Pytorch 실습
1. Kaggle data download
kaggle에서 찾을 수 있는 yelp_light 데이터를 이용한 레스토랑 리뷰 감성 분류기 실습
(다운로드 링크 : https://www.kaggle.com/datasets/hhalalwi/yelp-light?select=raw_train.csv)
이 데이터는 고객들이 남긴 리뷰와 해당 리뷰가 긍정인지 부정인지 알 수 있는 라벨로 구성되어 있다.
이 실습에서는 고객들이 남긴 리뷰를 input으로 넣어 해당 리뷰가 긍정인지 부정인지 분류하는 간단한 분류기를 만들 예정이다.
- 실험에 사용할 데이터 확인
import pandas as pd
# pandas 라이브러리는 데이터 처리와 분석을 위한 라이브러리로 행/열로 이루어진 데이터 객체를 만들어 다룰 수 있다.
train_data = pd.read_csv(filepath_or_buffer='./raw_train.csv', header=None)
# filepath_or_buffer : 데이터 경로
# header : 해당 파일에 header가 없는 경우에 None으로 설정
train_data.head(5)
# 읽어온 데이터의 상위 5개 출력
위의 코드로 csv 파일을 pandas의 DataFrame객체로 읽어올 수 있다.
DataFrame 객체는 행과 열로 이루어져 있고, 현재 읽어온 데이터는 [0,1]이라는 두개의 column과 각 row들로 이루어져 있다.
(가장 왼쪽의 숫자는 해당 row의 index 번호를 의미한다.)
'0' column은 우리가 학습할 데이터의 정답을 의미한다. (1은 부정, 2는 긍정)
'1' column은 모델의 input으로 들어갈 고객들의 리뷰내용이다.
상위 5개의 row를 확인하면 위의 결과 사진과 같고, 2번째/5번째 row는 긍정적인 리뷰이며, 나머지 3개는 부정적인 리뷰인 것을 확인할 수 있다.
# column 이름을 각각 rating과 review로 변경
train_data.rename(columns={0:'rating', 1:'review'}, inplace=True)편의상 '0', '1' column을 각각 'rating', 'review'라는 이름으로 변경한다.
# 읽어온 데이터 정보 확인
train_data.info()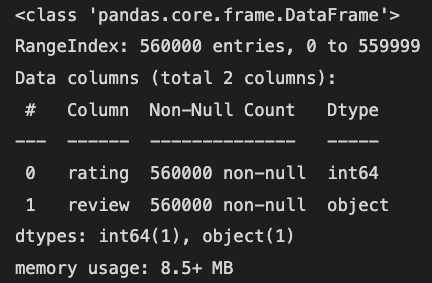
위 코드로 해당 데이터의 정보를 읽어올 수 있다.
# rating column을 채우고 있는 데이터들 중복없이 확인
train_data['rating'].unique()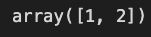
정답 라벨인 'rating' column을 확인해보면 [1,2]로 이루어져 있는 것을 알 수 있고, 이 때 1은 부정, 2는 긍정적인 리뷰를 의미한다.
2. train, val data로 데이터 분리
전체 데이터를 학습용으로 사용할 수 있지만, 학습이 잘 되었는지 확인하기 위해서는 학습에 사용하지 않은 데이터를 이용하여 분류를 해야한다.
따라서, 데이터를 train set과 validation set으로 분리한다.
train/validation set에 긍정적인 리뷰와 부정적인 리뷰를 적절히 섞어줘야 올바른 평가를 할 수 있기 때문에, 긍정적인 리뷰와 부정적인 리뷰를 따로 나누어서 수행한다.
'split'이라는 이름의 컬럼을 새로 만들어 train data는 'train'으로, valid data는 'valid'로 표시한다.
# 긍정적인 리뷰와 부정적인 리뷰로 DataFrame 쪼개기
pos_train_data = train_data[train_data['rating'].apply(lambda x:x==1)]
neg_train_data = train_data[train_data['rating'].apply(lambda x:x==2)]
# 긍정적/부정적 데이터 개수
num_pos_split = len(pos_train_data)
num_neg_split = len(neg_train_data)
# train, valid 나누는 비율로 train을 총 데이터의 80%로 가져간다
train_proportion = 0.8
# 데이터의 행을 무작위로 섞어준다
# 행을 섞는 과정에서 index도 같이 섞이기 때문에 reset_index 메소드를 통해 index를 재조정한다
pos_train_data = pos_train_data.sample(frac=1).reset_index(drop=True)
neg_train_data = neg_train_data.sample(frac=1).reset_index(drop=True)
# 'split' 컬럼을 새로 만들어 train/valid set을 구분해준다
pos_train_data.loc[:int(train_proportion * num_pos_split), 'split'] = 'train'
pos_train_data.loc[int(train_proportion * num_pos_split) + 1:, 'split'] = 'val'
neg_train_data.loc[:int(train_proportion * num_neg_split), 'split'] = 'train'
neg_train_data.loc[int(train_proportion * num_neg_split) + 1:, 'split'] = 'val'
# 긍정적/부정적 데이터를 하나의 DataFrame으로 합친다
final_df = pd.concat([pos_train_data, neg_train_data], axis=0).reset_index(drop=True)
final_df.head(5)3. 데이터 전처리
현재 데이터의 review를 그대로 사용하기에는 알파벳 이외의 문자들이 많이 포함되어 있다.
학습에서 사용할 사전을 만들때는 단어 (띄어쓰기) 단위로 만들것이기 때문에 데이터에 전처리가 필요하다.
- 대문자는 모두 소문자로 변경
- . , ? ! 문자의 경우 앞,뒤로 공백 추가
- 알파벳 . , ? ! 문자 이외의 문자는 공백으로 대체
import re
def preprocess(text):
"""Review 데이터 전처리 함수
Args:
text (str): 전처리를 진행할 review
Returns:
str: 전처리가 완료된 review
"""
# 소문자로 변경
text = text.lower()
# . , ? ! 문자의 경우 앞뒤로 공백 추가
text = re.sub(r"([.,?!])", r" \1 ", text)
# 알파벳 . , ? ! 이외의 문자들을 공백으로 대체
text = re.sub(r"[^a-z.,!?]+", r" ", text)
return text
for dataset in total_dataset.values():
dataset['review'] = dataset['review'].apply(preprocess)4. token 사전 만들기
문자열로 구성된 데이터를 모델에 넣기 위해서는 벡터형태로 변환이 되어야한다.
따라서 각각의 단어마다 고유의 숫자를 배정해주는 사전을 만든다.
python의 dictionary를 사용하여 tokenize를 진행한다.
class Vocabulary():
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx # token -> index
self._idx_to_token = {idx:token for token, idx in self._token_to_idx.items()} # index -> token
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
return cls(**contents)
def add_token(self, token):
"""단어를 사전에 추가하는 함수
Args:
token (str): 추가할 단어
Returns:
int: 해당 단어(token)의 index
"""
if token in self._token_to_idx:
index = self._token_to_idx[token]
else:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def lookup_token(self, token):
"""사전에 기록된 단어의 index를 반환하는 함수
Args:
token (str): index를 확인할 단어
Returns:
int: 해당 단어의 index
"""
if self._add_unk:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""lookup_token 함수의 반대 작용을 하는 함수
"""
if index not in self._idx_to_token:
raise KeyError(f'Vocabulary에 인덱스 {index:%d}가 없습니다.')
return self._idx_to_token[index]
def __len__(self):
"""단어 사전에 기록된 전체 단어 개수를 반환하는 함수
Returns:
int: 단어 사전에 기록된 단어 개수
"""
return len(self._token_to_idx)5. Dataset class 만들기
Pytorch는 Dataset 클래스로 데이터셋을 추상화한다.
따라서 새로운 데이터셋을 사용할 때는 Dataset 클래스를 상속하여 getitem과 len메서드를 구현해야한다.
데이터에서 단어들을 추출하고, 해당 단어들로 데이터셋을 만든다.
이 때, 특정 횟수 이상 나온 단어들만 단어 사전에 추가하도록 한다.
이후, 모델에 넣어줄 수 있는 형태인 vector로 표현하기 위하여 one-hot vector로 vectorize를 진행한다.
class ReviewDataset(Dataset):
def __init__(self, review_df, cutoff=25):
self.review_df = review_df
self.train_df = self.review_df[self.review_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.review_df[self.review_df.split=='val']
self.val_size = len(self.val_df)
self.test_df = self.review_df[self.review_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_df = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.val_size),
'test': (self.test_df, self.test_size)}
self._review_vocab = Vocabulary(add_unk=True)
self._rating_vocab = Vocabulary(add_unk=False)
# 정답 라벨에 대한 사전을 만드는 부분
for rating in sorted(set(review_df['rating'])):
self._rating_vocab.add_token(rating)
# review 데이터로부터 사전을 만드는 부분
word_counts = Counter()
for review in review_df.review:
for word in review.split(' '):
if word not in string.punctuation and word != '':
word_counts[word] += 1
for word, count in word_counts.items():
if count > cutoff:
self._review_vocab.add_token(word)
self._len_vocab = len(self._review_vocab._token_to_idx)
def set_split_target(self, split_target='train'):
"""해당 데이터셋이 train인지 validation인지 구분
Args:
split_target (str, optional): 해당 데이터셋을 분류. Defaults to 'train'.
"""
self._target_df, self._target_size = self._lookup_df[split_target]
def vectorize(self, review):
"""tokenize된 리뷰를 모델에 넣을 수 있는 one-hot vector형식으로 만드는 부분
Args:
review (str): 리뷰내용
Returns:
np.ndarray: 해당 리뷰의 one-hot vector
"""
one_hot = np.zeros(len(self._review_vocab._token_to_idx), dtype=np.float32)
for token in review.split(' '):
if token not in string.punctuation and token != '':
one_hot[self._review_vocab.lookup_token(token)] = 1
return one_hot
def __getitem__(self, idx):
row = self._target_df.iloc[idx]
review = self.vectorize(row['review'])
rating = self._rating_vocab.lookup_token(row['rating'])
return {'x_data': review,
'y_target': rating}
def __len__(self):
return self._target_size
6. Model 클래스
모델은 linear layer하나로 간단하게 구성하였다.
num_features에는 단어 사전의 총 길이가 들어간다.
class ReviewClassifier(nn.Module):
def __init__(self, num_features):
super(ReviewClassifier, self).__init__()
self.fc1 = nn.Linear(in_features=num_features, out_features=1)
def forward(self, x, apply_sigmoid=False):
y = self.fc1(x).squeeze()
if apply_sigmoid:
y = torch.sigmoid(y)
return y7. training
먼저 학습에 필요한 각종 parameter들을 선언해놓는다.
loss 함수, optimizer를 선언하고 학습에 들어간다.
- Dataloader : 학습에 필요한 미니배치로 모으는 작업을 해주는 파이토치 내장클래스
- criterion : loss를 계산할 함수
- optimizer : 가중치 업데이트 함수
- model : 위에서 간단하게 구현한 분류기
args = Namespace(
cutoff = 25,
batch_size = 128,
learning_rate = 1e-3,
num_epochs = 10,
seed=2023,
device = 'cuda' if torch.cuda.is_available() else 'cpu',
model_save_path = '/checkpoints')
dataset = ReviewDataset(final_df, cutoff = args.cutoff)
model = ReviewClassifier(num_features=dataset._len_vocab)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=args.learning_rate)
for epoch in range(args.num_epochs):
dataset.set_split_target('train')
train_loader = DataLoader(dataset=dataset, batch_size=args.batch_size, shuffle=True, drop_last=True)
model.train()
total_train_loss = 0.0
for batch_idx, item in enumerate(train_loader):
x = item['x_data'].to(args.device)
y = item['y_target'].to(args.device)
# 기울기를 0으로 초기화하는 부분
optimizer.zero_grad()
# 모델이 추론한 결과
y_pred = model(x)
# loss
loss = criterion(y_pred, y.float())
loss_batch = loss.item()
# batch 학습이 끝날 때마다, 전체 평균을 구하는 부분
total_train_loss += (loss_batch - total_train_loss) / (batch_idx + 1)
# 손실을 사용해 기울기를 계산하는 부분
loss.backward()
# 가중치 업데이트 부분
optimizer.step()
dataset.set_split_target('val')
val_loader = DataLoader(dataset=dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)
model.eval()
total_val_loss = 0.0
best_loss = 100000000
for batch_idx, item in enumerate(val_loader):
x = item['x_data'].to(args.device)
y = item['y_target'].to(args.device)
y_pred = model(x)
loss = criterion(y_pred, y.float())
loss_batch = loss.item()
total_val_loss = (loss_batch - total_val_loss) / (batch_idx + 1)
# 만약 validation loss가 기존 loss보다 작다면 모델 저장
if total_val_loss < best_loss:
torch.save(model.state_dict(), os.path.join(args.model_save_path, f'{epoch}.pth'))참고 문헌 : 파이토치로 배우는 자연어 처리
