1. 0과 1로 숫자를 표현하는 방법
컴퓨터는 0과 1만 인식한다고 했는데 3,4 같은 숫자는 어떻게 인식할까?
컴퓨터가 표현하는 정보 단위에 대해서 알아보고 0과 1만으로 숫자를 표현하는 방법을 알아보자.
1.1 정보 단위
0과 1을 나타내는 가장 작은 정보 단위를 비트라고 한다. 비트는 전구에 빗대어 생각하면 쉽게 이해할 수 있다. 전구 한 개는 꺼짐 혹은 켜짐 두 가지 상태를 표현할 수 있듯이 비트도 0 또는 1로 표현된다.
2비트는 네 가지 상태를 표현할 수 있다. 3비트는 여덟 가지 상태를 표현할 수 있다.
n비트는 2의 n제곱가지의 정보를 표현할 수 있다.
웹 브라우저, 워드 등 우리가 실행하는 프로그램은 수 많은 0과 1로 이루어져 있다. 다시 말해, 프로그램은 수십만 비트, 수백만 비트로 이루어져 있다.
하지만 통상적으로 프로그램의 크기는 비트로 표현하기엔 매우 크기 때문에 비트보다 큰 단위를 사용한다.
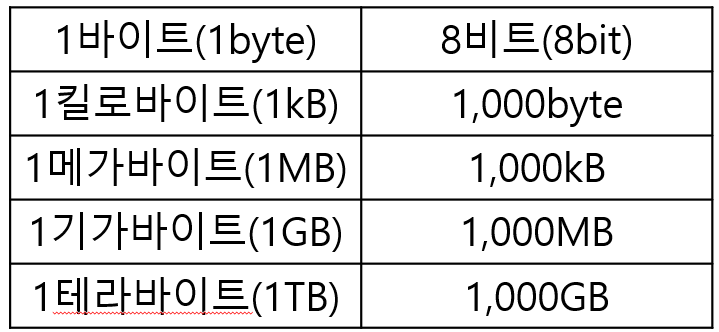
이전에는 1,024개씩 묶어서 표현하기도 했는데 KiB, MiB, GiB, TiB라고 불렸었다
1.2 이진법
수학에서 0과 1만으로 모든 숫자를 표현하는 방법을 이진법이라고 한다.
1이 넘어가는 시점에서 자리 올림을 하면된다.
우리는 보통 숫자를 셀 때 9를 넘어가는 시점에 자리올림을 하는데 이런 방식은 십진법이라고 한다.
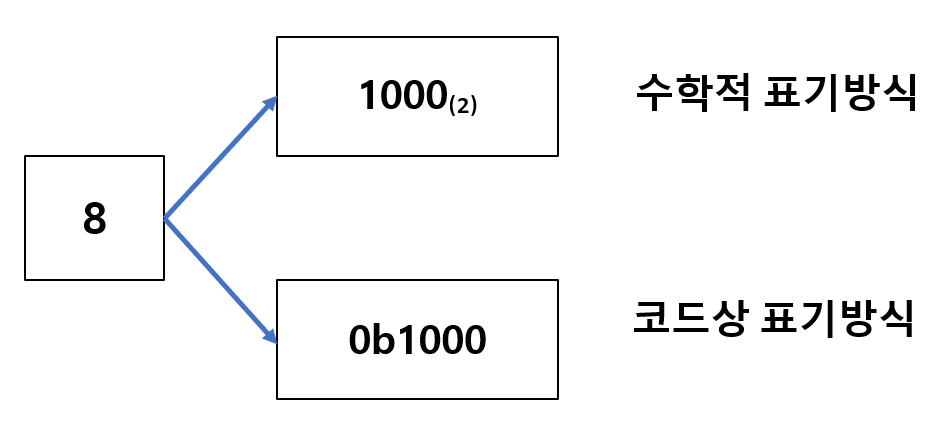
숫자 10만 보고 십진수인지 이진수인지 구분할 수 없기 때문에 혼동을 방지하기 위해 아래 그림과 같은 방식으로 표기를 한다.
1.2.1 이진수의 음수 표현
십진수 음수를 표현할 땐 단순히 숫자 앞에 마이너스 부호를 붙이면 끝이다. -1,-3,-5,...
하지만 컴퓨터는 0과 1만 이해할 수 있기 때문에 마이너스 부호를 사용하지 않고 0과 1만으로 음수를 표현해야 한다.
가장 널리 사용되는 방법은 2의 보수를 구해 이 값을 음수로 간주하는 방법이다.
2의 보수의 사전적 의미는 "어떤 수를 그보다 큰 2의 n제곱에서 뺀 값"을 의미한다.
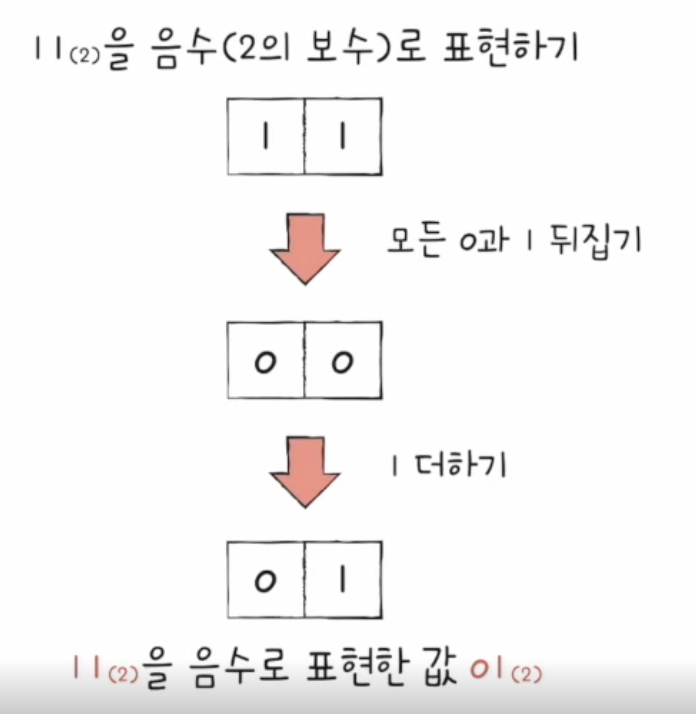
예를 들면 11(2)의 2의 보수는 11(2)보다 큰 2n, 즉 100(2)에서 11(2)을 뺀 01(2)이 되는 것이다.
사전적 의미는 위와 같지만 간단하게 2의 보수를 구할 수 있는 방법이 있다.
"모든 0과 1을 뒤집고, 거기에 1을 더한 값"으로 표현할 수 있다.
이런 질문도 있을 수 있다.
-1011(2)을 표현한 음수로서 0101(2)과 십진수 5를 표현한 양수 0101(2)은 똑같이 생겼는데 어떻게 구분할까?
컴퓨터 내부에서 양수인지 음수인지 구분하기 위해 플래그를 사용한다.
1.3 십육진법
이진법은 0과 1만으로 숫자를 표현하다 보니 숫자의 길이가 너무 길어진다는 단점이 있다. 십진수 32를 이진수로 표현하면 100000(2)같이 여섯개의 자릿수가 필요하다.
그래서 데이터를 표현할 때 이진법 이외에도 십육진법을 사용하기도 한다.
십육진법은 15를 넘어가는 시점에 자리 올림을 하는 숫자 표현 방식이다.

십진법이 아닌 십육진법을 사용하는 이유?
- 이진수를 십육진수로, 십육진수를 이진수로 표현하기 쉽기 때문이다.
1.4 문자 집합과 인코딩
컴퓨터는 0과 1만 이해할 수 있다고 했는데, 워드같은 프로그램에서는 어떻게 문자를 표현할 수 있을까 라는 질문을 해볼 수 있다.
컴퓨터가 인식하고 표현할 수 있는 문자의 모음을 문자 집합이라고 한다.
문자 집합에 속한 문자라고 해서 컴퓨터가 이해할 수 있는게 아니라 문자를 0과 1로 변환해야 이해할 수 있는데 이것은 문자 인코딩이라고 한다.
0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 것을 문자 디코딩이라고 한다.
1.5 아스키코드
아스키(ASCII:American Standard Code for Information Interchange)는 초창기 문자 집합 중 하나로 알파벳, 아라비아 숫자, 특수 문자를 포함한다.
아스키 문자 집합에 속한 문자들은 각각 7비트로 표현되는데 총 27(128)개의 문자를 표현할 수 있다.
실제로는 하나의 아스키 문자를 나타내기 위해 8비트를 사용한다. 하지만 1비트는 패리티 비트라고 불리는 오류 검출을 위한 비트이다.
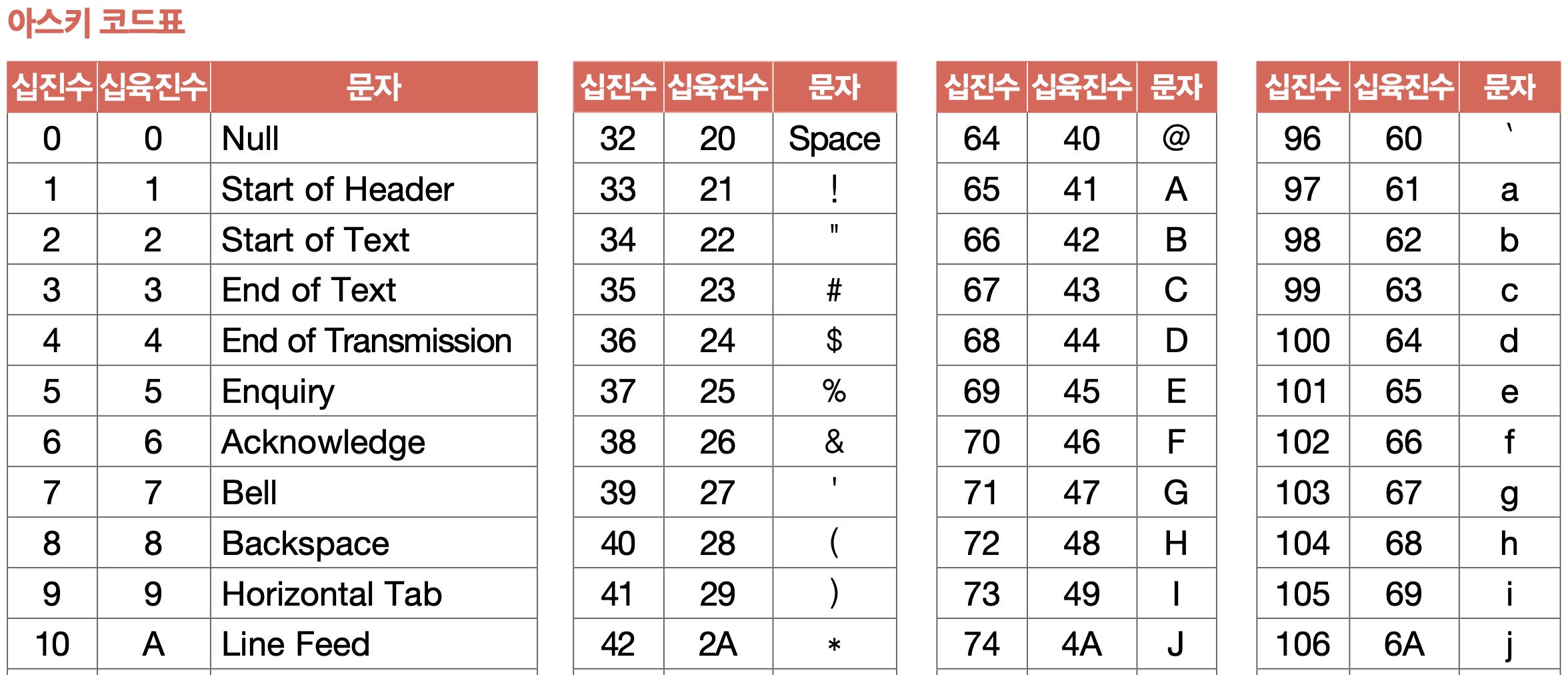
아스키 코드는 인코딩이 매우 간단하다는 장점이 있지만, 한글이나 특수문자 등 여러 언어를 표현할 수 없다는 단점을 가지고 있다.
1.6 EUC-KR
한글 인코딩에는 두 가지 방식이 있다. 완성형 인코딩과 조합형 인코딩이다.
- 완성형 인코딩은 초성,중성,종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여하는 인코딩 방식이다.
- 조합형 인코딩은 초성을 위한 비트열, 중성을 위한 비트열, 종성을 위한 비트열을 할당하고 그것들의 조합으로 하나의 글자 코드를 완성하는 인코딩 방식이다.
한글 한 글자에 2바이트 코드가 부여되니까 EUC-KR로 인코딩된 한글 한 글자를 표현하려면 16비트가 필요하다.
EUC-KR인코딩 방식으로 총 2,350개 정도의 한글 단어를 표현할 수 있다. 이 양은 모든 한글 조합을 표현할 수 있을 정도의 양은 아니기 떄문에 '뷁','믜'같은 글자는 표현할 수 없다.
1.7 유니코드와 UTF-8
EUC-KR을 이용해서 한국어로 인코딩할 수 있겠지만 다른 나라의 언어를 인코딩을 해야한다면 또 다른 인코딩 방식을 써야할 것이다.
그런데 모든 나라의 인코딩 방식이 통일되어 있다면 언어별로 인코딩하지 않아도되기 때문에 매우 편리하다.
그것을 도와주는 것이 유니코드이다.
유니코드 문자 집합에서는 아스키 코드나 EUC-KR과 같이 각 문자마다 고유한 값이 부여된다.
예를 들어 '한'에 부여된 값은 D55C(16), '글'에 부여된 값은 AE00(16)이다.
