- 본 자료는 'tcpshcool' 의 'java' 항목에서 일부 발췌한 후, 필자가 재구성하였습니다.
메모리 구조
-
모든 자바 프로그램은 자바 가상 머신(JVM)을 통해서 실행됩니다.
-
자바 프로그램이 실행되면, JVM은 운영 체제로부터 해당 프로그램을 수행할 수 있도록 필요한 메모리를 할당받습니다.
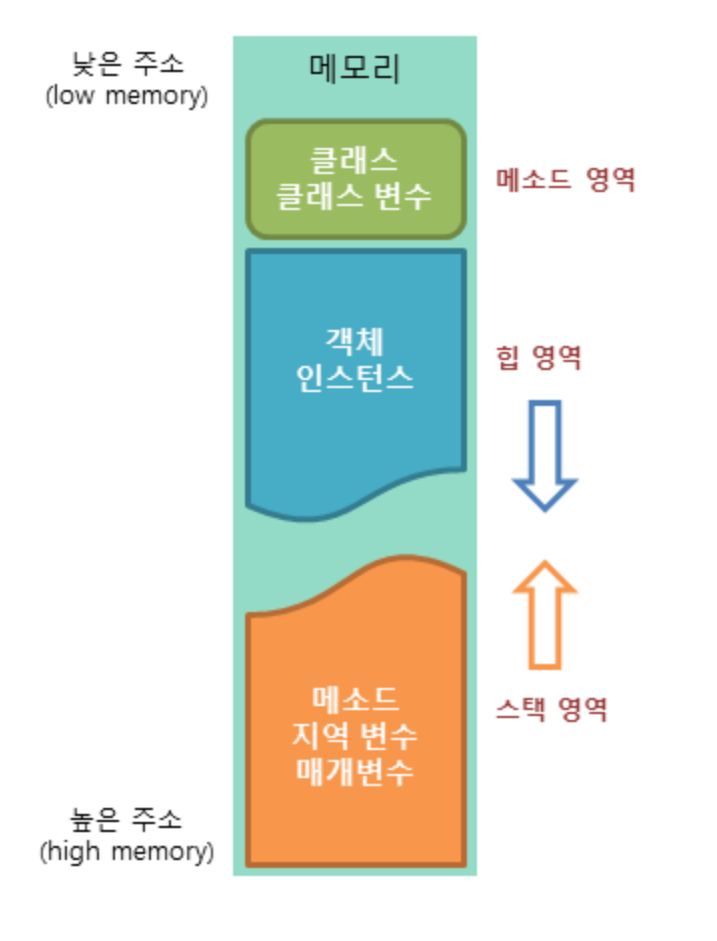
JVM은 용도에 따라 다음과 같이 메모리를 구분하고 관리합니다.
메소드(method) 영역
- 메소드(method) 영역은 자바 프로그램에서 사용되는 클래스에 대한 정보와 함께 클래스 변수(static variable)가 저장되는 영역입니다.
- JVM은 자바 프로그램에서 특정 클래스가 사용되면 해당 클래스의 클래스 파일(*.class)를 읽어들여, 해당 클래스에 대한 정보를 메소드 영역에 저장합니다.
힙(heap) 영역
- 힙(heap) 영역은 자바 프로그램에서 사용되는 모든 인스턴스 변수가 저장되는 영역입니다.
- JVM은 자바 프로그램에서 new 키워드를 사용하여 인스턴스가 생성되면, 해당 인스턴스의 정보를 힙 영역에 저장합니다.
- 힙 영역은 메모리의 낮은 주소에서 높은 주소의 방향으로 할당됩니다.
스택(stack) 영역
- 스택(stack) 영역은 자바 프로그램에서 메소드가 호출될 때 메소드의 스택 프레임이 저장되는 영역입니다.
- JVM은 자바 프로그램에서 메소드가 호출되면, 메소드의 호출과 관계되는 지역 변수와 매개변수를 스택 영역에 저장합니다.
- 이렇게 스택 영역은 메소드의 호출과 함께 할당되며, 메소드의 호출이 완료되면 소멸합니다.
- 이렇게 스택 영역에 저장되는 메소드의 호출 정보를 스택 프레임(stack frame)이라고 합니다.
- 스택 영역은 푸시(push) 동작으로 데이터를 저장하고, 팝(pop) 동작으로 데이터를 인출합니다.
- 이러한 스택은 후입선출(LIFO, Last-In First-Out) 방식에 따라 동작하므로, 가장 늦게 저장된 데이터가 가장 먼저 인출됩니다.
- 스택 영역은 메모리의 높은 주소에서 낮은 주소의 방향으로 할당됩니다.
배열(array)이란?
- 배열(array)은 같은 타입의 변수들로 이루어진 유한 집합으로 정의할 수 있습니다.
- 배열을 구성하는 각각의 값을 배열 요소(element)라고 하며, 배열에서의 위치를 가리키는 숫자를 인덱스(index)라고 합니다.
- 자바에서 인덱스는 언제나 0부터 시작하며, 0을 포함한 양의 정수만을 가질 수 있습니다.
- 배열은 같은 종류의 데이터를 많이 다뤄야 하는 경우에 사용할 수 있는 가장 기본적인 자료 구조입니다.
- 배열은 선언되는 형식에 따라 1차원 배열, 2차원 배열뿐만 아니라 그 이상의 다차원 배열로도 선언할 수 있습니다.
-하지만 현실적으로 이해하기가 쉬운 2차원 배열까지가 많이 사용됩니다.
1차원 배열
- 1차원 배열은 가장 기본적인 배열로 다음과 같은 문법에 따라 선언합니다.
- 타입[] 배열이름;
- 타입 배열이름[];
-
타입은 배열 요소로 저장되는 변수의 타입을 명시합니다.
-
배열 이름은 배열이 선언된 후에 배열에 접근하기 위해 사용됩니다.
-
자바에서는 배열을 만들기 위해 위의 두 가지 방법을 모두 사용할 수 있지만, 될 수 있으면 첫 번째 방법만을 사용하는 것이 좋습니다.
-
위와 같이 선언된 배열은 new 키워드를 사용하여 실제 배열로 생성할 수 있습니다.
배열이름 = new 타입[배열길이];
- 배열의 길이는 해당 배열이 몇 개의 배열 요소를 가지게 되는지 명시합니다.
- 또한, 다음과 같이 배열의 선언과 생성을 동시에 할 수도 있습니다.
타입[] 배열이름 = new 타입[배열길이];
-
자바에서는 이러한 배열도 모두 객체이므로, 각각의 배열은 모두 자신만의 필드와 메소드를 가지고 있습니다.
-
하지만 해당 배열의 길이를 초과하는 인덱스를 사용하면, ArrayIndexOutOfBounds 예외가 발생할 것입니다.
배열의 초기화
- 자바에서는 변수와 마찬가지로 배열도 선언과 동시에 초기화할 수 있습니다.
- 다음과 같이 괄호({})를 사용하여 초깃값을 나열한 것을 초기화 블록(initialization block)이라고 합니다.
- 자바에서는 이러한 초기화 블록을 이용하여 배열을 선언과 동시에 초기화할 수 있습니다.
초기화 블록을 이용한 배열의 초기화 방법은 다음과 같습니다.
- 타입[] 배열이름 = {배열요소1, 배열요소2, ...};
- 타입[] 배열이름 = new 타입[]{배열요소1, 배열요소2, ...};
- 위의 두 가지 초기화 방법은 완전히 같은 결과를 반환하며, 초기화 블록에 맞춰 자동으로 배열의 길이가 설정됩니다.
- 하지만 다음과 같은 경우에는 첫 번째 방법이 아닌 두 번째 방법만을 사용하여 초기화해야 합니다.
- 배열의 선언과 초기화를 따로 진행해야 할 경우
- 메소드의 인수로 배열을 전달하면서 초기화해야 할 경우
다차원 배열(multi-dimensional array)
- 다차원 배열이란 2차원 이상의 배열을 의미하며, 배열 요소로 또 다른 배열을 가지는 배열을 의미합니다.
- 즉, 2차원 배열은 배열 요소로 1차원 배열을 가지는 배열이며, 3차원 배열은 배열 요소로 2차원 배열을 가지는 배열이고, 4차원 배열은 배열 요소로 3차원 배열을 가지는 배열인 것입니다.
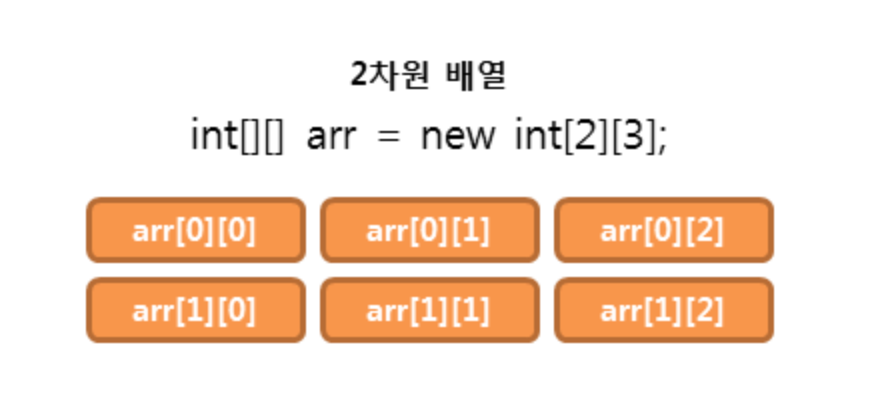
2차원 배열(two dimensional array)
-
2차원 배열이란 배열의 요소로 1차원 배열을 가지는 배열입니다.
-
자바에서는 2차원 배열을 나타내는 타입을 따로 제공하지 않습니다.
-
대신에 1차원 배열의 배열 요소로 또 다른 1차원 배열을 사용하여 2차원 배열을 나타낼 수 있습니다.
-
자바에서 2차원 배열은 다음과 같은 문법으로 선언할 수 있습니다.
- 타입[][] 배열이름;
- 타입 배열이름[][];
- 타입[] 배열이름[];
-
타입은 배열 요소로 저장되는 변수의 타입을 설정합니다.
-
배열 이름은 배열이 선언된 후에 배열에 접근하기 위해 사용됩니다.
다음 그림은 2차원 배열을 이해하기 쉽도록 도식적으로 표현한 그림입니다.
배열의 선언과 동시에 초기화하는 방법
- 1차원 배열과 마찬가지로 2차원 배열도 선언과 동시에 초기화할 수 있습니다.
- 자바에서는 2차원 배열의 모든 요소를 좀 더 직관적으로 초기화할 수 있습니다.
타입 배열이름[열의길이][행의길이] = {
{배열요소[0][0], 배열요소[0][1], ...},
{배열요소[1][0], 배열요소[1][1], ...},
{배열요소[2][0], 배열요소[2][1], ...},
...
};
배열의 복사
-
자바에서 배열은 한 번 생성하면 그 길이를 변경할 수 없습니다.
-
따라서 더 많은 데이터를 저장하기 위해서는 더욱 큰 배열을 만들고, 이전 배열의 데이터를 새로 만든 배열로 복사해야 합니다.
-
이러한 배열의 복사를 위해 자바에서는 다음과 같이 여러 가지 방법을 제공합니다.
- System 클래스의 arraycopy() 메소드
- Arrays 클래스의 copyOf() 메소드
- Object 클래스의 clone() 메소드
- for 문과 인덱스를 이용한 복사
-
이 중에서 가장 좋은 성능을 보이는 것은 배열의 복사만을 위해 만들어진 arraycopy() 메소드입니다.
-
하지만 현재 배열의 복사를 위해 가장 많이 사용되는 메소드는 좀 더 유연한 방식의 copyOf() 메소드입니다.
-
arraycopy(), copyOf() 메소드와 for 문을 이용한 복사는 배열의 길이를 마음대로 늘일 수 있습니다.
-하지만 clone() 메소드는 이전 배열과 같은 길이의 배열밖에 만들 수 없습니다.
Enhanced for 문
- JDK 1.5부터는 배열과 컬렉션의 모든 요소를 참조하기 위한 Enhanced for 문이라는 반복문이 새롭게 추가됩니다.
- 이 반복문은 배열과 컬렉션 프레임워크에서 유용하게 사용됩니다.
- 자바에서 Enhanced for 문은 다음과 같은 문법으로 사용합니다.
for (타입 변수이름 : 배열이나컬렉션이름) {
배열의 길이만큼 반복적으로 실행하고자 하는 명령문; }
- Enhanced for 문은 명시한 배열이나 컬렉션의 길이만큼 반복되어 실행됩니다.
- 루프마다 각 요소는 명시한 변수의 이름으로 저장되며, 명령문에서는 이 변수를 사용하여 각 요소를 참조할 수 있습니다.
- 하지만 Enhanced for 문은 요소를 참조할 때만 사용하는 것이 좋으며, 요소의 값을 변경하는 작업에는 적합하지 않습니다.
- Enhance for 문에서 배열 요소의 값을 변경하여도 원본 배열에는 아무런 영향을 주지 못하게 됩니다.
