이번엔 API 설계 원칙과 직렬화 포맷을 결정한다. 대부분의 경우 이 두가지는 '당연히 REST랑 JSON 아님?' 하며 관례적으로 결정하고 넘어가곤 하지만, 빼먹지 말고 이것도 의사결정 과정을 끼워 두자. 사실 이 앞에 프로토콜을 결정하는 챕터를 넣어두려 했는데, 거기까진 너무 TMI인 것 같아서 나중으로 미뤘다. 프로토콜은 일단 현재로선 일반적으로 사용되는 HTTP/1.1을 사용하는 것으로 하자. 물론 추후에 HTTP/2에 대한 이야기도 할 예정이다.
도입 이유
API 설계 원칙
우리는 결론적으로 웹 어플리케이션 서버를 개발하고 운영하는 것이 목적이므로, '이렇게 HTTP 요청을 보내면, 이렇게 응답해준다'라는 스펙을 기능에 따라 설계해야 한다. API 설계 원칙은 웹 서버의 API 스펙을 어떤 규칙에 따라 정의할 것인지를 나타낸다.
-
'
GET /post는 게시글 목록을 불러오고,GET /post/{id}는 특정 게시글의 내용을 불러온다'같은 설계는 다 아키텍처 기반으로 결정하는 것이 좋다. 아키텍처가 없다고 API 디자인을 못하는 것은 아니지만, 의사결정의 기반이 있는 것이 좋기 때문이다. 나는 옛날에 이런 걸 몰랐어서 모든 요청을 싹 다POST /로 받고, 101, 102와 같은 동작 code를 가지고 로직을 분기시켰다. '미친놈인가'하는 소리 안 들으려면 아키텍처 베이스가 있어야 한다. -
'잘 디자인된' API는 불필요한 커뮤니케이션 비용을 줄인다.
직렬화 포맷
직렬화 포맷에 대해 예를 들면, '게시글'을 나타내는 '제목'과 '내용' 데이터를 표현하기 위해 아래와 같은 방법들을 사용할 수 있다.
{
"title": "...",
"content": "..."
}syntax = "proto3";
message Post {
required string title = 1;
required string content = 2;
}<title>...</title>
<content>...</content>title: ...
content: ...데이터를 어떤 방식으로 표현할 지를 결정해 두어야, 클라이언트와 서버 간의 데이터 교환에서 혼란을 줄일 수 있다.
의사결정
API 설계 원칙
배경과 요구사항
-
클라이언트 사이드에게 익숙한 아키텍처거나, 러닝커브가 감당 가능한 수준이어야 한다.
-
개발 일정에 딜레이를 일으킬 여지가 있으면 안된다.
선택지
-
HTTP API
-
REST API
-
GraphQL
의사결정
HTTP API를 선택하겠다. 그 이유는,
-
REST API가 명시하는 모든 원칙을 만족하는 API를 작성하는 것은 쉽지 않다. 결국은 '느슨한 REST' 느낌의 HTTP API가 되기 마련이다. 따라서 괜히 RESTful API 이러면서 깝치다가 정의구현 당하는 수가 있다. 제약조건을 따르던지 다른 단어를 쓰도록 하자. REST의
self-descriptive와HATEOAS원칙은 만족하기 정말 어렵다. -
REST는
HATEOAS(hypermedia as the engine of application state)라는 원칙을 지켜야 하는데, 이는 '어플리케이션의 상태가 Hyperlink를 이용해 전이되어야 한다'라는 의미다. 우리의 API는 미디어 타입이 JSON(JSON 형식의 데이터를 위주로 주고받는 형태)일텐데, HATEOAS를 지키기 어렵다. -
API가 꼭 REST API여야 할 필요가 없다.
-
GraphQL은 사례가 너무 적다. 사용자 인증 처리 로직을 생각하는 것부터 고민이 많아진다.
-
GraphQL은 클라이언트 사이드에서 러닝커브가 생길 수 있다.
-
HTTP API가 이야기하는 아키텍처로 충분할 것이라고 판단했다.
본인이 REST라는 걸 잘못 알고 있었나 싶다면, 그런 REST API로 괜찮은가라는 슬라이드 자료를 읽어보자.
준비
MDN의 HTTP 개요 문서, 이고잉님의 HTTP 강의 영상을 한번쯤 보면 좋을 것 같다. 'HTTP를 하나도 모르겠다'라면, 진도를 더 나가기 어려울 수 있으니 개발 잘하는 친구한테 물어보거나, 구글링을 하거나 해서 조금이라도 배경을 쌓고 넘어가자.
직렬화 포맷
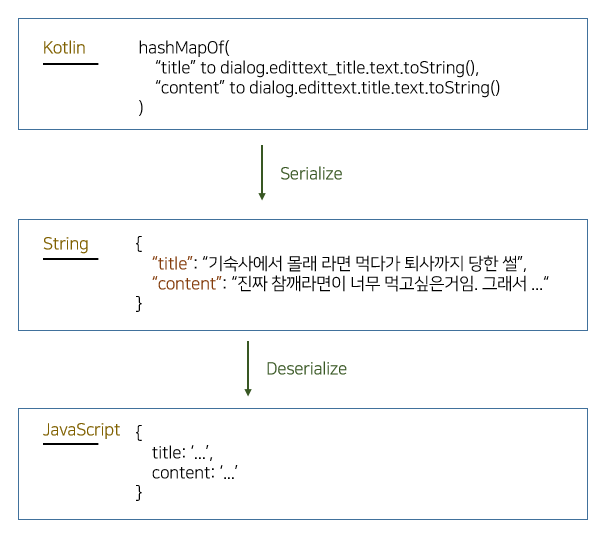
예를 들어, Kotlin로 이루어진 안드로이드 어플리케이션이 HashMap 객체를 문자열과 같이 특별한 형태로 가공해서 보내면, Node.js로 구성된 WAS가 이를 JavaScript 고유의 Object 타입으로 해석해 사용할 수 있어야 한다. 이를 위해 표준화된 직렬화 포맷이 여럿 존재하며, 그들 중 어떤 포맷을 사용할 것인지를 결정하도록 하자.
배경과 요구사항
-
이것 또한 클라이언트 사이드에게 익숙한 아키텍처거나, 러닝커브가 감당 가능한 수준이어야 한다.
-
key-value 매핑과 array와 같은 요소의 나열 표현에 문제가 없어야 한다.
-
충분한 수준의 데이터 타입을 커버할 수 있어야 한다. - 정수, 실수, 문자열, boolean 등
선택지
-
XML
-
JSON
-
YAML
의사결정
JSON을 사용하자. 그 이유는,
-
동일한 데이터를 표현하더라도, JSON이 비교적 더 잘 경량화되어 있으며 가독성도 좋다.
-
XML의 tree 구조는 자원을 표현하는 데에 그리 효과적인 포맷은 아닌 것 같다고 판단했다.(Array의 표현이 어려움) 옛날엔 많이 쓰였다고 하는데, 주관적인 의견을 덧대자면 진짜 이거 왜 쓰는지 모르겠다. 아직도 공공 API의 일부가 XML을 쓰는 게 정말 놀랍다. -
YAML은 관례 상 직렬화 포맷으로 잘 사용하지 않는다. 역직렬화 속도도 느리고, YAML을 썼을 때 생기는 메리트가 딱히 없다. -
Protobuf는 구글에서 개발한 data exchange format이다. 직렬화/역직렬화 속도가 빨라 성능 상의 이점이 있고, .proto 파일을 정의하는 것만으로 validation rule들을 정리하고, 비교적 적은 노력으로 API 문서화에도 응용할 수 있으며, 클라이언트 단은 proto 컴파일을 통해 이들에 대응되는 클래스(DTO)들을 자동으로 정의할 수도 있어서 시도해볼 가치가 충분하다. 그러나 조직 내에 protobuf를 사용했을 때 문제가 없을지에 대한 신뢰 수준이 낮고, 우리의 서비스 규모가 크지 않으므로 protobuf에 대한 확신이 생기고 난 후에 바꾸더라도 스트레스가 크지 않을 것이라는 생각이다. 당장은 다들 익숙해 하는 JSON을 쓰고, 나중에 바꿔 보자. -
JSON은 JavaScript Object Notation의 약자다. JavaScript나 그 형제들(TypeScript 등)로 로직 처리를 하게 될 프론트엔드에게 JSON만큼 편한 구조가 없으며, 모바일 앱과 웹을 포함해 대부분의 프론트엔드 엔지니어들은 이미 JSON에 익숙해져 있다.
준비
Stackoverflow의 'What is JSON and why would I use it?이라는 질문과, json.org의 JSON 개요 문서를 한 번 읽어 보자. 이번 챕터에서는 의사결정에 관례의 비중이 컸다. 기술 선택에 너무 의외성이 크면 조직 전체에 걸쳐서 기술부채가 생길 수 있어서, 관례를 감안할 수밖에 없었던 것 같다.
지금까지
- 버전 관리 시스템으로 Git을 사용하기 시작했다.
- Git 웹호스팅 서비스로 GitHub를 사용하기 시작했다.
- GitHub Issues와 Projects로 이슈 트래킹을 시작했다.
- 개발 프로세스와 브랜칭 모델을 정립했다.
- HTTP API 아키텍처 기반으로 API 스펙을 디자인하기로 했다.
- JSON을 직렬화 포맷으로 결정했다.



좋은 글 잘 봤습니다.
아직도 rest api 와 http api 는 정확히 구분하기 힘드네요. 정의와 구분을 명확히 하는데 도움이 될 수 있는 자료를 알고계시다면 공유 부탁드려도 괜찮을까요?