
어플리케이션 레벨 의사결정은 이제 반 정도 한 것 같다. 뭐 이렇게 자잘한 것까지 다 결정하냐 싶겠지만, 내가 맘대로 정하고 통보하는 것보단 나을 것 같았기 때문에, 그리고 꽤 재밌는 이야깃거리일 것 같아서 이렇게 하고 있다. 12챕터의 내용들은 딱히 몰라도 상관 없기 때문에, 맘에 안 들면 그냥 13챕터로 넘어가도록 하자.
의사결정
시각 데이터 저장 방식
배경과 요구사항
-
데이터의 생성일과 최근 수정일을 기록하는 것은 비즈니스적 지표를 뽑아내고(ex - 1월에 가입한 사용자 수, 날짜별 신규 게시글 수 등), 서비스에서 사용하고(ex - 게시글 작성일자 표기, 마이페이지에서 사용자 가입일 표시 등), 관리의 관점에서 데이터의 변화를 추적할 수 있는 기준이 될 수 있기에 여러모로 의미가 크다. 이렇게 데이터와 관련된 시각 정보를 기록하는 것을 timestamping이라 하는데, 이것도 데이터 저장에 대해 정해진 룰이 없으면 나중에 큰 기술부채가 될 수 있다.
-
글로벌 서비스 시 유연하게 대응할 수 있는 방식이어야 한다.
-
millisecond 단위까지 표현할 수 있어야 한다. 사실 이렇게 단위를 결정할 때는 기술 조직 전체의 협의를 진행하는 것이 좋지만, 기술 조직 전체가 나 혼자니까 내 맘대로 정했다.
-
MySQL에서 시각 데이터를 관리하기 위한 DATETIME 타입이 잘 인식할 수 있어야 한다.
-
human friendly한 포맷이면 좋다. 예를 들면 Unix time(1547580999)보다 시각 문자열(2019-01-15 19:36:39)이 낫다.
-
Unix time처럼 특정 시각에 문제를 발생시키는 포맷이 아니어야 한다. 구체적인 내용은 2038년 문제를 참고하자.
선택지
-
Unix time
-
Asia/Seoul 기준의 시각 문자열
-
UTC 기준의 시각 문자열
-
ISO 8601 format 문자열
의사결정
UTC 기준의 시각 문자열로 저장하도록 하자. 그 이유는,
-
Unix time은2038년 문제를 일으키고(2038년까지 서비스가 살아있을지 모르겠지만), 사람이 읽기 힘들다. -
어느 timezone 기준으로 시각 데이터를 저장하는지에 대해 일관성만 보장되면 상관 없으니 그냥 KST를 써도 당장 문제는 없겠지만, UTC가 '국제 표준시'로서 기준점이 되기도 하고, local timezone에 의존하며 생길 수 있는 실수를 방어하기가 좋다. 시각을 다루는 대부분의 라이브러리가 제공하는
now()와utcnow()의 차이인건데, 예를 들어 한국 region에서의 now()와 미국 버지니아 region에서의 now()는 각각 Asia/Seoul(UTC+9), America/Virgin(UTC-4) 기준의 현재 시각을 반환할 것이다. 코드가 실행되는 운영체제의 timezone 설정에 의존한다는 것이다. 그냥 애초에 시각 정보를 UTC 기준으로 생성하면 timezone이 어떻게 생겨먹었던 어디서든 동일한 시차(UTC+0)의 시각 데이터를 만들 것이므로 실수를 방지할 수 있을 것이다. 물론 반대로now(timezone='Asia/Seoul')같은 코드를 통해 '애초에 KST 기준으로 생성하면 되지 않나'라고 생각할 수도 있겠지만, 위에서도 말했듯 UTC는 '국제 표준시'로서의 기준점이 되니 굳이 KST를 고집할 필요가 없다. -
ISO 8601은2019-01-15T19:36:39+09:00같은 포맷인데, '시각은 이거고, 이 시각은 UTC에 얼마 만큼의 시간을 더하거나 빼서 만들어진건지'를 명시한다. 사실 이건 시각 데이터에 대한 표현 단에서 쓸모있는 포맷이라, 저장 단에서는 투머치다. 바로 아래 의사결정에서 한 번 더 얘기할 것이다.
시각 데이터 표현 방식
배경과 요구사항
-
필요에 따라, UTC 기준으로 저장된 시각 문자열을 API에서 내려줘야 할 일이 생길 것이다. 예를 들면 '게시글 목록' API에서 각 게시글의 생성일을 포함시켜 주는 것이다. 이에 따라 표현(representation)에 대한 결정이 필요하다.
-
timezone에 대해 자유로울 수록 좋다. 바로 위 의사결정에 있었던 '글로벌 서비스 시 유연하게 대응할 수 있는 방식이어야 한다.'라는 요구사항의 연장선이다. 프론트엔드 관점에서, API가 반환한 시각 문자열이 어느 timezone을 기준으로 했는지에 대해 신경쓸 필요가 없어야 한다.
-
시간을 다루는 라이브러리들이 잘 파싱할 수 있는 포맷이어야 한다. 환경에 따라 케바케겠지만 190115-193639보단 2019-01-15 19:36:39가 더 안전할 것이라고 생각한다.
-
현재의 어플리케이션 기술스택에 무리 없이 적용할 수 있는 포맷이어야 한다.
선택지
-
YYYY-MM-DD HH:mm:ss.SSS
-
Unix time
-
YY-MM-DD HH:mm:ss.SSS
-
ISO 8601 format(YYYY-MM-DD
THH:mm:ss.SSS±hh:mm) -
RFC 3339 format
의사결정
ISO 8601 format으로 표현하도록 하자. 그 이유는,
-
ISO 8601은 날짜와 시간에 관련된 데이터 표현을 다루는 국제 표준이다. 애초에 ISO 8601의ISO가 국제 표준화 기구를 의미한다. ISO 8601 format의 시각 문자열을 파싱 못하는 정신나간 환경은 없을 것이라 생각한다. -
ISO 8601이 표준화한대로 시각을 표현하려면, 그레고리력 날짜와 24시간제에 기반하는 시간, 그리고 UTC와의 시간 간격(time interval)을 조합해 만든다. 글로벌(다중 timezone 위에서) 서비스를 한다고 했을 때, 시각 데이터에 대한 국제화를 위해 ISO 8601을 사용한다는 것은 충분히 납득 가능하다고 생각한다.
-
어차피 UTC로 저장했으니 그냥 그대로
YYYY-MM-DD HH:mm:ss.SSS포맷을 써도 될 것 같기도 하다. 그러나 '시각 문자열이 UTC다'라는 것은 단지 내부적으로 정한 룰일 뿐이고, 데이터에 이를 명시할 수 있는 방법이 뻔히 존재하므로 충분히 써먹도록 하자. -
RFC 3339는 ISO 8601과 비슷하게 생긴 시각 데이터 표현 표준이다. ISO 8601의 부분집합이라고 보면 되는게, 두 글자로 이루어진 연도 표현(2018을 18로 표현)이 불가능하고 + 마침표 문자를 millisecond 하위 단위에서만 사용할 수 있고 + date와 time을 구분하는 시간 지정자인 'T'를 대신해 공백을 허용하는 것 정도가 핵심적인 차이점이며 나머지는 모두 ISO 8601과 동일한 스펙이다. 조금 더 완전한 표현(complete representation)을 사용하도록 제약한다는 것인데, 이는 의사결정의 요구사항을 만족하는 데에 추가적인 기여를 딱히 하지 않는다. 게다가 Python에서 자주 쓰이는 시간 관련 라이브러리인 datetime과 arrow를 따져 보면, 둘 다 RFC 3339 format을 '제대로 지원'하고 있지 않다.isoformat()은 지원하더라도rfcformat()은 지원하지 않는다는 것이다. 어차피 두 글자로 이루어진 연도 표현을 피하는 것 정도만 지켜주면 되는데, datetime이나 arrow나isoformat()은 이미 이게 포함되어 있는 상태다. Golang은 RFC 3339를 자주 써서, 우리가 결정한 어플리케이션 기술스택이 그 쪽이었다면 RFC를 썼을텐데 모든 상황이 우리가 ISO 8601을 쓰도록 만들고 있다. -
ISO 8601과 RFC 3339를 제외한 나머지 선택지들은, '이 시각 데이터가 어느 timezone을 기준으로 했는지'를 신경써야 할 수밖에 없다. 이렇게 되면 결국은 프론트엔드 레벨에서 시각 데이터에 timezone 정보, 혹은 특정 timezone과의 시간 간격 정보를
UTC+9와 같이 별도로 추가해서 쓰게 될텐데, timezone에 대한 명시를 백엔드가 해주면 'API가 내려주는 모든 시각 데이터는 UTC 기준이다.'처럼 내부적인 룰을 귀찮게 따로 얘기하지 않아도 되니 더 낫고, 이를 위해 ISO 8601이 좋은 해결책이 되어줄 것이라고 생각했다. 이미 '시간 간격은 UTC를 기준으로 한다'는 게 표준으로서 정의되었으니 말이다. -
부가적인 옵션이긴 하지만, 사람이 읽기 좋다는 것도 이유 중 하나다.
JSON key 네이밍 룰
배경과 요구사항
-
우리가 사용하기로 한 직렬화 포맷인 JSON의 핵심 타입 중엔 Object라는 타입이 있는데, 이는 key-value 매핑으로 데이터를 나열하도록 되어 있다. Python의 Dictionary나 Java의 Map을 떠올리면 되는데, '사용자'의 데이터를 표현하기 위해 'id', 'password', 'nickname', 'email'같은 key에 값들을 달아주는 것을 예로 들 수 있다. 이러한 key들은 'signin_date'처럼 여러 단어가 섞이는 경우도 생긴다. 이러한 '이름'들에 대한 표기 룰을 정해둬야 한다. '이름을 짓는 방법'이라기보단 'key에서 단어와 단어 사이를 어떻게 구분할 것인지'를 결정한다고 생각하면 될 것 같다.
-
코딩을 조금 해 봤다면 '이름을 잘 짓는 것'과 '이름 짓기에 일관성을 지키는 것'은 생각보다 꽤 중요하다는 것을 이미 깨달았을 것이다.
-
프론트엔드가 사용하는 네이밍 룰과 섞였을 때, 위화감이 적거나 없어야 하며 관례를 고려하자. Python이 어떤 네이밍 룰을 쓰는지는 상관 없다.
선택지
-
신경쓰지 않는다.
ex) 'signindate' -
공백으로 분리한다.
ex) 'signin date' -
카멜 케이스(Camel Case)를 사용한다.
ex) 'signinDate' -
파스칼 케이스(Pascal Case)를 사용한다.
ex) 'SigninDate' -
스네이크 케이스(Snake Case)를 사용한다.
ex) 'signin_date'
의사결정
카멜 케이스를 사용하자. 그 이유는,
-
프론트엔드에선 이러한 데이터 처리 로직들을 JavaScript나 TypeScript로 처리하게 될텐데, 대부분의 인지도 있는 코드 가이드라인들은 Object의 key를 네이밍할 때 camel case를 사용하도록 권고하고 있다.
-
모바일 어플리케이션에서도 변수 네이밍에 camel case를 사용하는 가이드라인이 지배적이다. 모바일 어플리케이션 개발에 일반적으로 사용하는 Java, Kotlin, Objective-C, Swift가 그렇다. 이 쪽에도 변수 네이밍 룰을 통일해 주면 좋을 것 같았다.
val signinDate = payload['signinDate']가val signinDate = payload['signin_date']보다 나을 것이다. -
Python은 변수 네이밍에 snake case를 사용하지만, 프론트엔드를 배려하고 관례를 지키도록 하자는 입장이다.
일러두기
이제 정말로 어플리케이션 개발만 진행하면 되는 상황인데, 그 전에 몇가지를 일러 두겠다.
gitignore
git에서 특정 파일을 무시하도록 만들기 위해 .gitignore라는 파일을 만들어서 무시 대상들을 목록화시킬 수 있다. 내 경우 gitignore.io라는 서비스의 도움을 받아서 작성하며, 여기선 Python/Windows/macOS/PyCharm+all을 선택해서 .gitignore 파일에 포함시킬 것이다. 이후에 회고를 진행하면서 다시 이야기해볼 것이다.
JWT 관리 방식
JWT 관리 방식에 대해서는 나도 정확히 아는 입장이 아닌지라 쉽게 얘기할 수 있을 것 같지 않고, 내용 자체도 길어질 것 같아서 JWT에 관한 의사결정과 코드 업데이트는 나중으로 미뤄서 별도의 챕터로 작성할 예정이다. 당장은 'JWT를 제대로 못 쓰는' 상태로 라이브러리가 알려주는 Basic Usage를 따라 '일단 동작하게 만들기'를 먼저 해보자.
사용할 라이브러리
WAS를 개발하기 위해 사용할 라이브러리는 다음과 같다. Pipfile에 리스팅될 라이브러리의 목록이라고 이해하면 되며, 의사결정을 거하게 할 필요가 없는 것 같아서 한 곳에 정리한다.
-
Flask : 9. Compute Engine 결정과 Hello World 서버 배포에서 이야기했다.
-
schematics, sqlalchemy, mysqlclient : 12. 어플리케이션 레벨 의사결정 - (1)에서 이야기했다.
-
arrow : 시간에 관한 로직을 잘 처리하기 위해 사용한다. 딱히 길게 얘기할 것 없이, Python에 내장되어 있는 시간 라이브러리인 datetime보다 훨씬 낫다.
-
flask-jwt-extended : JWT를 관리하기 위해 사용한다. pyjwt를 써서 비교적 low-level로 JWT를 관리하면 조금 더 많은 일들을 할 수 있지만, 굳이 그렇게까지 할 필요가 없다. flask-jwt라는 라이브러리가 한동안 star 수가 더 많았는데, 개발이 제대로 진행되고 있지 않고 있는데다 라이브러리의 컨셉 자체가 그렇게 좋은 편이 아니었어서 오래 전에 flask-jwt-extended에게 역전당했다.
-
flask-restful : API 로직을 class 단위로 작성할 수 있게 해주는 flask의 MethodView를 조금 더 확장한 라이브러리다. 더 탄탄한 어플리케이션 구조를 만드는 데에 큰 도움을 준다.
-
termcolor : 터미널에 대한 표준 출력에 color를 입히기 위해 사용하는 라이브러리다. 꼭 필요한 건 아니라 사치품이긴 한데, Flask-Large-Application-Example에 이미 속해 있기도 하고 색이 입혀진 텍스트는 미관 상 좋기도 하니까 굳이 제외하지 말도록 하자.
민감한 데이터 관리 방식
데이터베이스 접속 비밀번호같은 민감한 데이터들은, 아무리 private repository라고 하더라도 소스코드 바깥에서 관리하는 게 좋다. 이전에 AWS well architecture에 관한 글을 읽었을 때, '깃허브가 해킹당하면 private도 의미가 없다'라는 내용이 있었다. 이러한 데이터들을 어디에 관리할지는 사람마다 다른데, 이 내용은 별도의 챕터로 분리하는 것으로 하고, 당장은 환경 변수에서 관리하도록 하자. AWS Lambda Management Console에 들어가서 이전에 배포해 두었던 함수를 선택한 후 '환경 변수' 섹션을 통해 데이터를 넣어 두겠다. RDS MySQL의 엔드포인트와 사용자 이름, 비밀번호를 각각 DB_ENDPOINT, DB_USER, DB_PASSWORD라는 이름으로 추가했다.
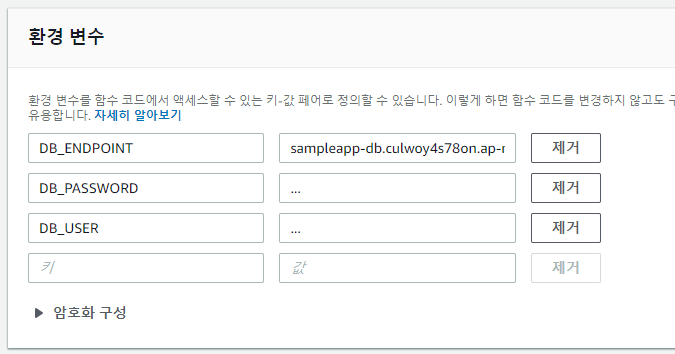
값들은 그대로 따라하지 말고, 독자 여러분의 상황에 따라 입력해 두자. 엔드포인트는 RDS Management Console에 들어가서 DB 인스턴스를 클릭하면 볼 수 있고, 사용자 이름과 비밀번호는 이전에 RDS 인스턴스를 만들며 입력해 두었던 마스터 사용자 이름과 마스터 암호를 사용하자.
