LLM 서빙과 KV Cache, vLLM
최근 출시되는 오픈소스 LLM들은 MoE, quantization 기법등의 적용으로, M4 맥북, RTX4090과 같은 개인용 GPU 수준에서도 추론이 가능해지고 있습니다.
하지만 동시에 여러 사람들에게 서빙되어야하는 LLM Service에서는 얘기가 조금 다릅니다. Transformer 기반 LLM의 특성상, 동시 요청 수에 따라 필요한 VRAM이 선형적으로 증가하기 때문인데요. 메모리 사용량이 증가하는 대부분의 이유는 KV Cache 때문입니다.
OOM 방지 및 현재 수용 가능한 동시 요청 수 등을 파악하기 위해서 이런 부분을 어느정도 계산할 수 있는 것이 좋을 것 같아 우선 KV Cache가 무엇인지부터 어떻게 요청 당 메모리 요구량을 계산할 수 있는지 정리해보려고 합니다.
KV Cache
KV Cache에서 K, V는 각각 어텐션 매커니즘의 Key, Value를 뜻합니다. KV Cache는 말 그대로 Key, Value를 캐싱하여 저장하는 저장소입니다.
KV Cache가 필요한 이유는 연산량을 줄일 수 있기 때문입니다.
번째 출력 토큰을 계산하기 위해서는 까지의 컨텍스트, 즉 attention 계산에 사용되는 key, value 값이 필요합니다. 번째 출력 토큰에는 까지의 컨텍스트가 필요하구요.
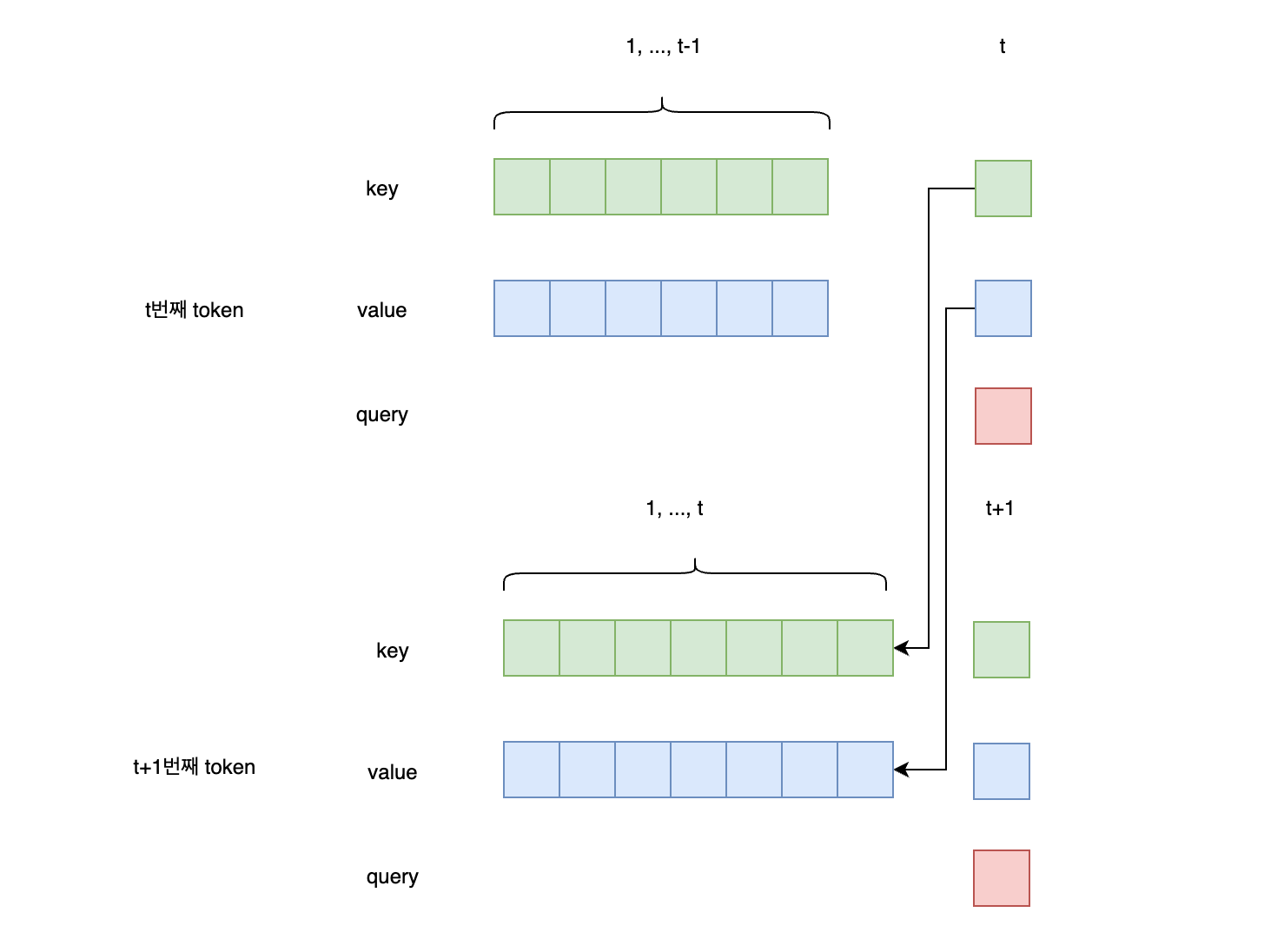
이 때 매번 key, value 전체를 새로 계산할 필요 없이, 이전 시점의 key, value값을 저장해 주었다가, 현재 시점의 key, value만 새로 계산하는 것으로 연산량을 극적으로 줄일 수 있습니다.
즉 이를 위해 이전 시점까지의 key, value를 모두 저장하고 있어야하는데, 이것이 KV Cache 입니다.
KV Cache의 크기 계산 (naive)
 출처:
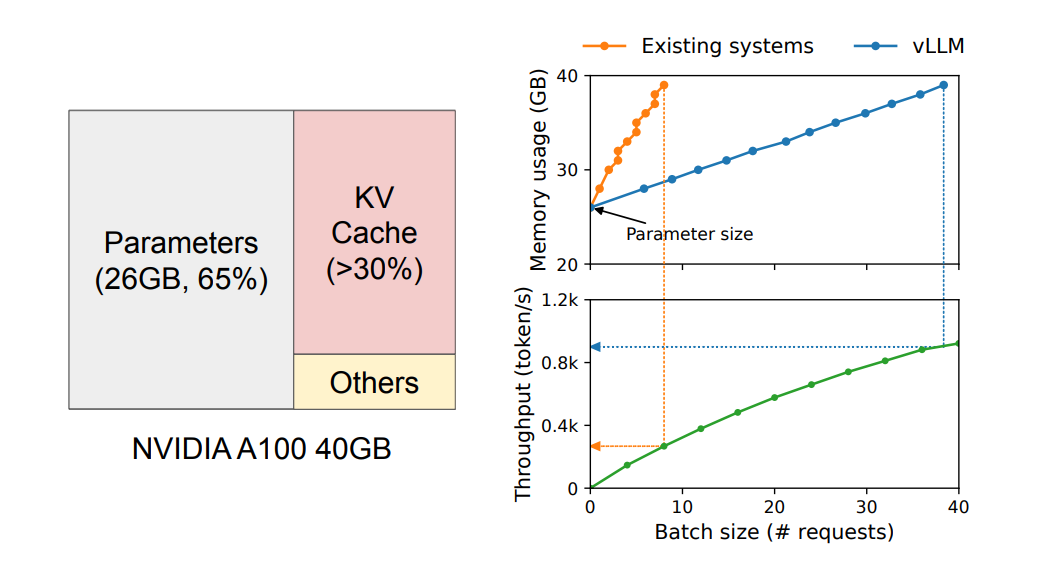
출처: KV Cache가 차지하는 크기는 결코 작지 않은데요.
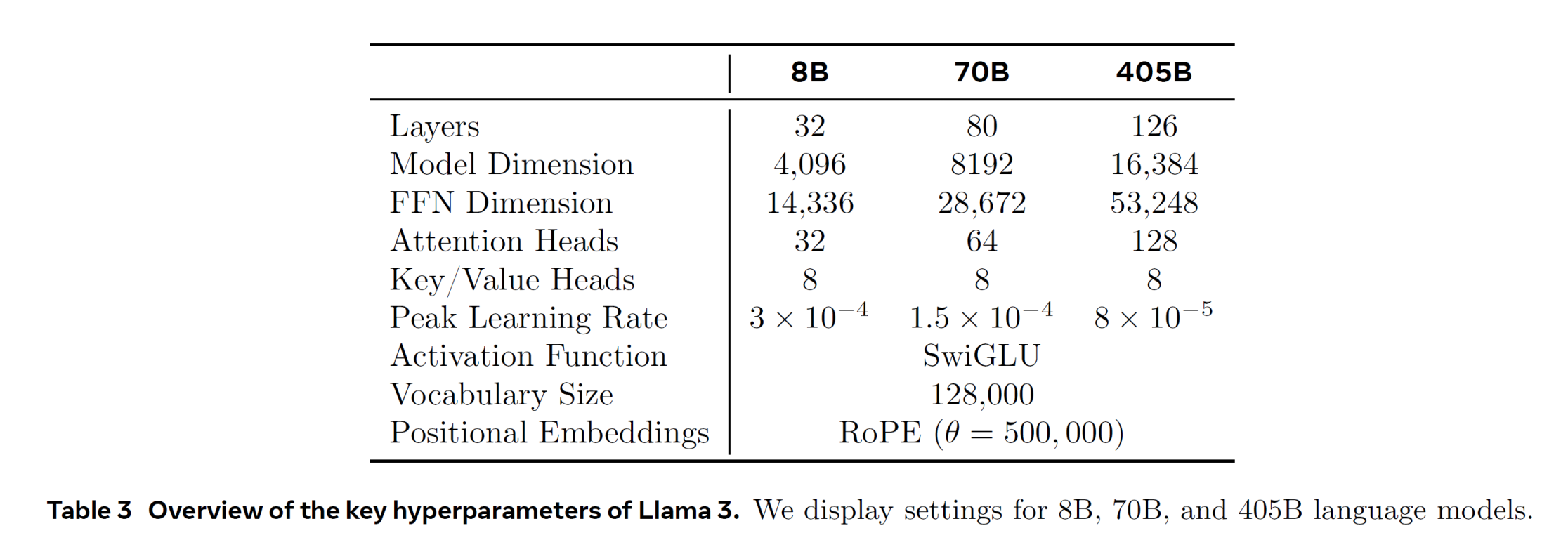
llama3.1의 표를 보면 토큰 하나에 필요한 KV Cache의 개수는 다음과 같습니다.
- Layers = 32
- hidden_size = 4096 (
config.json참조)
(참고) 최신 LLM들은 여러가지 방법론을 사용해서 실제 추론중에 필요한 KV Cache를 훨씬 더 적게 요구합니다. 예를들어 위 llama 3.1표에서도 GQA라는 방법론을 사용해서 실제 필요한 KV Cache는 제가 계산하는 것보다는 훨씬 적습니다. 다만 이해를 위해서 우선 곧이곧대로 계산해보겠습니다.
(key, value 1개씩 2개) x (layers) x (hidden_size) x 2Byte(FP16)
즉 토큰 1개에 필요한 KV Cache는 512KB가 됩니다.
만약 Input token length가 1024개, max token length가 1000개라면
llama 3.1 8b는 최대 128K의 context length를 갖는데, 이를 그대로 적용하면 요청하나가 64GB로 A100 1개로는 이미 감당할 수 없게 됩니다.
예를 들어 8B 크기의 llama3.1을 FP16으로 A100 GPU에 서빙하면 모델 파라미터가 약 16GB가 필요하고 대략 20GB 정도의 메모리를 KV Cache로 사용할 수 있으니, context length를 4K 정도로 타협해야 겨우 10개 정도를 동시에 처리할 수 있게됩니다.
VLLM
이 문제를 해결하려면 VRAM이 더 많이 필요하다는 결론을 얻을 수 있는데요
GPU가 좋아져도 보통 FLOPs가 좋아지지, VRAM이 극적으로 증가하지는 않습니다. 즉 좋은 GPU보다는 GPU 여러개를 묶어서 서빙할 수 있는 방법이 필요합니다.
이를 간단히 해결해주는 것이 바로 VLLM과 같은 모델 서빙 프레임워크입니다.
VLLM 공식문서에서 확인할 수 있듯, 멀티 GPU 노드 또는 멀티 노드의 GPU를 하나로 묶어 서빙하는 기능을 제공합니다.
INFO 07-23 13:56:04 [kv_cache_utils.py:775] GPU KV cache size: 643,232 tokens
INFO 07-23 13:56:04 [kv_cache_utils.py:779] Maximum concurrency for 40,960 tokens per request: 15.70x앞서 계산했던 KV Cache또한 자동으로 계산해주는데, 로그를 통해 KV Cache가 643,232 토큰을 동시에 저장할 수 있으며, 이는 Max Context length를 40,960으로 설정했을 때 15개의 동시 요청을 처리할 수 있다는 뜻입니다.
KV Cache의 효율적인 사용
앞서 본 것처럼 KV Cache의 메모리 사용량은 요청 수와 컨텍스트 길이에 선형적으로 비례하기 때문에, 단순히 모든 요청마다 최대 context length만큼의 KV Cache를 예약해 두면 VRAM 낭비가 심각하게 발생합니다.
실제 LLM 서비스 환경에서는 모든 사용자가 항상 최대 길이의 컨텍스트를 쓰는 것이 아니며, 요청의 길이와 수명도 동적으로 변하기 때문에 연속적인 메모리 할당 방식은 다음과 같은 두 가지 문제를 유발합니다.
1. Internal fragmentation
KV Cache를 연속된 공간에 최대 길이 기준으로 할당하기 때문에 실제 필요한 크기보다 더 많은 공간이 항상 예약됩니다. 예를 들어 context length가 4K만 필요한 요청도 128K 기준의 메모리를 점유하게 되어 낭비가 심해집니다.
2. External fragmentation
GPU 메모리 공간 중간중간이 비어 있어도, 그 크기가 요청의 최대 context length보다 작다면 재사용할 수 없게 됩니다. 즉, 작은 빈 공간들이 쌓여 전체적으로는 VRAM에 여유가 있어 보이지만 새로운 요청을 수용하지 못하는 상황이 발생합니다.
이 문제를 해결하기 위해 vLLM에서는 PagedAttention 기법을 도입했습니다.
PagedAttention
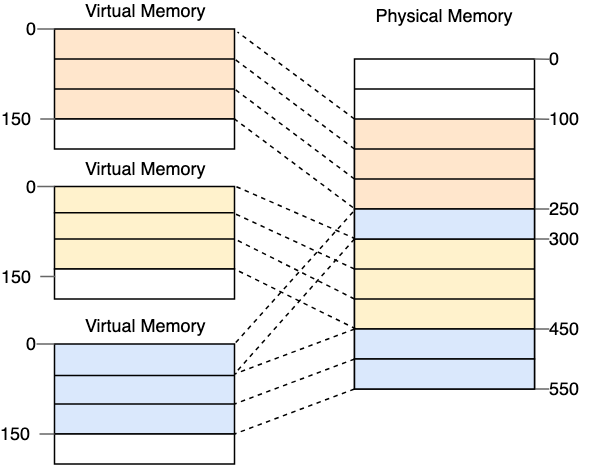 현대 OS의 메모리 페이징 기법
현대 OS의 메모리 페이징 기법
출처 : Philipp Oppermann's blog
PagedAttention은 KV Cache를 블록 단위로 분할하여 저장, 사용하는 어텐션 기법입니다. 운영체제를 배울 때 항상 등장하는 메모리 페이징 기법과 유사합니다.
각 블록은 고정된 크기의 토큰(Key/Value)을 저장할 수 있는 단위이며, 연속된 메모리 공간에 배치될 필요가 없습니다.
요청별로 필요한 KV Cache 크기만큼만 블록을 할당할 수 있으므로 internal fragmentation 문제를 크게 줄일 수 있습니다. 모든 블록 크기가 동일하기 때문에, VRAM 내의 빈 블록은 어디든 재활용 가능하여 external fragmentation 문제가 제거됩니다.
즉, PagedAttention는 현대 OS의 메모리 관리에 사용되는 페이징 기법을 이용해 동일한 VRAM 환경에서 훨씬 더 많은 동시 요청을 처리할 수 있게 해줍니다.
결론
KV Cache는 LLM 추론에서 가장 큰 메모리 사용 요인이기 때문에 모델 서빙시 반드시 고려해야 합니다.
vLLM을 이용할 경우 Max Context Length를 기준으로 계산을 제공해주지만, 대력적으로 어떻게 계산하는지 알면 도움이 될 것 같아서 따로 정리해보았습니다. (GQA, Quantization을 통해 필요한 KV Cache는 위에서 계산한 naive한 값보다는 더 줄어듭니다. 이것까지 다루기엔 너무 많아서 따로 다루겠습니다.)
vLLM은 이런 모델 서빙외에도 LLM에 특화된 기능들을 많이 제공해주는데, 그중 핵심이 GPU를 더 효율적으로 사용할 수 있도록 하는 PagedAttention입니다.
이를 고려해서 추론 서버로 요청을 넘기기 전에, 앞단에서 예상되는 Cache를 계산해준다면 모든 요청을 Max context length로 간주하지 않고, 더 유연하게 많은 요청을 처리할 수 있을 것 같습니다.
예를들어 요청마다 예상 KV Cache 사용량을 미리 추정하고, 이를 기반으로 admission control(대기열 관리)을 하면 OOM 없이도 더 안정적인 서빙이 가능한데, 이 부분이 엔지니어링 측면이 될 것 같네요
