라우터의 구조
라우터의 전체적인 구조는 다음과 같다.
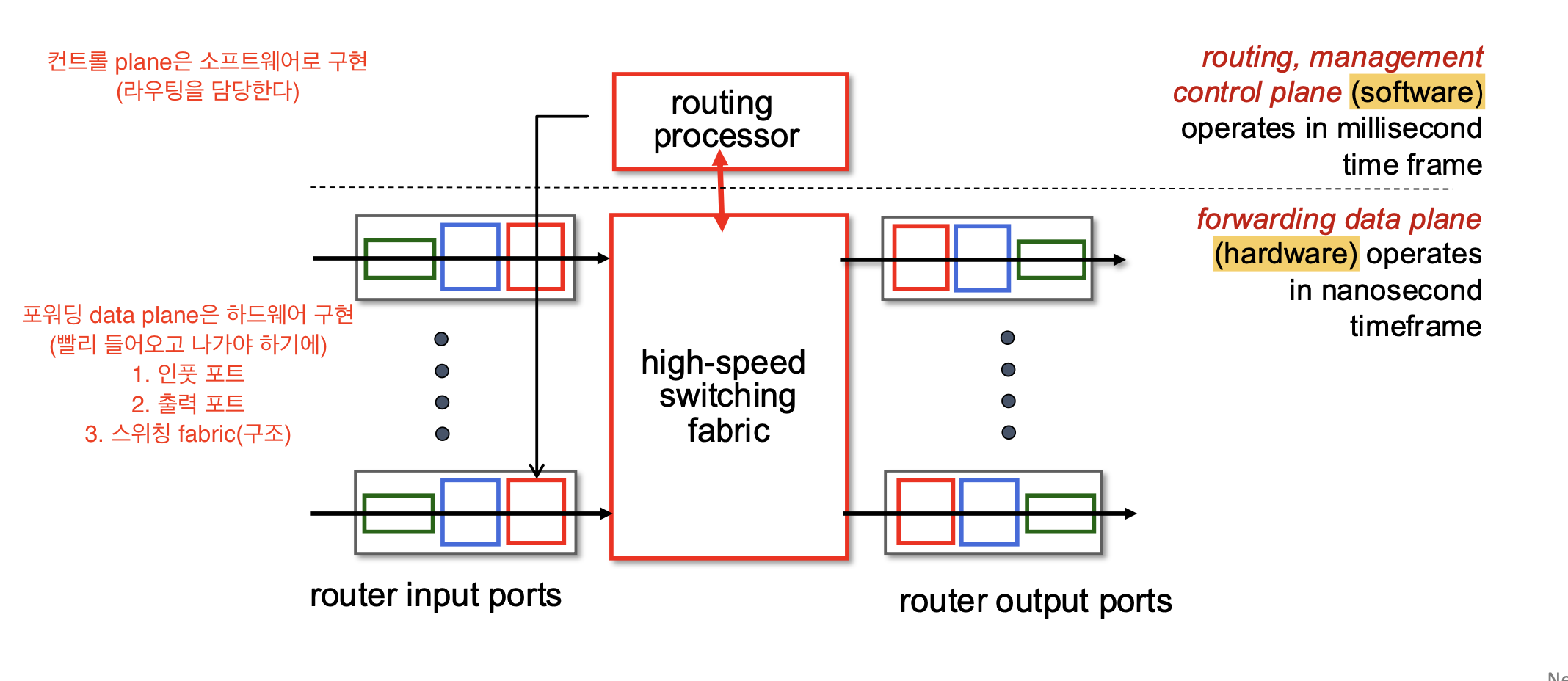
-
데이터 plane은 하드웨어로 구현된다.
이러한 이유는 데이터를 빨리 들여 보내고 내보내야 하기 때문이다. -
컨트롤 plane은 소프트웨어로 구현된다.
Input 포트 기능
패킷의 헤더 정보를 확인하고 포워딩 테이블과 매칭하여 출력 포트로 보낸다.
(match plus action)
인풋 포트는 물리, 링크, 네트워크 레이어로 구성된다.
가장 오른쪽 네트워크 레이어쪽의 인풋 포트에는 큐가 존재한다.
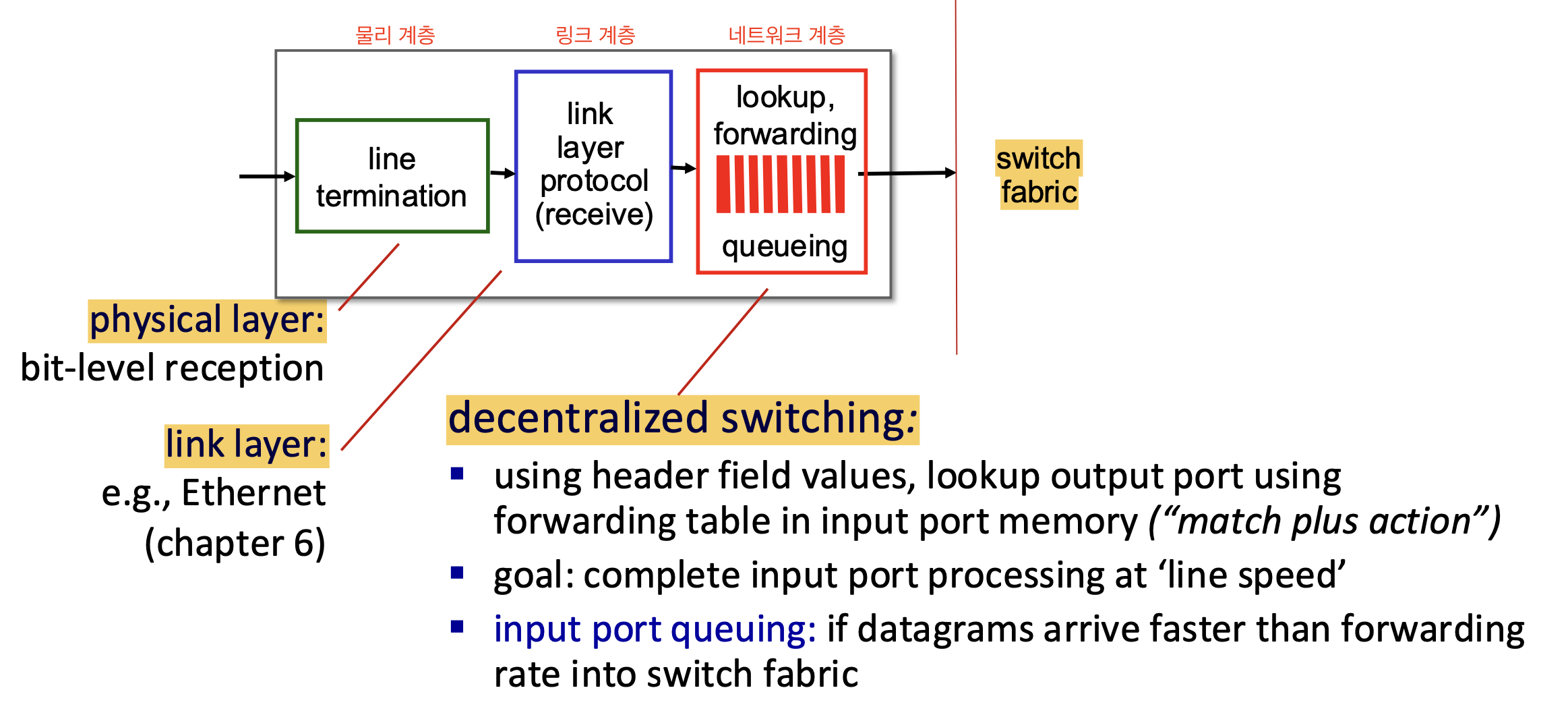
Decentralized Switching (분산 스위칭)
라우터의 인풋 포트는 분산 스위칭을 통해 빠르게 패킷을 전송한다.
-
헤더 필드 값 기반 포워딩
- 패킷의 헤더 필드 값(예: IP 주소, VLAN ID 등)을 기반으로 포워딩 테이블을 조회하여, 해당 패킷을 전달할 출력 포트를 결정한다.
- 이 과정은 입력 포트의 메모리(큐)에서 이루어진다
(match plus action)
-
목표: '라인 속도(line speed)'로 처리
- 입력 포트에서의 모든 처리가 패킷 전송 속도에 맞춰 이루어져야 한다.
(적당한 속도로 전송해야 한다. fabric 보다 빨리 전송하면 loss발생)
- 입력 포트에서의 모든 처리가 패킷 전송 속도에 맞춰 이루어져야 한다.
-
입력 포트 큐잉 (Input Port Queuing)
- 만약 데이터그램이 스위치 패브릭으로 전달되는 속도보다 더 빠르게 도착하면, 입력 포트에서 큐잉 딜레이가 발생한다.
- 이로 인한 지연과 loss를 막기 위해 라인 속도로 보내야 한다.
destination-based forwarding
송신자 IP 정보를 확인 후 보낸다.
generalized forwarding
송수신 IP, 포트, 혹은 메세지 body까지의 정보도 확인하여 포워딩한다.
목적지 기반 포워딩 (범위)
IP를 적절한 범위로 나누어 해당 엔트리의 범위에 있는 출력 포트로 매핑한다.

32 비트의 IP 주소 마다 테이블 엔트리를 만드는 것은 무리이다.
그래서 범위로 IP를 나누어 해당 엔트리의 범위에 있으면 매핑한다
Longest Prefix 매칭
테이블 엔트리의 앞 부분과 가장 길게 맞아 떨어지는 출력 포트로 매핑한다.

스위칭 fabric (구조)
패킷을 입력 링크로 부터 받아 출력 링크로 빠르게 전달하는 기능을 수행한다.
(input -> output 으로 스위칭 된다.)
fabric의 스위칭 rate 속도가 가장 중요하다. -> 최대한 빨리 보내야 한다.
왜냐면 input포트에서 오는 속도보다 느리게 되면 큐잉딜레이와 loss가 발생할 수 있기 때문.
스위칭 rate
- 입력에서 출력으로 패킷을 얼마나 빠르게 전달할 수 있는지를 나타낸다.
- N개의 입력을 가진 스위치의 이상적인 스위칭 속도
(1Gbps 속도의 입력 포트 4개라면, 스위칭 속도는 4Gbps가 이상적이다)
왜냐하면 모든 포트가 동시에 데이터를 최대 속도로 전송할 수 있기 떄문이다.
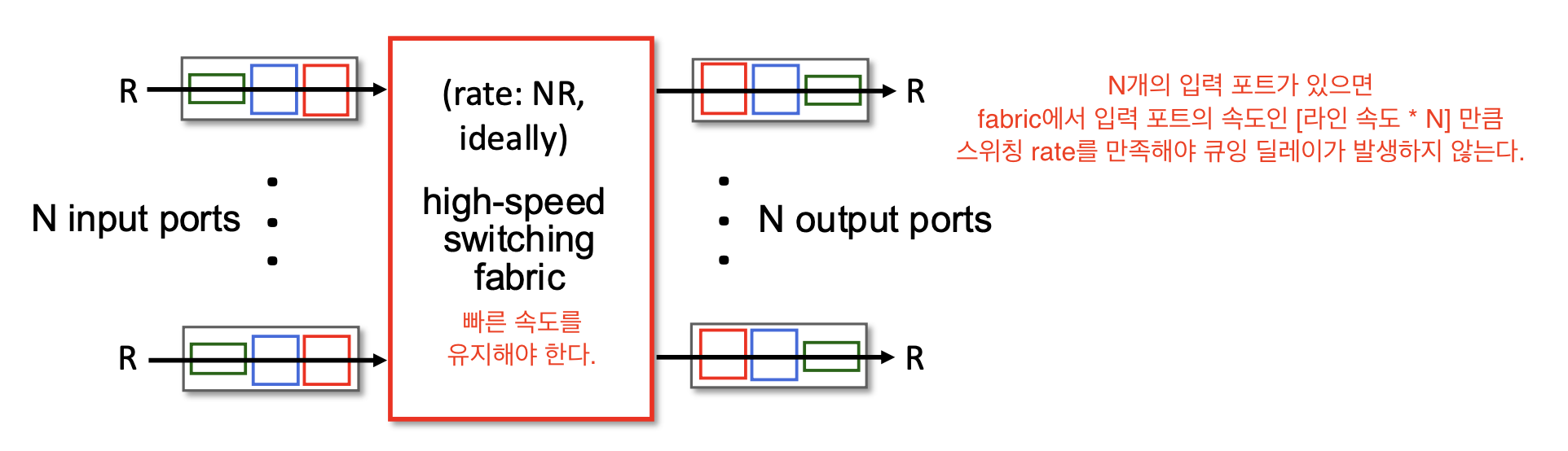
인풋의 속도 보다 스위칭 rate이 느리게 되면
(N개의 라인이 있는데 스위칭 rate = 라인속도 * N 이 아니라면)
인풋 큐에 패킷이 쌓인다 -> 큐잉 딜레이 발생
이제 세가지 스위칭 방법에 대해 알아보자.
1. 메모리를 통한 스위칭
중앙 메모리를 이용해 입력 포트에서 출력 포트로 데이터를 전송하는 방식
패킷 전달 과정
-
패킷이 도착하면 입력 포트는 라우팅 프로세서에게 인터럽트를 보내 패킷을 프로세서 메모리에 복사한다.
-
라우팅 프로세서는 헤더에서 목적지 주소를 추출한다.
-
포워딩 테이블에서 적절한 출력 포트를 찾은 다음 패킷을 출력 포트의 버퍼에 복사한다.
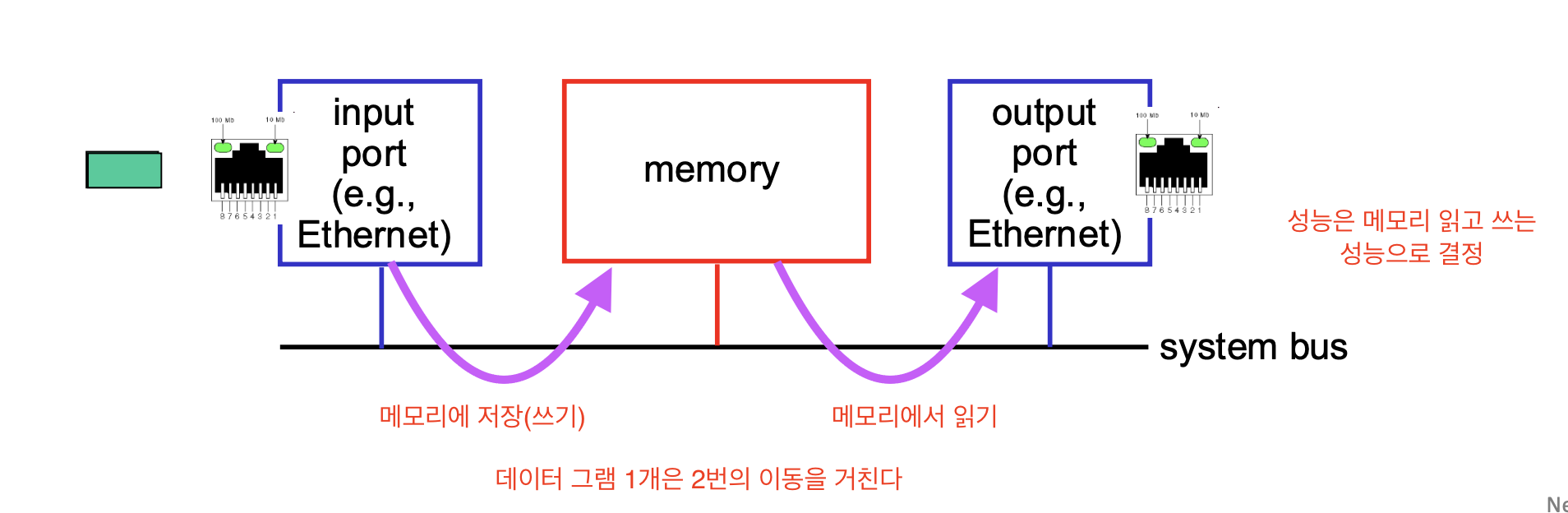
메모리 대역폭
스위치의 전체 성능은 메모리가 데이터를 얼마나 빠르게 읽고 쓸 수 있는지에 따라 결정된다.
각 패킷이 한 번의 쓰기와 한 번의 읽기를 필요로 하므로, 2배의 메모리 대역폭이 필요하다.
<예시>
라인 속도가 1Gbps인 경우,
메모리는 최소 2Gbps의 속도를 지원해야 모든 입력/출력 처리를 원활히 수행할 수 있다.즉 성능(속도)는 메모리의 대역폭에 따라 결정된다.
2. bus를 통한 스위칭
공유 버스를 통해 데이터를 출력 포트로 전송한다.
입력 포트는 라우팅 프로세서의 개입 없이 공유 버스를 통해 직접 출력 포트로 패킷을 전송한다.
패킷 전달 과정
-
입력 포트로 들어오게 되면 각 패킷을 레이블링 한다.
-
레이블링 한 후 모든 출력 포트에 패킷을 보낸다.
-
추후 레이블과 매칭되는 포트로 전송된 패킷(맞는 경로로 간 패킷)만 유지하고 다른 패킷을 drop한다.
-
레이블은 버스를 통과하기 위해서만 사용되므로 출력 포트에서 제거된다.
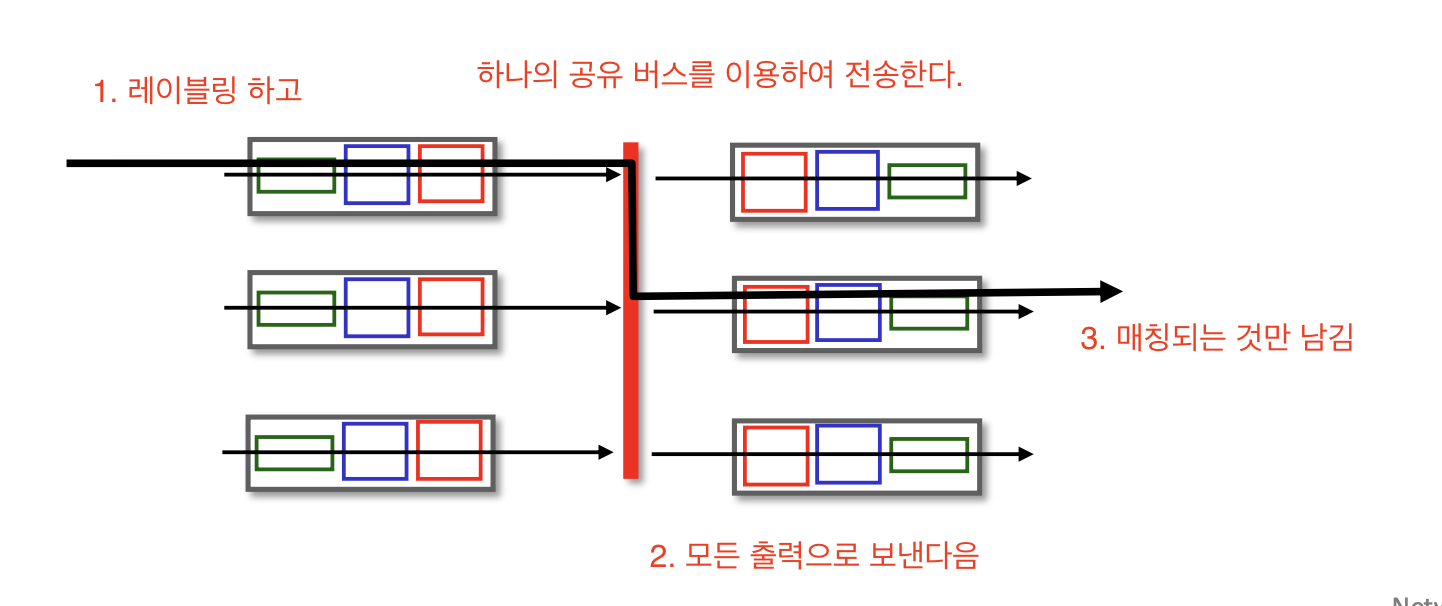
동시에 여러 패킷이 다른 입력 포트에 있는 라우터에 도착하면 한 번에 하나의 패킷만 버스를 통과할 수 있기 때문에 하나를 제외한 모든 패킷이 대기 해야한다.
모든 패킷이 하나의 버스를 통과해야하므로 라우터의 교환 속도는 버스 속도에 의해 제한된다.(속도가 비교적 느리다.)
3. 상호 연결 네트워크를 통한 교환
bus가 교차되는 지점에 스위치가 존재하여 여러 인풋으로 동시에 들어와도 병렬적으로 전송가능 하다.
그러나 두개의 서로 다른 입력 포트에서 나오는 2개의 패킷이
동일한 출력 포트로 보내지는 경우,
한번에 하나의 패킷만 특정 버스에서 전송될 수 있기 때문에 입력을 기다려야한다.
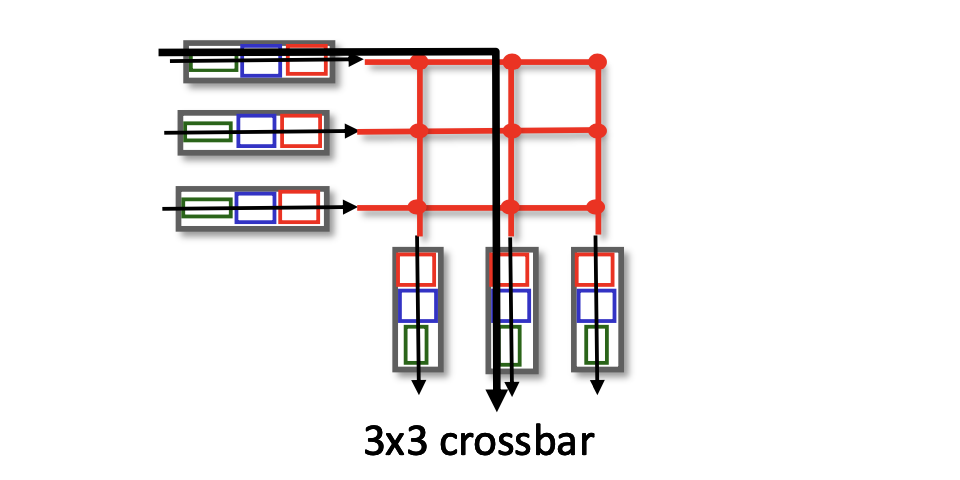
-
멀티스테이지 스위치
N*N 개의 스위치가 존재한다.
(위 그림의 교차점이 스위치) -
성능 더~~ 올리기
패킷을 청크로 나누어(고정 길이 셀) 병렬적으로 빠르게 보냄
추후 다시 데이터 그램으로 만듬

-
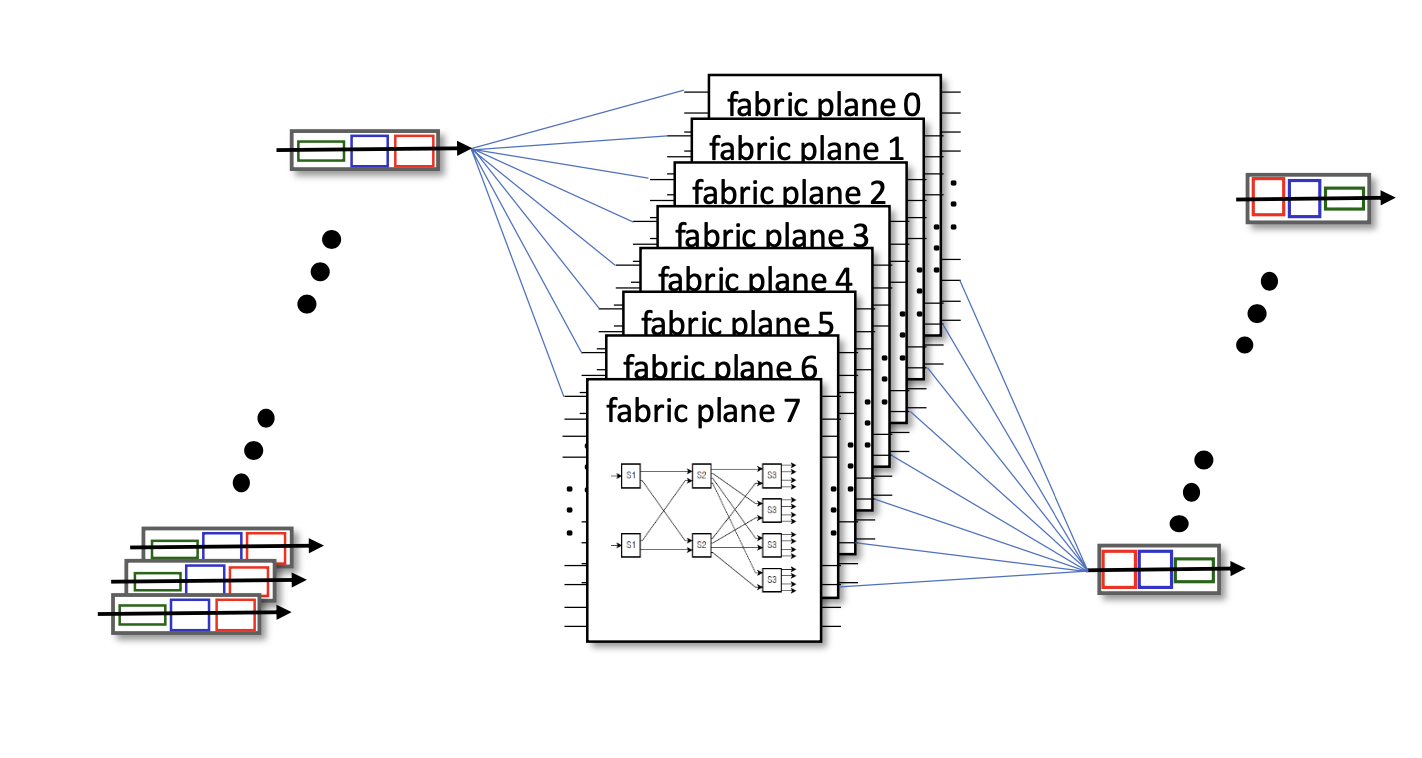
다중 스위칭 fabric 평면(Planes)
여러 개의 fabric 평면을 병렬로 사용하여 확장성과 처리 속도를 높임. -
Cisco CRS 라우터
• 기본 단위로 8개의 fabric 평면을 사용.
• 각 평면은 3단계(3-stage) 상호 연결 네트워크로 구성
• 이 구성을 통해 수백 Tbps의 스위칭 용량을 제공
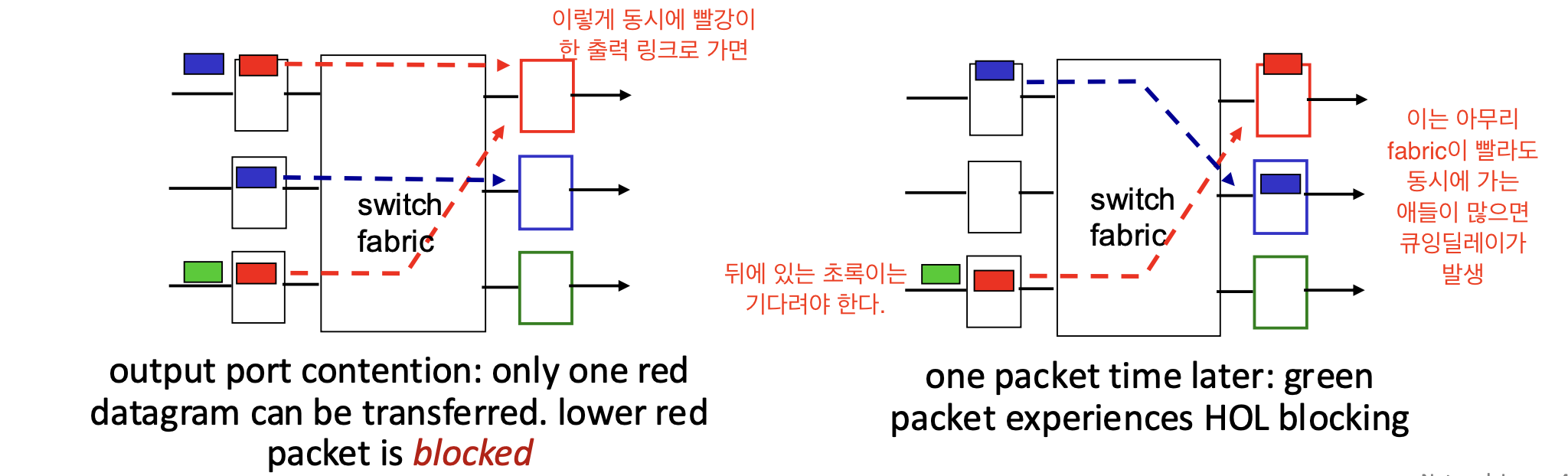
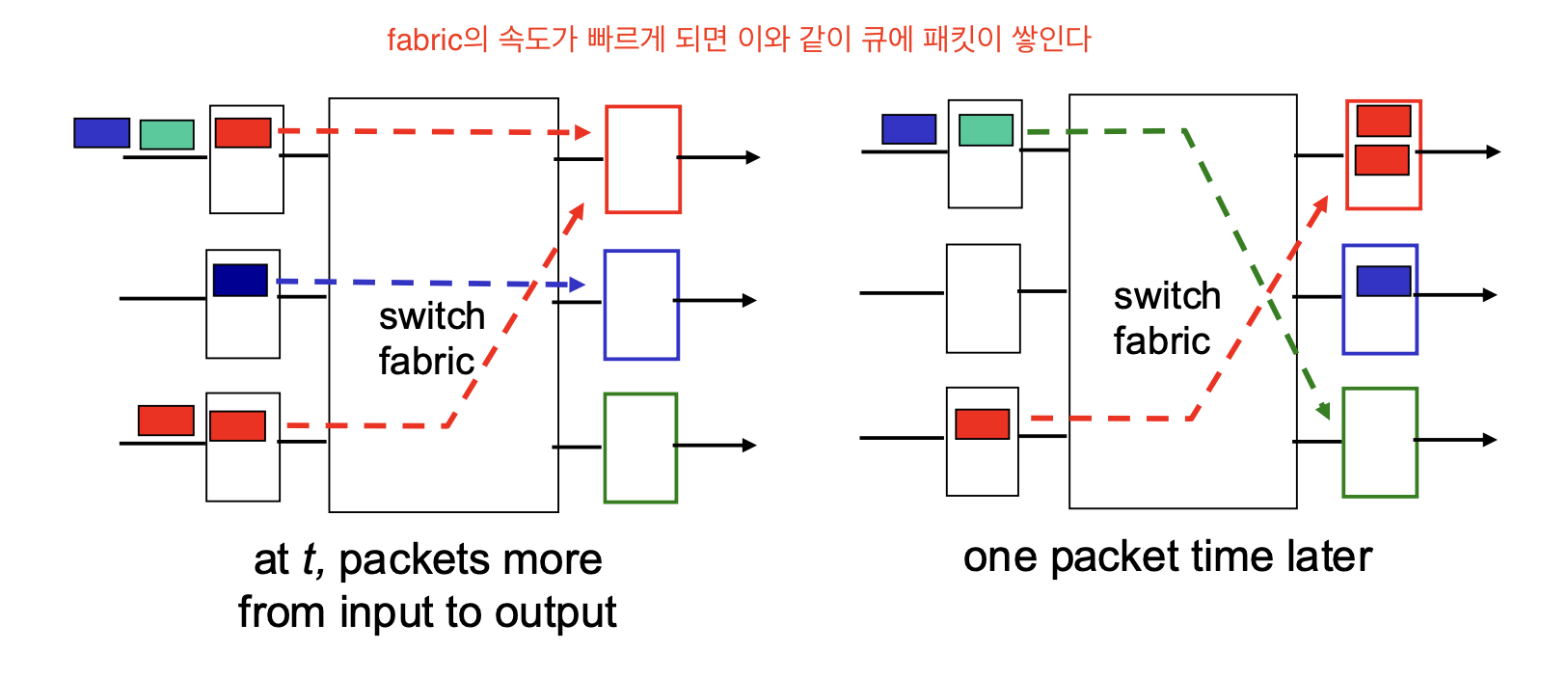
Input 포트 큐잉
-
큐잉 딜레이와 loss
만약 fabric이 인풋 포트보다 느리면 큐잉딜레이, loss가 발생한다. -
HOL blocking
앞서 가는 패킷들 때문에 기다려하 하는 시간이 길어 질 수 있다.
(아무리 febric 빨라도 기다려야 한다.)
Output 포트 큐잉
Output 포트에서도 마찬가지로
스위칭 fabric rate>Output rate(transmission delay)
이면 Output 큐에도 패킷이 쌓여 loss 및 큐잉딜레이가 발생한다.
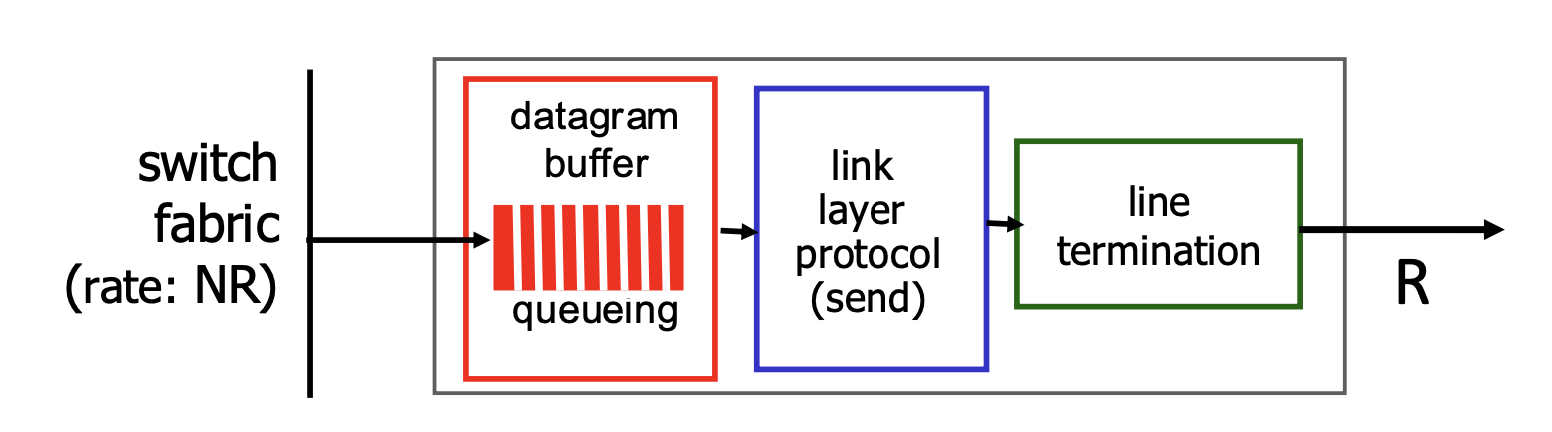
loss 및 큐잉딜레이의 발생 가능성으로 두가지의 상황을 고려해야한다.
-
버퍼 안에 패킷이 쌓이면 어떤 걸 먼저 보내야 하는지?
-
버퍼가 꽉 차게 되면 어떤걸 먼저 drop해야 하는지?
먼저 도착한 것을 보내야 할까, 패킷의 우선순위를 고려해야 할까, 패킷의 사이즈를 고려해야 할까...?
이렇듯 어떤것에 우선순위를 두어 스케줄링 하느냐에 따라 성능에 영향을 미치게 된다.
버퍼 사이즈의 결정
두 가지의 방법이 있다.
-
버퍼 사이즈=typical RTT*링크 용량 C -
버퍼 사이즈=typical RTT*링크 용량 C/ 루트TCP 플로우 개수
버퍼 사이즈가 마냥 크면 좋을 것 같지만 막상 그렇지는 않다.
버퍼사이즈가 크게 되면 그 만큼 큐에서 오래 대기하는 패킷이 생길 수 있다.
즉, 딜레이가 길어질 수 있다.(이는 실시간 통신에서 치명적이다.)
또한, 긴 RTT 를 갖는 다면 당연하게도 성능이 최악일 것이다.
버퍼 Management
-
drop 정책
tail drop - 늦게 온 패킷부터 drop 한다.
priority - 패킷의 우선순위가 가장 낮은 것 부터 버린다. -
마킹 정책
혼잡 상황일 때 어떤 패킷에 마킹을 하여 혼잡 상황을 알려야 할까?(ECN, RED)
우선순위가 높은 것에 하거나 ...
패킷 스케줄링
어느 패킷을 먼저 보내야 할지 정하는 4가지의 방법이 존재한다.
1. FCFS
선입 선출, 가장 먼저온 패킷 부터 보낸다.
2. 우선순위
패킷이 도착하면
높은 우선순위 큐/낮은 우선순위 큐에 나누어 높은 우선순위 큐 에서부터 보낸다.
그 후 같은 우선순위 큐에 존재하는 패킷들은 FCFS 방식을 사용한다.
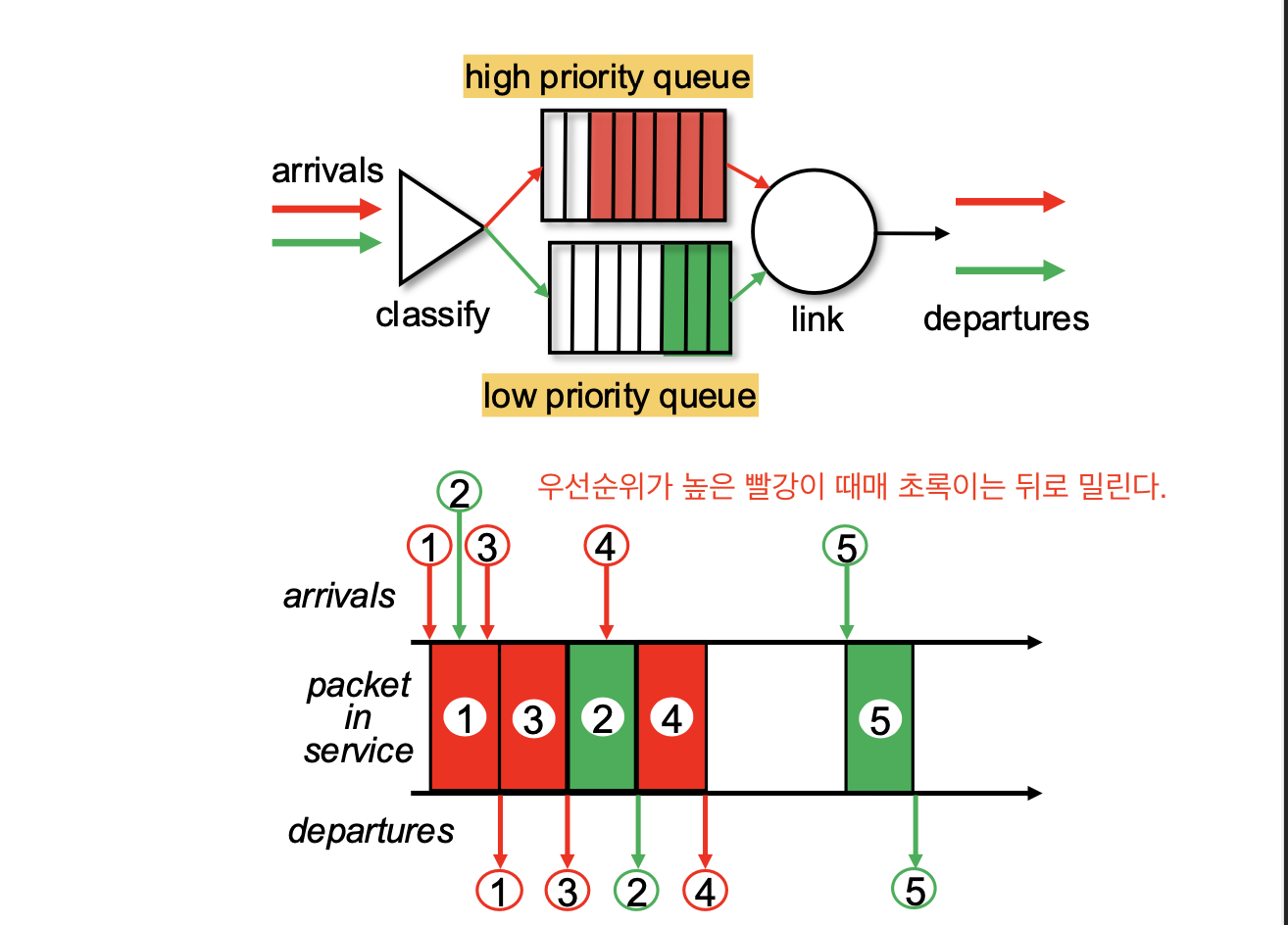
3. Round Robin
클래스를 여러개로 나누어 (큐를 여려개를 둔다.) 번갈아 가면서 보내는 방식
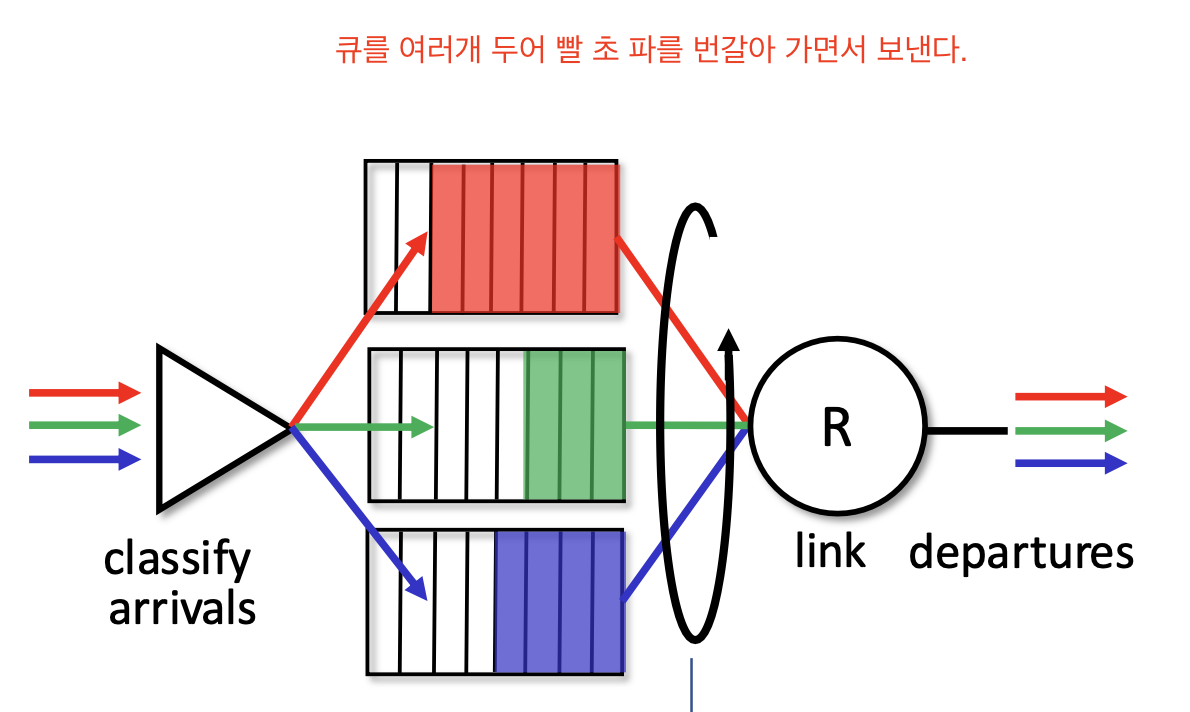
이때 빨강이 뒤쪽에 있는 패킷들은 늦게 보내질 수 있다.
4. Weighted Fair Queueing (WFQ)
라운드 로빈처럼 큐를 여러개 두고 번갈아 가며 전송하지만,
각 클래스에 우선순위에 따른 가중치를 두어 보낸다.
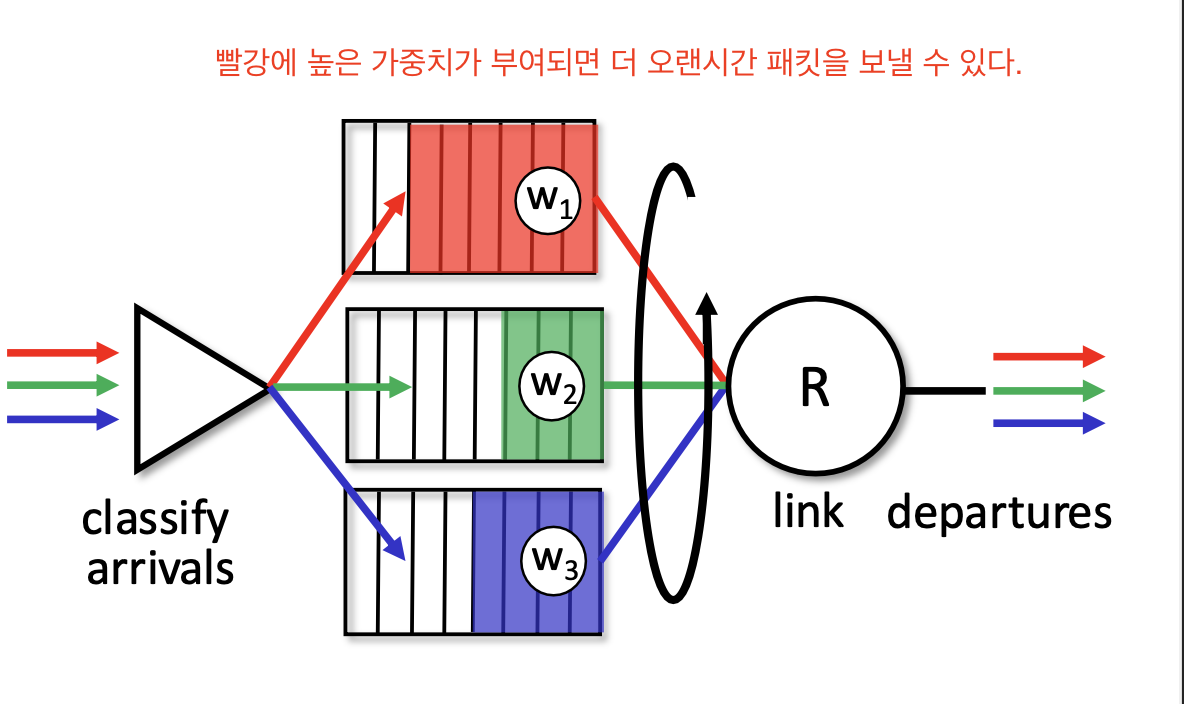
WFQ에서는 각 클래스당
가중치 w(i) / ∑w(i) 만큼의 서비스 시간을 보장받는다.
즉, 최악의 경우 모든 큐에 패킷이 있을 때도 위의 시간을 보장 받는다.
(각 클래스에 트래픽이 있어도 최소 대역폭이 보장된다.)
따라서 전송률 R인 링크에 대해 클래스 i는 항상 최소한 R x w(i) / ∑w(i)의 처리율을 갖는다.
참고
망 중립성
위에서 살펴 보았듯 패킷을 보낼 때 여러가지 기준에 따라 정책을 달리하여 패킷을 전송할 수 있다.
그렇다면 인터넷 서비스를 제공하는 ISP (네트워크의 사업자)는 서비스의 품질을 결정 할 수 있다.
때문에 이러한 망의 사용이 네트워크의 사업자에 따라 좌우될 수 있으므로
(어느 사람에게는 느리게 보내고 빨리 보내고.. 가입비에 따라 서비스 품질 차이를 둔다거나...) 규제가 필요하다.
