Apollo Cache / Cache warming / Cache bursting
웹사이트의 속도가 빨라질수록, 사용자가 웹사이트에 오래 머무른다는 조사 결과가 있고, 이는 곧 웹사이트의 매출로 이어진다.
웹사이트의 로딩 속도를 빠르게 하기 위해 cache를 사용하게 된다.
cache warming
처음 방문하는 사용자는 필연적으로 cache miss가 될 수밖에 없다. 이를 방지하기 위해 웹사이트가 인위적으로 방문자가 오기전에 cache를 생성하여 cache hit이 되도록 하는 것이다.
하지만 큰 회사의 경우 여러대의 캐시 서버와 CDN을 사용하게되는데, 이를 모두 warming하기 위해서는 crawler를 사용하여 같은 페이지를 여러번 방문하도록해야된다(모든 캐시서버에 저장될때까지).
https://www.section.io/blog/what-is-cache-warming/
cache bursting
웹사이트를 방문하게되면 유저의 브라우저에 여러 file들이 캐싱되게 되는데, 이중 static file들은 꽤나 긴 시간동안 캐싱된다. 따라서 이 파일들에 변경점들이 있어도 바로바로 적용되지 않는 경우가 있다.
cache bursting은 유저들이 최신파일을 hard refresh나 browser cache를 임의로 clear하지 않아도 되기 때문에 유용하다. 아래의 방법을 사용하여 cache bursting을 할 수 있다.
- file name versioning (e.g.
style.v2.css) - file path versioning (e.g.
/v2/style.css) - query strings (e.g.
style.css?ver=2)
이 중에서 query string을 사용하는 방법은 이를 인식하지 못하는 CDN이 있어 피하는 것이 좋다.
https://www.keycdn.com/support/what-is-cache-busting
Apollo cache policy
cache-first
cache에 있는 값을 가져오고, 없을 경우 network에 요청한다. cache에 값이 존재할경우, server에서 값이 변하더라도 알지 못한다.
cache-and-network
cache-first와 비슷하게 동작하지만 cache에서 값을 찾았다더라도 network에 요청을 한다. 만약 값이 바뀌었다면 update하고 어느정도의 정보를 넘겨준다
network-only
항상 network에 요청하여 가장 최신의 정보를 받아옴. 하지만 다른 곳에서 request를 보낼 때 같은 데이터를 요청할 수 있기때문에 caching을 하긴한다.
Apollo의 자동 캐시 업데이트가 문제가 될 수 있는 경우
useMutation(
CREATE_TASK,
{
refetchQueries: [getOperationName(FETCH_TASKS)]
}
)위와 같은 방식으로 CREATE_TASK를 수행할 때 refetch되도록할 경우,
1. FETCH_TASK를 호출한 component가 아직 mount되어있어야하며
2. getOperationName(FETCH_TASK)에서 같은 이름을 반환받는 모든 component들이 동시에 refetch(서버에서)하기 때문에 성능이슈가 있다.
useMutation(CREATE_TASK, {
update: (cache, mutationResult) => {
const newTask = mutationResult.data.createTask;
const data = cache.readQuery({
query: FETCH_TASKS, variables: { name: newTask.name }
});
cache.writeQuery({
query: FETCH_TASKS,
variables: { name: newTask.name },
data: { tasks: [...data.tasks, newTask]
})
}
})따라서 위와 같은 방식으로 update 메소드를 통해 직접 cache를 업데이트하면 불필요한 네트워크통신을 줄일 수 있다.
https://medium.com/rbi-tech/tips-and-tricks-for-working-with-apollo-cache-3b5a757f10a0
https://www.apollographql.com/blog/apollo-client/caching/when-to-use-refetch-queries/
Apollo cache normalization 파헤치기
Normalization이란 data redundancy를 줄이기 위해 data를 organize하는 방법입니다. Relational database는 매우 좋은 예시입니다.
Relational database와 Apollo client는 facade pattern을 사용한다는 점에서 비슷합니다. Facade pattern이란 사용자들이 복잡한 low-level을 사용하지 않도록 추가적으로 top-level layer(facade)를 만들어 사용할 수 있도록 하는 것입니다. 즉, facade는 API입니다.
[네이버 영어사전] Facade
1. 명사 (건물의) 정면[앞면]
2. 명사 (실제와는 다른) 표면, 허울 // 이 뜻으로 보시면 될 것 같습니다.
Relational database에서는 DDL을 사용하여 database의 형태를 정의하고, SQL을 사용하여 데이터를 받아오고 조작합니다.
Apollo client에서는 cache policy을 사용하여 client-side cache의 형태를 디자인하고 설정할 수 있으며, useQuery나 useMutation등을 사용하여 데이터를 받아오고 조작합니다.
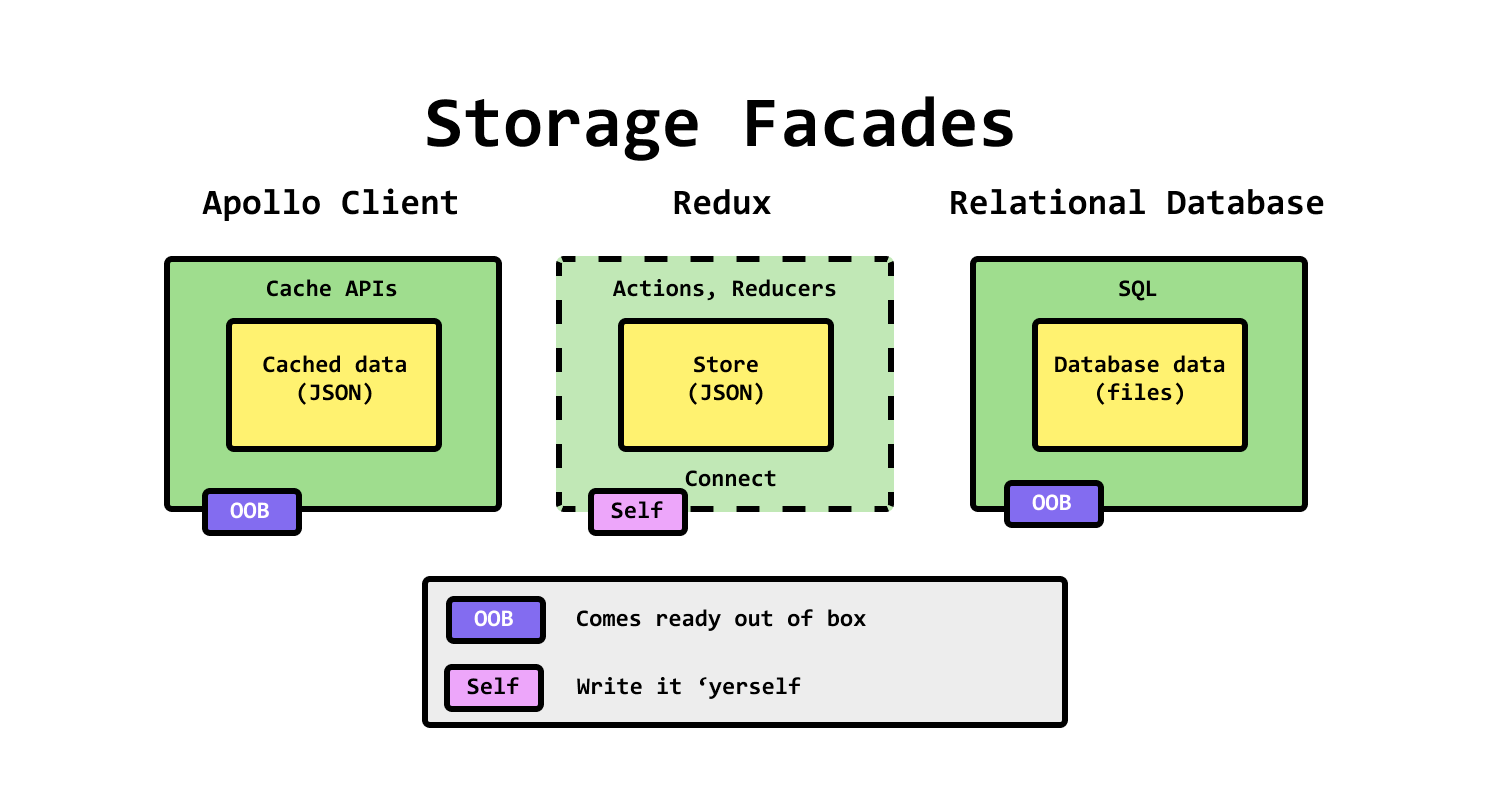
여기서 facade나 API의 중요한 점은, 사용자가 직접 데이터를 조작하는 것이 아니기 때문에 tool이 data normalization과 같은 작업을 수행할 수 있다는 점입니다.
Data normalization Algorithm
Algorithm은 아래의 3단계로 이루어져있습니다
1. result를 개별적인 object로 분리합니다
2. 각각의 object에 logically unique id을 부여합니다. 이는 cache가 각 entity를 안정적으로 tracking하기 위함입니다.
3. object를 flattened data structure에 저장합니다.
좀 더 자세히 살펴보겠습니다.
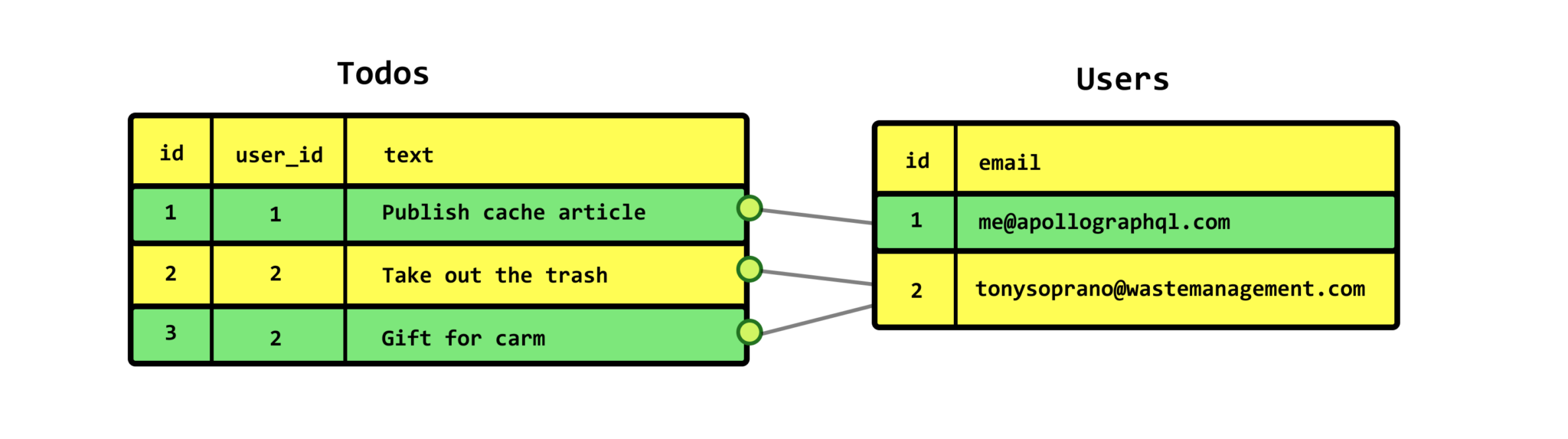
1. result(response)를 분리
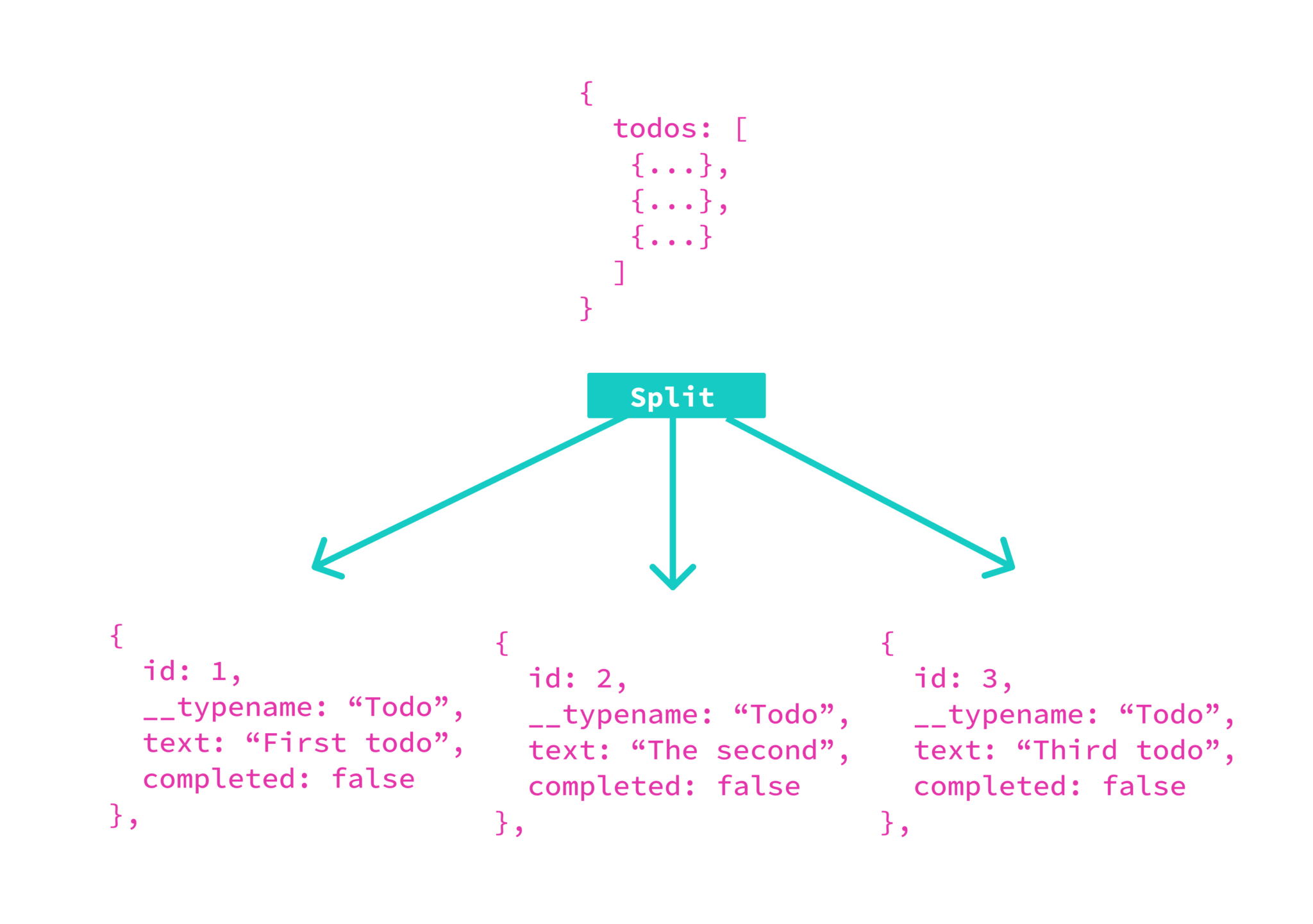
2. logically unique id를 부여

위의 색칠된 박스안의 내용이 각 object의 unique id입니다. id + __typename으로 구성되어있는 것을 보실 수 있습니다.
하지만 경우에 따라 unique id의 field의 이름이 id가 아닐 수도 있습니다.
만약 unique id field의 이름이 todoId일 경우 다음과 같이 apollo에게 알려줄 수 있습니다.
const cache = new InMemoryCache({
typePolicies: {
Todo: {
// let's use "todoId"
keyFields: ["todoId"],
}
},
});또 경우에 따라 unique id가 존재하지 않는 경우도 있습니다. 이 경우 unique할 가능성이 높은 field를 사용하거나 여러 field를 조합하여 사용할 수 있습니다.
아래는 date, user.email을 마치 relational database의 composite key처럼 사용하는 것입니다.
// response
{
__typename: "Todo",
text: "First todo",
completed: false,
date: "2020-07-08T15:05:32.248Z",
user: {
email: "me@apollographql.com",
}
}// cache config
const cache = new InMemoryCache({
typePolicies: {
Todo: {
// If one of the keyFields is an object with fields of its own, you can
// include those nested keyFields by using a nested array of strings:
keyFields: ["date", "user", ["email"]],
}
},
});위의 세팅으로 생성된 identifier입니다.
Todo:{"date":"2020-07-08T15:05:32.248Z","user":{"email":"me@apollographql.com"}}각 object를 unique하게 정의하는 것은 Apollo client가 여러 query에서 반환되는 object들 중에서 같은 object를 판별하고 필요에 따라 머지하는 등 내부 작업에서 사용되기 때문에 매우 중요합니다.
3. flattened data structure에 저장
각 object에 unique id가 부여되면 이 object들은 Apollo client cache의 raw, normalized JS object에 저장됩니다.

그렇기 때문에 hash-table처럼 사용되어 매우 빠르게 검색 & 접근할 수 있습니다.
하지만 대부분의 경우 배열을 response로 받게 되고, 이 때, 배열 안의 순서는 매우 중요합니다. 이 순서를 유지하기 위해 아래와 같이 저장됩니다.

위의 방식처럼 복사되어 중복된 값을 배열에 가지는 것이 아니라 reference를 가지고 있기 때문에 cache의 사이즈를 최소한으로 유지할 수 있습니다. 또, 일반적인 JS object형태이기 때문에 쉽게 JSON-serializable하여 cache.extract()와 cache.restore(snapshot)을 통해 백업/복구할 수 있습니다.
Operations that cache can automatically update
- Queries
- 하나의 entity만 변경하는 Mutation
- Bulk update하여 변경된 모든 변경된 item을 반환하는 mutation
- 이전에 cache한 모든 field를 포함하여야합니다.
Operations that cache cannot automatically update
- Application-specific side-effects
- Bulk update하였지만 일부의 item만 반환하는 경우
- Addition & Deletion
- cache는 새로운 데이터를 cache에서도 추가해야될지, 삭제된 데이터를 cache에서도 삭제해야될지 알지못합니다.
update를 사용하여 처리합니다.
https://www.apollographql.com/blog/apollo-client/caching/demystifying-cache-normalization/
