AWS Lambda란?
잘 알고 있지만, AWS Lambda는 Amazon Web Services에서 만든 이벤트 중심의 서버리스 컴퓨팅 플랫폼을 이야기 합니다.
지원되는 언어로 Node.js , Python , Java , Go , [2] Ruby , [3] 및 C# ( .NET 사용) 등 여러가지 언어가 있지만, 대부분 콘솔에서 작업을 하거나 CDK를 활용해서 배포를 하는데,
모델을 배포하는데 여러가지 라이브러리와 환경 설정이 어려워 Docker로 배포해서 관리하는 방법을 공유하고자 합니다.
생각하고 있는 아키텍처는 CodeCommit을 활용해서 아래와 같이 구축을 생각하고 있습니다.
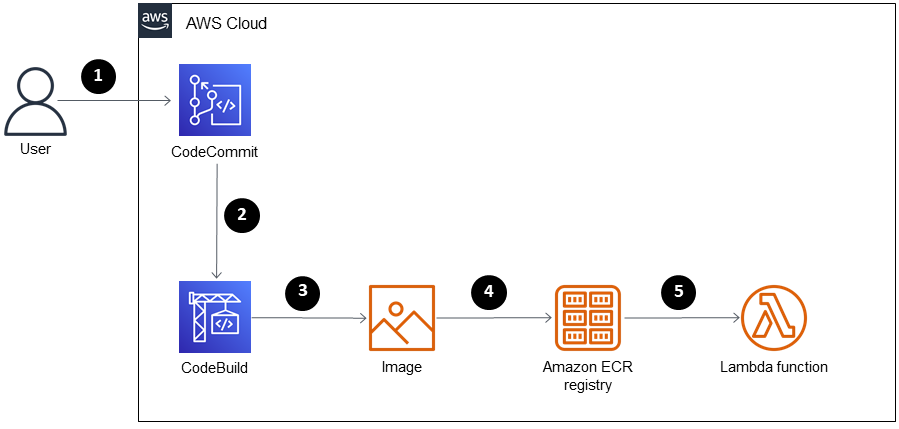
간단하게 코드는 간단한 모델 생성 -> 도커라이징 -> ECR 배포로 생각하시면 나머지는 자동 세팅이니 보시면 되겠습니다.
모델생성
첫번째로는 모델을 생성하는 과정을 진행하겠습니다.
!pip install mxnet==1.9
import pandas as pd
from autogluon.tabular import TabularDataset, TabularPredictor
train_data = train_data.iloc[0:10].reindex()
predictor = TabularPredictor(label="target").fit(train_data)
############ 여기까지 생성
model = TabularPredictor.load('AutogluonModels/ag-20230206_060502/')
model.persist_models(models='all')
# Lambda handler code
def lambda_handler(event, context):
df = pd.read_json(event['body']).reindex()
pred_probs = model.predict_proba(df)
return {
'statusCode': 200,
'body': pred_probs.to_json()
}
test_data = TabularDataset("https://autogluon.s3.amazonaws.com/datasets/timeseries/m4_hourly_subset/train.csv")
job_name = "AutogluonModels/ag-20230206_060502/"
model = TabularPredictor.load(job_name)
model_score = model.leaderboard(test_data, silent=True)
model_score
del test_data["target"]
test_data = test_data.iloc[0:10].reindex().to_json()
# 결과값 획득
import json
lambda_handler({"body": test_data}, None)
모델 빌드 및 ECR 배포
이렇게 모델이 생성이 완료 됩니다.
그러면 이후 작업은 모델을 배포할 환경을 만들어 주면 되는데,
import json
import pandas as pd
from autogluon.tabular import TabularPredictor
model = TabularPredictor.load('/opt/ml/',require_version_match=False)
model.persist_models(models='all')
def lambda_handler(event, context):
df = pd.read_json(json.dumps(event))
df["timestamp"] = pd.to_datetime(df["timestamp"])
pred_probs = model.predict_proba(df)
return {
'statusCode': 200,
'body': pred_probs.to_json()
}
이런식으로의 기본 코드를 만들어 주고, load를 할 환경은 /opt/ml/로 적용합니다. (이부분은 도커 파일에 설정 부분이라 그렇습니다.)
그후 도커는 아래와 같은 형식으로 설정해줍니다.(autogluon 버전은 sagemaker와 동일하게 하기위해 0.5.2 버전으로 진행합니다.)
FROM public.ecr.aws/lambda/python:3.8
RUN yum install libgomp git -y \
&& yum clean all -y && rm -rf /var/cache/yum
ARG TORCH_VER=1.9.1+cpu
ARG TORCH_VISION_VER=0.10.1+cpu
ARG NUMPY_VER=1.19.5
RUN python3.8 -m pip --no-cache-dir install --upgrade --trusted-host pypi.org --trusted-host files.pythonhosted.org pip \
&& python3.8 -m pip --no-cache-dir install --upgrade wheel setuptools \
&& python3.8 -m pip uninstall -y dataclasses \
&& python3.8 -m pip --no-cache-dir install --upgrade torch=="${TORCH_VER}" torchvision=="${TORCH_VISION_VER}" -f https://download.pytorch.org/whl/torch_stable.html \
&& python3.8 -m pip --no-cache-dir install --upgrade numpy==${NUMPY_VER} \
&& python3.8 -m pip install setuptools==59.5.0 \
&& python3.8 -m pip install autogluon==0.6.2 \
&& python3.8 -m pip --no-cache-dir install --upgrade autogluon.tabular==0.6.2
COPY app.py ./
COPY v113_MOR /opt/ml/
COPY v113_MOR/models /opt/ml/models
CMD ["app.lambda_handler"]이렇게 설정하고
aws ecr 명령어
docker build -t {} .
docker run --name {} {}
docker exec -it {} /bin/bash
docker tag {}:latest {}.dkr.ecr.ap-northeast-2.amazonaws.com/{}:latest
docker push {}.dkr.ecr.ap-northeast-2.amazonaws.com/{}:latestECR에 도커 로그인와 빌드 및 배포를 진행해줍니다.
이후는 람다에 콘솔로 배포를 진행을 해도 되지만, 위에 구조를 위해서 따로 boto3를 활용하여 만들어 보도록 하겠습니다.
감사합니다.
참고 사이트
https://en.wikipedia.org/wiki/AWS_Lambda
https://github.com/daekeun-ml/autogluon-on-aws
https://auto.gluon.ai/dev/tutorials/cloud_fit_deploy/cloud-aws-lambda-deployment.html
https://docs.aws.amazon.com/ko_kr/prescriptive-guidance/latest/patterns/deploy-lambda-functions-with-container-images.html
https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtime-environment.html
