들어가며
물리적 메모리로의 주소 변환은 OS가 관여하지 않지만, 가상 메모리 기법은 전적으로 OS가 관여한다
Demand Paging
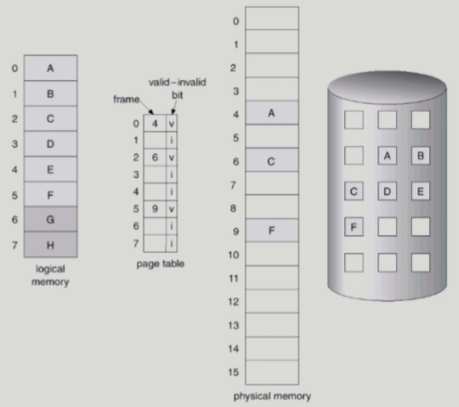
- 실제로 필요할 때(= 해당 페이지가 요청됐을 때) page를 메모리에 올리는 것
- I/O 양 감소
- memory 사용량 감소
- 빠른 응답 시간
- 더 많은 사용자를 수용
- valid/invalid bit 사용
Invalid의 경우- 사용되지 않는 주소 영역인 경우
- 페이지가 물리적 메모리에 없는 경우(= backing storage에 있음)
- 처음에는 모든 page entry가 invalid로 초기화되어 있음
- 주소 변환시에 invalid bit이 set되어있는 현상을
page fault(trap)라고 함 => backing storage에서 가져와야 함
Page Fault
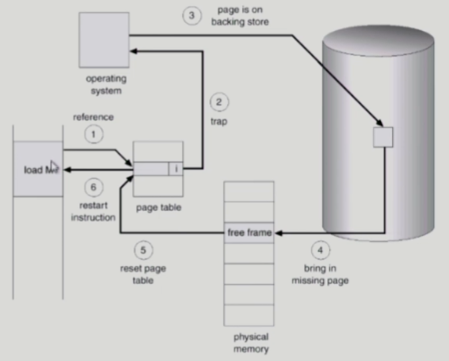
- invalid page에 접근하면 MMU가 trap을 발생시킨다(=page fault trap), CPU는 OS에게 넘어감
- kernel mode로 들어가서 page fault hanlder가 invoke됨
- 다음과 같은 순서로 page fault를 처리함
- 잘못된 요청인지 확인함 (e.g bad address, protection violation) => abort process 함
- get an empty page frame (없으면 뺏어온다:replace)
- 해당 page를 disk에서 memory로 읽어옴
- disk I/O가 끝나기까지 이 프로세스는 CPU를 preempt 당함 (block)
- disk read가 끝나면 page tables entry 기록, valid/invalid bit = "valid" (I/O끝나면 interrupt)
- ready queue에 process를 insert -> dispatch later
- 이 프로세스가 CPU를 잡고 다시 running
- 아까 중단됐던 instruction을 재개
free frame이 없는 경우?
페이지 교체
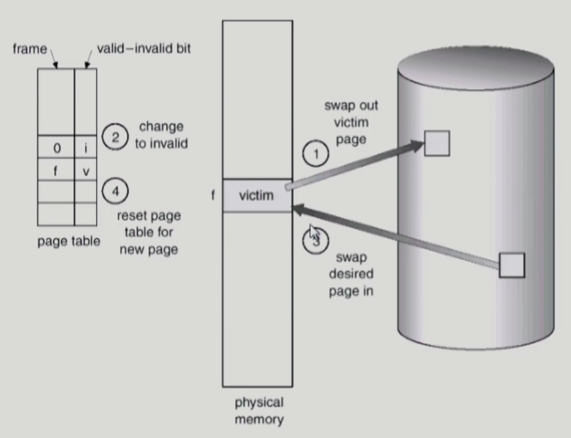
- 어떤 frame을 빼앗아올지 결정해야 함
- 곧바로 사용되지 않을 page를 쫓아내는 것이 좋음
- 동일한 페이지가 여러 번 메모리에서 쫓겨났다가 다시 들어올 수 있음
Replacement Algorithm
- page-fault rate을 최소화하는 것이 목표
- 알고리즘의 평가
- 주어진 page reference string에 대해서 page fault를 얼마나 내는지 조사
- reference string의 예
- 1,2,3,4,1,2,5,1,2,3,4,5
Optimal Algorithm
- 가장 이상적인 알고리즘, 미래의 참조 순서를 안다는 전제하에 전개됨
- 실제로는 사용할 수 없지만, 다른 알고리즘 성능에 대한 상한선을 제공함(MIN, OPT, Bealdy's optimal algorithm 등으로 불름)
FIFO(First In First Out)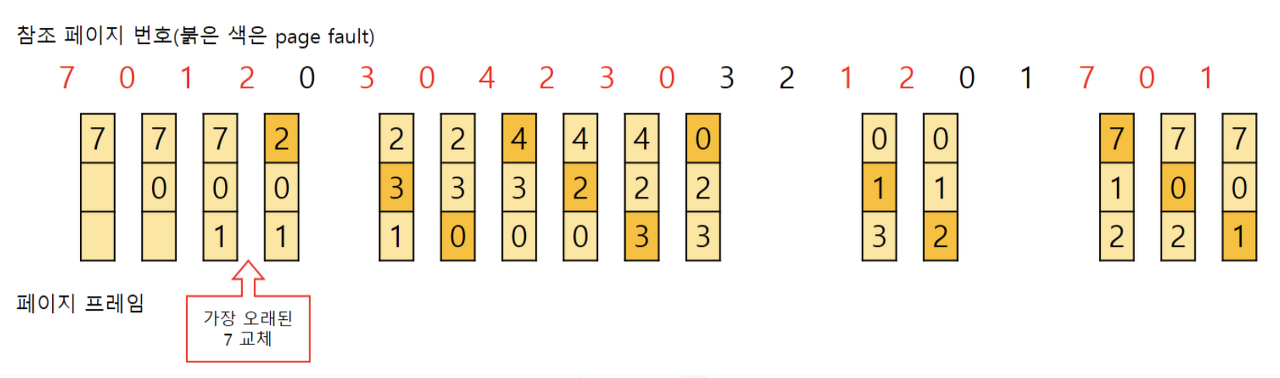
- 메모리 프레임이 늘어나면 오히려 성능이 악화되는 기이한 현상이 발생할 수도 있음
FIFO Anomaly,Belady's Anomaly라고 부름
- 가장 먼저 들어온 페이지를 페이지 폴트가 발생하면 교체한다.
- 동일한 페이지가 계속 참조되는게 아니라면 페이지 폴트가 지속적으로 발생한다.
LRU(Least Recently Used)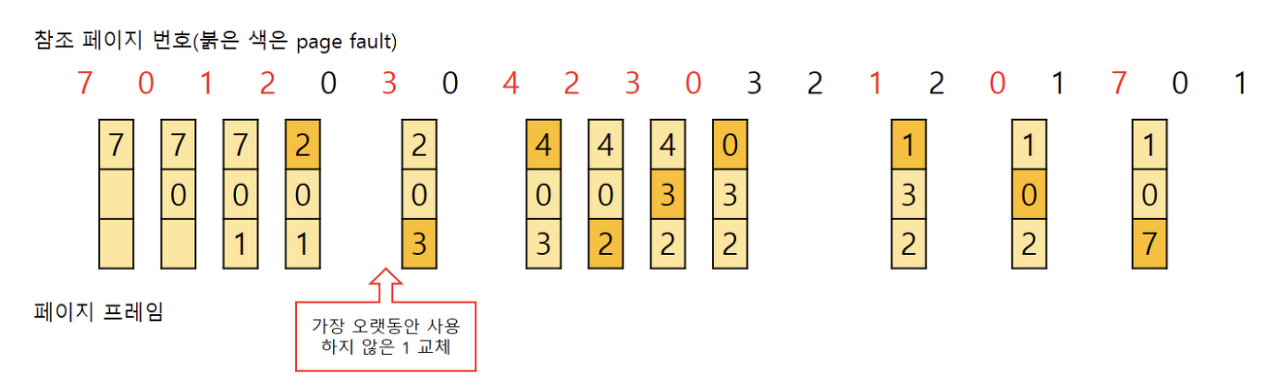
- 가장 오래전에 참조되었던 것을 지움
- 구현 방식
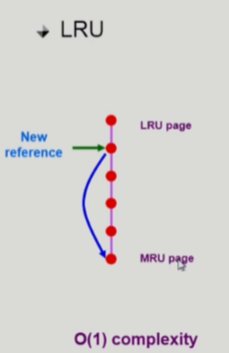
- 줄을 세워 놓고 LinkedList의 형태로 페이지 순서를 관리하게 됨
- 사용 시 다른 페이지간 비교는 필요없고 오래된 걸 빼고, 최근에 참조된 걸 맨 뒤로 줄 세우는 작업만 하기 때문에 O(1) 의 시간복잡도가 걸림
LFU(Least Frequently Used)
- 참조 횟수가 가장 적은 페이지를 지운다
- 최근에 교체된 페이지가 교체될 가능성이 높다.
- 페이지 참조에 대한 횟수를 기록하는 오버헤드가 발생한다.
- 최저 참조 횟수인 page가 여러개가 있는 경우 page 중 임의로 선정
- 성능 향상을 위해서 가장 오래전에 참조된 page를 지우게 구현할 수도 있음
- 장단점
- LRU처럼 직전 참조 시점만 보는것이 아니라 장기적 시간 규모를 보기 때문에 page의 인기도를 좀 더 정확히 반영할 수 있음
- 참조 시점의 최근성을 반영하지 못함
- LRU보다 구현이 복잡
- 구현 방식
- 리스트 방식

- 최악의 경우 다른 모든 페이지와의 비교가 필요하기 때문에 O(n)이 걸림
- 힙 방식
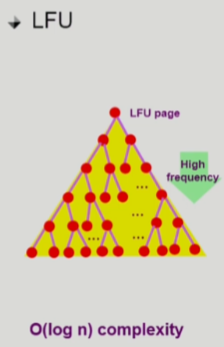
- 한 줄로 세운 방식보다 시간 복잡도가 줄어듦
- 리스트 방식
LRU, LFU는 Paging System에서 가능한가?
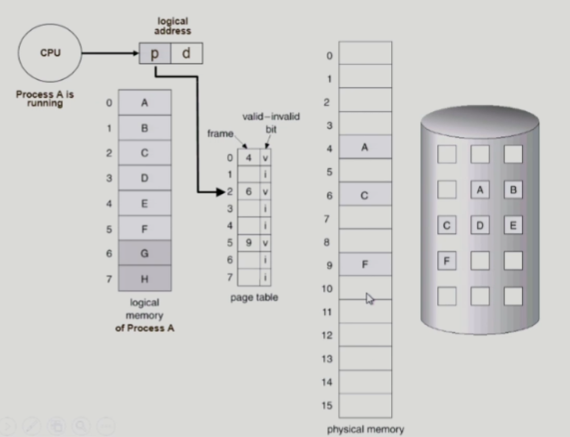
- CPU로 들어온 논리적 메모리 주소를 물리적 메모리로 변환하는건 HW가 전적으로 관여함
- OS가 관여하는 순간은
페이지 교체가 필요한 시점 뿐이고, 이런 이유로 OS는 페이지의 참조 횟수를 알 지 못함 - 페이지의 참조 시간이 들어오는 시점은 바로 이
페이지 교체가 일어난 페이지에 한정됨 => 이미 올라와 있는 페이지는 알 수가 없음,즉 메모리에 존재하지 않는 페이지에 대한 정보만을 포함하는 반쪽짜리 정보임 - 결과적으로 LRU와 LFU는 가상 메모리를 사용하는 시스템에서는 사용할 수 없는 알고리즘임
캐싱 기법
- 한정된 빠른 공간(= 캐시)에 요청된 데이터를 저장해 뒀다가 후속 요청 시 캐시로부터 직접 서비스하는 방식
- paging system 외에 cache memory, buffer caching, web caching 등 다양한 분야에서 사용 중
- 캐시 운영의 시간 제약 조건
- 교체 알고리즘에서 삭제할 항목을 결정하는 일에 지나치게 많은 시간이 걸리는 경우 실제 시스템에서 사용할 수 없음
- Buffer caching 이나 Web caching 의 경우
- O(1)에서 O(log n) 정도까지 허용
- Paging system 의 경우
- page fault인 경우만 OS가 관여
- 페이지가 이미 메모리에 존재하면 참조시각 등 정보를 OS가 알 수 없음
- O(1) 인 LRU list 조작조차 불가능 함
- LRU와 LFU가 사용할 수 없다면 실제로 어떤 페이지 교체 알고리즘을 사용할까? =>
Clock Algorhtim
Clock Algorthim
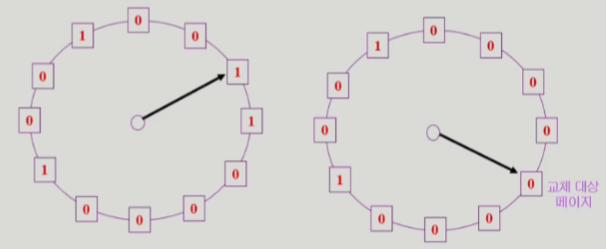
- LRU의 근사(approximation) 알고리즘
- 한 바퀴를 돌면서 최근에 참조되지 않은 페이지를 교체하는 방식
- 여러 명칭으로 불림
- second chance algorithm
- NUR(Not Used Recently) or NRU(Not Recently Used)
- 최근에 사용되지 않은 페이지는 앞으로도 사용되지 않을 가능성이 높다는 것을 전제로 한다. => 가장 오래전에 참조된 페이지는 OS가 알 수 없기 때문에 가장 최근에 사용되지 않는 페이지를 대상으로 선정한다
- 각 페이지마다 두 개의 비트
참조 비트,변형 비트를 사용한다 => 주소 변환을 해주는 H/W가 이를 기록해준다참조 비트: 페이지가 참조되지 않았을 때 0, 호출 됐을 때 1 (최근에 참조됐다는 걸 의미)변형 비트: 페이지 내용이 변경되었을 때 1, 변경되지 않았을 때 0- 우선 순위 : 참조 비트 > 변형 비트
참조 비트를 사용해서 교체 대상 페이지 선정함(circular list)참조 비트가 0인 것을 찾을 때까지 포인터를 하나씩 앞으로 이동하고 이동하는 중에참조 비트가 1인 건 모두 0으로 바꿈참조 비트가 0인 것을 찾으면 그 페이지를 교체함- 한바퀴를 되돌아와서도(=second chance) 0이면 그 때 replace 함 => 자주 사용되는 페이지라면 second chance가 왔을 때 1임
Clock Algorhtim의 개선
참조 비트와변형 비트(= dirty bit)를 같이 사용참조 비트=1: 최근 참조된 페이지변형 비트=1: 최근 변경된 페이지(I/O를 동반하는 페이지)- e.g) ref bit=0, mod bit=0 => backing storage에서 올라온 뒤로 변형이 없었기 때문에 그냥 날려도 상관없음
- e.g) ref bit=0, mod bit=1 => backing storage에서 올라온 뒤로 변형이 있었다는 의미로, 날리기 전에 backing storage로 변경된 내용을 반영한 후에 날려야 함
- 즉, mod bit가 1인 것보다 0인 걸 우선적으로 교체함으로써 성능을 개선할 수 있음
Page Frame Allocation
- 페이징의 성능 향상을 위해서는
페이지 교체를 줄이는 것이 필수적이고,이를 위해서는 일련의 페이지들이 같이 메모리에 올라와 있어야 함 - Allocation의 필요성
- 메모리 참조 명령어 수행 시 명렁어, 데이터 등 여러 페이지를 동시에 참조함
- 명렁어 수행을 위해서 최소 할당되어야 하는 frame의 수가 있음
- Loop를 구성하는 page들은 한꺼번에 allocate 되는 것이 유리함
- 최소한의 allocate가 없으면 매 loop마다 page fault가 발생함
- 메모리 참조 명령어 수행 시 명렁어, 데이터 등 여러 페이지를 동시에 참조함
- Allocation Scheme
- Equal allocation: 모든 프로세스에 똑같은 갯수 할당
- Propotional allocation: 프로세스 크기에 비례하여 할당
- Priority allocation: 프로세스의 priority에 따라 다르게 할당
Global vs Local Replacement
Global replacement
- Replace 시에 다른 process에 할당된 frame을 빼앗아 올 수 있음
- Process별 할당량을 조절하는 또 다른 방법임
- FIFO, LRU, LFU 등의 알고리즘을 global replacement로 사용시 해당
- Working set, PFF 알고리즘 사용
Local replacement
- 자신에게 할당된 frame 내에서만 replacement
- FIFO, LRU, LFU 등의 알고리즘을 process별로 운영시
Thrashing
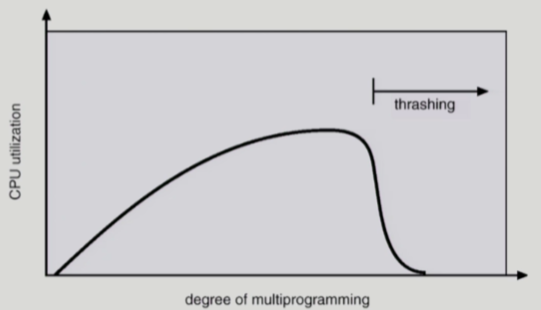
- 프로세스의 원활한 수행에 필요한 최소한의 page frmae 수를 할당받지 못한 경우 발생함
- 발생 순서
- page fault rate가 매우 높아짐
- CPU uilitzation이 낮아짐
- OS가 MPD(Multiprogramming degree)를 높여야 한다고 판단
- 또 다른 프로세스가 시스템에 추가됨 (higher MPD)
- 프로세스 당 할당된 frame의 수가 더욱 감소함
- 프로세스는 page swap in/out 으로 매우 바빠짐
- 대부분 시간에 CPU는 한가함
- low throughput
- Thrashing 방지하는 방식에는 크게
working-set model과PFF Scheme이 있음
1. Working-Set Model
- locality에 기반해 프로세스가 일정 시간동안 원활하게 수행되기 위해 한꺼번에 메모리에 올라와 있어야 하는 page들의 집합을
working set이라고 정의함 - working set 모델에서는 process의 working set 전체가 메모리에 올라와 있어야 하고, 그렇지 않으면 모든 frame을 반납하고 swap out(suspend)됨
- MPD를 결정하며, Thrashing을 방지함
locality of reference
- 프로세스는 특정 시간동안에 일정 장소만을 집중적으로 참조하는 특징이 있음
- 집중적으로 참조되는 해당 page들의 집합을 locality set이라고 함
Working set의 결정 방법
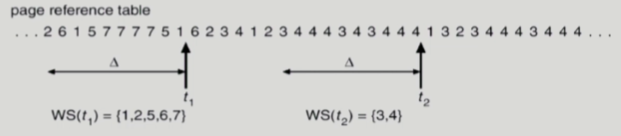
- working set은 미리 알 수가 없기 때문에 과거를 통해서 working set을 추정함
- working set window를 통해 알아냄
Working-Set Algorithm
- 프로세스들의 working set size의 합이 page frame의 수보다 큰 경우
- 일부 프로세스를 swap out 시켜서 남은 process의 working set을 우선적으로 충족시켜 준다(= MPD를 줄임)
- Working set을 다 할당하고도 page frame이 남는 경우
- swap out 됐던 프로세스에게 working set을 할당 (= MPD를 키움)
2. PFF(Page-Fault Frequency) Scheme
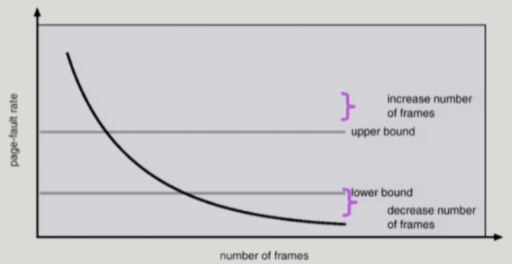
- page-fault rate이 크다? => working set이 보장되지 않았다고 판단해서 page를 더 할당하고, 반대면 줄이는 방식
- page-fault rate의 상한과 하한을 둠
- page fault rate가 상한값을 넘으면 frame을 더 할당
- page fault rate가 하한값 이하면 할당 frame 수를 줄임
- 빈 frame이 없으면 일부 프로세스를 swap out
Page Size 결정
- Page size를 감소시키면
- 페이지 수 증가
- 페이지 테이블 크기 증가
- Internal fragmentation 감소
- disk transfer 효율성 감소
- seek/rotaiton vs transfer
- disk I/O에는 sink 하는 시간이 오래 걸리기 때문에 한번 가져올 때 뭉텅이로 가져오는게 효율적임(= page size가 큰게 효율적)
- 필요한 정보만 메모리에 올라와 메모리 이용이 효율적
- locality 활용 측면에서는 좋지 않음
- trend는 page size를 더 크게 하는 방식임
출처: http://www.kocw.net/home/search/kemView.do?kemId=1046323

내 머릿속 지우개