YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
intro
bag-of-freebies
:inference시 추가적인 cost 없이 네트워크의 성능을 향상시키기 위한 방법
“Our focus will be on some optimized modules and optimization methods which may strengthen the training cost for improving the accuracy of object detection, but without increasing the inference cost. We call the proposed modules and optimization methods trainable bag-of-freebies.”
Architecture
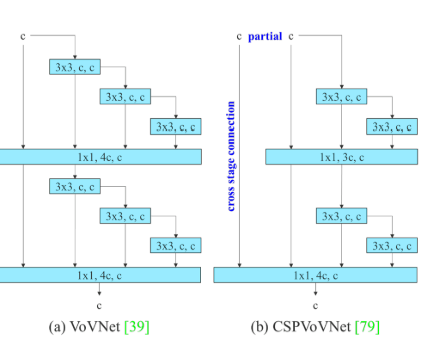
- VoVNet -> CSPVoVNet
보통 아키텍처를 설계할 때 매개변수의 수, 계산량 및 계산 밀도만을 고려함.
CSPVoVNet은 VoVNet을 변형할 때 가중치에 대한 그라디언트 경로를 추가적으로 분석
VoVNet, CSPVoVNet 그림)
- 그림 (b)에선 CSPVoVNet의 컨볼루션 블록 1개를 보여주고 있음
- 입력 데이터 c를 두 부분으로 분할하여(복제하여 전달) 진행
- 일부는 기존의 3x3 layer가 있는 작은 블록을 지나고
- 일부는 cross stage connection을 통해 작은 블록을 거치지 않고 다음 layer로 바로 전달
- 결과)
- 그래디언트가 두 경로로 흐를 수 있게 되어, 각각의 블록이 학습하는 동안 더 다양한 정보가 제공
- 특히, 블록을 통해 학습된 정보와 나뉜 경로의 정보를 다시 합치면서, 그래디언트 분산 경로가 더욱 안정적으로 이루어져 깊은 네트워크에서도 학습이 원활하게 진행
-
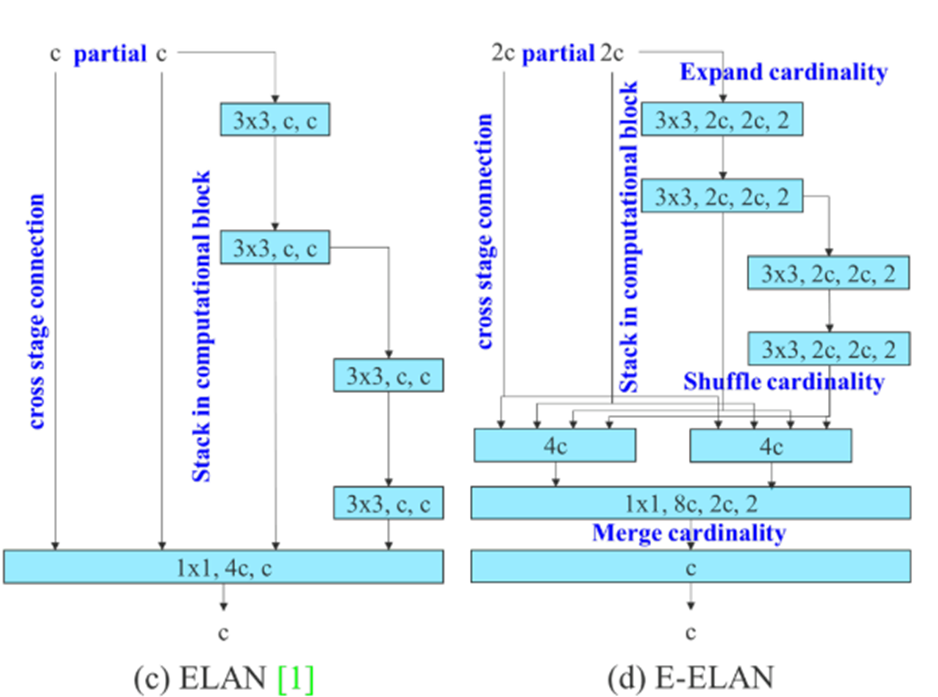
ELAN -> E-ELAN
ELAN도 마찬가지로 그라디언트 경로를 고려한 아키텍처-
"더 깊은 네트워크가 효과적으로 학습하고 수렴"하는 것을 목표로 함
-
“the shortest longest gradient path를 제어한다"
-
하지만, 무한적으로 쌓으면 불안정해짐 ->E-ELAN
-
ELAN, E-ELAN 그림)
- ELAN
짧은 경로: cross-stage connection
긴 경로: computational block 을 지나는 경로- E-ELAN:
- 입력 데이터의 채널 수가 2C로 증가 -> 필터가 더 많은 특징을 학습
- computational block에선 각 layer마다 group convolution을 진행
-> 2C 입력 채널을 두 개의 그룹으로 나눔 각 그룹에는 입력 채널 중 절반(C)씩이 할당되어 독립적인 컨볼루션 연산을 수행, 다시 합쳐짐- Expand Cardinality:
그룹 컨볼루션에서의 그룹 수뿐 아니라 네트워크 전체에서 여러 경로를 통해 데이터를 처리하는 능력을 확장하는 전략
- Cardinality(카디널리티)의 개념:
Cardinality는 네트워크의 표현력을 높이기 위해 데이터를 처리하는 경로나 그룹의 수를 의미.
여기선 경로로 이해하는 게 더 수월함.- Shuffle and Merge cardinality
데이터를 무작위로 섞어 다양한 조합을 통해 특징을 추출한 뒤
다른 레이어로부터 전달된 정보를 합쳐서 풍부한 특징을 만든다.
Model scaling for concatenation-based models
Model scaling
:이미 설계된 모델의 크기를 확대하거나 축소하여 다양한 컴퓨팅 장치에 맞게 조정하는 방법
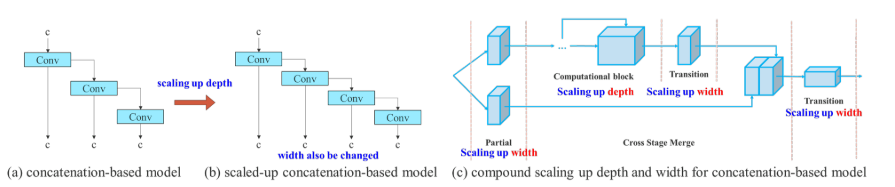
concatenation-based models의 경우 모델 scaling 시 translation layer가 변화(b)
이를 고려한 scaling이 필요!
=>깊이와 너비(채널수)를 함께 조정(c)
eg) Depth scaling 시
output channel의 변화 계산, translation layer의 변화만큼 width를 scaling
Planned re-parameterized convolution
Yolo v7은 RepVGG의 변형을 사용
- RepVGG: reparameterization을 사용한 VGG
여러 개의 conv layer를 병렬로 두어 가중치를 훈련하다가 inference시 conv과 Relu만 있는 plain 구조를사용
(Relu는 양수 값만 보냄으로써 경사소실 해결을 위해 사용)
-> 다양한 feature 학습
-> 더 빠른 속도
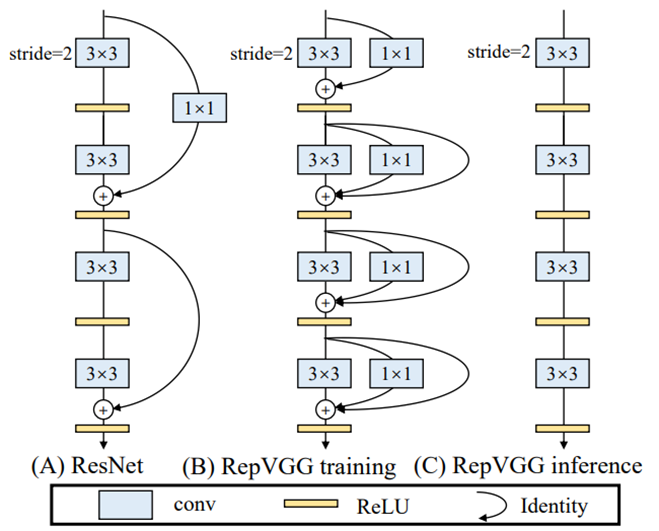
문제) 그러나 RepVGG의 RepConv의 identity connection은 ResNet의 residual이나 DenseNet의 concatenation connection을 destroy
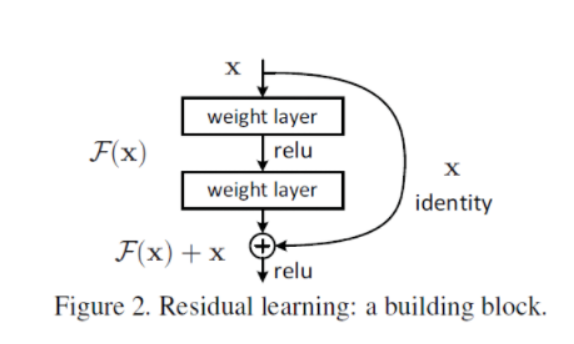
참고) residual block
기존 CNN은 입력 값 x를 타깃 값 y로 매핑하는 함수 H(x)를 얻는 것이 목적이었다.
But, ResNet은 'F(x)+x'(=residual mapping)를 최소화 하는 것을 목적으로 함. (x는 정해진 입력값이므로 결국 F(x)를 최소화)
F(x)= H(x)-x= Residual
residual block들이 쌓인 것이 ResNet
DenseNet 아키텍처)
DenseNet에서는 모든 이전 레이어의 output 정보를 이후의 레이어의 input으로 받아옴
해결) identity connection 없는 RepConv인 RepConvN을 사용
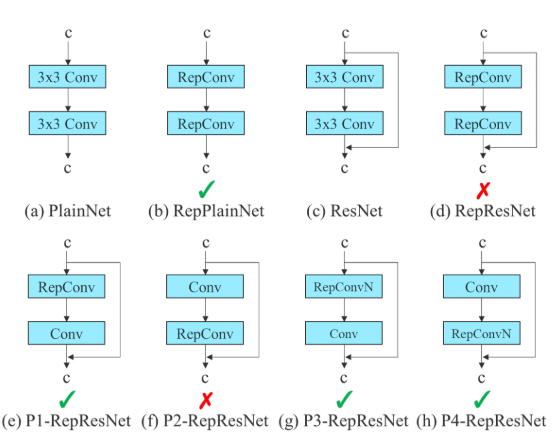 그림에서 (d)의 경우 입력데이터에서 그대로 오는 연결이 겹쳐지며 문제가 생김
그림에서 (d)의 경우 입력데이터에서 그대로 오는 연결이 겹쳐지며 문제가 생김
-> identity connection을 삭제한 RepConvN을 사용함으로써 해결됨
Coarse for auxiliary and fine for lead
- Deep supervision
: 중간 레이어의 결과값도 사용하여 loss를 계산->경사소실 해결
=”중간 레이어에 추가적인 보조 헤드(auxiliary head)사용”
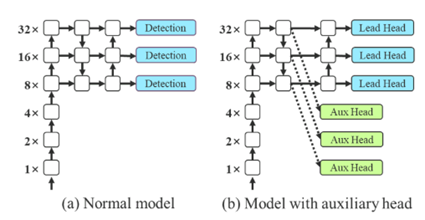
- 문제발생)
원래 yolo는 Prediction 한 bounding box와 ground truth 사이 IOU 값을 objectness에 대한 soft label(확률 값)로 사용
But, 출력값(lead head)과 중간 레이어 출력값(auxiliary head)이 동시에 있으면 soft label을 만들 수 없음
*Ground Truth는 데이터셋을 구축할 때 사람이 직접 레이블링하여 얻는 정보
*soft label 값을 높히는 방향으로 학습 진행
논문에선 다음 3가지의 방법을 제시
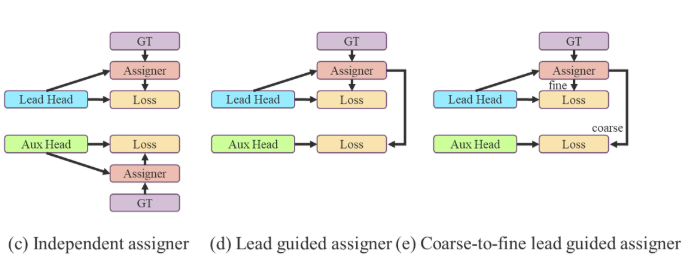
- 기존 방법
Lead head와 auxiliary head를 분리해 각각 계산, 각각을 GT에 연결
-> soft label 두 개 - 제안된 방법 1
lead head prediction과 ground truth를 기반으로 만든 soft label만 만들어, auxiliary head, lead head의 training에 모두 사용
->soft label 한 개 - 제안된 방법 2
lead head prediction을 guidance로 사용, coarse-to-fine 계층적 labels 생성- 제안 1로 만든 soft label = fine label
- 제약을 줄여 조금 더 낮은 IoU 점수를 가진 grid들도 positive target으로 간주
Fine label에 비해 덜 섬세한 coarse label을 만들어 Auxiliary head 학습에만 사용
->coarse label, fine label 두개
보조 헤드의 학습 능력이 주 헤드만큼 강하지 않기에 학습해야 할 정보를 잃을 수도 있음. Auxiliary head의 recall에만 최적화하는 데 초점을 맞추기 위함
평가
- COCO dataset으로 성능평가 진행
- validation set을 통해 hyper parameter를 조정
- 각 모델 이름
- GPU 종류에 따라
Edge GPU->YOLOv7-tiny
Normal GPU->YOLOv7
Cloud GPU-> YOLOv7-W6 - compound scaling up 한 것
YOLOv7-x: YOLOv7 기준
YOLOv7-E6, D6: YOLOv7-W6 기준 - E-ELAN 사용
YOLOv7-E6E: YOLOv7-E6 기준
- GPU 종류에 따라
- 평가 표
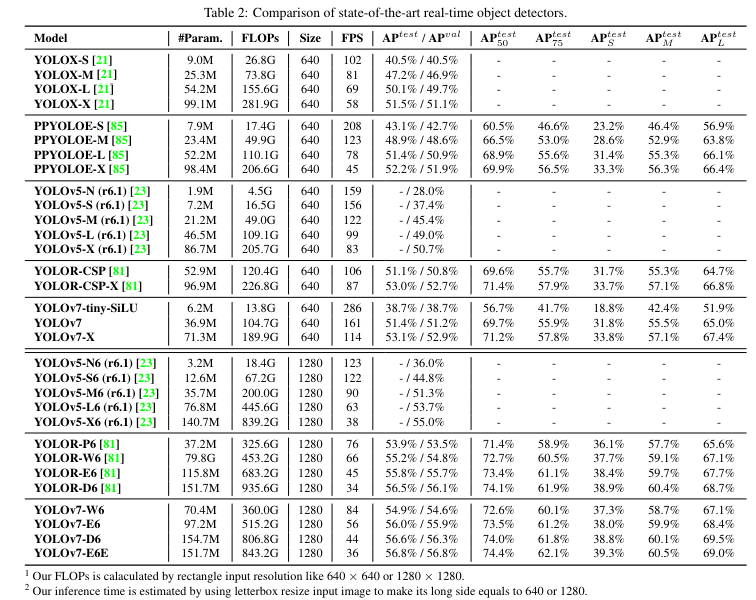
Param.: 모델의 파라미터 수
FLOPs: 모델이 한 번의 추론을 수행하는 데 필요한 연산의 수
Size: 입력 이미지의 해상도
AP, AP50, AP75, APs, APm, APl: 다양한 IoU 임곗값과 객체 크기에 대한 평균 정밀도(AP)
FPS: 초당 처리할 수 있는 프레임 수(속도)
=>"모델의 복잡도는 줄어들고,속도와 성능은 향상된 것을 확인"비교 그래프)

