Data Layer란?
0개 이상의 데이터 소스를 포함할 수 있는 저장소, application data와 business logic 데이터가 포함된다.
💡 이와 같은 역할을 수행하기 위해 구글에서는 한 개의 데이터가 존재하더라도 무조건 repositoriy를 만들도록 권장한다.Repository Class의 역할
- 앱의 나머지 부분에 데이터 노출하기
- 데이터에 대한 변경 사항을 중앙 집중화하기
- 여러 데이터 소스 간의 충돌 해결하기
- 데이터 소스의 추상화하기
- 비즈니스 로직을 포함하기
-
안드로이드에서는 단방향적인 계층구조를 준수하라고 권장한다. Data Layer에 접근하려면 반드시 Repository를 거쳐야 하며 UI Layer가 직접 접근성을 가져서는 안된다.
-
Data Layer에서 노출된 데이터는 immutable해야 하며, 이러한 부분이 준수되지 않으면 데이터의 일관성을 해칠 수 있다.
그림으로 표현한 Data Layer
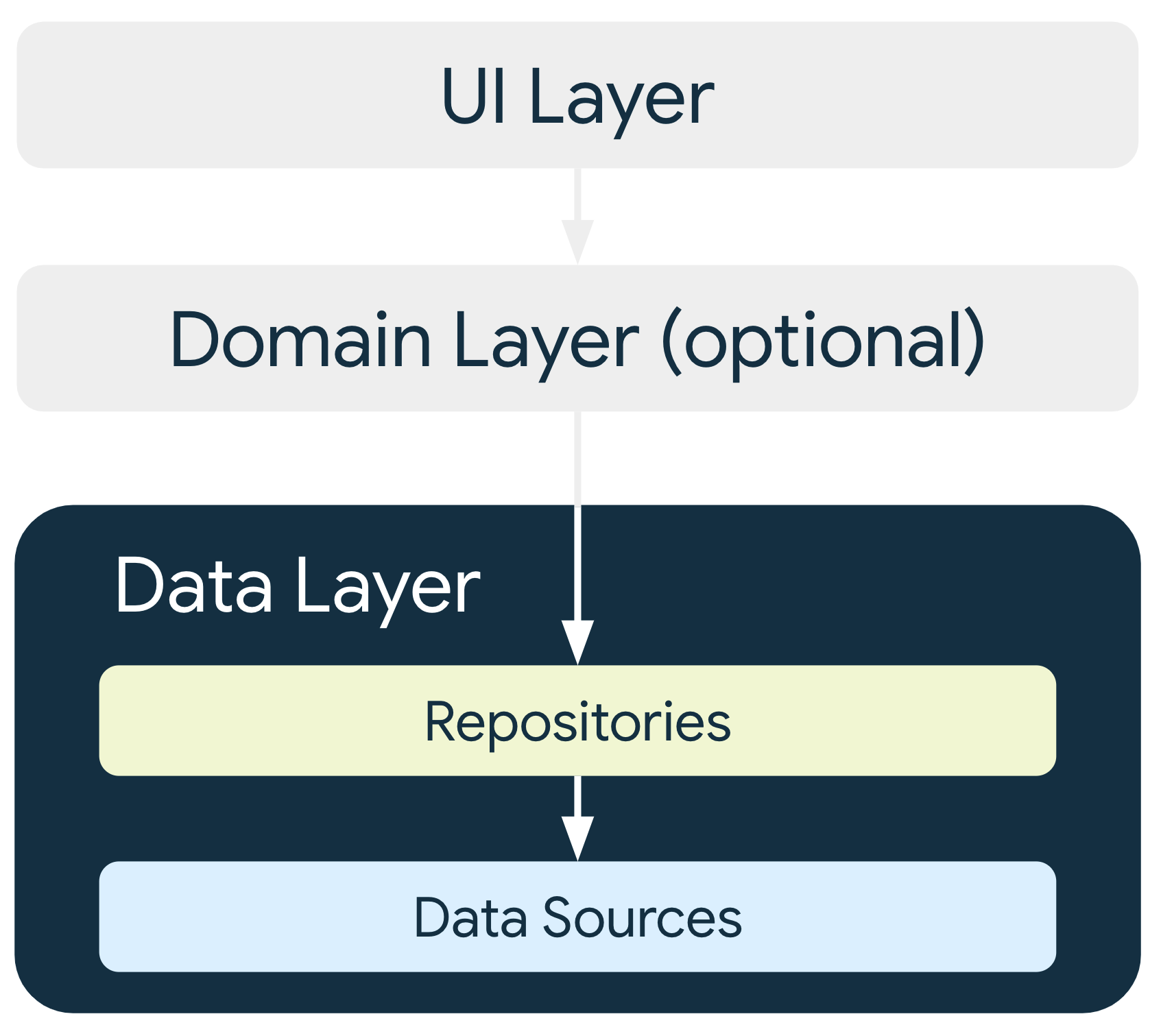
Data Layer 클래스의 동작
경우에 따라 One-shot operations와 To be notified of data changes over time으로 나뉜다. 공식 문서에서 자바의 경우도 별도 설명이 있었으나 코틀린만 적어보겠다.
**One-shot operations:**
데이터 레이어는 코틀린에서 함수를 사용해 반환값을 노출해야 한다.**To be notified of data changes over time:**
데이터 레이어는 코틀린에서 flows를 노출해야 한다.- Data Source 및 Repository 호출은 굉장히 안전해야 한다. 이는 suspend 호출과 같은 API를 통해 이루어지며 코루틴을 공부하면 추가적으로 알 수 있다.
권장되는 네이밍 컨벤션
- 레포지토리 클래스는 type of data + Repository를 사용한다.
(ex: NewsRepository)- 데이터 소스는 type of data + type of source + DataSource를 사용한다.
(ex: NewsDiskDataSource)
UI layer와 Data Layer를 분리함으로 얻는 효과
- 데이터를 여러 화면에서 사용
- 앱의 다른 부분 간에 정보를 공유
- UI 외부에서 비즈니스 로직을 단위 테스트하기 위해 비즈니스 로직을 복제하는 것이 가능해짐
다층 구조 Repositories
복잡한 비즈니스 요구 사항이 포함되면 Repository는 다른 Repository에 종속될 수 있다. 데이터의 소스가 여러개 존재하거나 다른 Repository Class에 캡슐화가 필요한 경우가 해당된다. 아래를 보면 UserRepository가 다른 Repository에 종속되어 있는 모습을 볼 수 있다.
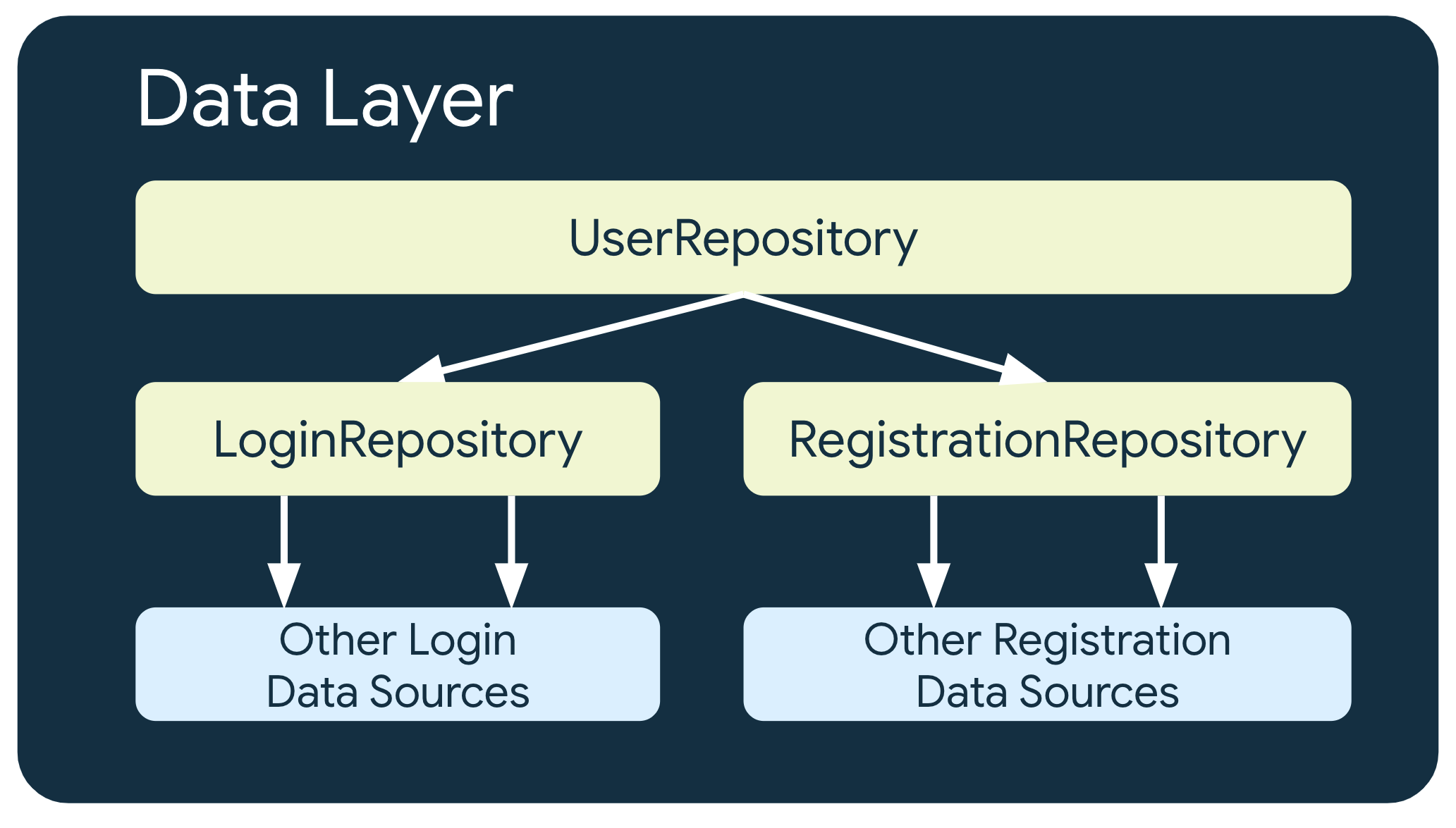
- 캡슐화란? 클래스 안에 서로 연관있는 속성과 기능들을 하나의 캡슐(capsule)로 만들어 데이터를 외부로부터 보호하는 것을 말한다. (출처: 코드스테이츠)
LifeCycle
Data Layer의 인스턴스는 memory에 앱의 다른 객체에서 참조될 때까지 존재한다. 각 인스턴스의 라이프사이클은 앱 내에서 의존성을 제공하는 방법을 결정하는 중요한 요소이다. 이는 의존성 주입 모범 사례를 따르는 것이 권장되는데, Hilt관련 게시글을 통해 공부할 수 있다.
사용 예시
노출시키고자 하는 data model은 다음과 같이 표현된다.
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)모든 정보를 그대로 사용하는 것은 옳은 일인가? 그렇지 않다.
사용하고자 하는 데이터를 레포지토리에서 다음과 같이 표현해준다.
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)💡 앱에서 요구되는 데이터와 일치하지 않는 부분이 생긴다면, 언제든지 새로운 모델을 생성하는 것이 권장된다.모델 클래스를 분리하면서 얻는 효과
- 앱 메모리를 감소시키고 필요한 데이터만을 유지한다.
- 외부 데이터 유형을 앱에서 사용하는 적응형 데이터 유형으로 사용할 수 있다.
- 관심사의 분리를 통해 팀의 구성원은 개별적으로 작업할 수 있다. 네트워크 쪽과 UI 쪽이 동시에 작업을 하는 경우를 말한다.
데이터 작동의 유형
- UI-oriented operations
- 사용자가 특정 화면에 있을 때만 관련이 있고, 해당 화면에서 이동하면 사라진다. 예시로는 서버에서 얻은 데이터 출력이 해당된다.
- App-oriented operations
- 앱이 열려 있을 때만 관련이 있다. 앱이 종료되면 사라진다. 예시로는 화면이 지나가도 데이터가 남아 있는 캐싱이 해당된다.
- Business-oriented operations
- 프로세스 종료 이후에도 존재한다. 예시로는 프로필 사진 업로드가 해당된다.
예외처리
suspend fun에서는 try/catch,flow에서는 catch를 사용한다. 이를 통해 다양한 오류를 처리할 수 있다.
💡 위와 같은 Data Layer의 사용은 어디까지나 구글 권장 아키텍처의 권장사항이며, 상황에 맞게 아키텍처를 적용하는 것은 개발자의 역량이다.Data Layer 적용 Tasks 4가지 ( 참고링크 )
- 글이 너무 길어질 것 같아서 참고자료를 첨부한다.
ps. 이 글은 구글 공식문서를 참고하였습니다.
