이번엔 Compute Engine을 결정하자. 우리가 구현한 서버를 실행할 위치를 결정하는 것이다. 아래 3가지에 대해 의사결정이 필요하다.
-
어떤 컴퓨팅 파워를 이용할 것인지(출처)
-
만약 외부 서비스를 이용하기로 했다면, 어떤 서비스를 사용할 것인지
-
해당 서비스에서 제공하는 컴퓨팅 엔진들 중 어떤 것을 사용할 것인지 등
오늘 하게 될 이야기는 AWS와 배경지식이 부족하면 조금 어려울 수도 있다. 읽다가 어렵다면 이고잉님의 AWS 강의로 흐름을 선회해도 좋을 것 같다. 컨테이너, dockerize, nginx, IAM 등등 이해되지 않는 부분이 있을 수 있을텐데, 큼지막한 흐름이 대충 이해가 된다면 머리아프게 다 이해하려 하지 말고 그냥 다음 내용으로 넘어가도 괜찮다. 이 컨텐츠는 텀을 길게 두고 두세번 정도 읽는 게 좋다고 생각한다. 일단 쭉 읽어보기 바란다.
도입 이유
Compute Engine
나는 초등학교 고학년(2012년) 때 마인크래프트 서버를 운영했었다. 내가 쓰던 데스크탑의 IPv4 주소에 oa.to 도메인을 묶어 두고, craftbukkit으로 서버를 직접 돌리는 방식이었다. 서버를 돌리기 위해 24시간동안 계속 컴퓨터를 켜두는 건 컴퓨터의 수명에 문제가 있지 않을까 걱정도 되고, 부모님 눈치도 보였기에 서버를 켜고 끄는 시간을 정해 공지해 두었었다. 3년만에 당시 운영하던 카페에 들어가보니, 켜지는 시간은 오전 8시 10분이었고 꺼지는 시간은 오후 11시였다. 등교하기 전에 켜두고, 잠들기 전에 껐나보다.
아무튼 결국 서비스 사용자의 트래픽을 처리하기 위해선 24시간 쉬지 않고 돌아가는 컴퓨팅 파워가 필요하다. 그게 PC던, 서버용 하드웨어를 구입해 구축한 홈서버던, 임대료를 지불해 호스팅받은 서버던, 클라우드 서비스던 말이다. 뭘 쓰던 '당장 되게 만드는 것'에는 문제가 없을 테지만, 여러 질문을 던져보며 가장 좋은 방향으로 의사결정 해보자. 백엔드 조직에 휴먼 리소스가 그리 많지 않은 상황이니, 되도록이면 서버의 컴퓨팅 자원같은 잡다한 부분을 직접 운영하는 일을 최대한 적게 만드려고 한다. 개발자는 어플리케이션 코드를 제공하기만 하면 되도록 말이다.
의사결정
컴퓨팅 파워의 출처
배경과 요구사항
-
우리는 돈이 없다. 비용이 최소한으로 발생하는 방법을 선택해야 한다.
-
그렇다고 불안정한 컴퓨팅 파워를 쓰진 말아야 한다.
-
인프라 엔지니어링에 익숙하지 않기에, 인프라 관리에 있어서 휴먼 리소스가 되도록 적게 소비되어야 한다.
선택지
-
PC
-
서버용 하드웨어를 구입해 홈서버 운영
-
서버호스팅
-
클라우드 플랫폼
의사결정
클라우드 플랫폼을 선택하겠다. 그 이유는,
-
PC던 별도의 하드웨어를 구입해 돌리던 자체 데이터 센터를 운영하는 경우 초기 투자 비용이 너무 비싸고, 인프라 엔지니어링을 잘할 수 있는 조직이 아니라면 운영도 어렵다. 클라우드 플랫폼은 쓰기 좋게 준비된 컴퓨팅 자원을 원하는 리소스 수준에 맞게, 원하는 만큼만 사용할 수 있다.
-
클라우드 형태로 제공되는 인프라는 일반적으로 'pay as you go' 컨셉을 가지고 있다. 사용하는 만큼만 비용을 지불하는 것이다. 만약 하드웨어 스케일이 너무 크다거나 머신이 필요없어 졌다면, 그냥 버튼 클릭 몇 번으로 더 작은 하드웨어 사이즈를 가진 인스턴스 타입으로 변경하거나, 없애버릴 수 있다. 서비스가 망해서 인프라 규모를 줄여야 하는 상황이 왔을 때를 생각하면, 클라우드가 더 낫다고 생각한다.
-
인프라 관리에 대해 수많은 부분이 이미 준비되어 있다. 오버워치같이 꽤 큰 조직들마저 클라우드 플랫폼을 사용하는 이유가 이건데, 서버 시스템 엔지니어 수 명이 비싼 서버실을 대신 운영해주는 수준이기 때문이다. 수 분만에 리눅스 서버를 띄우고, 서버를 다중화하고, 트래픽을 분산시키고, 로그 메트릭을 적재적소에 전송하고, 도메인을 달고, 스토리지를 자동으로 백업하고, 인바운드/아웃바운드 접근 제어를 수정하고, 트래픽 상태에 따라 서버를 늘리고 줄이는 등의 설정이 클릭 몇 번으로 가능하다. 물론 아무것도 모르는 사람이 마음껏 설정할 수 있을 정돈 아니지만, 뭐 하나 세팅하려고 라우터에 접속해서 커맨드 치고있는 것보다 훨씬 쉽고 빠르며 정확하다.
-
SLA(Service-Level Aggrement, 서비스 수준 협약서)를 통해 인프라의 가동 시간을 보장받는다. 부득이하게 SLA에 명시된 만큼의 서비스 수준을 보장받지 못한다면, 페이백이나 크레딧 등을 통해 돈으로 보상받을 수 있다. 백엔드 조직이 서버를 직접 운영한다고 치면, 클라우드 플랫폼 만큼의 높은 가동 시간을 보장할 수 없을 것이라고 판단했다. -
인프라의 신속한 배치, 쉬운 자동화, 유연한 용량(확장성), 실패에 대한 대비(신뢰성), 규모의 경제가 주는 비용적 혜택, 전 세계에 어플리케이션을 쉽게 배포하고, 높은 수준의 보안과 품질 표준이 준수되어 있는 등 클라우드를 사용함으로써 얻을 수 있는 것이 수없이 많다.
클라우드 플랫폼이 얼마나 편하며 비용 걱정이 줄어드는지는 한 번 써보면 알 것이다. 몇몇은 '클라우드에 너무 의존하지 말라'고들 하지만, 나는 라우터 세팅같이 짜치는 일에 돈과 인생을 낭비하고 싶지 않다. 클라우드 컴퓨팅에 대해 조금 더 알고 싶다면 AWS의 '클라우드 컴퓨팅이란?' 문서를 읽어보자.
클라우드 플랫폼
배경과 요구사항
-
우리는 돈이 없다. 무료로 제공되는 범위가 클수록 좋다.
-
조직은 현재 AWS(Amazon Web Service)에 익숙하다.
선택지
-
AWS(Amazon Web Service)
-
GCP(Google Cloud Platform)
-
Microsoft Azure
의사결정
AWS(Amazon Web Service)를 선택하겠다. 그 이유는,
-
조직이 AWS에 가장 익숙하다.
-
AWS는 이미 클라우드 플랫폼 시장의 50% 이상을 점유하고 있으며, 수많은 대형 클라이언트들의 신뢰를 받고 있다.
-
모든 종류의 operation이 API화되어 있고, 이런 API에 접근할 수 있는 high level의 라이브러리(AWS SDK)들이 언어별로 잘 개발되어 있어서, 코드 레벨에서의 리소스 접근과 인프라 제어에 대한 장벽이 낮다.
-
AWS에 새로 회원가입하고 나면, 12개월간 주요 서비스를 일정 한도 내에서 무료로 이용할 수 있는 free tier를 제공해주는 건 덤이다. Google Cloud Platform과 Azure도 비슷하지만, AWS가 가장 후하게 무료 플랜을 제공해준다.
컴퓨팅 엔진
배경과 요구사항
-
프로젝트 시작 단계이므로 트래픽이 적고, 얼마나 늘어날지 예측 불가능하다. 트래픽의 양에 따라 서버의 스케일을 변동시키는 것에 도움을 받을 수 있어야 한다.
-
인프라를 직접 관리하는 범위가 적을수록 좋다.(개발자들은 코드를 제공하기만 되게)
-
Python으로 개발된 어플리케이션을 배포하는 데에 문제가 없어야 한다.
선택지
-
EC2(Elastic Compute Cloud)
-
Beanstalk
-
ECS(Elastic Container Service)
-
ECS+Fargate
-
Lightsail
-
Lambda
의사결정
Lambda를 선택하고, 추후에 ECS+Fargate로 마이그레이션을 진행하겠다. 그 이유는,
-
먼저, 트래픽에 따라 서버의 스케일을 변동시키는 Auto Scaling은 AWS를 비롯한 거의 모든 클라우드 서비스가 잘 제공하고 있는 기능이다. 물론 Lambda는 기본 지원이고 ECS는 설정을 좀 해줘야 한다는 차이가 있지만, AWS가 잘 추상화해 두어서 크게 어려운 건 아니라 Auto Scaling에 대한 가점/감점 요인은 없었다.
-
Lambda는 월마다 100만 개의 요청까지를 무료로 제공해준다. 정확히는 100만 초만큼의 함수 실행 시간을 무료로 제공해주는 것인데, 서비스가 인기몰이를 하기 전까진 이걸로 버텨볼만 하다. API 사용량이 많아지면 ECS+Fargate로 옮기는 것을 고려해보려 한다.
-
Lambda엔 서버가 존재하긴 하지만, 서버 관리의 주체는 우리가 아니고 Amazon이다(serverless). 이는 Amazon에서 관리하는 뛰어난 가용성을 가진 인프라에서 동작하기 때문에, 코드에 문제가 있는 것이 아니라면 API가 죽을 일이 거의 없다는 것이다. 알아서 여러 가용 영역(데이터 센터)에 걸쳐서 컴퓨팅 파워를 유지시키고, 우리가 따로 설정하지 않더라도 트래픽에 따라 서버를 축소/확장시키는
auto scaling도 기본으로 제공받는다. 우리는 컴퓨팅 파워를 직접 운영할 필요 없이, 코드를 제공하기만 하면 된다. 트래픽이 적고, 얼마나 늘어날지 예측 불가능한 현재 배경에 가장 알맞다. -
서비스가 커지면 과금 문제 때문에 lambda를 계속 유지하기가 어려울 것이다. lambda는 코드(함수)의 실행 시간에 비례하여 가격을 책정하는데, 일정 수준이 넘어가면 해당 트래픽의 처리기로 컴퓨팅 인프라를 직/간접적으로 따로 운영하는 것이 웬만하면 훨씬 싸다. 그 때를 생각해 추후 마이그레이션 대상으로
ECS+Fargate를 선택했다. 그 이유는 아래에서 설명한다. -
EC2는 모던한 컴퓨팅 파워 서비스인데, 이게 EC2만 달랑 쓰면 배포 파이프라인을 수립하기가 번거롭다. 예를 들어 2대 이상의 인스턴스에 동일한 웹 어플리케이션을 배포하려면, 하나 잡아서 배포해 두고 이미지를 그대로 떠서 복사시켜줘야 하는데, 구성도 귀찮고 오류에 대한 리스크도 크며 느리다. 차라리 EC2를 쓸거라면 Beanstalk이나 ECS같이 EC2를 기반으로 돌아가는 추상화 계층을 두어 이들의 도움을 받는 것이 좋을 것이라는 판단이다.
-
Beanstalk은 웹 어플리케이션을 간편하게 배포하고 조정할 수 있는 서비스다. heroku같은 PaaS를 생각하면 되는데, 세팅 조금만 하면 GitHub같은 데에 hook 걸어서 배포 자동으로 알아서 해주고 트래픽 변동이 생기면 서버 사이즈 scaling도 자동으로 해준다. 서버의 관리를 클라우드 제공자에게 위임하는 서버리스 형태를 유지하면서, lambda의 실행 시간에 비례한 과금 정책을 회피할 수 있게 된다. 위에서도 말했듯 EC2를 기반으로 돌아가는 추상적인 layer라고 볼 수 있는데, 추후 웹 어플리케이션의 런타임을 옮기는 입장에서 생각해 보면, 어차피 EC2 위에 뭔가 올려서 쓴다고 쳤을 때 그냥 조금 더 공부해서 ECS 쓰는 게 더 낫다는 판단이다.
-
ECS는 docker 컨테이너 orchestration 서비스다. 컨테이너식 어플리케이션은, 경량 가상화된 OS 위에서 어플리케이션을 실행하게 되므로 환경에 구애받지 않고 어플리케이션을 배포, 확장하며 빌드 과정을 파일로 표준화시킬 수 있는 여지가 생긴다. 배포 자동화던 scaling 자동화던 Beanstalk이나 ECS나 고만고만 하니까, 컨테이너식 어플리케이션의 메리트를 가져오자는 생각이다. 컨테이너식 어플리케이션은 관리의 입장에서 orchestration이 필요한데, kubernetes나 Docker swarm을 직접 운영하지 않더라도 ECS가 대신 해준다. 컨테이너와 docker가 어렵다면 초보를 위한 도커 안내서 시리즈나 AWS의 Docker란 무엇입니까?, 도커를 이용한 웹서비스 무중단 배포하기의 초반부 정도를 읽어 보자. 왜 백엔드 엔지니어들이 다 도커도커 거리는지의 이유를 대충 알게 될 것이다.
-
Fargate는 옵션에서 제거할 수 있는 부분이라 따로 선택지를 두었다. ECS는 EC2 인스턴스 위에 올릴 수도 있는데, 결국 이것도 컴퓨팅 자원을 따로 운영해야 하기에 관리 포인트가 될 수밖에 없다. Fargate는 컨테이너에 최적화된 별도의 컴퓨팅 엔진을 제공하고, 이를 직접 관리해 주므로 서버리스 컨테이너 엔진이라고 이야기할 수 있다. ECS와 Fargate를 묶어서 쓰게 되면, 서버리스 형태를 유지하며 컨테이너 기반 어플리케이션의 장점을 함께 가져가기에 좋을 것이라고 생각했다. 원래 Fargate가 EC2보다 한 2배 정도 비쌌어서 고민하고 있었는데, 최근에 요금 인하가 되어서 걱정이 좀 사라졌다.
-
Lightsail은 어플리케이션을 손쉽게 배포하고 관리하는 데에 필요한 필수적인 인프라(컴퓨팅, 스토리지, 데이터베이스, DNS 등)들이 자체적으로 포함되어 있는 플랫폼이다. 간단한 어플리케이션을 빠르게 셋업하는 데에 초점이 맞추어져 있는데, Lambda를 운영하는 것과 비교했을 때 그리 큰 메리트가 있어 보이지 않는다.
여기에 더해 terraform같은 Infrastructure as Code(IaC) 도구나, EKS(Elastic Kubernetes Service)를 통해 kubernetes 인프라를 직접 운영하는 간지나는 모습도 욕심은 나지만 조직 상황을 감안해서 보류했다. kubernetes 등으로 컨테이너 클러스터의 orchestration을 직접 수행하는 것은 비즈니스적 요구사항에 매우 유연하게 대응할 수 있겠지만, 조직이 크지 않은 상황에서 클러스터 자체 운영은 자칫하면 IaC와 kubernetes에 익숙하지 않은 현재 조직에게 휴먼 리소스의 낭비가 될 수 있으므로 ECS의 도움을 받으려 한다.
일러두기
Lambda?
Amazon Lambda는 '호출 기반으로 코드를 실행해주는 서비스'라고 요약할 수 있다. 호출을 수행하는 주체, 즉 event source는 대표적으로 CloudWatch, API Gateway가 있는데, 그 예를 들면,
-
CloudWatch의 호출 : 특정 EC2 인스턴스에서 CPU 사용량이 80%가 넘어가면, 설정해 둔 lambda 함수를 호출해 조직 내 슬랙의 특정 채널에 경고 메시지를 보낸다. 이러한 설정을 'CloudWatch 이벤트 트리거'라고 부른다.
-
API Gateway의 호출 : 외부의 요청이 들어오면, 설정해 둔 lambda 함수를 호출해 결과를 얻고 응답을 반환한다. 마치 웹 어플리케이션 서버를 호출하는 웹 서버(nginx 등)처럼 말이다.
우리는 API Gateway를 사용하는 후자의 방식을 사용할테고, AWS Lambda를 이용해서 HTTP API 만들기라는 outsider님의 포스트를 천천히 읽어보면 대충 무슨 말인지 알 것이다.
서버리스 어플리케이션 배포
위에 링크해 두었던 글을 읽어 보았다면, 우리는 Lambda에 코드를 배포하기 위해 아래의 과정을 거쳐야 한다는 것도 깨달았을 것이다.
-
소스 코드를 zip으로 패키징해 S3라는 object storage 서비스에 업로드한다.
-
소스 코드를 Lambda에 올려 새로운 버전의 코드가 lambda를 구성하도록 만든다.
-
만약 이게 최초 배포라면, API Gateway를 세팅해 준다. 특정 엔드포인트에 반응하여 lambda 함수를 호출하도록 말이다. CloudFormation같이 Amazon 자체에서 제공하는 Infrastructure as Code 서비스를 써야할 수도 있을 것이다.
물론 이걸 손으로 직접 클릭해가며 하진 않을테고 CLI에서 커맨드를 입력하는 방식을 사용하게 될텐데, 그렇게 생각하더라도 여간 귀찮은 일이 아닐 수 없다. update같은 커맨드를 입력하면 알아서 패키징하고, S3에 올리고, lambda를 세팅하고, API Gateway를 세팅해주는 도구가 있다면 매우 편할 것이다. Python 판에서는 zappa라는 서버리스 배포 헬퍼 라이브러리와 AWS에서 개발하고 있는 서버리스 프레임워크인 chalice가 높은 인지도를 가지고 있는데, 이미 조직이 Flask와 Sanic을 통해 웹 어플리케이션을 개발하는 것에 익숙한 상태라서 배포에 대해 도움을 받을 수만 있으면 되고, zappa가 서버리스 배포에 부족함이 없으므로 굳이 러닝커브를 감수할 필요가 없다고 생각했다. 우리는 서버리스 어플리케이션 배포를 위해 zappa를 사용할 것이다.
작업
Hello World 서버 배포하기
aws configure
먼저 zappa는 AWS 리소스에 대한 접근 권한이 필요하므로, 권한을 부여해 주어야 한다. AWS 콘솔에 로그인하고(계정이 없으면 만들자.), IAM이라는 서비스의 콘솔에 들어가 zappa를 위한 IAM 사용자를 만들자. 본인 계정의 AWS 콘솔에 접근할 수 있는 권한을 가진 또 다른 하위 사용자를 만드는 것이다. AWS 계정의 IAM 사용자 생성 가이드를 보며 따라하면 된다. 주의해야 할 것은,
-
액세스 권한 유형은
프로그래밍 방식 액세스(또는 Programmatic access)를 선택하자. -
권한 설정은 '기존 정책 직접 연결'을 선택해
AdministratorAccess를 부여하도록 하자. 필요한 권한만 연결하고, 그룹을 만드는 것이 여러모로 좋지만, 이건 따로 챕터를 진행할 것이다.
사용자를 생성하고 나면 Access Key ID와 Secret Access Key를 제공받을 수 있을텐데, CLI 터미널(cmd, terminal 등)을 켜고 아래의 순서에 따라 설정을 진행하자. AWS CLI 구성 가이드와 동일한 내용이다.
-
pip install awscli커맨드를 실행해 AWS CLI 툴을 설치하자. 일부러 pipenv 대신 pip를 사용했다. -
aws configure커맨드를 실행한 후 Access Key ID와 Secret Access Key를 붙여넣자. Default region name에는 원하는 지역을 AWS region 규칙에 따라 입력하자. 나는 서울 region을 사용할 것이므로,ap-northeast-2를 입력했다.
zappa init
pipenv install zappa 커맨드로 의존성 목록에 zappa를 추가함과 함께 패키지를 본인의 가상 환경에 설치하고 프로젝트 루트 디렉토리에서 zappa init 커맨드를 입력해 zappa 설정을 초기화하자. environment, bucket name같은 것들은 적당히 잘 입력하거나 default로 설정되도록 그냥 엔터만 누르면 되고, 'Where is your app's function?'에 대한 답만 잘 입력하자. app 객체가 있는 경로를 입력하면 되는데, 현재 Hello World 서버 기준으론 run.py 모듈에 객체 이름이 app이므로 run.app이라 입력할 것이다. 내 경우 pipenv install 시 Python 3.7.1 버전으로 초기화되었는데, zappa가 Python 2.7과 3.6만을 지원해서 pipenv install --python 3.6 커맨드로 pipenv를 다시 초기화하고 진행했다. 성공하면 zappa_settings.json이라는 파일이 새로 생길 것이다. pipenv install zappa, zappa init 직후의 스냅샷
이제 배포 준비가 완료되었지만, 문제는 Sanic 어플리케이션을 zappa로 업로드하는 과정에 오류가 많다는 것이다. zappa에서는 마이크로 프레임워크로 Flask를 공식 지원하고 있고, Sanic은 Flask-like하게 만들어져 있으므로 Hello World 서버를 Flask 기반으로 변경하자. Pipfile에도 반영하고, 코드에도 반영해야 한다. 변경 직후의 스냅샷
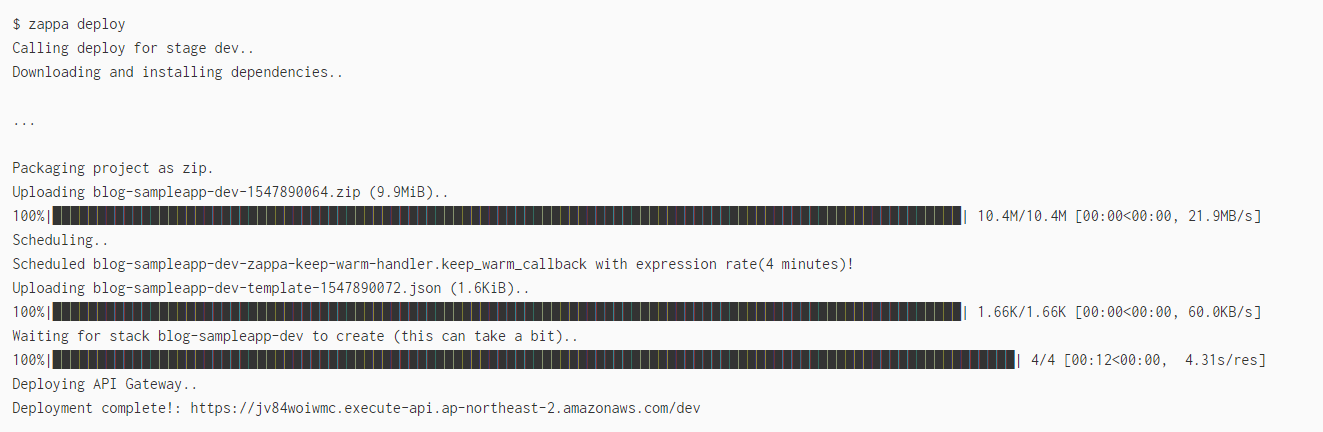
이제 정말 배포만 남았다. zappa deploy를 입력하고 조금 기다리면 https://abc.execute-api.us-east-1.amazonaws.com/...같은 형태의 URL이 콘솔에 보여질 것이다.
$ zappa deploy
Calling deploy for stage dev..
Downloading and installing dependencies..
...
Packaging project as zip.
Uploading blog-sampleapp-dev-1547890064.zip (9.9MiB)..
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 10.4M/10.4M [00:00<00:00, 21.9MB/s]
Scheduling..
Scheduled blog-sampleapp-dev-zappa-keep-warm-handler.keep_warm_callback with expression rate(4 minutes)!
Uploading blog-sampleapp-dev-template-1547890072.json (1.6KiB)..
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 1.66K/1.66K [00:00<00:00, 60.0KB/s]
Waiting for stack blog-sampleapp-dev to create (this can take a bit)..
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:12<00:00, 4.31s/res]
Deploying API Gateway..
Deployment complete!: https://jv84woiwmc.execute-api.ap-northeast-2.amazonaws.com/dev그대로 복사해서 브라우저로 접속해 봤을 때, 'Hello World'가 뜨면 성공이다. 사람들이 그렇게나 말하던 서버리스 어플리케이션을 배포한 것이다.


7개의 댓글

안녕하세요. 우선 글 잘 읽고 있습니다 !
글을 보던 중 사소한 오타를 발견하였는데 혹시나 도움이 될까 댓글 남겨봅니다.
컴퓨팅 파워의 출처를 선택하시는 부분에서 선택 이유중 SLA에 대한 설명을 남기실 때 Agreement를 Aggrement로 잘못 표기하신 것이 있어서 댓글 남겼습니다 ㅎㅎ..
좋은 글 잘 읽도록 하겠습니다. 앞으로도 좋은 글 부탁드립니다 !
안녕하세요 올려주시는 글 잘 읽고 있습니다!
저는 서버리스 프레임워크들에 대해 관심이 많기도 하고
PlanB 님께서 어떤 기술의 도입에 대한 의사결정의 근거를 잘 정리해 주시니
궁금한 마음에 여쭤봅니다
Python Serverless 프레임워크 중에는
인지도 면에서는 Serverless Framework 도 널리 알려져있고
chalice 는 aws 에서 개발한 오픈소스 프레임워크인데
zappa 만이 거의 유일 하다고 판단하신 이유가 있을까요...?
(두 가지 다 편하게 잘 사용했던 경험이 있어서요. 저는 현재 Serverless Framework 를 사용 중입니다)
혹시 다른 것도 사용해 보셨으면 어떤 면에서 zappa 가 좋았는지 알려주시면
큰 도움이 될 것 같습니당
감사합니다.