오늘은 배열과 연결리스트를 비교해보도록 하겠습니다.
그동안 둘을 구분짓지 않고 편한대로 개발에서 사용했던 것 같네요..😢
지금이라도 제대로 알고 상황에 따라 필요한 자료구조를 사용하도록 해야겠어요! 😀
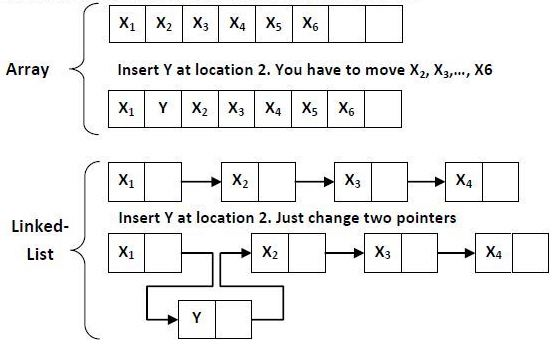
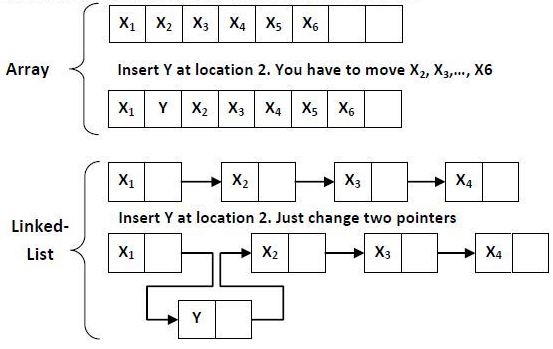
배열(Array)
- 데이터가 순차적으로 저장되어있는 선형 자료구조
- 메모리가 연속적이므로
Cache hit rate 높음 - 메모리 상
연속된 구간을 잡아야하므로 할당에 제약이 있음 - 추가적으로 소모되는 메모리 양(overhead) 거의 없음
- 원소 확인/변경:
O(1)
- index를 통해 데이터 바로 접근 가능- How? 연속적인 메모리 공간에 저장되어 있어 논리적 저장 순서와 물리적 저장 순서가 같기 때문에
- 인덱스가 주소에 상응하는 의미 갖게 됨
- 삽입 & 삭제
- 원소의 끝:
O(1) - 임의의 위치:
O(N)
- 원소의 끝:
- 메모리 할당 시점:
컴파일 타임,정적,Stack에 저장됨(c에서)
- 자바에서는 배열도 객체로 봐서Heap에 저장됨
링크드리스트(Linked List)
- 데이터가 순차적으로 저장되어있는 선형 자료구조
- 원소 저장시 저장 위치까지 포함해 저장
- 메모리 상에
비연속적으로 데이터 저장하여, 포인터로 다음 데이터 가리킴
→ 낭비되는 메모리 없음 - 메모리가 비연속적이므로
Cache hit rate 낮지만, 할당이 다소 쉬움 - 인덱스는 데이터 순서의 의미만 (주소의 의미 X)
- K번째 원소 확인/변경 :
O(K) - 삽입 & 삭제 임의의 위치:
O(1) - 종류 : 단일 연결 리스트, 이중 연결 리스트, 원형 리스트
- 메모리 할당 시점 :
런타임,동적,Heap에 저장됨
💡 Cache Hit Rate가 배열에서 높고 연결리스트에서 낮은 이유는?
캐시 메모리는 CPU와 메모리의 속도 차이를 줄이기 위해 사용하는 고속 버퍼 메모리이다. 자주 사용하는 데이터를 캐시 메모리에 저장하여 메모리 접근 횟수를 줄이고 성능을 향상 시킨다.
CPU가 메모리에 접근하기 전에 캐시에서 데이터 존재 여부를 먼저 살펴본다. 데이터가 있으면 hit, 없으면 miss 라고 한다.
Cache Hit Rate은 요청한 데이터를 캐시 메모리에서 찾을 확률이다. 다시 말해, Cache Hit Rate이 높아야 컴퓨터가 빠르게 데이터를 가지고 올 수 있는 것이다.
캐시 메모리는 참조 지역성(Locality of reference)에 근거한다.
시간 지역성: 최근에 참조한 데이터를 다시 참조할 가능성이 높다공간 지역성: 참조한 데이터와 인접한 데이터가 참조될 가능성이 높다.
cpu 캐시나 디스크의 경우 한 메모리 주소에 접근할 때, 블록(block) 단위로 가져오게 된다. 블록의 크기는 32 bytes나 64 bytes이다.
이렇게 크게 블록으로 가져오는 이유는 메모리에 접근하는 비용이 크기 때문에 한번에 많이 가져오게 한 것이다.순차적 지역성: 분기가 발생하지 않는 한 메모리에 저장된 순서대로 실행된다.
즉, 배열은 연속적인 메모리에 저장하고, 연결 리스트는 비연속적인 메모리에 저장한다는 점에서
공간 지역성에 근거하여 배열의 Cache Hit Rate이 더 높다.
연결리스트와 관련된 추가 질문
-
원형 연결 리스트 내의 임의의 노드 하나가 주어졌을 때 해당 List의 길이를 효율적으로 구하는 방법은?
임의의 노드 값을 저장해놓고 해당 값이 나올때까지 이동시키면 된다.
공간복잡도 O(1), 시간복잡도 O(N) -
중간에 만나는 두 연결 리스트의 시작점들이 주어졌을 때 만나는 지점을 구하는 방법은?
두 연결 리스트를 각각 끝까지 이동시켜 각각 연결리스트의 길이를 구한다. 그 후 다시 시작점으로 돌아와, 두 연결리스트의 차 만큼 더 짧은 연결리스트를 먼저 이동시킨다. 이제 두 리스트가 한 점에서 만날때까지 이동시킨다.
공간복잡도 O(1), 시간복잡도 O(A+B) -
주어진 연결 리스트 안에 사이클이 있는지 판단하라.
Floyd's cycle-finding algorithm
한 칸씩 이동하는 커서와 두 칸씩 이동하는 커서를 동일한 곳에서 시작시킨다. 두 커서가 만나게 되면 사이클이 존재하는 것이다.
공간복잡도 O(1), 시간복잡도 O(N)
정리
배열
- 목적 : 인덱스에 해당하는 원소를 빠르게 접근하기 위해 사용
- 물리적 메모리에 연속적으로 위치
연결리스트
- 목적 : 임의의 위치에 추가/삭제할 때 사용
- 물리적 메모리에 비연속적으로 위치
참고자료
https://www.interviewbit.com/courses/programming/linked-lists/arrays-vs-linked-lists/
https://blog.encrypted.gg/927
https://blog.encrypted.gg/932
https://github.com/da-in/tech-interview-study/blob/main/Tech%20Interview%20Cheat%20Sheet/Data%20Structure/Array&List.md
