[Deep Residual Learning for Image Recognition] 논문(https://arxiv.org/pdf/1512.03385.pdf)을 읽고 정리한 내용입니다. 내용에 오류가 있다면 지적 부탁드립니다.
논문 정리에 앞서, 오차와 잔차의 차이를 짚고 넘어가자.
모집단의 회귀식을 통해 얻은 예측값과 실제 관측값의 차이를 오차,
표본집단의 회귀식을 통해 얻은 예측값과 실제 관측값의 차이가 잔차라고 한다.
0. Abstract
ResNet은 Deeper neural networks일수록 학습이 더 어려워진다는 문제점을 해결하기 위해 고안되었다. 본 논문에서는 기존에 사용되어 왔던 것보다 실질적으로 더 깊은 네트워크의 훈련을 용이하게 하기 위해 residual training 프레임워크를 제안한다. ResNet이라 칭하는 본 논문의 심층 신경망은 참조되지 않은 함수를 학습하는 대신 layer 입력을 참조하여 residual function을 배우는 것으로 레이어를 재구성하고 있다. ResNet은 152 layer로 구성되어있으며, VGG net보다 8배 더 깊은 depth를 가진다. ILSVRC 2015 image classification 분야에서 ImageNet dataset을 학습하고 평가하여 3.57% top-5 test error를 기록하며 1위를 차지하였다. 이외에도 CIFAR-10, COCO detection, segmentation 부문에서 1위를 차지하며 좋은 성능을 보이고 있다. 이햐 멋져!
1. Introduction
Is learning better networks as easy as stacking more layers?
Deep convolutional neural networks는 image classification 분야에서 획기적인 발전을 보여준다. 최근까지의 네트워크들은 depth가 중요한 요소로 여겨졌고, depth가 더 깊은 모델일수록 좋은 성능이 나온다고 보여졌다. 하지만 네트워크의 depth가 깊어질 때 Degradation 문제가 발생한다.
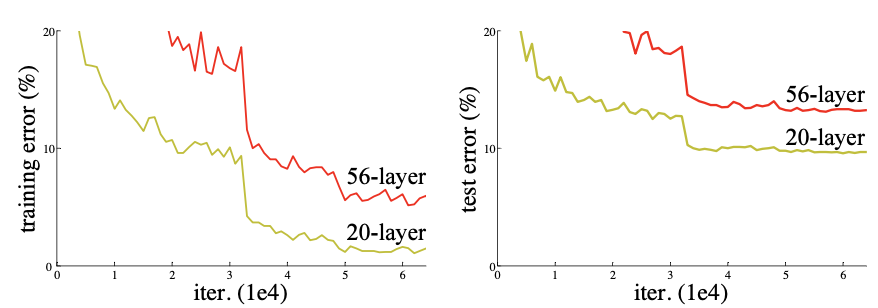
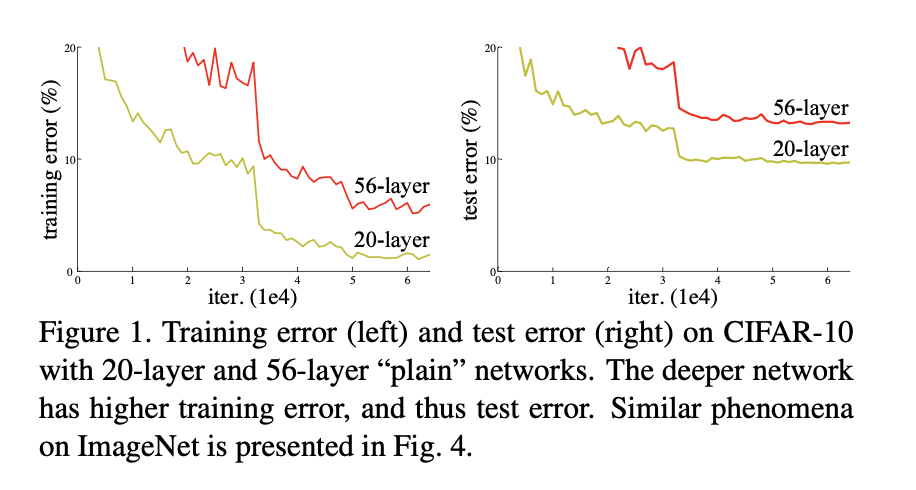
Figure 1. Training error (left) and test error (right) on CIFAR-10 with 20-layer and 56-layer “plain” networks. The deeper network has higher training error, and thus test error. Similar phenomena on ImageNet is presented in Fig. 4.
Degradation 문제
네트워크를 깊게 만들면 vanishing/exploding gradients 문제때문에 depth가 증가할지라도 어느정도 한계에 이르면 성능이 떨어지는 degradation현상을 보인다. 이는 네트워크의 depth가 증가함에 따라 정확도는 포화 상태로 급격히 떨어져 더 이상 증가하지 않는 것이다. 이러한 성능저하(degradation)는 오버피팅으로 인한 것이 아니며, deep model에 더 많은 layer를 추가할 때 발생한다. (오버피팅이라면 deep한 layer의 train accuracy는 높아야 하는데, 20 layer보다 56 layer가 train/test error 모두 낮다. 오버피팅: testing data 성능에 대한 문제 | degradation: training data에 대한 성능 문제라고 할 수 있겠다.)
Training accuracy의 degradation 문제는 모든 시스템이 비슷하게 optimize되기 어렵다는 것을 나타낸다. 논문에서는 이 degradation 문제를 더 깊은 레이어가 쌓일수록 구조의 optimize가 어려워지기 때문에 발생하는 문제로 보고 해결하기 위한 구조를 제시한다.
+) vanishing gradient
기울기 값이 소실되는 문제는 인공 신경망에서 기울기값을 베이스로 하는 backpropagation으로 학습 시키려고 할 때 발생된다. 이 문제는 신경망 구조에서 레이어가 늘어날수록 악화되며, 신경망에서 앞쪽 레이어의 파라미터를 학습시키고 튜닝하기 어렵게 만든다.
Residual learning
기존 인공신경망에서는 input(x)를 target(y)로 맵핑하는 함수 H(x)를 찾는 것이 학습 목적이라고 한다면, H(x)-y를 최소화하는 방향으로 학습을 진행하였다. 본 논문에서 ResNet은 네트워크가 H(x)-x를 얻는 것을 목표로 함을 제시한다. 입력과 출력의 잔차를 F(x) = H(x) - x라 정의하고, 네트워크는 F(x)를 찾도록 하는 것이다. 여기서 F(x)가 잔차이고, 네트워크가 이 잔차를 학습하는 것을 residual lerning이라 한다. (F(x)는 Conv block에서 나온 output)
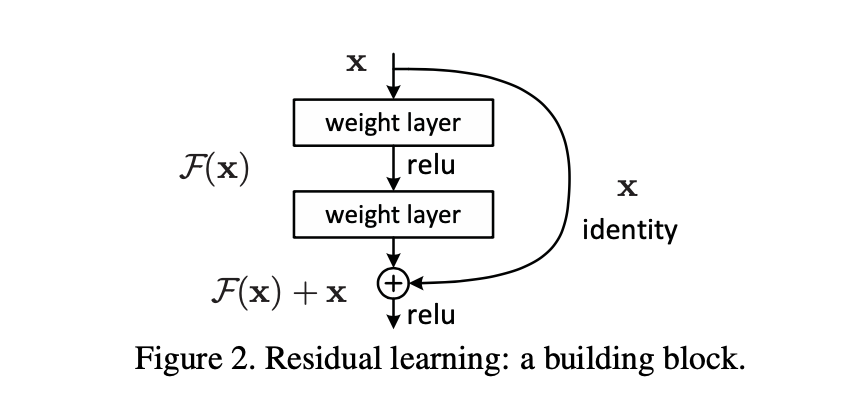
H(x) = F(x) + x
입력 x는 F(x) 모델을 거쳐, indentity mapping을 통해 x가 더해져 F(x)+x가 출력된다.
이를 shotcut connection이라 부른다.
shortcut connection을 통한 identity mapping의 경우, 차원이 같을 경우와 다를 경우의 수식은 각각 다음과 같다.
y = F(x) + x
y = F(x) + Ws * x // Ws projection matrix를 곱하여 차원을 같게 만듦
추가할 예정 !
