위치를 알고 URI 지정
- POST와 차이점
PUT /members/100 HTTP/1.1
Content-Type: application/json
{
"username": "hello",
"age": 20
}리소스가 있는 경우1
PUT /members/100 HTTP/1.1
Content-Type: application/json
{
"username": "old",
"age": 50
}->
/members/100
{
"username": "hello",
"age": 20
}=
{
"username": "old",
"age": 50
}리소스가 없는 경우1
PUT /members/100 HTTP/1.1
Content-Type: application/json
{
"username": "old",
"age": 50
}->
/members/100
이런 리소스 없음
=
{
"username": "old",
"age": 50
}주의! - 리소스를 완전히 대체한다1
PUT /members/100 HTTP/1.1
Content-Type: application/json
{
"age": 50
}->
/members/100
{
"username": "hello",
"age": 20
}=
{
"age": 50
}기존리소스를 삭제하고 대체해서 username 필드가 삭제됨
PATCH
- 리소스 부분 변경
PATCH /members/100 HTTP/1.1
Content-Type: application/json
{
"age": 50
}->
/members/100
{
"username": "young",
"age": 20
}=
{
"username": "young",
"age": 50
}age만 50으로 변경
DELETE
- 리소스 제거
DELETE /members/100 HTTP/1.1
Host: localhost:8080HTTP 메서드의 속성
- 안전(Safe Methods)
- 멱등(Idempotent Methods)
- 캐시가능(Cacheable Methods)
안전
Safe
- 호출해도 리소스를 변경하지 않는다.
- Q: 그래도 계속 호출해서, 로그 같은게 쌓여서 장애가 발생하면요?
- A: 안전은 해당 리소스만 고려한다. 그런 부분까지 고려하지 않는다.
멱등
Idempotent
-
f(f(x)) = f(x)
-
한 번 호출하든 두 번 호출하든 100번 호출하든 결과가 똑같다.
-
멱등 메서드
-
GET: 한 번 조회하든, 두 번 조회하든 같은 결과가 조회된다.
-
PUT: 결과를 대체한다. 따라서 같은 요청을 여러번 해도 최종 결과는 같다.
-
DELETE: 결과를 삭제한다. 같은 요청을 여러번 해도 삭제된 결과는 똑같다.
-
POST: 멱등이 아니다! 두 번 호출하면 같은 결제가 중복해서 발생할 수 있다.
-
활용
- 자동 복구 매커니즘
- 서버가 TIMEOUT 등으로 정상 응답을 못주었을 때, 클라이언트가 같은 요청을 다시 해도 되는가? 판단 근거
-
Q: 재요청 중간에 다른 곳에서 리소스를 변경해버리면?
- 사용자1: GET -> username:A, age:20
- 사용자2: PUT -> username:A, age:30
- 사용자1: GET -> username:A, age:30 -> 사용자2의 영향으로 바뀐 데이터 조회
-
A: 멱등은 외부 요인으로 중간에 리소스가 변경되는 것 까지는 고려하지 않는다.
캐시 가능
Cacheable
- 응답 결과 리소스를 캐시해서 사용해도 되는가?
- GET, HEAD, POST, PATCH 캐시 가능
- 실제로는 GET, HEAD 정도만 캐시로 사용
- POST, PATCH는 본문 내용까지 캐시 키로 고려해야 하는데, 구현이 쉽지 않음
HTTP 메서드 활용
클라이언트에서 서버로 데이터 전송
데이터 전달 방식은 크게 2가지
- 쿼리 파라미터를 통한 데이터 전송
- GET
- 주로 정렬 필터(검색어) - 메시지 바디를 통한 데이터 전송
- POST, PUT, PATH
- 회원가입, 상품 주문, 리소스 등록, 리소스 변경
4가지 상황
- 정적 데이터 조회
- 이미지, 정적 텍스트 문서
- 동적 데이터 조회
- 주로 검색, 게시판 목록에서 정렬 필터(검색어)
- HTML Form을 통한 데이터 전송
- 회원 가입, 상품 주문, 데이터 변경
- HTTP API를 통한 데이터 전송
- 회원 가입, 상품 주문, 데이터 변경
- 서버 to 서버, 앱 클라이언트, 웹 클라이언트(Ajax)
정적 데이터 조회
쿼리 파라미터 미사용
GET /static/star.jpg HTTP/1.1
Host: localhost:8080정리
- 이미지, 정적 텍스트 문서
- 조회는 GET 사용
- 정적 데이터는 일반적으로 쿼리 파라미터 없이 리소스 경로로 단순하게 조회 가능
쿼리 파라미터 사용
GET /search?q=hello&hl=ko HTTP/1.1
Host: www.google.com쿼리 파라미터를 기반으로 정렬 필터해서 결과를 동적으로 생성
정리
- 주로 검색, 게시판 목록에서 정렬 필터(검색어)
- 조회 조건을 줄여주는 필터, 조회 결과를 정렬하는 정렬 조건에 주로 사용
- 조회는 GET 사용
- GET은 쿼리 파라미터 사용해서 데이터를 전달
HTML Form 데이터 전송
POST 전송 - 저장
<form action="/save" method="post">
<input type="text" name="username" />
<input type="text" name="age" />
<button type="submit">전송</button>
</form>-> 웹 브라우저가 생성한 요청 HTTP 메시지
POST /save HTTP/1.1
Host: localhost:8080
Content-Type: application/x-www-form-urlencoded
username=kim&age=20GET 전송 - 저장
<form action="/save" method=get">
<input type="text" name="username" />
<input type="text" name="age" />
<button type="submit">전송</button>
</form>-> 웹 브라우저가 생성한 요청 HTTP 메시지
GET /save?username=kim&age=20 HTTP/1.1
Host: localhost:8080주의! GET은 조회에만 사용!
리소스 변경이 발생하는 곳에 사용하면 안됨!
멤버 조회할때 사용 가능
HTML Form 데이터 전송
multipart/form-data
파일 업로드할때 사용한다
default는 x-www-form 이다.
<form action="/save" method="post" enctype="multipart/form-data">
<input type="text" name="username" />
<input type="text" name="age" />
<input type="file" name="file1" />
<button type="submit">전송</button>
</form>-> 웹 브라우저가 생성한 요청 HTTP 메시지
POST /save HTTP/1.1
Host: localhost:8080
Content-Type: multipart/form-data; boundary=----XXX
Content-Length: 10457
----XXX
Content-Disposition: form-data; name="username"
kim
----XXX
Content-Disposition: form-data; name="age"
20
----XXX
Content-Disposition: form-data; name="file1"; filename="intro.png"
Content-Type: image/png
1012021093fdfafa029131230afsd
----XXX정리
- HTML Form submit시 POST 전송
- 예) 회원 가입, 상품 주문, 데이터 변경
- Content-Type: application/x-www-form-urlencoded 사용
- form의 내용을 메시지 바디를 통해서 전송(key=value, 쿼리 파라미터 형식)
- 전송 데이터를 url encoding 처리
- 예) abc김 -> abc%EA%B9%80
- HTML Form은 GET 전송도 가능
- Content-Type: multipart/form-data
- 파일 업로드 같은 바이너리 데이터 전송시 사용
- 다른 종류의 여러 파일과 폼의 내용을 함께 전송 가능(그래서 이름이 multipart)
- 참고: HTML Form 전송은 GET, POST만 지원
HTTP API 데이터 전송
POST /members HTTP/1.1
Content-Type: application/json
(
"username": "young",
"age": 20
)정리
- 서버 to 서버
- 백엔드 시스템 통신
- 앱 클라이언트
- 아이폰, 안드로이드
- 웹 클라이언트
- HTML에서 Form 전송 대신 자바 스크립트를 통한 통신에 사용(AJAX)
- 예) React, VueJs 같은 웹 클라이언트와 API 통신
- POST, PUT, PATCH: 메시지 바디를 통해 데이터 전송
- GET: 조회, 쿼리, 파라미터로 데이터 전달
- Content-Type: application/json을 주로 사용 (사실상 표준)
- TEXT, XML, JSON 등등
HTTP 설계 예시
- HTTP API -컬렉션
- POST 기반 등록
- 예) 회원관리 API 제공
- HTTP API - 스토어
- PUT 기반 등록
- 예) 정적 컨텐츠 관리, 원격 파일 관리
- HTML: FORM 사용
- 웹 페이지 회원 관리
- GET, POST만 지원
회원 관리 시스템
API 설계 - POST 기반 등록
- 회원 목록 /members -> GET
- 회원 등록 /members -> POST
- 회원 조회 /members/{id} -> GET
- 회원 수정 /members/{id} -> PATCH, PUT, POST
- 회원 삭제 /members/{id} -> DELETE
회원 관리 시스템
POST - 신규 자원 등록 특징
- 클라이언트는 등록될 리소스의 URI를 모른다.
- 회원등록 /members -> POST
- POST /members
- 서버가 새로 등록된 리소스 URI를 생성해준다.
- HTTP/1.1 201 Created
Location: /members/100
- HTTP/1.1 201 Created
- 컬렉션 (Collection)
- 서버가 관리하는 리소스 디렉토리
- 서버가 리소스의 URI를 생성하고 관리
- 여기서 컬렉션은 /members
파일 관리 시스템
API 설계 - PUT 기반 등록
- 파일 목록 /files -> GET
- 파일 조회 /files/{filename} -> GET
- 파일 등록 /files/{filename} -> PUT
- 파일 삭제 /files/{filename} -> DELETE
- 파일 대량 등록 /files -> POST
파일 관리 시스템
PUT - 신규 자원 등록 특징
- 클라이언트가 리소스 URI를 알고 있어야 한다.
- 파일 등록 /files/{filename} -> PUT
- PUT /files/star.jpg
- 클라이언트가 직접 리소스의 URI를 지정한다.
- 스토어(store)
- 클라이언트가 관리하는 리소스 저장소
- 클라이언트가 리소스의 URI를 알고 관리
- 여기서 스토어는 /files
HTML FORM 사용
-
HTML FORM은 GET, POST만 지원
-
AJAX 같은 기술을 사용해서 해결 가능 -> 회원 API 참고
-
여기서는 순수 HTML, HTML FORM 이야기
-
GET, POST만 지원하므로 제약이 있음
-
회원 목록 /members -> GET
-
회원 등록 폼 /members/new -> GET
-
회원 등록 /members/new, /members -> POST
-
회원 조회 /members/{id} -> GET
-
회원 수정 폼 /members/{id}/edit -> GET
-
회원 수정 /members/{id}/edit, /members/{id} -> POST
-
회원 삭제 /members/{id}/delete -> POST
-
HTML FORM은 GET,POST만 지원
-
컨트롤 URI
- GET, POST만 지원하므로 제약이 있음
- 이런 제약을 해결하기 위해 동사로 된 리소스 경로 사용
- POST의 /new, /edit, /delete가 컨트롤 URI
- HTTP 메서드로 해결하기 애매한 경우 사용(HTTP API 포함)
정리
참고하면 좋은 URI 설계 개념
- 문서 (document)
- 단일 개념(파일 하나, 객체 인스턴스, 데이터베이스 row)
- 예) /members/100, /files/star.jpg
- 컬렉션 (collection)
- 서버가 관리하는 리소스 디렉토리
- 서버가 리소스의 URI를 생성하고 관리
- 예) /members
- 스토어 (store)
- 클라이언트가 관리하는 자원 저장소
- 클라이언트가 리소스의 URI를 알고 관리
- 예) /files
- 컨트롤러 (controller), 컨트롤 URI
- 문서, 컬렉션, 스토어로 해결하기 어려운 추가 프로세스 실행
- 동사를 직접 사용
- 예) /members/{id}/delete
HTTP 상태코드
HTTP 상태코드 소개
상태 코드
클라이언트가 보낸 요청의 처리 상태를 응답에서 알려주는 기능
- 1xx (Information): 요청이 수신되어 처리중
- 2xx (Successful): 요청 정상 처리
- 3xx (Redirection): 요청을 완료하려면 추가 행동이 필요
- 4xx (Client Error): 클라이언트 오류, 잘못된 문법등으로 서버가 요청을 수행할 수 없음
- 5xx (Server Error): 서버 오류, 서버가 정상 요청을 처리하지 못함
만약 모르는 상태 코드가 나타나면?
- 클라이언트가 인식할 수 없는 상태코드를 서버가 반환하면?
- 클라이언트는 상위 상태코드로 해석해서 처리
- 미래에 새로운 상태 코드가 추가되어도 클라이언트를 변경하지 않아도 됨
- 예)
- 299 ??? -> 2xx (Successful)
- 451 ??? -> 4xx (Client Error)
- 599 ??? -> 5xx (Server Error)
1xx (Informational)
요청이 수신되어 처리중
- 거의 사용하지 않으므로 생략
2xx - 성공
2xx (Successful)
클라이언트의 요청을 성공적으로 처리
- 200 OK :
요청 성공 ex) GET - 201 Created :
요청 성공해서 새로운 리소스가 생성됨
ex) POST, 생성된 리소스는 응답의 Location 헤더 필드로 식별 Location: /members/100 - 202 Accepted
- 배치 처리 같은 곳에서 사용
- 예) 요청 접수 후 1시간 뒤에 배치 프로세스가 요청을 처리함
요청이 접수되었으나 처리가 완료되지 않았음
- 204 No Content
- 예) 웹 문서 편집기에서 save 버튼- save 버튼의 결과로 아무 내용이 없어도 된다.
- save 버튼을 눌러도 같은 화면을 유지해야 한다.
- 결과 내용이 없어도 204 메시지(2xx)만으로 성공을 인식할 수 있다.
3xx - 리다이렉션1
3xx (Redirection)
요청을 완료하기 위해 유저 에이전트의 추가 조치 필요
- 300 Multiple choices
- 301 Moved Permanently
- 302 Found
- 303 See Other
- 304 Not Modified
- 307 Temporary Redirect
- 308 Permanent Redirect
리다이렉션 이해
- 웹 브라우저는 3xx 응답의 결과에 Location 헤더가 있으면, Location 위치로 자동 이동(리다이렉트)
자동 리다이렉트 흐름
1. 요청 Client -> Server
GET /event HTTP/1.1
Host: localhost:8080- 응답 Server -> Client
HTTP/1.1 301 Moved Permanently
Location: /new-event- 자동 리다이렉트 Client -> Client
- 요청 Client -> Server
GET /new-event HTTP/1.1
Host: localhost:8080- 응답 Server -> Client
HTTP/1.1 200 OK종류
- 영구 리다이렉션 - 특정 리소스의 URI가 영구적으로 이동
- 예) /members -> /users
- 예) /event -> /new-event
- 일시 리다이렉션 - 일시적인 변경
- 주문 완료 후 주문 내역 화면으로 이동
- PRG: Post/Redirect/Get
- 특수 리다이렉션
- 결과 대신 캐시를 사용
영구 리다이렉션
301, 308
- 리소스의 URI가 영구적으로 이동
- 원래의 URL을 사용X, 검색 엔진 등에서도 변경 인지
- 301 Moved Permanently
- 리다이렉트시 요청 메서드가 GET으로 변하고, 본문이 제거될 수 있음(MAY)
- 308 Permanent Redirect
- 301과 기능은 같음
- 리다이렉트시 요청 메서드와 본문 유지(처음 POST를 보내면 리다이렉트 유지)
영구 리다이렉션 - 301
1. 요청 Client -> Server, POST 사용, 메시지 존재
POST /event HTTP/1.1
Host: localhost:8080
name=hello&ange=20- 응답 Server -> Client
HTTP/1.1 301 Moved Permanently
Location: /new-event- 자동 리다이렉트 Client -> Client
- 요청 Client -> Server, GET으로 변경, 메시지 제거
GET /new-event HTTP/1.1
Host: localhost:8080- 응답 Server -> Client
HTTP/1.1 200 OK영구 리다이렉션 - 308
1. 요청 Client -> Server, POST 사용, 메시지 존재
POST /event HTTP/1.1
Host: localhost:8080
name=hello&ange=20- 응답 Server -> Client
HTTP/1.1 308 Permanent Redirect
Location: /new-event- 자동 리다이렉트 Client -> Client
- 요청 Client -> Server, GET으로 변경, 메시지 제거
POST /new-event HTTP/1.1
Host: localhost:8080
name=hello&age=20- 응답 Server -> Client
HTTP/1.1 200 OK3xx - 리다이렉션2
일시적인 리다이렉션
302, 307, 303
- 리소스의 URI가 일시적으로 변경
- 따라서 검색 엔진 등에서 URL을 변경하면 안됨
- 302 Found
- 리다이렉트시 요청 메서드가 GET으로 변하고, 본문이 제거될 수 있음(MAY)
- 307 Temporary Redirect
- 302와 기능은 같음
- 리다이렉트시 요청 메서드와 본문 유지(요청 메서드를 변경하면 안된다. MUST NOT)
- 303 See Other
- 302와 기능은 같음
- 리다이렉트시 요청 메서드가 GET으로 변경
PRG: Post/Redirect/Get
일시적인 리다이렉션 -예시
- POST로 주문후에 웹 브라우저를 새로고침하면?
- 새로고침은 다시 요청
- 중복 주문이 될 수 있다.
PRG 사용전
1. 요청
POST /order HTTP/1.1
Host: localhost:8080
itemId=mouse&count=1- 주문데이터 저장
mouse 1 개 - 응답
HTTP/1.1 200 OK
<html>주문완료</html>- 결과 화면에서 새로고침
- 요청
POST /order HTTP/1.1
Host: localhost:8080
itemId=mouse&count=1- 주문 데이터 저장
mouse 1개 - 응답
HTTP/1.1 200 OK
<html>주문완료</html>일시적인 리다이렉션 -예시
- POST로 주문후에 새로 고침으로 인한 중복 주문 방지
- POST로 주문후에 주문 결과 화면을 GET 메서드로 리다이렉트
- 새로고침해도 결과 화면을 GET으로 조회
- 중복 주문 대신에 결과 화면만 GET으로 다시 요청
- 요청
POST /order HTTP/1.1
Host: localhost:8080
itemId=mouse&count=1- 주문데이터 저장
mouse 1 개 - 응답
HTTP/1.1 302 Found
Location: /order-result/19- 결과 화면에서 새로고침
- 요청
GET /order-result/19 HTTP/1.1
Host: localhost:8080- 주문데이터 조회 19번 주문
- 응답
HTTP/1.1 200 OK
<html>주문완료</html>- 결과 화면에서 새로고침
GET /order-result/19
결과 화면만 다시 요청(5번으로 이동)
- PRG 이후 리다이렉트
- URL이 이미 POST -> GET으로 리다이렉트 됨
- 새로 고침 해도 GET으로 결과 화면만 조회
그래서 뭘 써야 하나요?
302, 307, 303
- 잠깐 정리
- 302 Found -> GET으로 변할 수 있음
- 307 Temporary Redirect -> 메서드가 변하면 안됨
- 303 See Other -> 메서드가 GET으로 변경
- 역사
- 처음 302 스펙의 의도는 HTTP 메서드를 유지하는 것
- 그런데 웹 브라우저들이 대부분 GET으로 바꾸어 버림(일부는 다르게 동작)
- 그래서 모호한 302를 대신하는 명확한 307, 303이 등장함(301 대용으로 308도 등장)
- 현실
- 307, 303을 권장하지만 현실적으로 이미 많은 애플리케이션 라이브러리들이 302를 기본값으로 사용
- 자동 리다이렉션시에 GET으로 변해도 되면 그냥 302를 사용해도 큰 문제는 없음
기타 리다이렉션
- 300 Multiple Choices: 안쓴다
- 304 Not Modified
- 캐시를 목적으로 사용
- 클라이언트에게 리소스가 수정되지 않았음을 알려준다. 따라서 클라이언트는 로컬PC에 저장된 캐시르 재사용한다. (캐시로 리다이렉트 한다.)
- 304 응답은 응답에 메시지 바디를 포함하면 안된다. (로컬 캐시를 사용해야 하므로)
- 조건부 GET, HEAD 요청시 사용
4xx - 클라이언트 오류, 5xx - 서버오류
클라이언트 오류
**4xx (Clinet Error)
- 클라이언트의 요청에 잘못된 문법등으로 서버가 요청을 수행할 수 없음
- 오류의 원인이 클라이언트에 있음
- 중요 클라이언트가 이미 잘못된 요청, 데이터를 보내고 있기 때문에, 똑같ㅇ츤 재시도가 실패함
400 Bad Request
클라이언트가 잘못된 요청을 해서 서버가 요청을 처리할 수 없음
- 요청 구문, 메시지 등등 오류
- 클라이언트는 요청 내용을 다시 검토하고 보내야함
- 예) 요청 파라미터가 잘못되거나, API 스펙이 맞지 않을 때
401 Unauthorized
클라이언트가 해당 리소스에 대한 인증이 필요함
- 인증(Authentication) 되지 않음
- 401 오류 발생시 응답에 WWW-Authenticate 헤더와 함께 인증 방법을 설명
- 참고
- 인증(Authentication): 본인이 누구인지 확인, (로그인)
- 인가(Authorization) : 권한부여 (ADMIN 권한처럼 특정 리소스에 접근할 수 있는 권한, 인증이 있어야 인가가 있음)
- 오류 메시지가 Unauthorized 이지만 인증되지 않음 (이름이 아쉬움)
403 Forbidden
서버가 요청을 이해했지만 승인을 거부함
- 주로 인증 자격 증명은 있지만, 접근 권한이 불충분한 경우
- 예) 어드민 등급이 아닌 사용자가 로그인은 했지만, 어드민 등급의 리소스에 접근하는 경우
404 Not Found
요청 리소스를 찾을 수 없음
- 요청 리소스가 서버에 없음
- 또는 클라이언트가 권한이 부족한 리소스에 접근할 때 해당 리소스를 숨기고 싶을 때
5xx (Server Error)
서버오류
- 서버 문제로 오류 발생
- 서버에 문제가 있기 때문에 재시도하면 성공할 수도 있음 (복구가 되거나 등등)
500 Internal Server Error
서버 문제로 오류 발생, 애매하면 500 오류
- 서버 내부 문제로 오류 발생
- 애매하면 500 오류
503 Service Unavailable
서비스 이용 불가
- 서버가 일시적인 과부하 또는 예정된 작업으로 잠시 요청을 처리할 수 없음
- Retry-After 헤더 필드로 얼마뒤에 복구되는지 보낼 수도 있음
웬만하면 500대 오류가 발생하면 안된다. 진짜 서버에 문제가 있을때 (nullpointerexception, db 내려가거나..)
HTTP 헤더1 - 일반 헤더
HTTP 헤더 개요
HTTP 헤더
- header-field = field-name ":" OWS field-value OWS (OWS: 띄어쓰기 허용)
- field-name은 대소문자 구분 없음
GET /search?q=hello&hl=ko HTTP/1.1
Host: www.google.comHTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Content-Length: 3423
<html>
<body>...</body>
</html>HTTP 헤더
용도
- HTTP 전송에 필요한 모든 부가정보
- 예) 메시지 바디의 내용, 메시지 바디의 크기, 압축, 인증, 요청 클라이언트, 서버 정보, 캐시 관리 정보...
- 표준 헤더가 너무 많음
- 필요시 임의의 헤더 추가 가능
- helloworld: hihi
HTTP 헤더
분류 - RFC2616(과거)
- 헤더 분류
- General 헤더: 메시지 전체에 적용되는 정보, 예) Connection: close
- Request 헤더: 요청 정보, 예) User-Agent: Mozilla/5.0 (Macintosh; ..)
- Response 헤더: 응답 정보, 예) Server: Apache
- Entity 헤더: 엔티티 바디 정보, 예) Content-Type: text/html, Content-Length: 3423
HTTP BODY
message body - RFC2616(과거)
- 메시지 본문(message body)은 엔티티 본문(entity body)을 전달하는데 사용
- 엔티티 본문은 요청이나 응답에서 전달할 실제 데이터
- 엔티티 헤더는 엔티티 본문의 데이터를 해석할 수 있는 정보 제공
- 데이터 유형(html, json), 데이터, 길이 압축 정보 등등
HTTP 표준
1999년 FRC2616 -> 폐기됨
2014년 RFC7230~7235 등장
RFC723x 변화
- 엔티티(Entity) -> 표현(Representation)
- Representation = representation Metadata + Representation Data
- 표현 = 표현 메타데이터 + 표현 데이터
HTTP BODY
message body - RFC7230
- 메시지 본문(message body)을 통해 표현 데이터 전달
- 페이지 본문 = 페이로드(payload)
- 표현은 요청이나 응답에서 전달할 실제 데이터
- 표현 헤더는 표현 데이터를 해석할 수 있는 정보 제공
- 데이터 유형(html, json), 데이터 길이, 압축 정보 등등
- 참고: 표현 헤더는 표현 메타데이터와 페이로드 메시지를 구분해야 하지만, 여기서는 표현헤더라고 말함
표현
- Content-Type: 표현 데이터의 형식
- Content-Encoding: 표현 데이터의 압축 방식
- Content-Language: 표현 데이터의 자연 언어
- Content-Length: 표현 데이터의 길이
- 표현 헤더는 전송, 응답 둘다 사용
Content-Type
표현 데이터의 형식 설명
- 미디어 타입, 문자 인코딩
- 예)
- text/html; charset=utf-8
- application/json
- image/png
Content-Encoding
표현 데이터 인코딩
- 표현 데이터를 압축하기 위해 사용
- 데이터를 전달하는 곳에서 압축 후 인코딩 헤더 추가
- 데이터를 읽는 쪽에서 인코딩 헤더의 정보로 압축 해제
- 예)
- gzip (압축)
- deflate
- identity (원본)
Content-Language
표현 데이터의 자연 언어
- 표현 데이터의 자연 언어를 표현
- 예)
- ko
- en
- en-US
Content-Length
표현 데이터의 길이
- 바이트 단위
- Transfer-Encoding(전송 코딩)을 사용하면 Content-Length를 사용하면 안됨
협상(콘텐츠 네고시에이션)
클라이언트가 선호하는 표현 요청
- Accept: 클라이언트가 선호하는 미디어 타입 전달
- Accept-Charset: 클라이언트가 선호하는 문자 인코딩
- Accept-Encoding: 클라이언트가 선호하는 압축 인코딩
- ACcept-Language: 클라이언트가 선호하는 자연 언어
- 협상 헤더는 요청시에만 사용
한국어 브라우저를 사용하는 클라이언트가 다중 언어 지원하는 서버(1. 기본 영어, 2. 한국어 지원)에 요청을 할때 Accept-Language를 적용하지 않으면 기본 영어로 응답 받지만, 적용하면 한국어로 응답 받는다. 하지만 한국어 지원을 안할 경우에 우선순위를 지정할 수 있다.
**협상과 우선순위1
Quality Values(q)
GET /event
ACcept-language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7- Quality Values(q) 값 사용
- 0~1, 클수록 높은 우선순위
- 생략하면 1
- Accept-Language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7
- ko-KR;q=1 (q=1이면 생략)
- ko;q=0.9
- en-US;q=0.8
- en;q=0.7
**협상과 우선순위2
Quality Values(q)
GET /event
Accept: text/*, text/plain, text/plain;format=flowed, */*- 구체적인 것이 우선한다.
- Accept: text/, text/plain, text/plain;format=flowed, /*
- text/plain;format=flowed
- text/plain
- text/*
- /
**협상과 우선순위3
Quality Values(q)
- 구체적인 것을 기준으로 미디어 타입을 맞춘다.
- Accept: text/;q=0.3, text/html;q=0.7, text/html;level=1, text/html;level=2;q=0.4, /*;q=0.5
전송 방식
- Transfer-Encoding
- Range, Content-Range
전송 방식 설명
- 단순 전송 : Content-Length
HTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Content-Length: 3423- 압축 전송 : Content-Encoding
HTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Content-Encoding: gzip
Content-Length: 3423- 분할 전송 : Transfer-Encoding
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
5
hEllo
5
World
0
\r\n- 범위 전송 : Range, Content-Range
GET /event
Range: bytes=1001-2000HTTP/1.1 200 OK
Content-Type: text/plain
Content-Range: bytes 1001-2000 / 2000
afdadfdsfass일반 정보
- From: 유저 에이전트의 이메일 정보
- Referer: 이전 웹 페이지 주소
- User-Agent: 유저 에이전트 애플리케이션 정보
- Server: 요청을 처리하는 오리진 서버의 소프트웨어 정보
- DatE: 메시지가 생성된 날짜
From
유저 에이전트의 이메일 정보
-
일반적으로 잘 사용되지 않음
-
검색 엔진 같은 곳에서, 주로 사용
-
요청에서 사용
Referer
이전 웹 페이지 주소 -
현재 요청된 페이지의 이전 웹 페이지 주소
-
A->B로 이동하는 경우 B를 요청할 때 Referer: A를 포함해서 요청
-
Referer를 사용해서 유입 경로 분석 가능
-
요청에서 사용
-
참고: referer는 단어 referrer의 오타
User-Agent
유저 에이전트 애플리케이션 정보 -
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36(KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36
-
클라이언트의 애플리케이션 정보(웹 브라우저 정보, 등등)
-
통계 정보
-
어떤 종류의 브라우저에서 장애가 발생하는지 파악 가능
-
요청에서 사용
Server
요청을 처리하는 ORIGIN 서버의 소프트웨어 정보 -
Server: Apache/2.2.22 (Debian)
-
server: nginx
-
응답에서 사용
Date
메시지가 발생한 날짜와 시간 -
Date: Tue, 15 Nov 1994 08:12:31 GMT
-
응답에서 사용
특별한 정보
-
Host: 요청한 호스트 정보(도메인)
-
Location: 페이지 리다이렉션
-
Allow: 허용 가능한 HTTP 메서드
-
Retry-After: 유저 에이전트가 다음 요청을 하기까지 기다려야 하는 시간
Host
요청한 호스트 정보(도메인) -
요청에서 사용
-
필수
-
하나의 서버가 여러 도메인을 처리해야 할 때
-
하나의 IP 주소에 여러 도메인이 적용되어 있을 때
가상 호스트를 통해 여러 도메인을 한번에 처리할 수 있는 서버, 실제 애플리케이션이 여러개 구동될 수 있다.
GET /hello HTTP/1.1
Host: aaa.comLocation
페이지 리다이렉션
- 웹 브라우저는 3xx 응답의 결과에 Location 헤더가 있으면, Location위치로 자동 이동(리다이렉트)
- 응답코드 3xx에서 설명
- 201 (Created): Location 값은 요청에 의해 생성된 리소스 URI
- 3xx (Redirection): Location 값은 요청을 자동으로 리다이렉션하기 위한 대상 리소스를 가리킴
Allow
허용 가능한 HTTP 메서드
- 405(Method Not Allowed) 에서 응답에 포함해야함
- Allow: GET, HEAD, PUT
Retry-After
유저 에이전트가 다음 요청을 하기까지 기다려야 하는 시간
- 503 (Service Unavailable): 서비스가 언제까지 불능인지 알려줄 수 있음
- Retry-After: Fri, 31 Dec 1999 23:59:59 GMT (날짜 표기)
- Retry-After: 120 (초 단위 표기)
인증
- Authorization: 클라이언트 인증 정보를 서버에 전달
- WWW-Authenticate: 리소스 접근시 필요한 인증 방법 정의
인증
Authorization (인가, 권한부여)
클라이언트 인증 정보를 서버에 전달
- Authorization: Basic xxxxxxxxxxxxxx
WWW-Authenticate (인증)
리소스 접근시 필요한 인증 방법 정의
- 리소스 접근시 필요한 인증 방법 정의
- 401 Unauthorized 응답과 함께 사용
- WWW-Authenticate: Newauth realm= "apps", type=1, title="Login to \"apps\
"", Basic realm="simple"
쿠키
- Set-Cookie: 서버에서 클라이언트로 쿠키 전달(응답)
- Cookie: 클라이언트가 서버에서 받은 쿠키를 저장하고, HTTP 요청시 서버로 전달
Stateless
- HTTP는 무상태(Stateless) 프로토콜이다.
- 클라이언트와 서버가 요청과 응답을 주고 받으면 연결이 끊어진다.
- 클라이언트가 다시 요청하면 서버는 이전 요청을 기억하지 못한다.
- 클라이언트와 서버는 서로 상태를 유지하지 않는다.
쿠키를 사용하지 않으면 서버는 클라이언트가 누군지 모른다.
모든 요청에 사용자정보를 포함해도 되지만, 번거롭고 데이터 양이 많아진다.
쿠키
로그인
1.
POST /login HTTP/1.1
user=홍길동HTTP/1.1 200 OK
Set-Cookie: user=홍길동
홍길동님이 로그인했습니다.- 쿠키 저장소에 저장
- 로그인 이후 welcome 페이지 접근
GET /welcome HTTP/1.1
Cookie: user=홍길동HTTP/1.1 200 OK
안녕하세요. 홍길동님쿠키
- 예) set-cookie: sessionId=abcde1234; expires=Sat, 26-Dec-2020 00:00:00 GMT; path=/; domain= google.com; Secure
- 사용처
- 사용자 로그인 세션 관리
- 광고 정보 트래킹
- 쿠키 정보는 항상 서버에 전송됨
- 네트워크 트래픽 추가 유발
- 최소한의 정보만 사용(세션 id, 인증 토큰)
- 서버에 전송하지 않고, 웹 브라우저 내부에 데이터를 저장하고 싶으면 웹 스토리지(localStorage, sessionStorage) 참고
- 주의!
- 보안에 민감한 데이터는 저장하면 안됨(주민번호, 신용카드 번호 등등)
쿠키 - 생명주기
Expires, max-age
- Set-Cookie: expires=Sat, 26-Dec-2020 04:39:21 GMT
- 만료일이 되면 쿠키 삭제
- Set-Cookie: max-age=3600 (3600초)
- 0이나 음수를 지정하면 쿠키 삭제
- 세션 쿠키: 만료 날짜를 생략하면 브라우저 종료시 까지만 유지
- 영속 쿠키: 만료 날짜를 입력하면 해당 날짜까지 유지
쿠키 - 도메인
Domain
- 예) domain=example.org
- 명시: 명시한 문서 기준 도메인 + 서브 도메인 포함
- domain=example.org를 지정해서 쿠키 생성
- example.org는 물론이고
- dev.example.org도 쿠키 접근
- domain=example.org를 지정해서 쿠키 생성
- 생략: 현재 문서 기준 도메인만 적용
- example.org 에서 쿠키를 생성하고 domain 지정을 생략
- example.org에서만 쿠키 접근
- dev.example.org는 쿠키 미접근
쿠키 - 경로
Path
- example.org 에서 쿠키를 생성하고 domain 지정을 생략
- 예) path=/home
- 이 경로를 포함한 하위 경로 페이지만 쿠키 접근
- 일반적으로 path=/ 루트로 지정
- 예)
- path=/home 지정
- /home -> 가능
- /home/level1 -> 가능
- /home/level1/level2 -> 가능
- /hello -> 불가능
쿠키 - 보안
Secure, HttpOnly, SameSite
- Secure
- 쿠키는 http, https를 구분하지 않고 전송
- Secure를 적용하면 https인 경우에만 전송
- HttpOnly
- XSS 공격 방지
- 자바스크립트에서 접근 불가 (document.cookie)
- HTTP 전송에만 사용
- SameSite
- XSRF 공격 방지
- 요청 도메인과 쿠키에 설정된 도메인이 같은 경우만 쿠키 전송
HTTP 헤더2 - 캐시와 조건부 요청
캐시 기본 동작
캐시가 없을 때
- 데이터가 변경되지 않아도 계쏙 네트워크를 통해서 데이터를 다운로드 받아야 한다.
- 인터넷 네트워크는 매우 느리고 비싸다
- 브라우저 로딩 속도가 느리다.
- 느린 사용자 경험
캐시 적용
첫 번째 요청
HTTP/1.1 200 OK
Content-Type: image/jpeg
cache-control: max-age=60
Content-Length: 34012
dafdsfasfsad캐시 적용
- 캐시 덕분에 캐시 가능 시간동안 네트워크를 사용하지 않아도 된다.
- 비싼 네트워크 사용량을 줄일 수 있다.
- 브라우저 로딩 속도가 매우 빠르다.
- 빠른 사용자 경험
캐시 적용
세 번재 요청 - 캐시 시간 초과
요청할때 브라우저캐시에서 캐시 유효 시간을 검증한다.
시간이 지나있으면 첫번째요청처럼 다시받아서 캐시에 저장한다.
- 캐시 유효시간이 초과하면, 서버를 통해 데이터를 다시 조회하고, 캐시를 갱신한다.
- 이 때 다시 네트워크 다운로드가 발생한다.
검증 헤더와 조건부 요청1
- 캐시 유효 시간이 초과해서 서버에 다시 요청하면 다음 두가지 상황이 나타난다.
1. 서버에서 기존 데이터를 변경함
2. 서버에서 기존 데이터를 변경하지 않음 - 캐시 만료후에도 서버에서 데이터를 변경하지 않음
- 생각해보면 데이터를 전송하는 대신에 저장해 두었던 캐시를 재사용 할 수 있다.
- 단 클라이언트의 데이터와 서버의 데이터가 같다는 사실을 확인할 수 있는 방법 필요
검증 헤더 추가
첫번째 요청
HTTP/1.1 200 OK
Content-Type: image/jpeg
cache-control: max-age=60
Last-Modified: 2020년 11월 10일 10:00:00 // 데이터가 마지막에 수정된 시간
Content-Length: 34012
adfas데이터 최종 수정일 2020년 11월 10일 10:00:00
응답 결과를 캐시에 저장
두번째 요청 - 캐시 시간 초과
GET /star.jpg
if-modified-since: 2020년 11월 10일 10:00:00서버와 캐시의 데이터 최종 수정일이 같다. = 데이터가 아직 수정되지 않았다.
HTTP/1.1 304 Not Modified
Content-Type: image/jpeg
cache-control: max-age=60
Last-Modified: 2020년 11월 10일 10:00:00
Content-Length: 34012HTTP Body가 없음
헤더만 전송
-> 응답 결과를 재사용, 헤더 데이터 갱신
검증 헤더와 조건부 요청
정리
- 캐시 유효 시간이 초과해도, 서버의 데이터가 갱신되지 않으면 304 Not Modified + 헤더 메타 정보만 응답(바디X)
- 클라이언트는 서버가 보낸 응답 헤더 정보로 캐시의 메타 정보를 갱신
- 클라이언트는 캐시에 저장되어 있는 데이터 재활용
- 결과적으로 네트워크 다운로드가 발생하지만 용량이 적은 헤더 정보만 다운로드
- 매우 실용적인 해결책
검증 헤더와 조건부 요청2
- 검증 헤더
- 캐시 데이터와 서버 데이터가 같은지 검증하는 데이터
- Last-Modified, ETag
- 조건부 요청 헤더
- 검증 헤더로 조건에 따른 분기
- If-Modified-Since: Last-Modified 사용
- If-None-Math: ETag 사용
- 조건이 만족하면 200 OK
- 조건이 만족하지 않으면 304 Not Modified
예시
- If-Modified-Since: 이후에 데이터가 수정되었으면?
- 데이터 미변경 예시
- 캐시: 2020년 11월 10일 10:00:00 vs 서버: 2020년 11월 10일 10:00:00
- 304 Not Modified, 헤더 데이터만 전송(Body 미포함)
- 전송 용량 0.1M (헤더 0.1M, 바디 1.0M)
- 데이터 변경 예시
- 캐시: 2020년 11월 10일 10:00:00 vs 서버: 2020년 11월 10일 11:00:00
- 200 OK, 모든 데이터 전송(Body 포함)
- 전송 용량 1.1M (헤더 0.1M, 바디 1.0M)
검증 헤더와 조건부 요청
Last-Modified, If-Modified-Since 단점
- 데이터 미변경 예시
- 1초 미만(0.x초) 단위로 캐시 조정이 불가능
- 날짜 기반의 로직 사용
- 데이터를 수정해서 날짜가 다르지만, 같은 데이터를 수정해서 데이터 결과가 똑같은 경우
- 서버에서 별도의 캐시 로직을 관리하고 싶은 경우
- 예) 스페이스나 주석처럼 크게 영향이 없는 변경에서 캐시를 유지하고 싶은 경우
ETag, If-None-Match
- ETag(Entity Tag)
- 캐시용 데이터에 임의의 고유한 버전 이름을 달아둠
- 예) ETag: "v1.0", ETag: "aafadsfasd"
- 데이터가 변경되면 이 이름을 바꾸어서 변경함(Hash를 다시 생성)
- 예) ETag: "aaaaa" -> ETag: "bbbbb"
- 진짜 단순하게 ETag만 보내서 같으면 유지, 다르면 다시 받기!
첫번째 요청
HTTP/1.1 200 OK
Content-Type: image/jpeg
cache-control: max-age=60
ETag: "aaaaa"
Content-Length: 34012
adfas두번째 요청 - 캐시 시간 초과
GET /star.jpg
If-None-Match: "aaaaa"HTTP/1.1 304 Not Modified
Content-Type: image/jpeg
cache-control: max-age=60
ETag: "aaaaa"
Content-Length: 34012HTTP body가 없음
ETag가 같으면 데이터가 수정되지 않았기 때문
ETag, If-None-Match 정리
- 진짜 단순하게 ETag만 서버에 보내서 같으면 유지, 다르면 다시 받기!
- 캐시 제어 로직을 서버에서 완전히 관리
- 클라이언트는 단순히 이 값을 서벙 ㅔ제공( 클라이언트는 캐시 매커니즘을 모름)
- 예)
- 서버는 베타 오픈 기간인 3일 동안 파일이 변경되어도 ETag를 동일하게 유지
- 애플리케이션 배포 주기에 맞추어 ETag 모두 갱신
캐시와 조건부 요청 헤더
- Cache-Control: 캐시 제어
- Pragma: 캐시 제어(하위 호환)
- Expires: 캐시 유효 기간(하위 호환)
Cache-Control
캐시 지시어(directives)
- Cache-Control: max-age
- 캐시 유효 시간, 초 단위
- Cache-Control: no-cache
- 데이터는 캐시해도 되지만, 항상 원(origin) 서버에 검증하고 사용
- Cache-Control: no-store
- 데이터에 민감한 정보가 있으므로 저장하면 안됨
(메모리에서 사용하고 최대한 빨리 삭제)
- 데이터에 민감한 정보가 있으므로 저장하면 안됨
Pragma
캐시 제어(하위호환)
- Pragma: no-cache
- HTTP 1.0 하위 호환
**Expires
캐시 만료일 지정(하위 호환)
- expires: Mon, 01 Jan 1990 00:00:00 GMT
- 캐시 만료일을 정확한 날짜로 지정
- HTTP 1.0 부터 사용
- 지금은 더 유연한 Cache-Control: max-age 권장
- Cache-Control: max-age와 함께 사용하면 Expires는 무시
검증 헤더와 조건부 요청 헤더
- 검증 헤더(Validator)
- ETag: "v1.0", ETag: "dafsdfsad"
- Last-Modified: Thu, 04 Jun 2020 07:19:24 GMT
- 조건부 요청 헤더
- If-Match, If-None-Match: ETag 값 사용
- If-Modified-Since, If-Unmodified-Since: Last-Modified 값 사용
프록시 캐시
**Cache-Control
캐시 지시어(directives) - 기타
- Cache-Control: public
- 응답이 public 캐시에 저장되어도 됨
- Cache-Control: private
- 응답이 해당 사용자만을 위한 것임, private 캐시에 저장해야 함(기본값)
- Cache-Control: s-maxage
- 프록시 캐시에만 적용되는 max-age
- Age: 60 (HTTP 헤더)
- 오리진 서버에서 응답 후 프록시 캐시 내에 머문 시간(초)
캐시 무효화
Cache-Control
확실한 캐시 무효화 응답
- Cache-Control: no-cache, no-store, must-revalidate
- Pragma: no-cache
- HTTP 1.0 하위 호환
**캐시 지시어(directives) - 확실한 캐시 무효화
- Cache-Control: no-cache
- 데이터는 캐시해도 되지만, 항상 원 서버에 검증하고 사용(이름에 주의!)
- Cache-Control: no-store
- 데이터에 민감한 정보가 있으므로 저장하면 안됨
(메모리에서 사용하고 최대한 빨리 삭제)
- 데이터에 민감한 정보가 있으므로 저장하면 안됨
- Cache-Control: must-revalidate
- 캐시 만료후 최초 조회시 원 서버에 검증해야함
- 원 서버 접근 실패시 반드시 오류가 발생해야함 - 504(Gateway Timeout)
- must-revalidate는 캐시 유효 시간이라면 캐시를 사용함
- Pragma: no-cache
- HTTP 1.0 하위 호환
no-cache에서 원서버에 접근할 수 없는 경우 캐시 서버 설정에 따라서 프록시에서 캐시 데이터를 반환할 수 있음 Error or 200 OK (오류 보다는 오래된 데이터라도 보여주자)
must-revalidate의 경우에 원 서버에 접근할 수 없는 경우 항상 오류가 발생해야 한다 504Gateway Timeout(매우 중요한 돈과 관련된 결과로 생각해보자)
