Eager Loading (즉시 로딩)
- QuerySet은 기본적으로 Lazy-Loading이라는 전략을 택한다.
- 하지만 SQL로 한번에 많은 데이터를 끌어오고 싶다면?
- 이를 ORM에서 Eager Loading이라고 부른다.
- QuerySet에서는 Eager Loading을 지원하기 위해 select_related와 prefetch_related라는 메소드를 제공한다.
ORM에서 Lazy-Loading
users = User.objects.all()
for user in users:
user.userinfo
user_list = list(users)위의 예시는 서버에서 ORM을 이해하지 못하고 사용했을 때 발생하는 문제이다
- 위의 코드의 상황은 이렇다.
- user라는 테이블이 있고, userinfo라는 테이블이 있다.
- 1:1 관계인 상황에서, users를 선언해놓고 userinfo를 땡겨오려고 한다면?
- QuerySet의 기본 전략은 Lazy-Loading이기 때문에 모든 User의 정보를 SQL로 한번에 가져왔다 치더라도 userinfo 테이블은 당장 필요하지 않았기 때문에 호출이 지연되었다.
- 그래서 for 문이 돌 때마다, userinfo를 가져오기 위한 쿼리문이 계속해서 실행된다.

-
위의 로그를 보면 알겠지만... for문을 돌면서 처음 users인 모든 User를 불러는 SQL 하나와, user.userinfo를 부를 때 마다 인스턴스 하나 하나 쿼리문으로 불러낸다.
-
예를들어 10명의 User가 있다면 10명의 User를 부르는 SQL 하나와 user1부터 user2 ... user10까지 각자 단일 쿼리문을 사용해서 불러낸다.
-
개발자라면 위의 코드를 보고 전체 QuerySet을 불러오는 SQL 하나만 있으면 더 이상의 SQL은 필요없겠구나 라고 생각할 것이다.
하지만 ORM은 아니다
-
전체 QuerySet을 불러오는 SQL 하나 + User의 총 명수대로 SQL을 실행한다.
-
즉, 1번 실행할 것을 N + 1 번 실행한다.
이것을 N + 1 Problem 이라고 한다.
- 이 문제를 해결하기 위해 select_related()와 prefetch_related()를 사용한다.
- 이 개념은 밑에서 좀 더 자세히 다룰 것.
QuerySet 상세
QuerySet의 구성요소
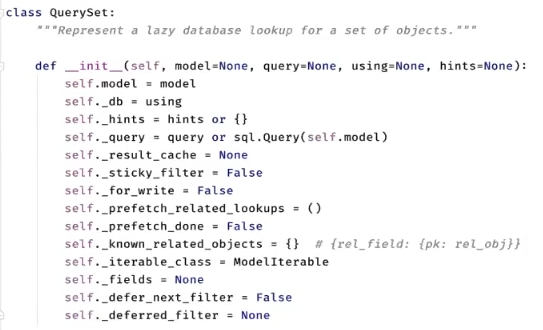
- 실제 QuerySet의 구성요소이다.
- 하지만 모두 알 필요 없다.
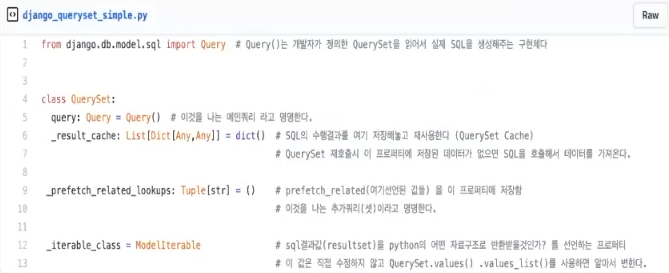
- QuerySet이 어떻게 동작하는지 알기 위해서는 위의 구성요소만 알아도 된다.
QuerySet은 1개의 쿼리와 0~N개의 추가쿼리(셋)로 구성되어 있다
query
- QuerySet은 하나의 Query를 최소로 가지고 있다.
- 이것을 메인 쿼리라고 부르도록 하자.
_result_cache
- _result_cache 라고 하는 변수에 QuerySet이 가져온 캐싱하는 데이터들을 저장한다.
- 그래서 _result_cache에 원하는 데이터가 없다면 SQL을 호출하게 된다.
_prefetch_related_lookups
- 추가 QuerySet이 될 타겟들을 저장하는 곳
iterable_class
- QuerySet의 반환 타입을 어떤 방식으로 반환할 것이냐에 대한 내용
- 추가적인 옵션을 주지 않으면 Django의 Model을 반환
- QuerySet.values()는 dict 형태로 QuerySet.values_list()는 list, tuple 형태로 알아서 반환하게 된다.
Eager-Loading의 옵션
select_related()
- join을 통해 데이터를 즉시 로딩하는 방식
prefetch_related()
- 추가 쿼리를 수행해서 데이터를 즉시 가져오는 방식
예시
Model.objects
.filter(조건절)
.select_related('정방향_참조_필드')
.prefetch_related('역방향_참조_필드')select * from 'Model' as m
(inner OR left outer) join '정방향_참조_필드' as r
on m.r_id=r.id
where '조건절';
select * from '역방향_참조_필드' where id in ('첫번째 쿼리 결과의 id 리스트');- select_related는 join으로 데이터를 호출
- prefetch_related는 쿼리가 추가로 호출
prefetch는 추가 쿼리를 발생시킴. 만약 prefetch 뒤에 filter가 이루어지면 근데 거기에 filter의 조건으로 prefetch를 해서 나온 결과의 field라면??
prefetch는 추가 쿼리 select는 join이다. 위의 경우에 prefetch를 해서 추가 쿼리를 발생시켜야 하는데, filter 때문에 위에서 먼저 쓸데없이 join을 하고 추가 쿼리를 발생시켜서 비효율적으로 된다.
그래서 prefetch 같은 경우는 filter 아래에 두고 사용하도록 하자!
https://kimdoky.github.io/django/2020/03/11/django-querysets-cashing-eval/
