Regularization
- 학습을 방해하는 패널티를 부여하는 것을 통해, 모델이 test data에 대해서도 잘 동작하게 하는 방법론이다.
- Generalization Performance(일반화 성능)을 높이기 위한 목적으로 사용하는 일종의 도구이다.
- 주로 이론적인 것보다는 실험적(practical)으로 증명된 방법을 많이 사용한다.
Early Stopping
- 말 그대로 학습을 일찍 멈추는 방법이다.
- Validation data로 검증하면서, validation error가 커지기 시작하는 지점에서 멈추는 방법이다.
- train data외에 validation data가 추가로 필요하다.
Parameter Norm Penalty
- 신경망의 parameter 크기가 너무 커지지 않게하여 웨이트(W)의 크기에 제한을 두는 방법이다.
- 모든 웨이트 파라미터를 제곱한 것의 합을 줄인다.
total cost = loss function + a/2||W||^2
Data Augmentation
- 신경망이나 딥러닝에서는 거의 항상 데이터가 많을수록 좋다.
- 하지만 데이터는 한정되어있는데, data augmentation은 주어진 학습 데이터를 다양한 방법으로 변형하여 새로운 학습 데이터로 활용하는 방법이다.
- 이미지 데이터를 예로들면, 이미지를 회전시키거나 찌그러트리는 등 라벨이 바뀌지 않는 선에서 변형시켜 이용할 수 있다.
- 예를들어 6을 뒤집으면 9가되는데, 이는 라벨이 바뀌므로 Data augmentation이라 할 수 없다.
Noise Robustness
- 입력 데이터에 일부러 노이즈를 주는 방법이다.
- 이렇게 하면 일반화 성능이 좋아진다는 것이 실험적으로 증명되었다.
Label Smoothing
- 학습 데이터 2개를 섞어 새로운 mix-up 데이터를 만드는 방법이다.
- 분류문제에서 decision boundary를 부드럽게 만들어주기 위한 목적으로 사용한다.
CutMix 방법
- 이미지 데이터를 cutmix하는 방법의 예는 다음과같다.
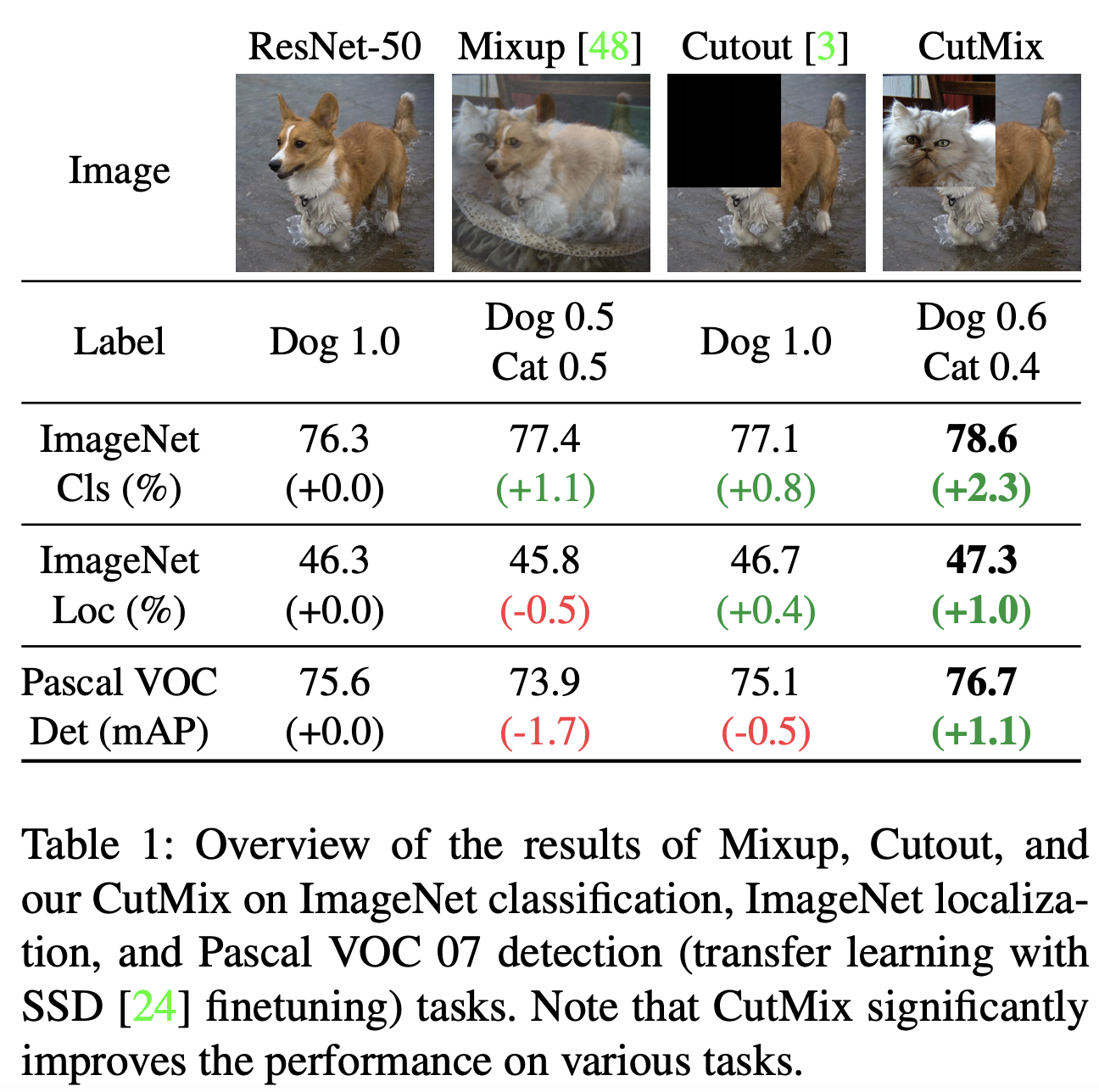
- Mixup : 두 가지 데이터의 라벨과 이미지를 겹치게 섞는다.
- Cutout : 이미지의 일정 영역을 잘라낸다.
- CutMix : 서로 다른 두 이미지를 잘라 붙인다.
Dropout
- 신경망에서 웨이트의 일부를 0으로 바꾸는 방법이다.
- dropout ratio가 0.5이면 weight의 50%을 0으로 바꾼다는 뜻이다.
Batch Normalization
-
신경망에서 batch size 만큼의 레이어를 선택하여, 평균을 빼고 분산으로 나누어 0 근처의 값으로 줄이는 방법이다.
-
layer가 깊게 쌓여있을 수록 일반화 성능이 잘 오르는 경향이 있다.
-
Batch는 전체 층에 대해 적용(Batch Norm)하거나, 각각의 레이어에 적용(Layer Norm), 데이터 하나에 적용(Instance Norm), 원하는 양만큼 그룹화하여 적용(Group Norm)하는 등 다양하게 적용할 수 있다.
