
numpy 함수
import numpy as np
def solution(numbers):
return np.mean(numbers)del 함수
del 함수 - 리스트의 특정 요소 혹은 리스트 특정 범위를 삭제
최댓값 만들기
문제설명 : numbers의 원소 중 두 개를 곱해 만들 수 있는 최댓값을 return하도록 solution 함수를 완성해주세요.
def solution(numbers):
m1 =max(numbers)
index=0
for i in numbers:
if i == m1:
del(numbers[index])
index += 1
m2 = max(numbers)
answer = m1*m2
return answer
# 내림차순 정렬 후 첫번째, 두번째 값을 곱해주기
def solution(numbers):
numbers.sort(reverse=True)
return numbers[0]*numbers[1]list 총정리!
-
리스트 더하기, 곱하기 연산 가능
L = [1,2,3] * 3 -
인덱스, 슬라이싱 사용가능
L[3]
L[2:5] -
List Comprehensions 방식으로 리스트를 만들 수 있음
L = [i*i for i in range(10)]
L = [i for i in L if i%3 == 0] -
in, not in 사용가능
5 in L
추가 및 복사
.append(a) : 맨 뒤에 a 추가
.extend(a) : a 리스트합치기
.insert(n,a) : n번째에 a 추가
.copy() : 리스트 복사 => 리턴받아서 사용
제거 함수
.remove(n) : n 하나 제거
.pop() : 마지막 제거 => 인자값이 있으면 특정 인덱스 값 삭제
.clear() : 리스트값 모두 삭제(빈 리스트)
del(L[2]) : 특정 인덱스 내용 삭제
del(L) : 리스트 자체 삭제
개수, 길이, 인덱스
.count(a) : a 값의 개수 확인
len(a) : a 리스트의 길이 확인
.index() : 해당 값의 인덱스값 찾기
순서
=> 매개변수는 iterable한 변수면 OK!
a.reverse() : 리스트 a에 들어있는 값 역순으로 바꿔줌 (리턴x)
reversed() : 기존 리스트의 역순을 갖는 배열 생성 => list(reversed(기존리스트)) => 리턴
최대 최소
max() : 최대값 출력
min() : 최소값 출력
list(range(2,101,2)) : 짝수만 갖는 데이터 만들기
list(range(10,0,-1) : 10부터 1까지 역순의 데이터 만들기
중복제거 하는 방법
set(리스트)을 이용
list(set(리스트))
- 순서 바뀜
- 집합 타입으로 변경
for문 이용
- for문 돌리고, in 연산자 써서 중복제거
dictionary를 이용하여 중복제거
- 딕셔너리는 key 값이 중복 불가!
- dict.fromkeys(iterable) => 인자로 들어온 iterable 데이터를 key 값으로 해서 딕셔너리 자료형을 만들어줌
# 중복된 문자 제거한 문자열 리턴하는 문제
def solution(my_string):
return ''.join(dict.fromkeys(my_string))lambda를 활용한 map, filter
map(람다식, 리스트나 튜플) => 반환 값은 map객체여서 list 혹은 tuple로 형 변환해야됨
filter(함수, 리스트나 튜플) => filter는 json을 반환
def solution(array:list, height:int)->int:
answer = len(list(filter(lambda x:x>height,array)))
return answerfor in 딕셔너리
-
키와 값 모두 출력하고 싶을때는 이렇게 써보자!
for 키, 값 in 딕셔너리.items(): 반복할 코드예시 => 옷가게 할인 받기
def solution(price):
discount_rates = {500000: 0.8, 300000: 0.9, 100000: 0.95, 0: 1}
for discount_price, discount_rate in discount_rates.items():
if price >= discount_price:
return int(price * discount_rate)
List Comprehension 문법 정리
-
기본 구조 : 표현식 + for문
result = [표현식 for 변수 in 리스트] -
표현식 + for문 + 조건문
result = [표현식 for 변수 in 리스트 조건문] -
조건문 + for문
result = [조건문 for 변수 in 리스트] -
중첩 for문
result = [조건문 for 변수1 in 리스트1 for 변수2 in 리스트2 ...] -
중첩 List Comprehension
정렬
- .sort() : 오름차순 정렬
- .sort(reverse = True) : 내림차순 정렬
- sorted() : 오름차순 출력 => 기존 리스트 데이터 변경x => 괄호 안에는 iterable 자료형 입력(문자열, 리스트 등)
-
sorted(정렬할 데이터)
-
sorted(정렬할 데이터, reverse 파라미터)
-
sorted(정렬할 데이터, key 파라미터)
-
sorted(정렬할 데이터, key 파라미터, reverse 파라미터)
- parameter
reverse
sorted([리스트], reverse=True)
key
- 정렬을 목적으로 하는 함수를 값으로 넣기
- lambda 이용가능
예시문제
길이가 짧은것부터, 길이가 같으면 알파벳 순으로 정렬
data_list = ['but','i','wont','hesitate','no','more','no','more','it','cannot','wait','im','yours']
#중복 제거
data_list = list(set(data_list))
data_list.sort()
print(data_list)
# 길이를 기준으로 정렬
# 콜론 뒤에 있는 것을 기준으로 앞의 리스트를 정렬
data_list.sort(key=lambda x : len(x))
print(data_list)
- 두가지 이상 요소 순서대로 정렬할때는
key = lambda x: (기준1, 기준2 , ...)방식로 사용
enumerate 함수
- enumerate => 순서와 리스트의 값을 전달하는 기능을 가집니다.
- 예제
dict1 = {'이름': '한사람', '나이': 33}
data = enumerate(dict1)
for i, key in data:
print(i, ":", key, dict1[key]
# 출력결과
# 0 : 이름 한사람
# 1 : 나이 33
zip 함수
파이썬 zip( ) 함수 : 길이가 같은 리스트 등의 요소를 묶어주는 함수
문자열 함수
슬라이싱 함수 ::
-
문자열[시작인덱스 : 종료인덱스 : 증가할 수]
-
슬라이싱은 초과해도 에러가 나지 않는다!
문자열 뒤집기
문자열을 하나씩, 반대로 잘라서 다시 입력시킨후 출력
'aaa'[::-1]
모음제거
- 문제설명
영어에선 a, e, i, o, u 다섯 가지 알파벳을 모음으로 분류합니다. 문자열 my_string이 매개변수로 주어질 때 모음을 제거한 문자열을 return하도록 solution 함수를 완성해주세요.
문자치환함수 => replace
String.replace(찾는 문자, 바꿀문자, 바꿀 문자 개수)
def solution(my_string):
answer = ''
remove_string = ('a,e,i,o,u')
for i in remove_string:
my_string = my_string.replace(i,'')
return my_stringjoin 함수
'구분자'.join(리스트)
리스트에 있는 요소 하나하나를 합쳐서 하나의 문자열로 바꾸어 반환하는 함수
' 'join(값) : 값을 공백으로 구분하여 string으로 반환
# join 함수 사용하기
def solution(my_string):
return "".join([i for i in my_string if not(i in "aeiou")])count()
문자열.count(a) => 문자열에 a가 들어있는지 세는 함수
isdigit()
- 문자열이 숫자로 이루어졌는지 판별하는 함수
문자열.isdigit()
=> true, false 반환 - 알파벳과 숫자가 섞여있는 문자열에서 숫자를 찾아서 더해주는 코드
def solution(my_string):
return sum(int(i) for i in my_string if i.isdigit())짱 쉽쥬?
Python Array[::] 사용법
arr[::], arr[1:2:3], arr[::-1] 등으로 배열의 index에 접근하는 방법을 Extended Slices라고 함
-
arr[A:B:C]의 의미는, index A 부터 index B 까지 C의 간격으로 배열을 만들라는 뜻
-
만약 A가 None 이라면, 처음부터 라는 뜻이고
B가 None 이라면, 할 수 있는 데까지 (C가 양수라면 마지막 index까지, C가 음수라면 첫 index까지가 되겠습니다.)라는 뜻입니다.
마지막으로 C가 None 이라면 한 칸 간격
대문자, 소문자
-
문자열 대문자로 변경하는 함수 (string.upper())
-
문자열 소문자로 변경하는 함수 (string.lower())
-
문자가 대문자인지 확인하는 함수 (string.isupper())
=> true, false 반환 -
문자가 소문자인지 확인하는 함수 (string.islower())
=> true, false 반환
swapcas()
string.swapcase() : 대소문자 상호 전환.
아스키코드, 문자열
- ord() => 문자열에서 아스키코드로 변환
- chr() => 아스키코드에서 문자열로 변환
ord('a`) # 94
chr(64) # afind 함수
string.find(찾을 문자, 시작 Index, 끝 Index)
찾는 문자가 존재 한다면 해당 위치의 index를 반환해주고
찾는 문자가 존재 하지 않는다면 -1 을 반환
split함수
string.split(구분자)
- split함수는 list를 리턴한다.
int 함수
- int() => 매개변수값을 정수로 변환
- int(x, radix)는 radix 진수로 표현된 문자열 x를 10진수로 변환하여 리턴한다. 예를 들어 2진수로 표현된 "11"의 10진수 값은 다음과 같이 구할수 있다.
int('11', 2) # => 2진수 11을 10진수로 변환해라
# 결과316진수로 표현된 "1A"의 10진수 값은 다음과 같이 구할수 있다.
int('1A', 16)
# 결과 : 26bin 함수
bin(number)
- 전달받은 integer 혹은 long integer 자료형의 값을 이진수(binary) 문자열로 돌려준다.
- 앞에 '0b'가 붙음 => 접두어 빼고 싶으면 format 함수 사용하기 👇
format 함수
(2진수, 8진수, 16진수) => 접두어 빼고 나옴
b = format(value, 'b')
o = format(value, 'o')
h = format(value, 'x')
eval 함수
- 매개변수로 받은 expression (=식)을 문자열로 받아서, 실행하는 함수
startswith & endswith
파이썬에서 문자열로 이루어진 리스트, 혹은 딕셔너리에서 특정 문자가 포함된 항목을 찾을 때 활용
str = 'final exam'
# startswith(특정 문자)
result = str.startswith('final')
str = 'final exam'
# endswith(특정 문자)
result = str.endswith('final')
deque
List 보다 deque의 속도가 훨씬 빠름
- import 해야됨
from collections import deque
a = deque()deque 함수
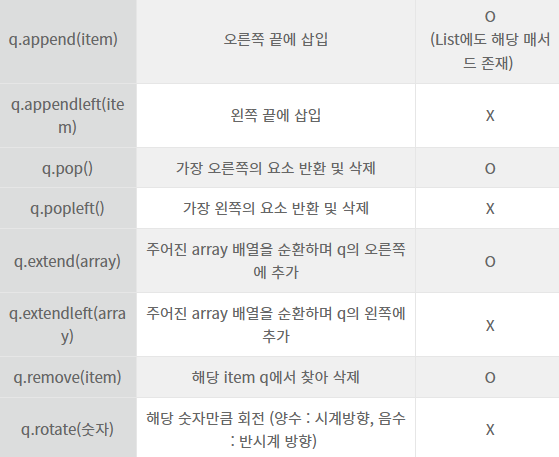
- q.rotate() => 음수는 왼쪽 회전, 양수는 오른쪽 회전
math 함수
import math
math.pow(x, y)
x의 y제곱
math.sqrt(x)
x의 제곱근
math.prod(iterable, *, start=1)
입력 이터러블(iterable)에 있는 모든 요소의 곱을 계산. 곱의 기본 start 값은 1.
math.factorial()
- math.facorial(x)
x의 팩토리얼 값을 return => x는 양의 정수!
gcd(a,b)
- a와 b의 최소공약수를 구해주는 함수
- from math import gcd => 바로 gcd 사용 가능
lcm(a,b)
- 최대공배수 구해주는 함수
비트 연산자
<<
정수를 2배로 곱하기
>>
정수를 2배로 나눠줌
- 예제
print(n<<1) #10을 2배 한 값인 20 이 출력된다.
print(n>>1) #10을 반으로 나눈 값인 5 가 출력된다.
print(n<<2) #10을 4배 한 값인 40 이 출력된다.
print(n>>2) #10을 반으로 나눈 후 다시 반으로 나눈 값인 2 가 출력된다.수학 공식
서로 다른 n개 중 m개를 뽑는 경우의 수 공식
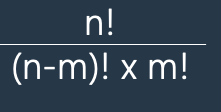
set함수
- set() => 집합 자료형 {}
- 괄호 안에 리스트 혹은 문자열 입력해서 만들 수 있음
set의 특징
- 중복 허용x
- 순서x
교집합
s1 = set([1,2,3,4,5,6])
s2 = set([4,5,6,7,8,9])
s3 = s1 & s2
print(s3) #result : {4,5,6}합집합
s3 = s1 | s2
print(s3) #result : {1, 2, 3, 4, 5, 6, 7, 8, 9}차집합
s3 = s1 - s2
print(s3) #result : {1, 2, 3}
s3 = s2 - s1
print(s3) #result : {8, 9, 7}대칭 차집합
set1 = set([1,2,3,4,5,6])
set2 = set([3,4,5,6,8,9])
print(set1 ^ set2)
{1, 2, 8, 9}집합 관련 함수
###1) 값 1개 추가히기(add)
이미 만들어진 set 자료형에 값을 추가할 수 있다.
s1 = set([1,2,3])
s1.add(4)
print(s1) #result : {1, 2, 3, 4}2) 값 여러개 추가하기(update)
s1 = set([1,2,3])
s1.update([4,5,6])
print(s1) #result : {1, 2, 3, 4, 5, 6}3) 특정 값 제거하기(remove)
s1 = set([1,2,3])
s1.remove(2)
print(s1) #result : {1, 3}Counter 클래스
- collections모듈의 Counter 클래스
- 리스트, 튜플에서 각 데이터가 등장한 횟수를 사전 형식으로 돌려줌
기본 예시
from collections import Counter
colors = ['red', 'blue', 'red', 'green', 'blue', 'blue']
cnt = Counter(colors)
print(cnt)
>> Counter({'blue': 3, 'red': 2, 'green': 1})most_common()
- 등장한 횟수를 내림차순으로 정맇
>>> numbers = [1, 2, 3, 3, 4, 4, 4, 5, 5]
>>> from collections import Counter
>>> cnt = Counter(numbers)
>>> cnt.most_common()
[(4, 3), (3, 2), (5, 2), (1, 1), (2, 1)]상위 n개의 결과 도출
>>> cnt.most_common(3)
[(4, 3), (3, 2), (5, 2)]최빈값
from collections import Counter
def modefinder(numbers): #numbers는 리스트나 튜플 형태의 데이터
c = Counter(numbers)
mode = c.most_common(1)
return mode[0][0]- 최빈수가 2개 이상 존재할 때
from collections import Counter
def modefinder(numbers):
c = Counter(numbers)
order = c.most_common()
maximum = order[0][1]
modes = []
for num in order:
if num[1] == maximum:
modes.append(num[0])
return modespermutaion
- 순열(순서를 고려)
import itertools
arr = ['A', 'B', 'C]
nPr = itertools.permutaions(arr, 2)
combination
- 조합(순서 고려x)
import itertools
arr= ['A', 'B', 'C']
nCr = itertools.combinations(arr, 2)
DFS
-
경로 탐색
-
네트워크 유형
-
조합 유형
-
재귀함수
BFS
- queue
DP 동적계획
- 수행시간 단축 알고리즘
- 정수 삼각형
- 메모리를 사용해서 중복 연산을 줄이고 중복 연산을 줄여서 수행 속도를 개선
기억하며 풀기
- DFS/BFS로 풀 수 있지만 경우의 수가 너무 많은 경우
- 500만개
- 경우의 수 중 중복이 많을 때
hash
-
key, value
-
전화번호부
-
다양한 자료형으로 데이터 관리 가능
-
모든 데이터 타입으로 접근 가능
-
String 기반으로 데이터 관리
String 알고리즘
- 문자열 단순 구현
- "".equals()
- length()
- toUpperCase()
- toLowerCase()
- indexOf() => 문자열 있는지 판단
- substring(1, 3) => 1부터 3까지 추출
- replace(a,b) => a를 b로 바꾸기
- compareTo => 알파벳 순서 비교하기 => 뒤가 작으면 -, 뒤가 크면 +, 같으면 0
- startswith()
- endswith()
- contains
Greedy
-
현재 시점에 가장 좋은 선택을 하는 알고리즘
-
경주마 알고리즘
-
탐욕스러운 선택 조건
-
정렬 => 현재 최적
