4장에서는 Data Plane, 즉 각각의 라우터에서 어떻게 포워딩 되는지를 다루었다.
5장에서는 Control Plane의 라우팅 알고리즘과 SDN 방식에 대해 알아볼 예정이다.
본격적으로 들어가기 전에 이전 내용을 복습해 보자.
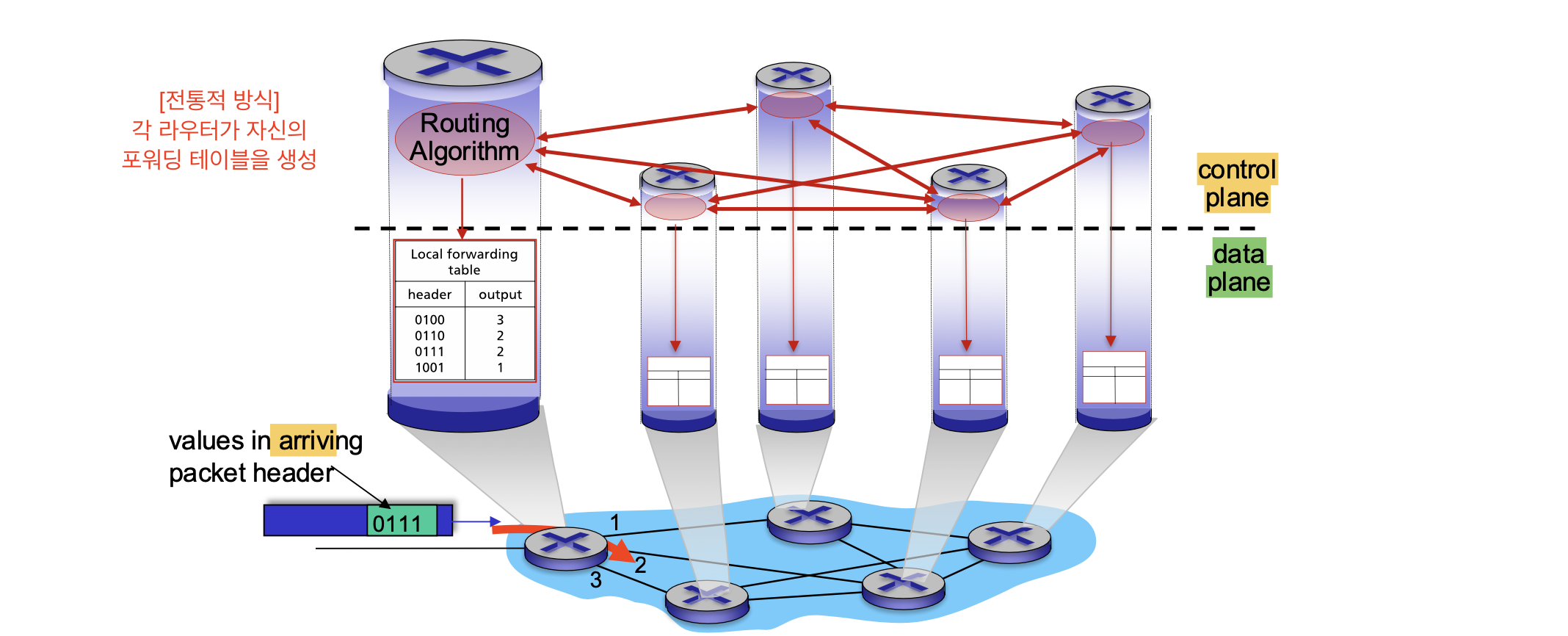
1. 전통적인 라우팅 알고리즘
각 라우터에서 자신의 포워딩 테이블을 결정한다.
(이웃 라우터와 주고 받은 정보를 바탕으로 테이블 생성)
per-router control이라고도 하며, 각 라우터가 자신의 정보를 교황하여 포워딩 테이블을 만들게 된다.
2. Software Defined Networkin (SDN)
외부의 중앙 서버가(컨트롤러) 각 라우터로 부터 정보를 수집하여 flow 테이블을 생성하여 라우터에 전달한다. (중앙 서버에서 직접 구현할수 있더 좀 더 유연하다)
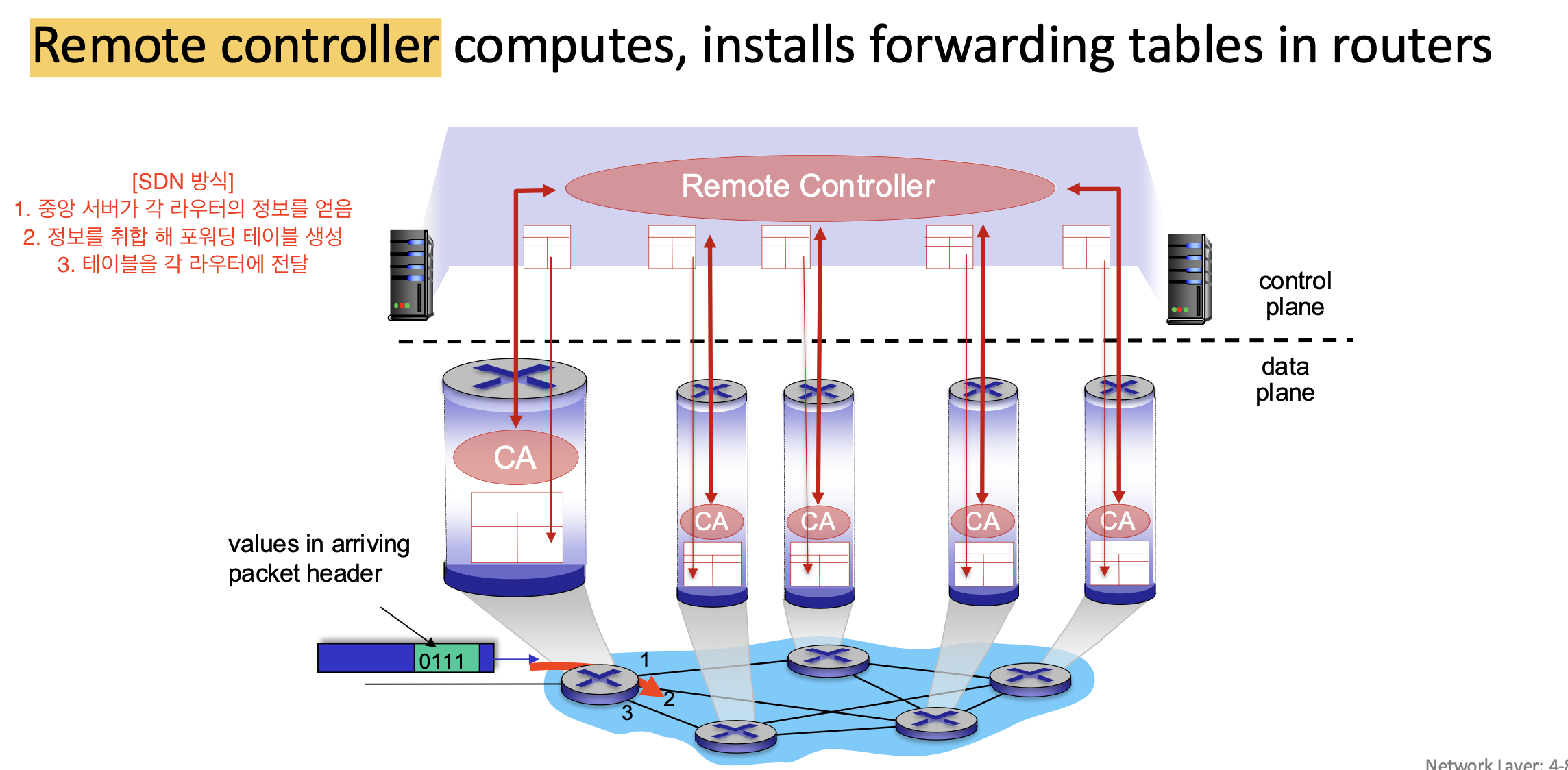
여기서 CA는 다음의 역할 을 한다.
1. 각 라우터에서 받은 정보를 컨트롤러에 전달. (UP)
2. 컨트롤러가 만든 테이블을 각 라우터에 전달. (DOWN)
라우팅 프로토콜
라우팅 프로토콜의 목표는 좋은 path를 결정하여 포워딩 테이블을 구성하는 것이다.
이 목차에서 다룰 라우팅 프로토콜은 전통적인 방식의 프로토콜이다.
여기서 "좋은"이라는 기준은 여러가지가 될 수 있다.
1. 가장 낮은 cost
2. 가장 빠른
3. 패킷이 몰리지 않고 고루 보내지는 것 (least congested)
이 기준은 어느것이 좋고 나쁜것은 없고,
네트워크의 오퍼레이터가 무엇을 중점으로 두느냐에 따라 정해진다.
라우팅 프로토콜의 분류
라우팅 프로토콜은 다음의 기준에 따라 분류될 수 있다.
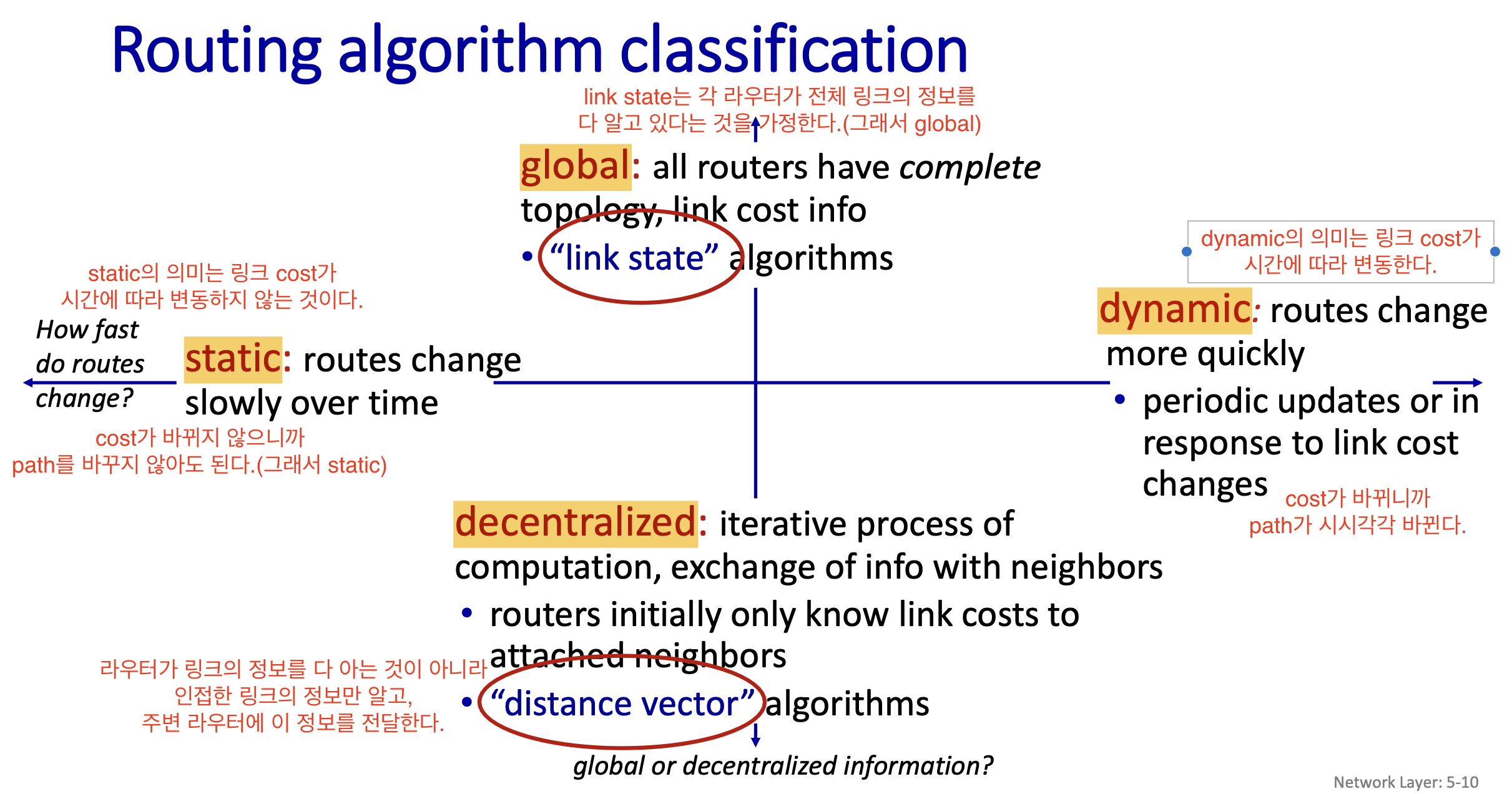
1. Global과 Decentralized
각 라우터가 링크의 정보를 알고 있는 범위에 따라 분류한다.
-
Global
각 라우터는 전체 링크의 cost 정보를 알고 있다.
➡️ Link State 알고리즘 -
Decentralized
각 라우터는 전체 링크의 cost 정보를 알지 못하고 인접한 링크의 정보를 알고 있다,
하지만 이웃 라우터와 정보를 교환한 링크 cost 정보를 통해 반복적으로 경로를 계산한다.
➡️ Distance Vector 알고리즘
2. Static과 Dynamic
시간에 따라 cost, 즉 path가 달라지는 것에 따라 분류한다.
-
Static
각 링크의 cost가 시간에 따라 천천히 바뀐다.
때문에 알고리즘이 생성한 path 또한 바꾸지 않아도 된다. -
Dynamic
각 링크의 cost가 시간에 따라 자주 바뀐다.
(혼잡상황에 따라 cost가 바뀐다.)
때문에 알고리즘이 생성한 path 또한 더욱 자주 바꿔야 한다.
Link State
모든 라우터가 전체 링크의 cost정보를 알고 있는 것이다.
-
Centralized
모든 링크의 정보를 알고 있는 것을 Centralized 라고 한다.
링크의 상태는 각 라우터가 자기 주변의 링크 cost 정보를 모든 라우터에 알려주어(Broadcast) 라우터가 모든 링크의 상태를 알게 된다.
➡️ 결국 모든 노드(라우터)는 같은 정보를 갖는다. -
테이블의 생성
한 노드에서 출발하여 모든 노드마다 가장 낮은 cost path를 계산하여 포워딩 테이블을 만든다. (다익스트라 알고리즘)
반복적인 계산을 통해 path를 결정한다.
<노테이션>
1. Cx,y : x,y가 서로 이웃일 때 cost. (이웃이 아니라면 값은 무한대이다.)
2. D(v) : v까지 가는데 드는 최소 cost의 합
3. P(v) : v까지 가는 path에서 v노드 바로이전 노드 까지 드는 최소 cost의 합
4. N' : 최소 cost의 '노드' 집합다익스트라 link-state 라우팅 알고리즘
탐욕적 방법(Greedy Approach)을 사용해 각 단계에서 최적의 선택을 하며, 결과적으로 전체 최단 경로를 구하는 알고리즘이다.
Pseudo code
<Initialization:>
2 N' = {u} /* N'은 이미 처리된 노드 집합으로 초기에는 시작 노드 u만 포함 */
3 for all nodes v
4 if v adjacent to u /* v가 u와 직접 연결된 노드인지 확인 */
5 then D(v) = cu,v /* u에서 v로 가는 직접 경로 비용으로 설정 */
6 else D(v) = ∞ /* 그렇지 않으면, u에서 v로 가는 비용을 무한대로 설정 */
7
8 Loop
9 find w not in N' such that D(w) is a minimum
10 add w to N'
11 update D(v) for all v adjacent to w and not in N' :
12 D(v) = min ( D(v), D(w) + cw,v )
13 /* 새로운 최단 경로 비용은 기존 비용과 w를 거치는 경로 중 더 작은 값 */
14 until all nodes in N'
<전체 흐름 요약>
1.시작 노드에서 다른 노드로 가는 경로를 초기화.
2. 아직 처리되지 않은 노드 중 최소 비용 노드를 선택.
3. 해당 노드와 연결된 이웃 노드들의 경로 비용을 갱신.
4. 모든 노드가 처리될 때까지 반복.다익스트라 예제
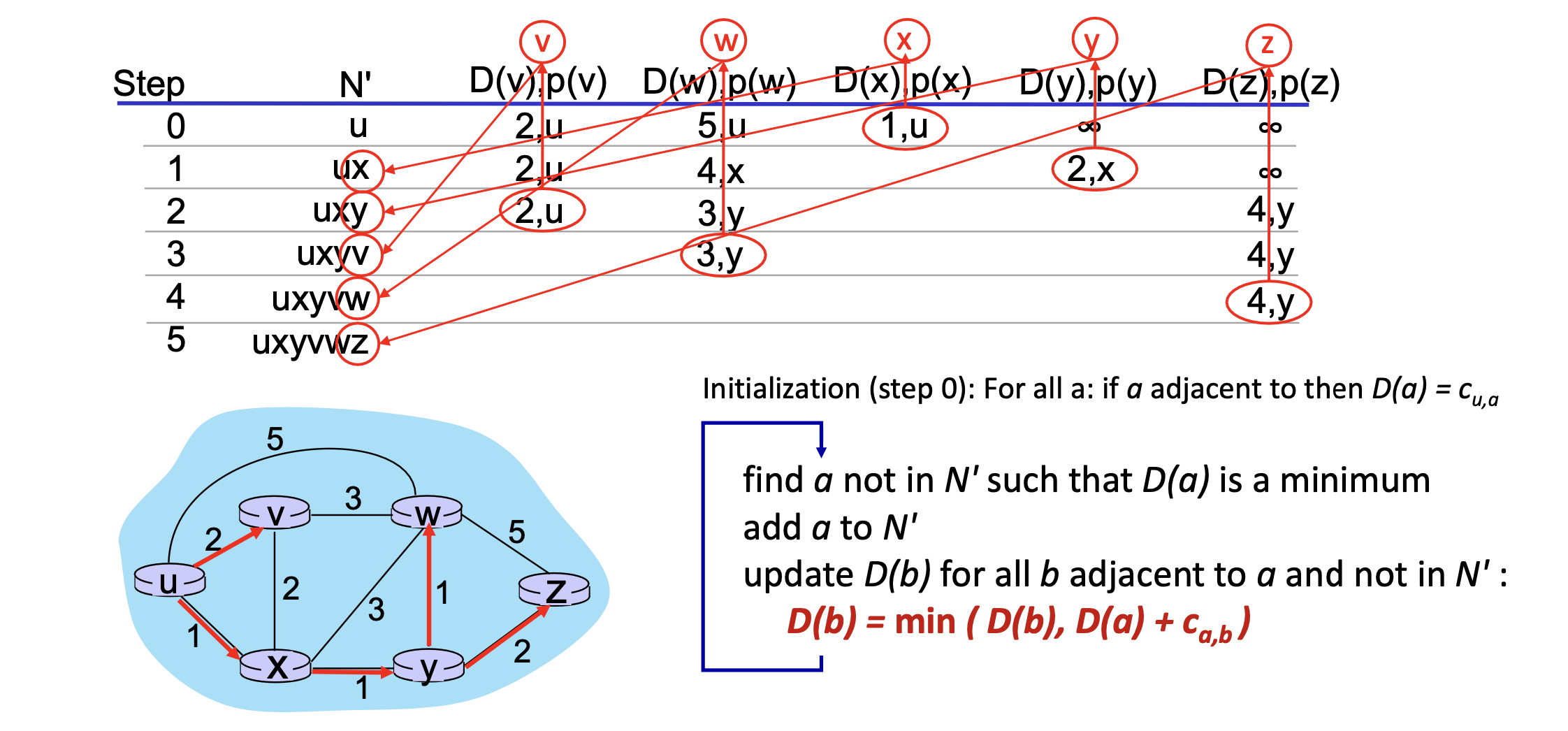
<0단계 (초기화)>
- N': 이미 처리된 노드 집합으로, 시작 노드인 u만 포함합니다.
- D(v): 각 노드 v에 대해 u에서의 최소 비용을 초기화합니다.
- D(x) = 1 (u와 x 간의 직접 경로 비용)
- D(y) = 2 (u와 y 간의 직접 경로 비용)
- D(w), D(v), D(z) = ∞ (직접 연결되지 않음)
- p(v): 최소 비용 경로의 이전 노드를 저장합니다. 초기에는 p(x) = u, p(y) = u.
<1단계>
- N': {u, x}
x는 D(x) = 1로, u에서 최소 비용인 노드이므로 선택.
- x의 인접 노드인 v와 w에 대해 D(v)와 D(w)를 업데이트:
- D(v) = min(∞, D(x) + c(x,v)) = 2 (1 + 2)
- D(w) = min(∞, D(x) + c(x,w)) = 4 (1 + 3)
- p(v) = x, p(w) = x로 경로 갱신.
<2단계>
- N': {u, x, y}
- y는 D(y) = 2로, 가장 작은 비용을 가진 노드이므로 선택.
- y의 인접 노드인 w와 z에 대해 D(w)와 D(z)를 업데이트:
- D(w) = min(4, D(y) + c(y,w)) = 3 (2 + 1)
- D(z) = min(∞, D(y) + c(y,z)) = 4 (2 + 2)
- p(w) = y, p(z) = y로 경로 갱신.
<3단계>
- N': {u, x, y, v}
- v는 D(v) = 2로, 가장 작은 비용을 가진 노드이므로 선택.
- v의 인접 노드인 w에 대해 업데이트:
- D(w) = min(3, D(v) + c(v,w)) = 3 (이미 최소값이므로 갱신 없음)
<4단계>
- N': {u, x, y, v, w}
- w는 D(w) = 3으로 선택.
- w의 인접 노드인 z에 대해 업데이트:
- D(z) = min(4, D(w) + c(w,z)) = 4 (3 + 1)
- p(z) = y 유지 (갱신 없음).
<5단계 (완료)>
- N': {u, x, y, v, w, z}
-모든 노드가 포함되었으므로 알고리즘 종료.
<결과>
최단 경로 비용 (D):
D(x) = 1, D(y) = 2, D(v) = 2, D(w) = 3, D(z) = 4
경로 (p):
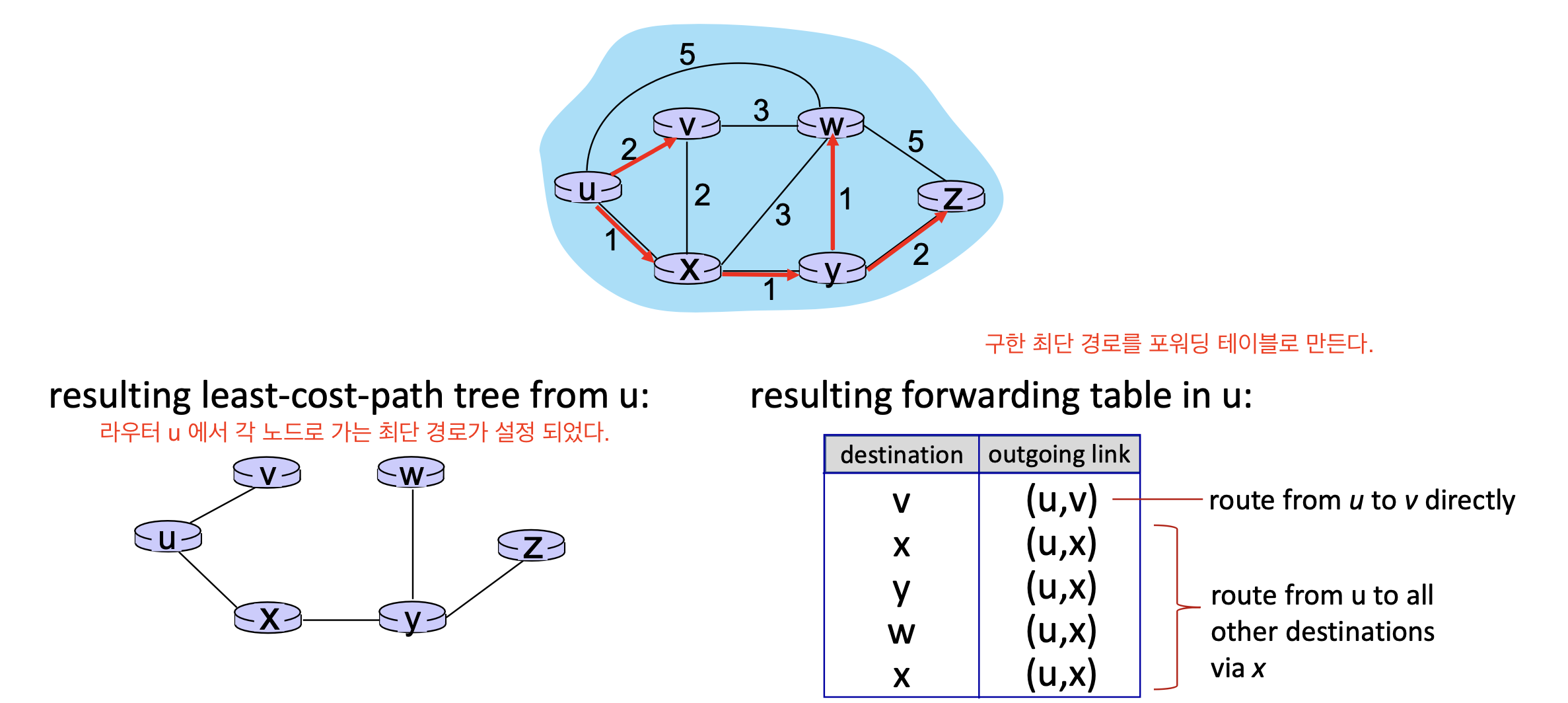
x는 u를 통해, y는 u를 통해, v는 x를 통해, w는 y를 통해, z는 y를 통해 연결됩니다.이렇게 구한 최단경로 그래프를 통해 포워딩 테이블을 생성한다.
다익스트라 알고리즘 복잡도 (n개의 노드)
-
첫번째 반복에서는 n개의 노드 전체의 비용을 검사한다.
-
두번째 반복에서는 n-1 , 세번째 반복에선 n-3... 이렇게 줄어드는 형태
-
따라서 찾아야 하는 노드의 총 수(검사해야 하는) = n(n+1)/2 이며,
O(n²)의 시간 복잡도를 갖는다. -
자료구조에 따라(힙.. 등등) O(NlogN)까지 개선할 수 있다.
메세지 복잡도
-
각 라우터는 자신의 링크의 상태정보를 n개의 라우터에
broadcast해야 한다. -
효율적인 브로드캐스트 알고리즘은 한 소스에서 브로드캐스트 메시지를 전파하기 위해 O(n) 개의 링크를 거친다.
(가장 효율적일때 n개의 노드만을 거쳐 상태정보를 다 전달할 수 있음) -
각 라우터의 메시지가 O(n) 개의 링크를 통과하므로, 전체 메시지 복잡도는 O(n²)
다익스트라 진동(oscillation) 문제
링크 비용이 트래픽 양에 따라 변동될 경우(다이나믹)
라우팅 경로가 지속적으로 변화하면서 진동 현상이 발생한다.
우리가 위에서 여지껏 살펴본 예제는 링크의 비용이 고정적일 때를 가정하였다.
하지만 트래픽에 따라 링크의 비용이 변화할 경우 라우팅 경로가 진동하는
(시시각각 변화하는) 문제가 발생한다.
예제
[전제 조건]
1. 목적지 a로의 라우팅을 고려.
2. 트래픽은 d, c, e에서 각각 1, e(<1), 1의 양으로 들어옴.
3. 링크 비용은 방향성이 있고, 트래픽의 양(volume)에 의존.1. 초기 상태
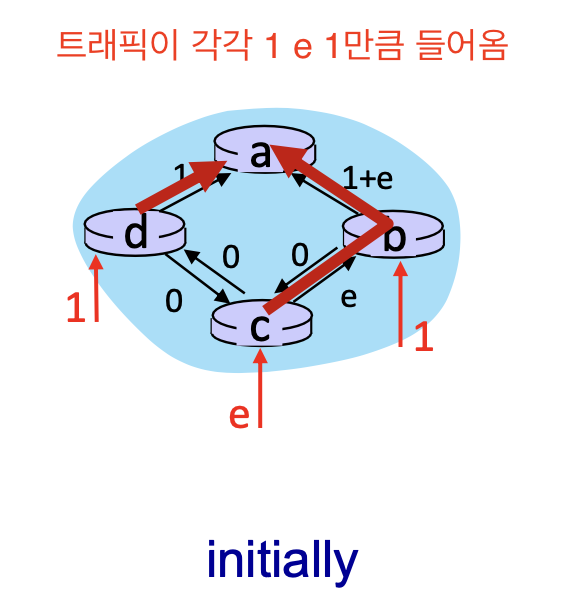
- a로 향하는 경로를 선택시 c->a d->a b->a는 최소 비용의 링크를 선택한다.
- 즉, 링크 상태 알고리즘이 수행되면 시계방향으로 경로를 선택하게 된다.
2. 초기상태에서 패킷이 전송되면
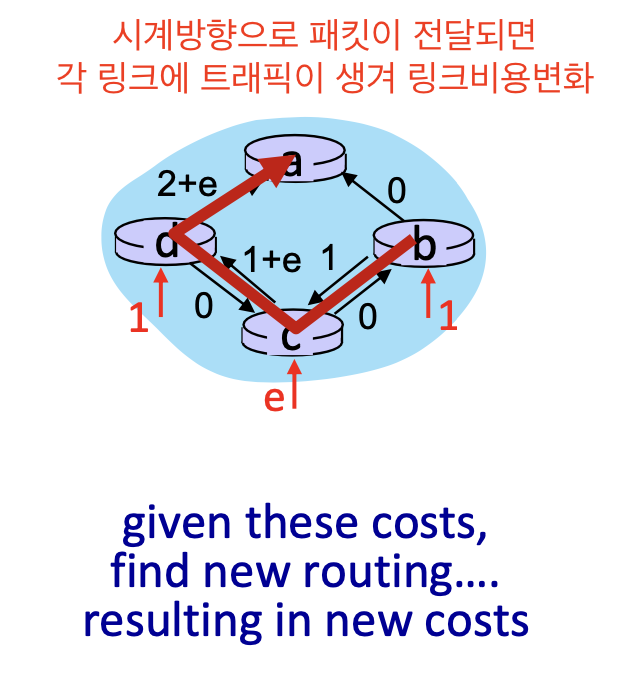
- 패킷이 전송되면 각 링크에 트래픽이 생겨 비용이 변경된다.
- 모두 시계방향으로 이동하였으니, 1 e+1 e+2 로 비용이 변한다.
- 링크의 비용이 변화하였으므로 링크 상태 알고리즘이 수행되면 반시계 방향으로 경로가 변화하게 된다.
3. 이러한 과정의 반복
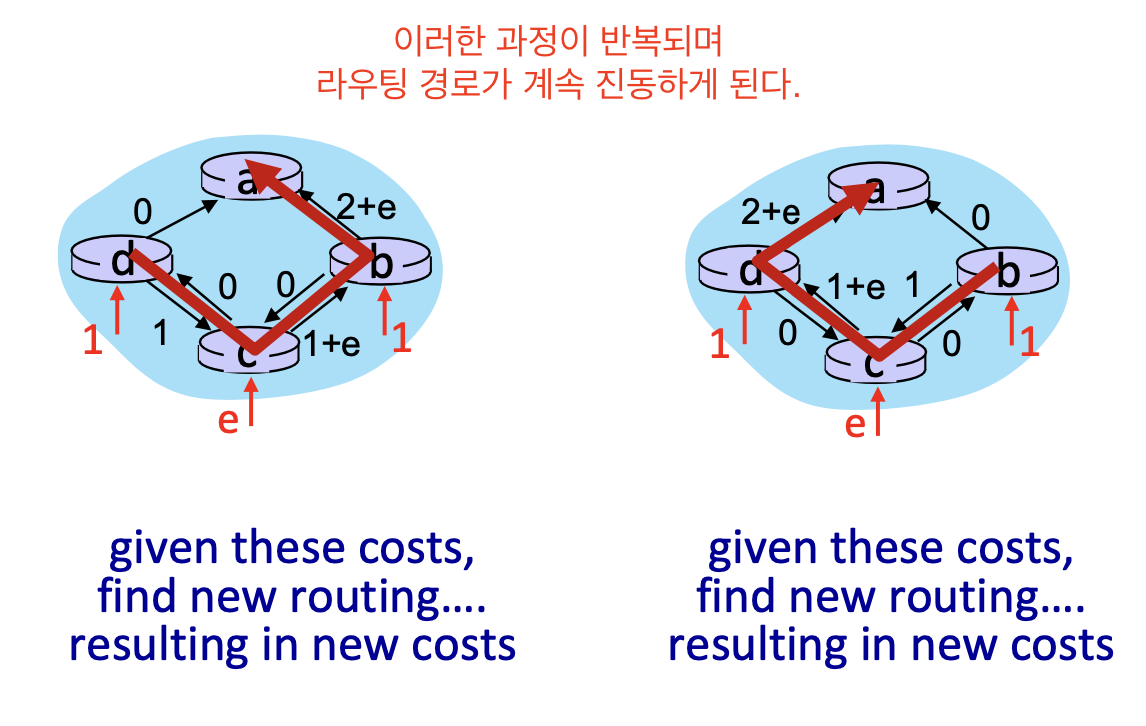
- 이렇게 반시계 시계 방향으로 링크 상태 알고리즘이 수행될 때마다
반대 방향으로 라우팅 경로가 변화하는 진동이 발생한다.
Distance Vector
link state와 달리 각 라우터는 자기 주변 라우터의 정보만 가지며,
각 라우터끼리 정보를 주고 받으며 라우팅 경로를 결정하는 알고리즘
Distance Vector 알고리즘은 반복적이고 비동기적이며 분산적이다.
분산적(distributed): 각 노드는 하나 이상의 직접 연결된 이웃으로부터 정보를 받고, 자체적으로 계산을 수행하며, 계산된 결과를 다시 이웃들에게 배포한다.반복적(iterative): 이웃끼리 더 이상 정보를 교환하지 않을 때까지 프로세스가 지속된다.비동기적(asynchronous): 모든 노드가 서로 정확히 맞물려 동작할 필요가 없다. ()
DV의 기본적인 작동원리
- 각 라우터는 목적지까지의 최단 거리와 방향(다음 홉) 정보를 담은 테이블(디스턴스 벡터 테이블)을 유지한다.
- 주기적으로 자신의 디스턴스 벡터 정보를 이웃 라우터와 교환한다.
- 벨만-포드 알고리즘을 기반으로, 이웃에서 받은 정보와 자신의 경로 정보를 비교하여 테이블을 업데이트한다.
벨만-포드 알고리즘
한 노드에서 다른 모든 노드로의 최단 경로를 찾는 알고리즘

-
X -> Y의 최단 경로의 계산은, X의 모든 이웃 노드 V에 대해
1. X->V로 가는 cost
2. V->Y로 가는 최소 cost (DV)
1+2 의 합을 계산하여 그 중 최소값을 갖는 경로를 최단 경로로 결정한다. -
x에서의 DV란?
➡️ x 에서 네트워크 상의 모든 다른 노드까지의 최소 비용을 예측한 값들의 집합
1. 간단한 예시
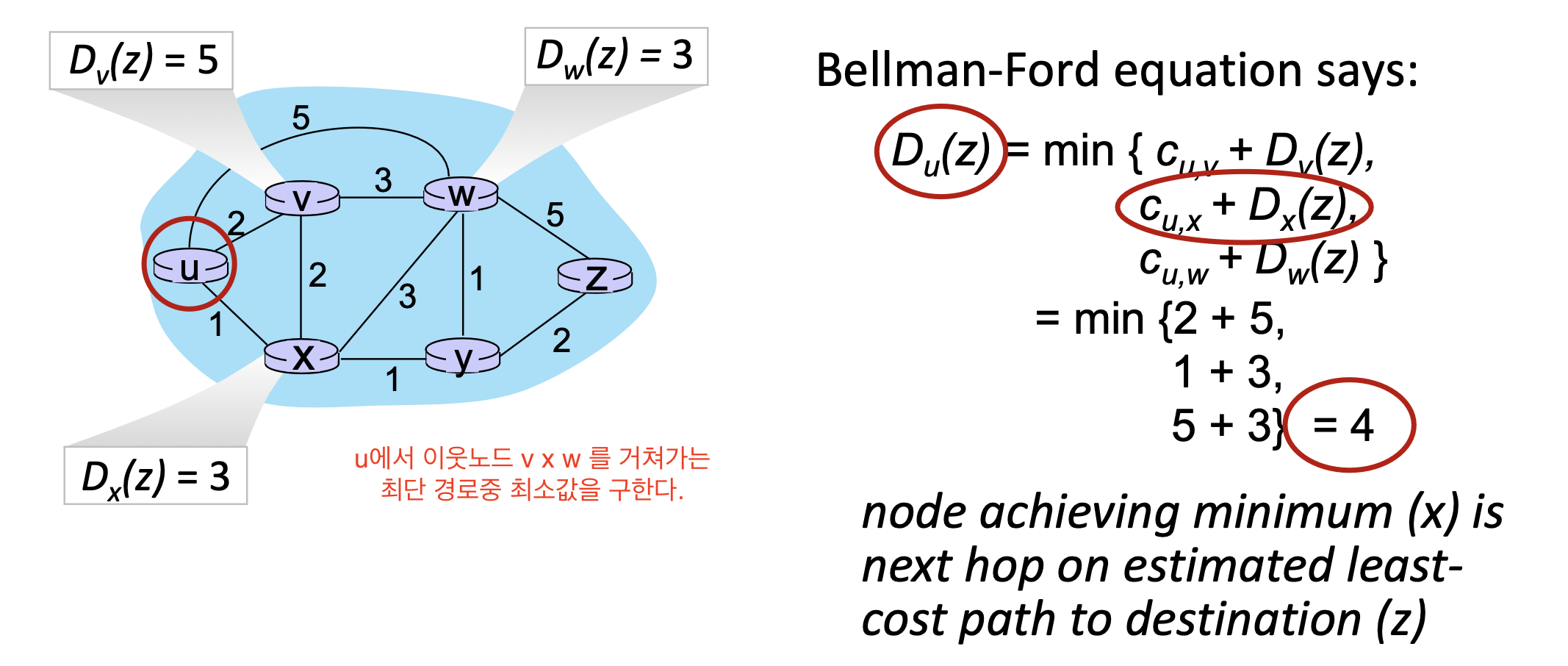
- 위의 예시는 각 이웃노드 v x w가 y로의 DV가 고정되어 있기 때문에 간단히 답을 구할 수 있다.
DV 알고리즘 원리
-
주기적인 Distance Vector 전송- 각 노드(node)는 주기적으로 자신의 Distance Vector(DV) 값을 이웃 노드(neighbor)들에게 전송한다.
-
Distance Vector 업데이트- 노드 x 가 이웃 노드 v 로부터 새로운 DV 값을 받으면, 이를 이용해 자신의 DV를 업데이트합니다.
-
업데이트: 벨만포드 알고리즘- x 는 이웃 노드 v 를 경유할 때의 비용을 계산하고,
이를 통해 최소 거리를 선택하여 자신의 Distance Vector를 갱신한다.
- x 는 이웃 노드 v 를 경유할 때의 비용을 계산하고,
-
수렴(Convergence)- D_x(y) 값은 실제 최소 비용 d_x(y) 로 수렴하게 된다.
- 이 과정은 네트워크에서 모든 노드가 동기화되고, 각 노드의 DV가 정확한 최소 비용 경로 정보를 가지게 될 때까지 계속
- 즉 수렴이란, 각 노드의 Distance Vector가 더 이상 변경되지 않는 안정된 상태에 도달하는 것을 말한다.
<수렴과정>
1. 초기 상태:
• 각 노드는 직접 연결된 이웃 노드에 대한 비용만 알고 있으며, 다른 노드들에 대한 비용은 **무한대 ( \infty )**로 시작합니다.
2. 업데이트 반복:
• 각 노드는 주기적으로 이웃 노드들로부터 받은 D_v(y) 값을 기반으로 자신의 D_x(y) 를 갱신합니다.
• D_x(y) \gets \min_{v} \{ c_{x,v} + D_v(y) \} 방정식을 사용하여 비용이 더 낮은 경로를 찾습니다.
3. 정보 전파:
• 네트워크의 모든 노드가 자신의 Distance Vector를 이웃 노드들과 교환하면서 점차 정확한 비용을 계산합니다.
4. 수렴 상태:
• 반복이 진행되면서 모든 노드의 D_x(y) 값이 더 이상 변하지 않게 됩니다.
• 이 상태에서는 D_x(y) 값이 실제 최소 비용 d_x(y) 와 같아집니다.
특징1. 반복적이고 비동기적이다
각 라우터가 자신의 변경사항을 전달하고 또 다시 계산하고 전달하고...
를 반복하며 비동기적으로 경로를 탐색한다.
반복적(iterative): 이웃끼리 더 이상 정보를 교환하지 않을 때까지 프로세스가 지속된다.비동기적(asynchronous): 모든 노드가 서로 정확히 맞물려 동작할 필요가 없다.
각각의 로컬 반복은 다음의 이유에서 발생한다.
1. 로컬링크의 비용 변화
2. 이웃 노드의 DV 변화 메세지를 수신
특징2. 분산되고 self-stopping
분산적(distributed): 각 노드는 하나 이상의 직접 연결된 이웃으로부터 정보를 받고, 계산을 수행하며, 계산된 결과를 다시 이웃들에게 배포한다.self-stopping: 반복하다 어느순간 자기 경로가 업데이트 되지 않으면
이웃노드에 변경사항을 알리는 것을 멈추게 되어 스스로 반복을 멈추게 된다.
이렇게 수렴이 되면(update X)이 때가 최단 경로 이고 결정된 경로로 테이블을 만든다.
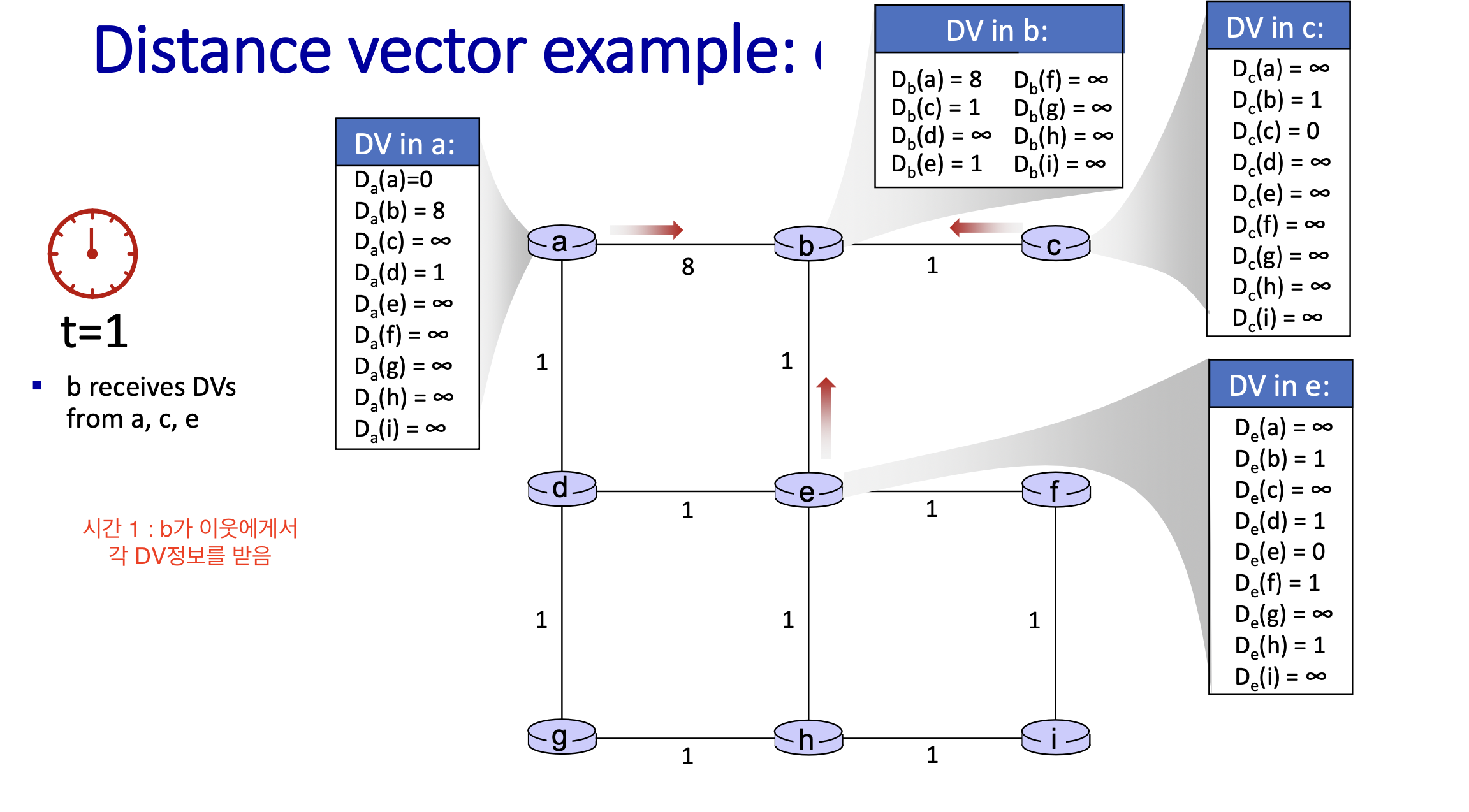
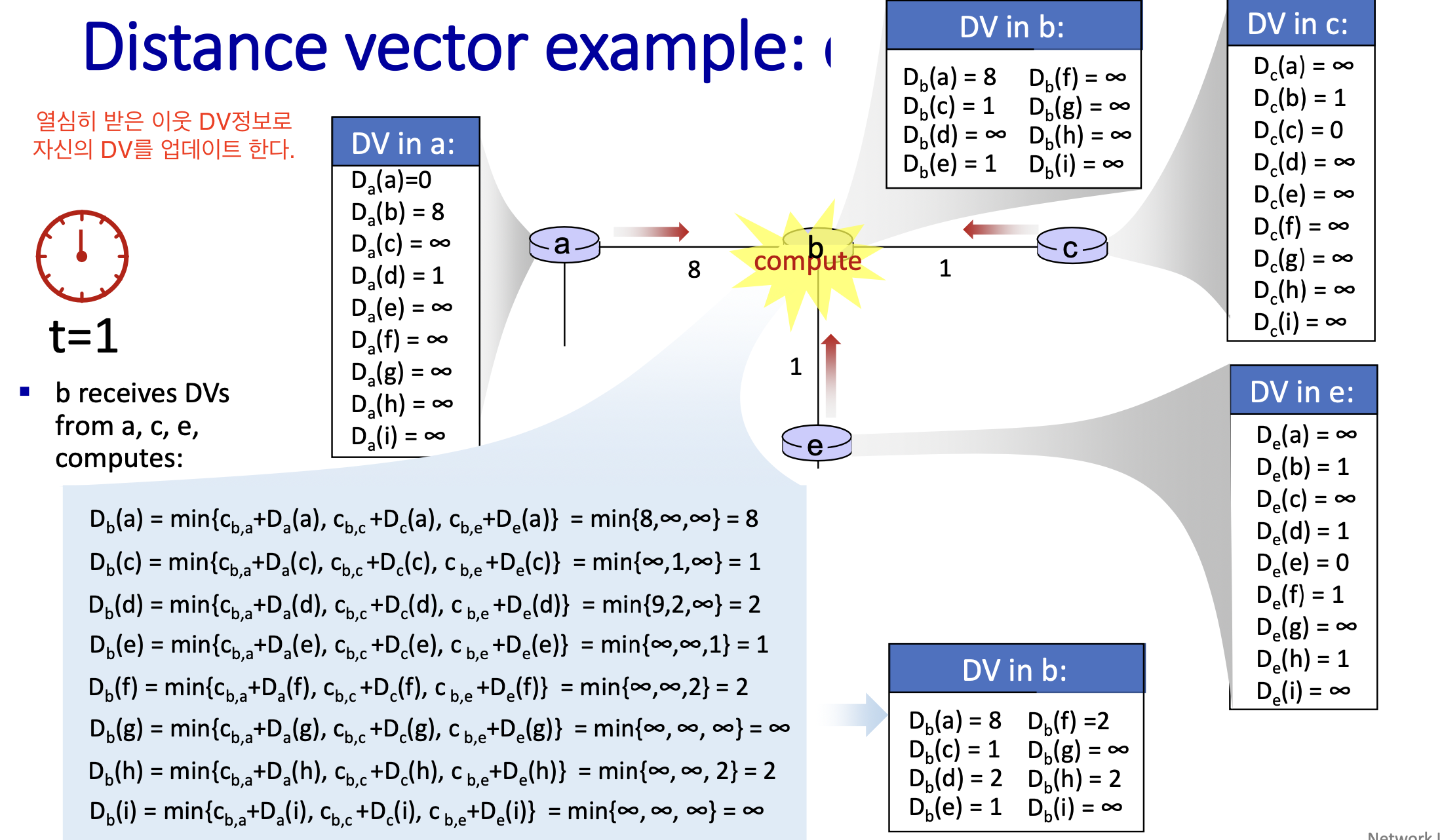
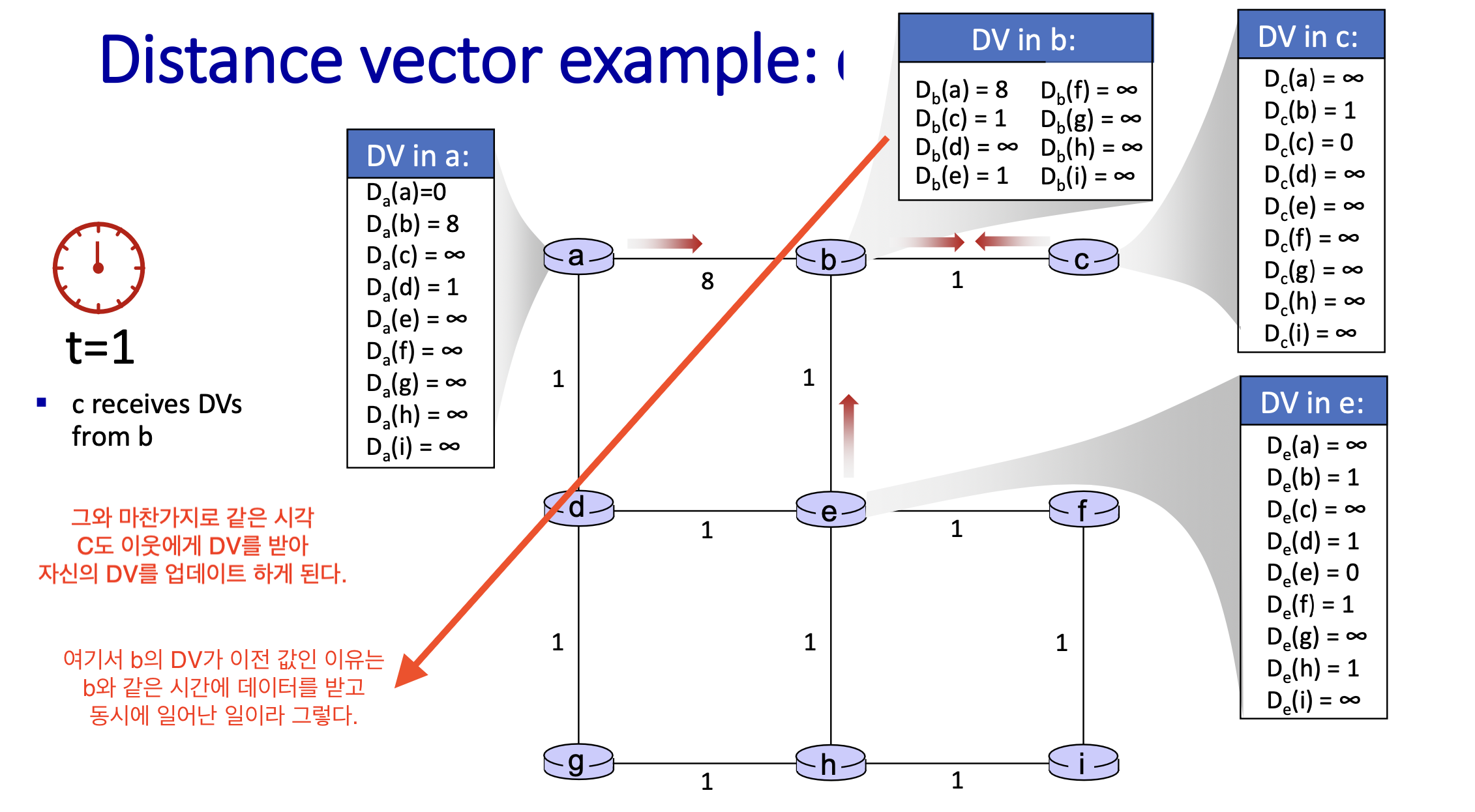
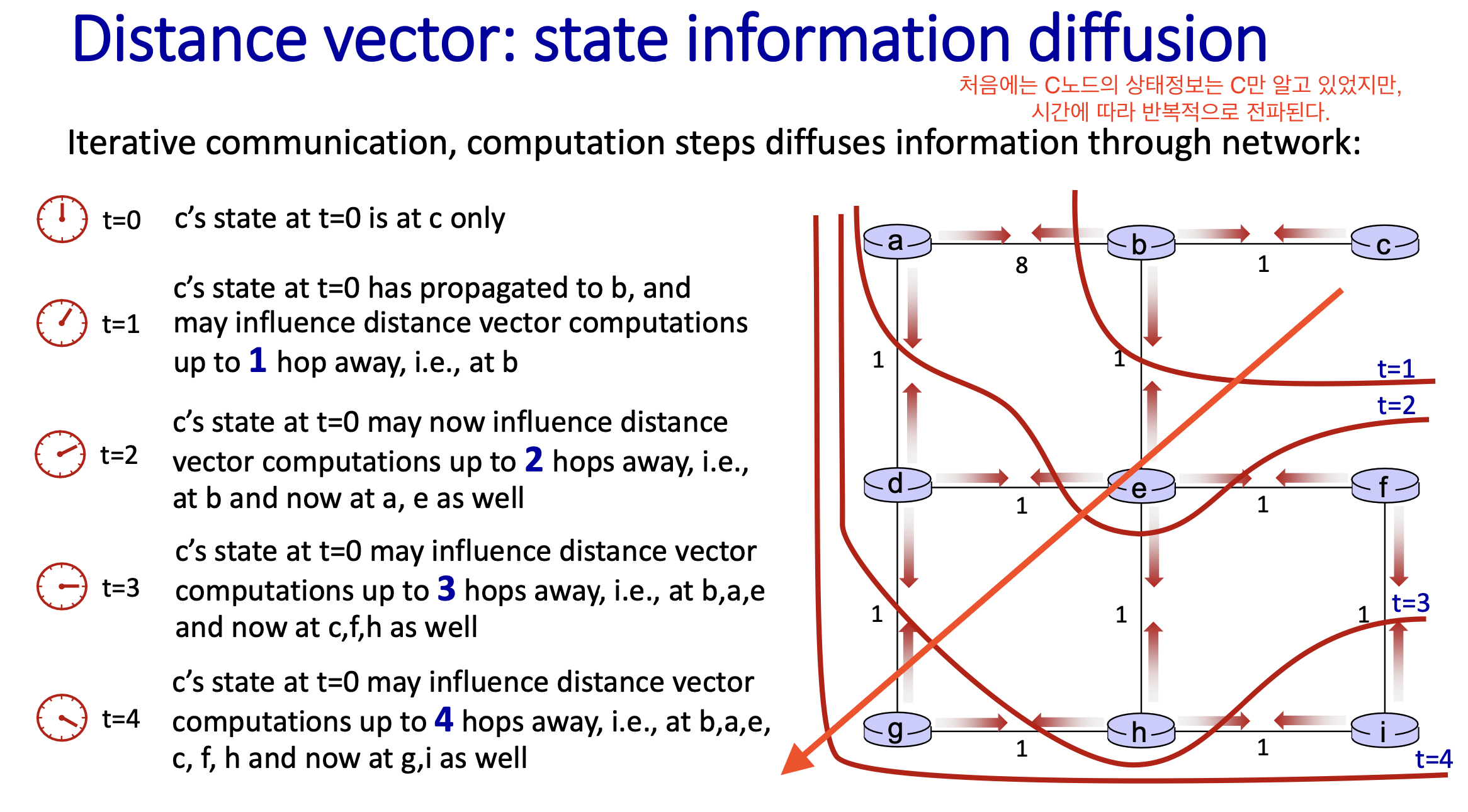
상태 정보의 확산
Distance Vector Algorithm은 반복적 통신(iterative communication)을 통해 정보를 교환하는데, 이 때 상태 정보가 주변 노드로 점진적으로 확신이 된다.
Iterative Communication:
- Distance Vector Algorithm은 반복적 통신(iterative communication)을 통해 정보를 교환한다.
- 노드 c 의 상태 정보가 주변 노드로 하나씩 확산(diffusion)되며, 점차적으로 네트워크 전체로 퍼진다.
- 각 시간 단계에서 정보는 한 홉(hop)씩 더 멀리 전파된다.
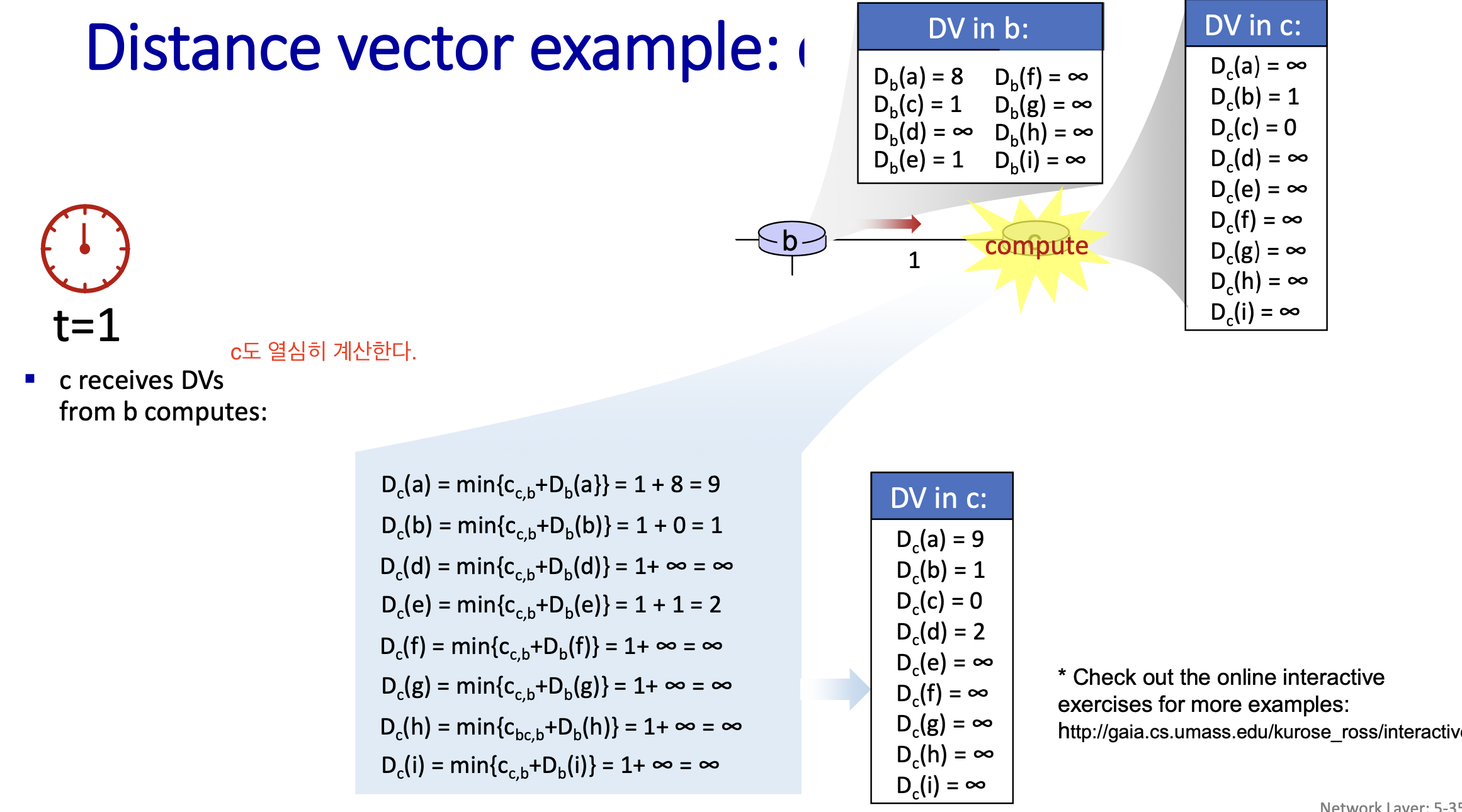
DV는 자신과 다이렉트하게 연결된 노드랑만 정보교환을 하지만,
시간이 지남에 따라 점점 확산된 정보를 얻어 전체 cost를 알 수 있다.
DV에서 링크 cost의 변화
링크의 cost가 변화하게 되면...
- 노드는 로컬링크(인접링크)의 비용변화를 감지
- 라우팅 인포를 업데이트하고, 자신의 DV를 다시 계산한다.
- 만약 DV가 변화했다면 이웃에게 알린다.
때문에 모든 노드들이 연쇄적으로 값의 변화가 없을 때 까지 자신의 DV를 다시 계산하게 된다.
예제1. - 빠른 시간 내에 수렴을 하는 경우
x-y사이의 링크 코스트가 1로 바뀐 상황이다.


- 시각 t0에서 노드Y는 링크 코스트의 변화를 감지한다.
- 따라서 노드Y는 Dy(x)를 다시 계산한 결과 4에서 1로 변화하였다.
- 이에 따라 변화내용을 Z노드에 전달한다.
- Z노드는 자신의 DV를 다시 계산한 후 바뀐 Dz(x)값 2를 다시 Y에게 전달한다.
- Y는 다시 DV를 계산 -> 변화가 없으므로 모든 노드는 갱신을 멈춘다.
예제2. - 수렴하는데 많은 계산이 필요한 경우
x-y사이의 링크 코스트가 60로 바뀐 상황이다.


-
시각 t0에서 노드Y는 링크 코스트의 변화를 감지한다.
-
따라서 노드Y는 Dy(x)를 다시 계산한 결과 4에서 6로 변화하였다.
-
이에 따라 변화내용을 Z노드에 전달한다.
-
Z노드는 자신의 DV를 다시 계산한 후 바뀐 Dz(x)값 7를 다시 Y에게 전달한다.
-
따라서 노드Y는 Dy(x)를 다시 계산하여 Z에 전달
...... 반복Dz(x)값이 50 이상이 되어 값이 바뀌지 않을 때 까지 위의 과정을 반복할 것이다.
➡️Count To Infinity문제 발생
Link state와 Distance Vector 비교
1. 메세지 복잡도
네트워크 전체에서 교환되는 메시지의 수
-
링크 상태 알고리즘 (LS)- O(n²)- 네트워크의 라우터가 n개라면, 각 라우터는 모든 라우터와 연결된 링크 상태 정보를 알고 있어야 한다.
- 이를 위해 각 라우터는 링크 상태 패킷(LSP)을 네트워크 전체에 전달해야 하므로, 메시지의 양은 O(n²)에 비례한다.
-
거리 벡터 알고리즘 (DV)- 수렴 시간에 따라 메시지 수 비례- 수렴하는 속도에 따라서 교환하는 메세지의 수가 비례하기 때문에,
수렴 시간에의해 복잡도가 결정된다 - 각 라우터는 모든 라우터와 연결된 링크 상태 정보를 정보의 교환을 통해 알고 있다 하더라도 수렴속도에 따라 메세지 수가 달라진다.
- 수렴하는 속도에 따라서 교환하는 메세지의 수가 비례하기 때문에,
2. 수렴 속도 Speed of Convergence
-
링크 상태 알고리즘 (LS)- O(n²)- 네트워크에서 모든 링크 상태를 업데이트한 후, 다익스트라 알고리즘을 실행해 최단 경로를 계산한다.
- LS는 이론적으로 빠르게 수렴할 수 있지만,
네트워크 크기(라우터 수 N)에 따라 계산량이 증가합니다. - 진동(oscillation) 문제가 발생할 수 있습니다.
(예: 혼잡도에 따라 라우터의 링크 비용이 변동이 심한 경우)
-
거리 벡터 알고리즘 (DV)- 상황에 따라 다름(다소 느리다)- DV는 수렴 속도가 네트워크 크기와 토폴로지에 따라 다르다.
- 라우팅 루프(routing loops) 또는
무한대로 증가하는 경로 비용(count-to-infinity) 문제발생 가능.
Q. 라우팅 루프란?
네트워크에서 특정 목적지로 가는 패킷이
두 개 이상의 라우터 간에 무한히 반복 전송되는 문제를 의미합니다.
이로 인해 데이터가 목적지에 도달하지 못하고 네트워크의 대역폭이 소모되며,
성능에 심각한 영향을 줄 수 있습니다.3. 견고성 Robustness
어느 한 링크의 고장 혹은 잘못된 cost가 전달될 시 받는 영향
-
링크 상태 알고리즘 (LS)- 각 라우터는 자신의 링크 상태만 네트워크에 전송하며,
이를 기반으로 독립적으로 경로를 계산한다 - 만약 하나의 라우터가 잘못된 정보를 전송한다면,
해당 라우터의 링크 상태만 잘못된 계산에 영향을 미친다
(LS는 잘못된 정보의 영향을 국소적으로 제한.)
- 각 라우터는 자신의 링크 상태만 네트워크에 전송하며,
-
거리 벡터 알고리즘 (DV)- 각 라우터가 자신의 테이블 정보를 이웃에 전송하고,
이를 바탕으로 다른 라우터들이 경로를 계산합니다. - 만약 하나의 라우터가 잘못된 경로 비용 정보를 전달한다면, 네트워크 전체로 잘못된 정보가 전파될 수 있다.
- 이는
Black-holing(데이터 손실)문제를 유발 - 잘못된 정보가 네트워크 전체로 퍼지므로,
타격이 매우 크고 회복에 시간이 오래 걸릴 수 있다.
- 각 라우터가 자신의 테이블 정보를 이웃에 전송하고,
4. 결론
- LS의 장점:
• 수렴이 빠르고, 잘못된 정보의 영향이 적다.
• 그러나 메시지 복잡도와 계산량이 커서 큰 네트워크에서는 비효율적일 수 있다. - DV의 장점:
• 이웃 간의 정보 교환만 필요하므로 메시지 전달 오버헤드가 상대적으로 적다.
• 그러나 라우팅 루프, count-to-infinity 문제로 인해 수렴 속도가 느릴 수 있으며, 잘못된 정보의 영향이 넓게 퍼질 가능성이 있다.
| 특징 | Link State (LS) | Distance Vector (DV) |
|---|---|---|
| 메시지 복잡도 | ( O(n^2) ): 모든 라우터가 네트워크 전체로 정보를 전파 | 이웃 간 정보 교환에 따라 메시지 수가 달라짐 |
| 수렴 속도 | 빠름: 네트워크 전체 정보를 사용하여 계산 | 느릴 수 있음: 루프나 count-to-infinity 문제 발생 가능 |
| 라우팅 루프 발생 가능성 | 낮음: 전체 네트워크 상태를 고려해 계산하므로 루프 거의 없음 | 높음: 잘못된 정보가 네트워크에 전파되면서 루프 발생 가능 |
| 견고성 | 잘못된 링크 비용 정보는 국소적 영향을 미침 | 잘못된 경로 정보는 전체 네트워크에 전파될 수 있음 |
| 계산 방식 | 다익스트라 알고리즘을 사용해 최단 경로 계산 | 이웃 노드로부터 받은 경로 비용 정보를 사용 |
| 정보 교환 대상 | 모든 라우터 (네트워크 전체에 홍수 방식으로 전송) | 직접 연결된 이웃 라우터와 정보 교환 |
| 장점 | 수렴 속도가 빠르고 네트워크 전체 정보를 알 수 있음 | 메시지 전송 오버헤드가 적고 계산이 간단함 |
| 단점 | 메시지 복잡도와 계산량이 크며, 네트워크 크기에 민감함 | 수렴 속도가 느리고 루프 문제로 인해 네트워크 혼잡 발생 가능 |
| 주요 문제 | 링크 상태의 변화에 따라 진동(oscillation) 가능 | count-to-infinity, 라우팅 루프 등 |
| 사용 예시 | OSPF(Open Shortest Path First), IS-IS | RIP(Routing Information Protocol), BGP |
