Java String에서 Thread Safe까지 흐름이야기 :: cisxo
Computer Science 깊이 있게 다루기
String 부터 시작해서 Thread safe를 보장하는 방식에 대해서 이야기합니다.
JAVA 문자열을 다루는 자료형 대표적인 3가지
StringBuffer, StringBuilder 클래스는 문자열을 추가 및 변경시 주로 사용하는 자료형이다.
String은 불변, StringBuffer/StringBuilder는 공간이 부족한 경우 버퍼의 크기를 유연하게 하여 가변적이다. StringBuffer와 stringBuilder는 내부 Buffer에 문자열을 저장하고 그 안에서 연산할 수 있도록 설계되어 있다.
String 또한 + 또는 concat() 메서드로 이어 붙일 수 있으나 새로운 인스턴스를 생성하여 결합이 많아질 수록 비효율적인 공간 낭비와 연산 속도 지연이 발생한다.
String
String은 불변이다. 기본적으로 String은 객체 값 변경이 불가하다.
한번 할당된 공간이 변하지 않는다고 해서 불변 자료형으로 불린다.
String 자료형 코드
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
/**
* The value is used for character storage.
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*
* Additionally, it is marked with {@link Stable} to trust the contents
* of the array. No other facility in JDK provides this functionality (yet).
* {@link Stable} is safe here, because value is never null.
*/
@Stable
private final byte[] value;인스턴스 생성 시 생성자의 매개변수로 입력받는 문자열은 value라는 byte[]를 통해 인스턴스 변수에 문자형 배열로 저장하게 된다. final 상수로 값을 바꾸지 못한다.
String str = new String("hi");
str ---> hi
str = str + " Jo";
str -x-> hi //Garbage collector 제거 대상
---> hi Jo //새로운 메모리 영역에 생성
실제 메모리는 추가시 새로운 영역에 생성된다.
- String을 불변으로 설정한 이유는 캐싱, 보안, 동기화, 성능적 측면에서 이점을 얻기 위해서라 한다.
- 캐싱: String을 불변으로 만듬으로 써 String pool에 각 문자열의 하나만 저장하여 다시 사용하거나 캐싱에 이용 가능하며 이를 통해 힙 영역의 메모리 절약이 가능하다.
- 보안: db에 연결 수신은 문자열로 전달되는데 공격자의 참조 값을 변경을 막는다.
- 동기화: 불변으로 동시에 실행되는 여러 쓰레드 환경에서 안정적이게 공유 가능하다.
StringBuffer
StringBuffer sb = new StringBuffer("hello);
str ---> hello
sb.append(" world!");
str ---> hello world! // 같은 메모리에 변경
public final class StringBuffer
extends AbstractStringBuilder
implements Appendable, Serializable, Comparable<StringBuffer>, CharSequence
{
/**
* A cache of the last value returned by toString. Cleared
* whenever the StringBuffer is modified.
*/
private transient String toStringCache;
/** use serialVersionUID from JDK 1.0.2 for interoperability */
@Serial
static final long serialVersionUID = 3388685877147921107L;
/**
* Constructs a string buffer with no characters in it and an
* initial capacity of 16 characters.
*/
@IntrinsicCandidate
public StringBuffer() {
super(16);
}
StringBuffer 내부 코드를 보면 toStringCache로 받아온다. 여기서 볼거는 final로 설정되어 있다. 또한 버퍼의 크기를 16을 기본적으로 사용한다.
StringBuffer 내장 메서드
StringBuffer의 경우 버퍼라는 독립적 공간을 가지며 문자열을 바로 추가할 수 있어 공간의 낭비 없이 빠른 문자열 연산을 제공한다. String Buffer의 경우 멀티 스레드 환경에서 안전한 장점이 있다.
기본적으로 버퍼 크기의 기본값은 16개의 문자를 저장할 수 있는 크기이며 생성자를 통해 별도로 크기설정이 가능하다. 만약 버퍼의 크기를 넘기면 자동으로 버퍼를 증강시키며, 효율을 위해서 넉넉하게 크기를 지정하는 것이 좋다.
StringBuffer sb = new StringBuffer(); //기본 16버퍼
System.out.println(sb.capacity()); //sb.capacity() -> stringBuffer 변수의 배열 용량 크기 반환 -> 16 출력
sb.append("11111111111111111111") // 20길이의 문자열 append
System.out.println(sb.capacity()); //sb.capacity() -> 20 출력
StringBuffer sb = new StringBuffer("abcdefg");
sout(sb) // -> abcdefg
sout(sb.toString) //StringBuffer를 String으로 변환
sout(sb.substring(2,4)) // 지정 범위 문자열 String으로 뽑아서 반환, 파라미터 1개는 그 위치부터 끝까지 반환, 파라미터 2개는 2위치부터 4까지 반환 -> cd
sout(sb.insert(2,"HI")) // abHIcdefg
sout(sb.delete(2,4)) // abefg
sout(sb.append("hijklmn")) // abcdefghijklmn
sout(sb.length()) // ->7 문자열 길이 반환
sout(sb.reverse()); //문자열 뒤집기 gfedcba
String과 StringBuffer,StringBuilder 값 비교
// String 비교
String str = "Hi";
String str2 = "Hi";
str==str2 => false
str2.equals(str) => true
//Stringbuffer 비교
StringBuffer sb = new StringBuffer("hi");
StringBuffer sb2 = new StringBuffer("hi");
sb==sb2 =>false
sb2.eqals(sb1) =>false
sb2.toString().equals(sb.toString()); => true
StringBuffer vs StringBuilder
StringBuilder의 경우 앖서 설명한 StringBuffer와 기본적인 동작이 비슷하다. 이 둘의 차이점은 멀티 쓰레드에서 안전하냐 아니냐의 차이이다. 또한 StringBuilder는 문자열 파싱 성능이 우수하다는 장점이 있다.
두 클래스는 문법이나 배열 구성도 같지만 동기화 지원의 유뮤가 다르다. StringBuffer 클래스는 동기화를 지원하여 멀티 쓰레드에서 안전하고 StringBuider에서는 동기화를 지원하지 않아 안전하지 않다고 하는데 그 이유를 알아보자.
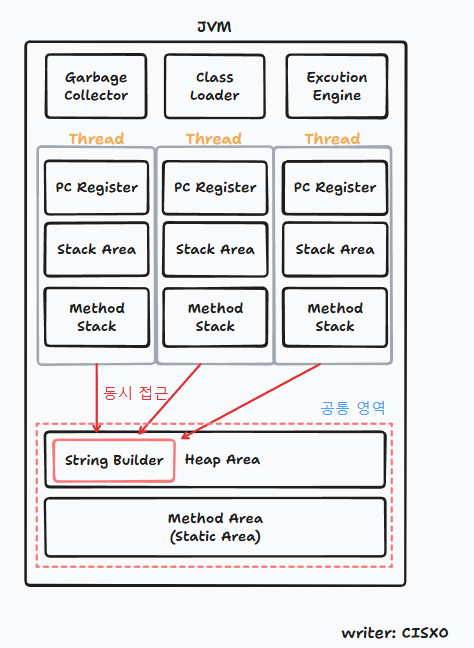
java에서 synchronized 키워드는 여러개의 스레드가 한 개의 자원에 접근할려고 할 때, 현재 데이터를 사용하고 있는 스레드를 제외하고 나머지 스레드들이 데이터에 접근할 수 없도록 막는 역할을 수행한다. 테스팅을 진행해보자.
public class test {
public static void main(String[] args) {
StringBuffer sbuffer = new StringBuffer();
StringBuilder sbuilder = new StringBuilder();
StringBuilder synchSbuilder = new StringBuilder();
for (int j = 0; j < 100; j++) {
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
sbuffer.append(1);
sbuilder.append(1);
synchronized (synchSbuilder) {
synchSbuilder.append("1");
}
}
}).start();
}
new Thread(() -> {
try {
Thread.sleep(3000);
System.out.println("StringBuffer complete: "+ sbuffer.length()); // thread safe 함
System.out.println("StringBuilder complete: "+ sbuilder.length()); // thread unsafe 함
System.out.println("synchStringBuilder complete: "+ synchSbuilder.length());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
결과:
StringBuffer complete: 100000
StringBuilder complete: 96723
synchStringBuilder complete: 100000
StringBuilder의 값이 더 작고 부정확하다. 데이터의 값이 정확하게 출력되는지 확인하기 위해 3초의 sleep()을 걸어주었다.
100개의 쓰레드를 생성하여 멀티 쓰레드 환경을 구성한 결과 StringBuilder의 경우 부정확한 데이터 출력을 보여주었다. synchnized 기반의 경우 append()를 다른 쓰레드가 수행하고 있을 경우에 동시에 수행하지 못하도록 잠시 대기를 시켜 순차적 실행을 통해 thread Safe로 정확한 결과를 출력한다. 또한 코드 및 결과를 보면 StringBuilder 또한 Synchnized를 통해 정확한 결과를 출력할 수 있다.
JVM Thread safe 안정성
"Thread Safety는 단순히 한 번에 하나의 스레드가 공유 자원에 접근하도록 보장하는 것만을 의미하지 않는다. race condition, deadlock, livelock, starvation이 발생하지 않는 동시에 공유 자원에 대한 순차적인 접근이 이루어지도록 보장해야 한다."
JAVA Thread-Safety
무상태(Stateless), 불변(Immutable)
객체를 무상태로 구현하면 항상 Thread-Safe 하다. 객체를 불변으로 구현하면 객체가 생성된 후 내부 상태를 변경할수 없으므로 Thread-safe 하다.
public class DataService {
private final String data;
public DataService(String data) {
this.data = data
}
//getter, no-Setter
public String getData() {
return data; //String은 불변 객체
}
...
}불변 클래스를 구현하는 방법을 클래스 및 인스턴스 변수를 private final로 선언한 뒤 setter를 제공하지 않고 내부 변경을 막아 thread-safe하게 만들 수 있다. getter를 통해 변경이 일어날수 있는데 새로운 메모리로 할당하여 return 시켜주어 다른 메모리 객체를 반환시키면 해결 가능하다.
Synchronized
자바의 객체는 모두 하나의 Monitor를 갖는다. Monitor는 상호 배제, 협력 두 종류의 스레드 동기화를 지원한다.
- 상호 배제: Lock을 통해 다수의 스레드가 공유 자원에 대해 독립적으로 연산을 수행할 수 있도록 한다.
- 협력: wait, notify 메서드를 통해 스레드가 상호 협력한다.
- 버퍼로 부터 데이터를 읽기,쓰기 스레드가 있다면 버퍼가 비어있는 경우 버퍼에 데이터를 쓰는 스레드가 데이터를 채울 때 까지 wait하고, 해당 작업이 종료되면 다시 읽기를 하는 것이다.
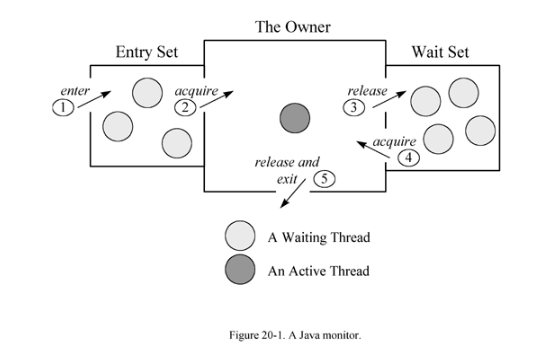
자바의 synchronized는 스레드 간 동기화를 위해 사용되는 기법이며 blocking으로 동작한다. 이는 객체 안에 존재하는 Monitor를 이용해 동기화를 수행하는 것이다. 하나의 스레드가 synchronized로 지정한 임계 영역에 들어가 있을 때 Lock이 걸리기 때문에 다른 스레드가 임계영역에 접근할 수 없는 것이다. 이후 해당 스레드가 임계 영역의 코드를 모두 실행 한 뒤 벗어나면 unlock 상태가 되어 대기하고 있던 다른 스레드가 임계 영역에 접근해 다시 Lock을 걸어 사용하는 것이다.
- 버퍼로 부터 데이터를 읽기,쓰기 스레드가 있다면 버퍼가 비어있는 경우 버퍼에 데이터를 쓰는 스레드가 데이터를 채울 때 까지 wait하고, 해당 작업이 종료되면 다시 읽기를 하는 것이다.
Atomic Objects
atomic 클래스는 멀티 스레드에서 원자성을 보장해 준다. Java는 AtomicInteger, AtomicLong, AtomicBoolean 등의 atomic 클래스가 존재한다. 이는 non-blocking 방식으로 동작하며 핵심 동작은 CAS(Compare And Swap) 알고리즘으로 동작한다.
public class test {
public static void main(String[] args) {
StringBuffer sbuffer = new StringBuffer();
StringBuilder sbuilder = new StringBuilder();
final AtomicInteger atomicInteger = new AtomicInteger();
for (int j = 0; j < 100; j++) {
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
sbuffer.append(1); // Thread-safe
sbuilder.append(1); // Thread-unsafe
atomicInteger.incrementAndGet();
}
}).start();
}
new Thread(() -> {
try {
Thread.sleep(2000);
System.out.println("StringBuffer complete: " + sbuffer.length()); // Thread-safe
System.out.println("StringBuilder complete: " + sbuilder.length()); // Thread-unsafe
System.out.println("AtomicInteger complete: " + atomicInteger.get());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
결과:
StringBuffer complete: 100000
StringBuilder complete: 95747
AtomicInteger complete: 100000inrementAndGet() 메서드는 원자적으로 값을 증가시킨다. 내부적으로 CAS 알고리즘을 사용하여 동기화를 구현한다.
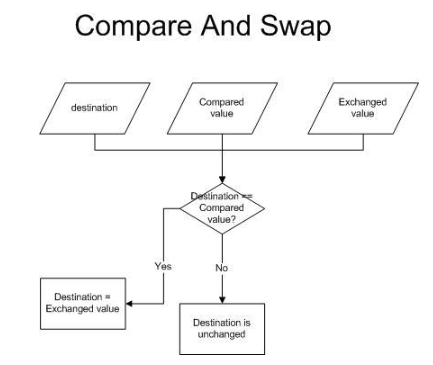
CAS 알고리즘
- 동작 과정:
- 메모리에 저장된 현재 값(기대 값)과 스레드가 작업 중 계산한 값(새로운 값)을 비교한다.
- 현재 값이 기대 값과 같으면 새로운 값으로 업데이트
- 그렇지 않으면 재시도한다. 이는 다른 스레드가 메모리 값을 먼저 변경한 경우에 발생한다.
스레드는 메모리의 데이터를 가져다가 캐시에 올려놓고 연산을 하게 된다. 연산을 마치면 연산 결과를 다시 메모리에 반영시키는 것이다. 만약 연산을 수행하는 스레드가 여러 개라면 메모리의 데이터와 스레드의 데이터가 불일치하는 상황이 발생하는데 이러한 경우 false를 반환한다.
- 장점
- 락을 사용하지 않아 성능 저하가 적다.
- 높은 경쟁 상태에서도 비교적 효율적으로 동작
- 단점
- 실패 시 반복으로 인해 성능이 약간 저하됨
return 값이 true 로 반환할 될 때까지 무한 루프를 돌면서 기다린다. 무한 루프를 돌면서 CPU를 붙잡고 있는데 synchronized 보다 나을까? 이는 synchronized가 lock이 걸린 경우 겪는 과정과 같기 때문에 무한 루프를 돌지만 true를 return받는 즉시 다음 작업을 수행하는 Atomic이 성능적으로 우세하다.
Atomic class에 붙은 volatile이라는 키워드란 무엇인가?
- 실패 시 반복으로 인해 성능이 약간 저하됨
Atomic 내부
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
/*
* This class intended to be implemented using VarHandles, but there
* are unresolved cyclic startup dependencies.
*/
private static final Unsafe U = Unsafe.getUnsafe();
private static final long VALUE
= U.objectFieldOffset(AtomicInteger.class, "value");
private volatile int value;
volatile 키워드를 붙이면 CPU Cache를 사용하지 않고 Main memory에 변수를 저장해 읽기,쓰기 연산을 수행한다고 명시한다. 오직 하나의 쓰레드에서만 읽기, 쓰기 작업을 수행하고 나머지 쓰레드에서는 읽기 작업만 보장하는 경우에 사용한다.
Synchronized Collections
자바 Collection Framework의 대부분 Collection 구현체들은 Thread-Safe 하지 않다. SynchronizedCollection() 메서드를 사용하여 Thread-Safe를 보장할 수 있지만 이는 클래스 내의 모든 메서드가 mutex 객체를 공유하여 다른 메서드 블록이 다 Lock이 걸려 단일 연산 작동으로 성능 저하 문제가 발생한다.
또한 동기화된 컬렉션을 사용해도 올바르게 동작하지 않을 수 있다.
public class test {
public static void main(String[] args) {
// 동기화된 리스트 생성
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
// 리스트에 초기 데이터 추가
for (int i = 0; i < 10; i++) {
synchronizedList.add(i);
}
// Thread A: 첫 번째 요소를 제거하는 스레드
Thread threadA = new Thread(() -> {
synchronized (synchronizedList) {
try {
Thread.sleep(100); // 다른 스레드가 동작할 여지를 줌
System.out.println("Thread A removing element at index 0");
synchronizedList.remove(0); // 인덱스 0 제거
System.out.println("Thread A removed element at index 0");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// Thread B: 리스트를 비우는 스레드
Thread threadB = new Thread(() -> {
synchronized (synchronizedList) {
try {
Thread.sleep(50); // Thread A와 간격 조정
System.out.println("Thread B clearing the list");
synchronizedList.clear(); // 리스트 전체 제거
System.out.println("Thread B cleared the list");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// 스레드 시작
threadA.start();
threadB.start();
try {
threadA.join();
threadB.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Final list: " + synchronizedList);
}
}
결과1:
Thread A removing element at index 0
Thread A removed element at index 0
Thread B clearing the list
Thread B cleared the list
Final list: []
Process finished with exit code 0
결과2:
Thread B clearing the list
Thread B cleared the list
Thread A removing element at index 0
Final list: []
Exception in thread "Thread-0" java.lang.IndexOutOfBoundsException: Index 0 out of bounds for length 0
at ...
3~4번 실행 결과 동기화 충돌이 발생하였다. 이를 해결하기 위해서는 synchronzied 블록을 명시적으로 사용하여 작업을 전체적으로 동기화해야 한다. 또한 하나의 스레드가 lock을 획득하는 순간에 다른 스레드는 blocking 상태가 되어 성능 저하로 이어질 수 있다.
Thread A는 리스트의 첫번째 요소를 remove(0)으로 제거하고 ThreadB와 충돌 가능성을 만들었다.
Thread B의 경우 리스트의 모든 요소를 clear() 메서드로 제거하고 sleep을 통해 Thread A와의 동기화 충돌을 유도한다.
Concurrent Collections
Synchronized Collection 대신 ConcurrentCollection을 사용하여 Thread-safe를 보장하자.
concurrent란 여러 스레드가 한 객체에 동시에 접근할 수 있다.
- 성능
- Synchronized Collection보다 높은 성능을 가진다.
- 전체 Map,List에 lock을 걸지 않는다.
- 여러 스레드가 한 번에 접근 가능하기 때문에 스레드 대기 시간을 줄여준다.
- 하나 이상의 스레드가 concurrent 하게 read,write 가능하다.
- 스레드 안정성 확보 방법
- Lock Striping같은 정교한 기법
- Lock Striping: 여러 개의 락을 사용하여 데이터를 분할한다. 컬렉션 데이터를 여러 개의 범위로 나누어서 각 범위마다 특정 락이 담당하도록 한다. ConcurrentHashMap은 16개의 락을 배열로 마련해두고 각각의 락이 전체 해시 범위의 1/16에 대한 락을 담당한다. 각 영역이 독립적인 락을 제공하여 서로 영향을 주지 않는 작업에 대해서 경쟁이 일어나지 않아 여러 스레드에서 동시 접근 가능하고 락 획득을 위한 대기시간을 줄인다.
- ConcurrentHashMap
각 테이블 버킷을 독립적으로 잠그고 빈 버킷에 노드를 삽입할 경우 lock 대신 CAS 알고리즘을 사용한다.- 전체 Map을 여러 조각으로 나눈다.
- 관련된 부분에만 락을 건다.
- 해당 컬렉션의 락이 걸리지 않은 다른 조각들에 여러 쓰레드들이 접근할 수 있다.
- CopyOnWriteArrayList
모든 쓰기 동작 시 원본 배열의 요소를 복사하여 새로운 임시 배열을 만들고, 임시 배열에 쓰기 동작을 수행한 후 원본 배열을 갱신한다. (명시적 락 사용), 읽기 동작은 lock이 걸리지 않는다. 또한 비용이 높은 배열 복사 작업이 있기에 쓰기 작업에 성능 이슈 가능성이 있다.- read: synchronization 없이 여러 읽기 쓰레드들이 읽을 수 있다.
- write: 전체 ArrayList를 복사하고 더 최신 컬렉션과 바꾼다.
- Lock Striping같은 정교한 기법
- 확장성
- 읽기 연산이 쓰기보다 많이 일어나는 등, 필요한 상황에 맞게 concurrent Collection class를 골라 사용할 수 있다.
- 더 높은 동시성과 확장성
실무에서 ConcurrentHashMap을 사용한다고 들어본 적이 있다. 이에 대해서 자세히 알아보자.
ConcurrentHashMap
Map의 일부만 lock을 건다. Thread-safe한 다른 Map Collection들 보다 성능 우위를 가진다.
ConcurrentHashMap 동작 방식
HashMap은 동기화 관련 코드가 없기에 Muti-Thread 환경에서 전체에 lock을 걸어야 한다. concurrentHashMap은 Lock Stripping이라는 내부적으로 데이터를 여러 버킷으로 나누고 각각의 Bucket 별로 동기화를 진행하기에 다른 Bucket에 속한 경우에 별도의 lock 없이 운용한다.
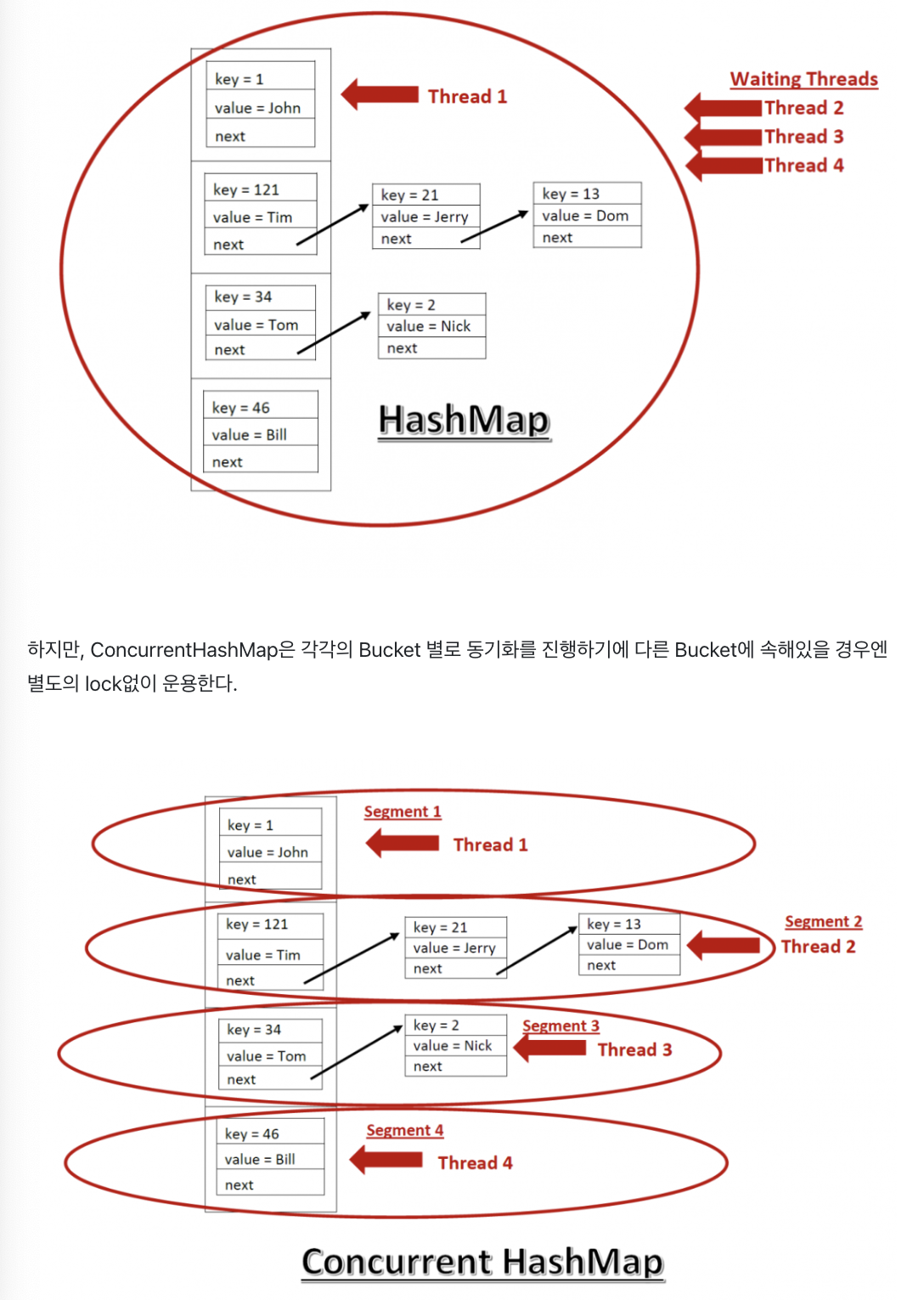
그림을 보면 HashMap의 경우 한 스레드가 전체를 담당하게 되고 나머지 쓰레드는 waiting에 걸린다.
concurrentHashMap의 경우 각 층 별 Bucket 별로 스레드를 운영하고 별도의 lock 없이 운용한다.
Put 메서드를 확인해보자
ConcurrentHashMap에 원소를 넣는 put을 호출하면 내부적으로 putVal(key, value, onlyIfAbsent)로 연결된다. method에 synchronized 키워드는 선언되어있지 않다.
1. 빈 Hash Bucket에 노드를 삽입하는 경우 CAS를 사용하여 새로운 Nodefmf HashBucket에 삽입하여 원자성을 보장한다.
2. 이미 Bucket에 노드가 존재하는 경우 synchronized(노드가 존재하는 해시 버킷 객체)를 이용해 하나의 쓰레드만 접근할 수 있도록 제어하고, 서로 다른 쓰레드가 같은 Hash Bucket에 접근할 때만 해당 block이 잠기게 된다.
- synchronzied안의 내부 코드에서는 HashMap과 비슷한 로직이다. 동일한 key이면 Node를 새로운 노드로 바꾸고, 해시 충돌인 경우에는 Separate Chaning에 추가하거나 TreeNode에 추가한다.
- TREEIFY_THRESHOLD 값에 따라 체이닝을 트리로 바꾼다.
- TREEIFY_THRESHOLD: 버킷에 저장된 노드 수가 8개 이상이면 트리로 변환하여 성능을 개선합니다.
UNTREEIFY_THRESHOLD: 트리 노드가 6개 이하로 줄어들면 다시 리스트로 변환됩니다.
- TREEIFY_THRESHOLD: 버킷에 저장된 노드 수가 8개 이상이면 트리로 변환하여 성능을 개선합니다.
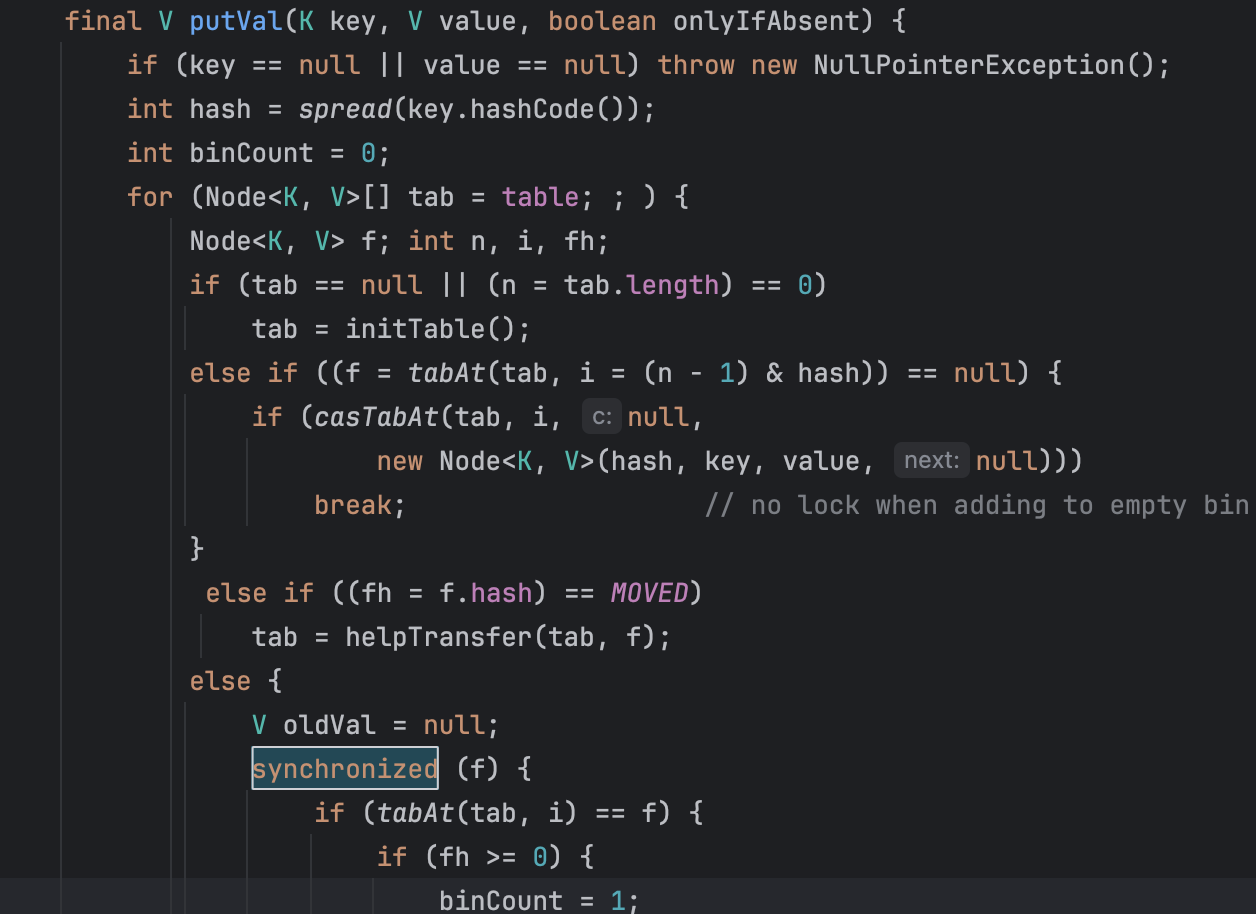
(1) f는 비어있지 않은 Node<K,V> type의 hash bucket을 의미하고 이것을 통해 동기화를 한다.
(2) 같은 Key 값이 들어올 경우 새로운 Node로 교체하고, putIfAbsent(key, value) 일 경우엔 값을 변경하지 않는다.
(3) Hash type fh 값이 양수이고 Hash 충돌일 경우엔 Seperate Chaining에 추가한다.
(4) Hash type fh 값이 음수일 경우엔 Tree에 추가한다.
(5) Hash bucket의 수 binCount에 따라 Linked List로 운용할지 Tree로 운용할지 정한다.
특히, (3), (4)에선 Separate Chaining에 추가 하거나 Tree에 추가하는 것을 알 수 있는데 이는 HashMap의 내부 구현과 같으며
bucket의 크기가 TREEIFY_THRESHOLD = 8 값보다 큰 경우 Linked List 대신 Tree로 운용하는 조건이 만족된다.
bucket의 크기가 UNTREEIFY_THRESHOLD = 6 보다 작아지면 Tree 대신 다시 Linked List로 운용된다.
get()
get에서는 synchronized가 없다. 이는 가장최신의 vlaue 값을 return한다.
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}생성자
tableSize는 16으로 이루어져 있는데 이는 bucket의 수가 16개이고 16개의 스레드가 동시 쓰기 할 수 있다는 것을 의미한다. 그리고 생성자에서 직접 HashTable을 생성하는 것이 아니라 첫 Node가 삽입 시 초기화된다.
/**
* Creates a new, empty map with the default initial table size (16).
*/
public ConcurrentHashMap() {
}
/**
* Creates a new, empty map with an initial table size
* accommodating the specified number of elements without the need
* to dynamically resize.
*
* @param initialCapacity The implementation performs internal
* sizing to accommodate this many elements.
* @throws IllegalArgumentException if the initial capacity of
* elements is negative
*/
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}initialCapacity
초기 용량을 결정한다. 구현은 지정된 부하 계수가 주어지면 이 많은 요소를 수용하기 위해 내부 크기 조정을 수행한다.
loadFactor
초기 hashTable의 크기를 설정하기 위한 용도로 쓰이며, 추후엔 ConcurrentHashMap에서는 이 인자 값과 상관 없이 0.75f로 동작한다.
ex) 초기 hashTable 크기가 16 이면 entry 수가 12개가 될 때 hashTable 사이즈를 16에서 32로 증가시킨다.
concurrencyLevel
"동시에 업데이트를 수행하는 예상 스레드 수" 라고 주석에 적혀 있지만, 구현시 이 값은 단순히 초기 테이블 크기를 정하는데 힌트로만 사용된다.
내부 remove()를 통해 충돌 해소
ConcurrentHashMap의 entrySet() 메서드는 맵의 키-값 쌍을 Set<Map.Entry<K, V>> 형태로 반환한다. 이 Set에서 remove()를 호출하면 해당 키-값 쌍을 ConcurrentHashMap에서 제거한다. 즉, entrySet()에서 반환되는 Set에 포함된 각 요소는 실제로 ConcurrentHashMap 내에서 관리되고 있으며, 그 요소를 제거할 때는 ConcurrentHashMap의 remove() 메서드를 사용하여 해당 키-값 쌍을 삭제한다.
즉, ConcurrentHashMap은 remove() 메서드를 적절히 동기화하여 여러 쓰레드가 동시에 제거 작업을 하더라도 여러 스레드가 동시에 공유 자원에 접근할 때 발생할 수 있는 충돌이 발생하지 않도록 처리한다.
public Set<Map.Entry<K,V>> entrySet() {
EntrySetView<K,V> es;
return (es = entrySet) != null ? es : (entrySet = new EntrySetView<K,V>(this));
}
''''
public boolean remove(Object o) {
Object k, v;
Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
map.remove(k, v));
}
''''
public boolean remove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
return value != null && replaceNode(key, null, value) != null;
}
map.remove(k, v)에서 불러오는 replaceNode()에서 기존의 방식과 같이 lock Striping을 활용하여 동시성 문제를 해결한다. 즉 map.remove(k,v)는 해당 버킷에 락을 걸어 키-값을 제거하는 동안 다른 버킷은 락을 걸지 않고 replaceNode() 메서드 내부에서 동시에 여러 스레드가 같은 버킷에서 동일한 키-값에 대한 수정 및 제거를 방지한다.
concurrentHashMap은 각 Table bucket을 독립적으로 잠그는 방식이다. 빈 bucket으로의 노드 삽입은 lock을 사용하지 않고 단순히 cas만을 이용하고 그 외의 삽입 삭제 업데이트 등 lock을 이용하지만 각 bucket의 첫 번째 Node를 기준으로 부분적인 lock을 획득하여 쓰레드 경합을 최소화하여 안전한 연산을 수행한다.
정리
문자열을 다루는 클래스부터 시작해서 Thread-safe까지 다루었다. 주가 되는 내용으로 ConcurrentHashMap 위주가 되었는데 실무에서 동시성 문제를 위해서 많이 사용된다고 하니 잘 알아보는게 좋을 것 같아서 주 내용이 되었다. 또한 String, StringBuffer, StringBuilder에 대한 차이점과 여러 thread가 동작하는 시스템에 대한 해결 방식의 이해는 분산 시스템 환경에서 중요한 역할을 하니 잘 이해하면 좋을 것이다.
