
Information Theory
정보 이론은 콜로드 섀년에 제안한 개념으로 정보를 구체화/수치화한 것으로, 드물게 일어나는 사건일수록 자주 일어나는 사건에 비해 더 많은 정보를 담고 있다는 이론이다. 정보 이론은 최적의 코드를 디자인하고, 메세지의 기대 길이를 계산하는데 도움이 된다. 머신러닝에서는 해당 확률분표의 특성을 알아내거나 확률 분포간의 유사성을 정량화하는데 사용된다. 이 이론의 핵심은 자주 일어나는 사건은 의미가 별로 없지만, 드물게 일어날수록 의미가 커지고 정보량이 많다는 것이다.
이 이론을 수학적으로 살펴보면,
- 드물게 발생하는 사건일 경우, 빈번하게 일어나는 사건보다 더 많은 정보량을 가진다고 고려한다.
- 자주 일어나는 사건일수록 더 적은 정보량을 가진다. 무조건 일어나는 사건 (= 확률이 1일 경우)은 정보량이 0이다.
- 독립 사건은 추가적인 정보량(additive information)을 가진다. 동전을 던져 앞면이 2번 나오는 사건에 대한 정보량은 동전을 던져 앞면이 한 번 나오는 정보량의 2배이다.
정보가 위와 같은 속성을 지니기 때문에 결국 확률에 종속적이 된다. 정보의 양을 h(x)라고 정의하면, 정보는 결국 확률 함수의 조합으로 표현이 될 것이다.
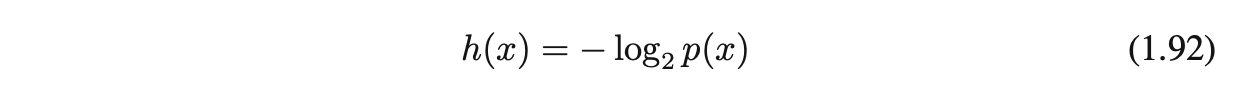
정보의 양을 나타내는 함수 h(x)는 확률 함수 p(x)의 음의 로그 값으로 볼 수 있다.
정보의 값은 0 이상이여야 하므로, 0~1 사이의 확률 값에 로그를 붙이는 경우 앞에 음수가 붙어야 한다.
로그의 base = 2를 사용, 이 경우 h(x)의 기본 단위가 bit라고 생각하면 된다.
Entropy
엔트로피는 정보의 단위라고 할 수 있다. 어떤 분포 p(x)에서 생성되는 discrete random variable x가 있다고 할 때, x가 전달 가능한 정보량을 어떻게 정량화할 수 있을까. 여기서 정보란, 학습에 있어 필요한 놀람의 정보(degree of surprise), 얼만큼의 bit가 있어야 x에 대한 완벽한 정보를 얻을 수 있는지로 보면 되겠다.
앞면과 뒷면이 나올 확률이 동일한 코인을 던졌을 때, 엔트로피는 앞면/뒷면 두 가지 경우만 생각하면 되므로 1이 된다. 반면, 확률이 동일하지 않은 코인을 던졌을 경우는 특정 면이 나올 확률이 다른 면이 나올 확률보다 상대적으로 더 크기 때문에 1보다 더 적은 정보를 사용하여 값을 맞추는 것이 가능해진다. 엔트로피는 불확실성이 높아질수록 커지며, 정보의 양이 많아진다. 엔트로피는 평균 정보량을 의미하며, p(x)인 distribution에서 h(x) 함수의 기댓값을 의미한다.
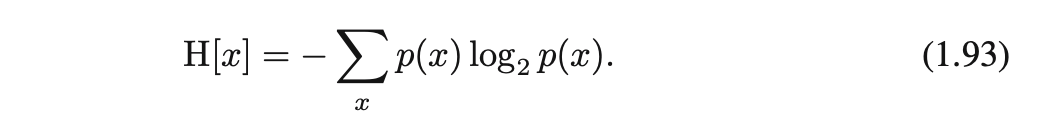
만약 p(x)가 0으로 가면 log2p(x)는 음의 무한으로 발산하게 되지만, p(x)가 0이 되는 속도가 더 빠르기 때문에 0이 된다.
Uniform distribution
각각의 random variable x가 1/8의 확률을 갖는 경우, 하나의 data x를 전송하기 위해 필요한 평균 bit는 3이다.
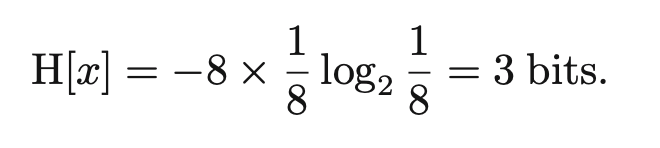
현재 확률 분포가 uniform 분포를 따르게 되므로 실제 데이터를 표현할 때 동일한 정보량을 갖는 형태로 표현된다.
bit 단위로 정보량을 표현하므로 임의의 데이터 1개를 전송하기 위한 평균 bit량은 3이라는 의미이다.
Non-Uniform distribution
각각의 경우가 발현될 확률이 (1/2, 1/4, 1/8, 1/16, 1/64, 1/64, 1/64, 1/64) 일 경우, 필요한 bit 수는 2가 된다.
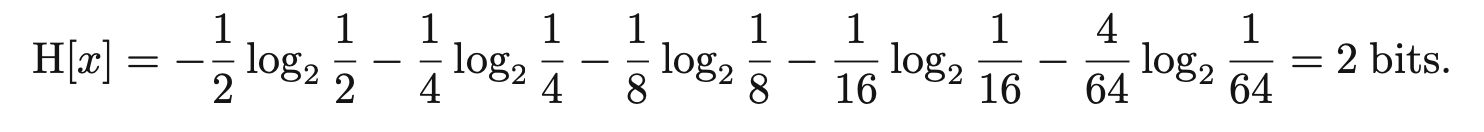
발현 빈도가 높은 데이터는 더 짧은 bit를 가지는 데이터로 표현하여 전체 전송량을 줄일 수 있게 된다.
결국 Non-uniform distribution의 엔트로피가 uniform distribution의 엔트로피보다 낮다.
Other Example
a, b, c, d, e, f, g, h 데이터를 전송하고자 한다.
이때, non-uniform 분포를 고려하여 각각의 인코딩 코드를 0, 10, 110, 1110, 111100, 111101, 1111110, 111111으로 만든다. 이렇게 하면 코드를 만드는 평균 길이는 아래와 같이 계산 가능하다.
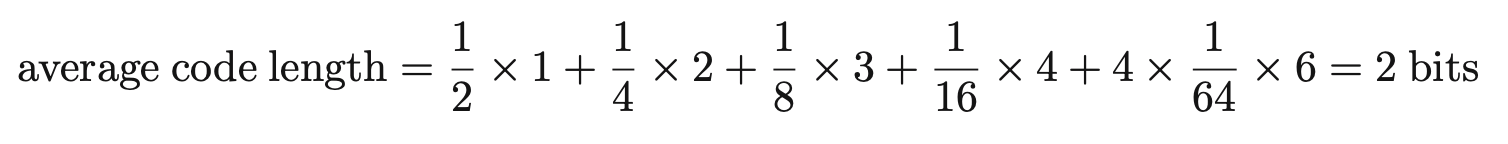
앞서 구했던 H(x)와 동일한 결과를 얻는다.
Multiplicity
전체 N개의 object들이 있고, 이 object들이 k개의 bin으로 나뉘어진다 할 때, N개의 물체가 i번째 bin에 들어갈 수 있는 object의 갯수를 ni라고 한다. 전체 bin 영역에 N개의 물체가 무작위로 놓여있다고 할 때, 총 나타날 수 있는 가지 수는 N!이 된다. (N개의 집합에서 N개를 뽑는 순열과 같다. N!) 이때, 같은 bin에 들어간 물체들은 어디에 속해있느냐가 중요한게 아니라 갯수에만 의미가 있다. (즉, object가 일부 바뀌더라도 갯수만 유지되면 상관 없음)
object들이 bin에 들어갈 수 있는 permutation의 갯수는 다음과 같이 나타내며, multiplicity라고 한다.
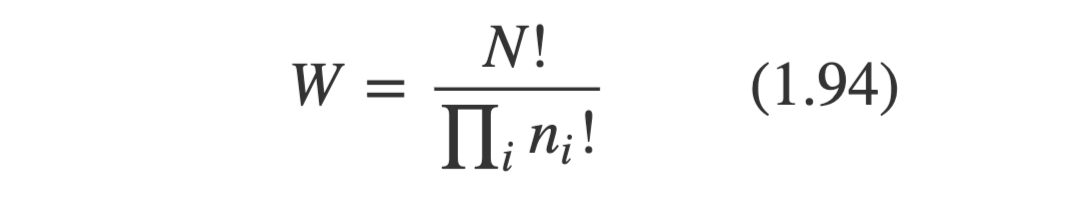
엔트로피란 multiplicity에 log를 취한 값을 의미한다. 즉 entropy H는 mulitiplicity W에 대해 아래와 같이 표현한다.
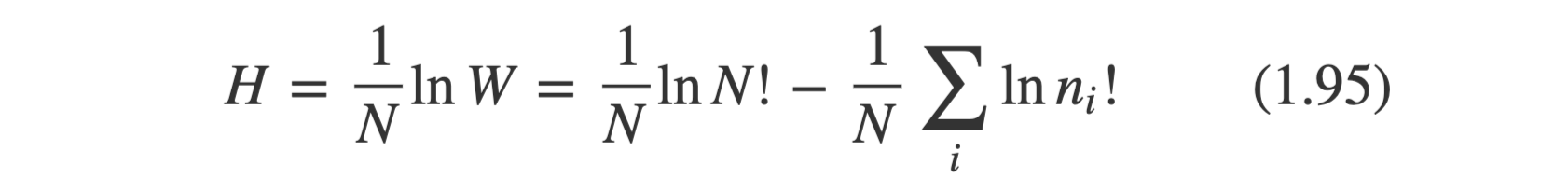
Stirling's approximation
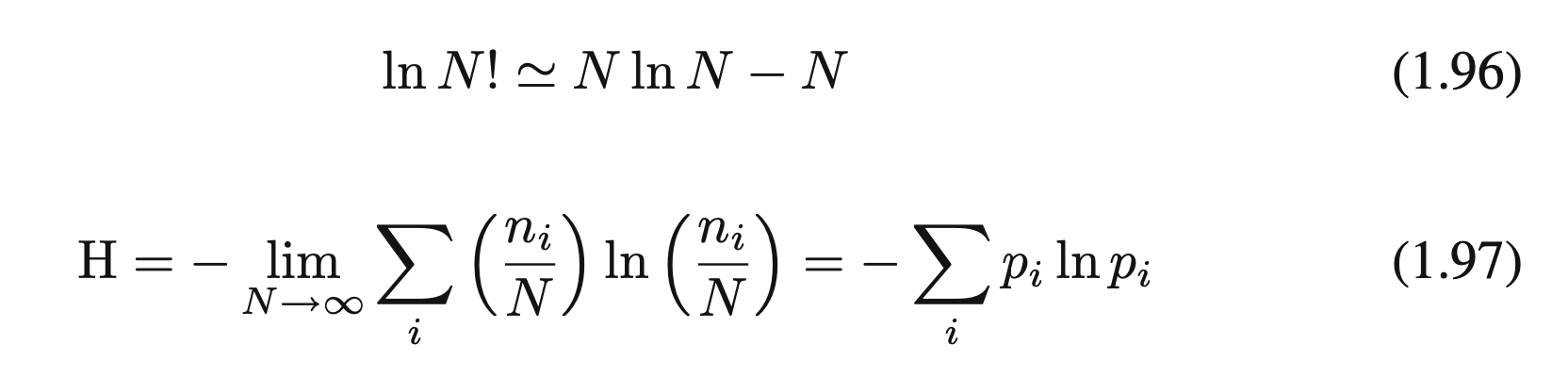
Reference
- Pattern Fecognition And Machine Learning (Bishop)
