
Pod
파드(Pod) 는 쿠버네티스에서 생성하고 관리할 수 있는 배포 가능한 가장 작은 컴퓨팅 단위이다
쿠버네티스 공식 문서에는 다음과 같이 정의 하고있다.
Container
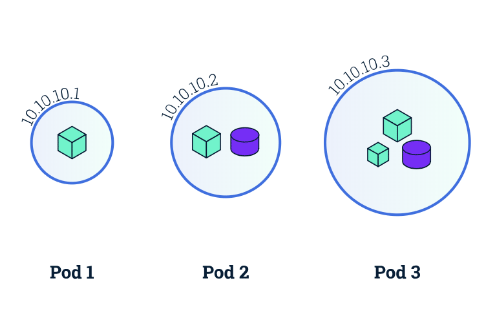
그림 처럼 하나의 파드에는 여러개의 컨테이너가 들어갈 수 있다.
다만 컨테이너에는 포트가 지정될텐데 한 Pod 내에서 컨테이너들끼리 같은 포트를 쓸수는 없다.
또한 Pod 가 생성될때 IP 를 할당해주는데, K8S 클러스터에서는 ip 주소로 Pod에 접근할수 있지만 외부에서는 접근을 할수가 없다.
Pod 가 만약에 문제가 생겨서 죽게되면 재생성이 되는데, 이 때 ip 주소는 변경된다. 이런 파드를 만들기 위해선 다음의 yaml 파일을 작성할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: pod-1
spec:
containers:
- name: container1
image: tmkube/p8000
ports:
- containerPort: 8000
- name: container2
image: tmkube/p8080
ports:
- containerPort: 8080두개의 컨테이너를 만들고 container1이라는 이름으로 8000번 포트를 오픈하였고 containter2라는 이름의 컨테이너로 8080번 포트를 오픈 하였다.
Label
각각에 파드마다 label도 달 수 있다.
label을 다라 목적에 따라 Pod를 분류할수 있다. 예를들어 어떤 파드는 frontend 또 다른 파드는 db 또 다른 파드는 backend 이렇게 구분을 지어서 라벨링을 해줄수 있다는 것이다. 또한 lo 라는 라벨링을 써서 dev와 production의 pod 도 구분할 수 있다. 이렇게 구분되는 정보는 Service라는 Object 와 매핑시켜 사용할 수도 있다.
apiVersion: v1
kind: Pod
metadata:
name: pod-2
labels:
type: web
lo: devNode Schedule
Node Schedule 옵션은 Pod를 만들때 마다 Node를 지정해줄수 있다. 여기서 Node는 실질적인 물리 서버라고 생각하면 된다. Node1, Node2가 있다고 가정을 해보면 내가 직접 Node1 혹은 Node2에 Pod를 둘지 아니면 쿠버네티스 클러스터가 직접 노드를 선택하여 Pod를 올릴지 선택하는 옵션이다.
만약 내가 직접 노드에 Pod를 배치하고 싶다면 다음과 같이 yaml 을 작성하면 된다.
apiVersion: v1
kind: Pod
metadata:
name: pod-3
spec:
nodeSelector:
hostname: node1
containers:
- name: container
image: tmkube/init쿠버네티스 스케쥴러가 판단해서 Pod를 배치하는 경우에는 각각 노드의 지정된 Cpu와 memory가 있을텐데, 특정 Pod의 memory와 Cpu를 보고 쿠버네티스 스케쥴러가 판단하여 자동으로 Pod를 배치해준다. 쿠버네티스 스케쥴러가 직접 Pod를 배치하기 위해선 다음과 같이 yaml을 작성한다.
apiVersion: v1
kind: Pod
metadata:
name: pod-4
spec:
containers:
- name: container
image: tmkube/init
resources:
requests:
memory: 2Gi
limits:
memory: 3Gi해당 Pod는 2기가바이트의 메모리 request를 하는 Pod 이기에 쿠버네티스 노드 스케쥴러가 적절하게 원하는 Pod에 배치 해줄것이다.
Service
쿠버네티스에 서비스 타입은 총 3개가 있다. ClusterIP, NodePort, Load Balancer가 있는데, 서비스 타입마다 동작하는 방식이 상이해서 각각의 타입이 어떻게 동작하는지 알아야한다.
ClusterIP
ClusterIP는 서비스의 IP를 통해서 Pod에 접근하는 방식이다. Pod에도 ip가 있다. 하지만 Service의 ip를 통해서 접근하는 이유는 Pod는 죽을수 있는 가능성이 있고, 실제로 Pod가 죽게되면 ip가 변경이 된다. Pod의 ip는 가변적이기 때문에 Service를 통해서 접근을 하게 해줘야한다.
또한 Pod를 여러개를 연결시켜 트래픽을 분산시켜 줄수 있다.
만약 다음과 같은 Pod의 yaml이 있다고 가정해보자.
apiVersion: v1
kind: Pod
metadata:
name: pod-1
labels:
app:pod
spec:
containers:
- name: container
image: tmkube/p8080
ports:
- containerPort: 8080ClusterIP의 서비스에는 다음과 같이 연결시켜줄수 있다.
apiVersion: v1
kind: Service
metadata:
name: svc-1
spec:
selector:
app: pod
ports:
- port: 9000
targetPort: 8080매핑이 되는 방식은 pod에 있는 metadata.labels.app 과 service에 있는 metadata.spec.select.app과 연결이된다.
pod의 포트는 8080이기에 service의 targetPort와 연결이 되며, 서비스의 9000번 포트를 열어놓겠다는 말이된다.
NodePort
기본적으로 ClusterIP와 같은데, NodePort는 쿠버네티스 클러스터에 연결되어있는 모든 노드 즉 물리서버에 똑같은 Port로 할당이 되서 어떤 노드로 접속하던지 NodePort의 서비스로 연결을 시켜준다. 그렇게 되면 서비스는 Pod에 트래픽을 전달을 해줄것이다.
yaml 파일은 다음과 같다.
apiVersion: v1
kind: Service
metadata:
name: svc-2
spec:
selector:
app: pod
ports:
- port: 9000
targetPort: 8080
nodePort: 30000
type: NodePortLoad Balancer
Load Balancer 타입의 서비스는 NodePort의 성격을 그대로 가지고 있다. 다만 다른 부분이 있다면 노드 앞단에 Load Balancer를 생성시켜서 각각의 노드에 트래픽을 분산시켜준다. 하나 주의 해야할점은 Load Balancer의 ip는 쿠버네티스 클러스터가 알아서 할당을 해주지 않는다. 별도로 플러그인을 설치해야 ip를 할당시켜줘야 외부에서 Load Balancer의 ip로 접근을 할 수 있다.
apiVersion: v1
kind: Service
metadata:
name: svc-3
spec:
selector:
app: pod
ports:
- port: 9000
targetPort: 8080
type: LoadBalancerVolume
emptyDir
emptyDir 은 한 파드안에서 컨테이너들끼리 데이터를 공유하기위해 볼륨을 사용한다. 최초 볼륨이 생성될때는 볼륨이 항상 비어있기 때문에 emptyDir이라고 지칭한다. emptyDir은 Pod가 생성되면 같이 만들어지고 삭제될때 같이 없어지기 때문에 영구적으로 저장할 파일이 있으면 emptyDir을 사용하면 안된다.
apiVersion: v1
kind: Pod
metadata:
name: pod-volume-1
spec:
containers:
- name: container1
image: kubetm/init
volumeMounts:
- name: empty-dir
mountPath: /mount1
- name: container2
image: kubetm/init
volumeMounts:
- name: empty-dir
mountPath: /mount2
volumes:
- name : empty-dir
emptyDir: {}이렇게 생성을 하면 emptyDir이 생성되는데, containter1과 container2는 로컬에서 파일을 i/o 하는것 처럼 사용할 수 있다.
자세히 보면 container1은 /mount1로 볼륨을 마운트 했고 container2 는 /mount2로 볼륨을 마운트 했다. 컨테이너 마다 마운팅 되는 경로는 다르지만 결국에는 하나의 볼륨을 사용하고 있는 것이다.
hostPath
hostPath는 하나의 호스트에 볼륨을 마운팅 시키는 것인데, 각각의 Pod들이 올라가져 있는 노드에 볼륨을 마운트 하는것이다. emptyDir과 다른점은 하나의 노드에 볼륨이 마운팅 되어있어서, 데이터가 사라질 걱정은 없다. 다만 한가지 고려해야 할점은 Pod를 생성할 때 Node Schedule을 걸어놓지 않았다면 쿠버네티스 클러스터가 자원 상태를 보고 노드를 지정하여 Pod를 생성할텐데, Node1에 hostPath를 걸어놨지만 Node2에 Pod 가 생성되면 문제가 될 수도있다. 하지만 방법을 찾는다면 노드가 추가 될때마다 똑같은 이름의 경로를 만들어서 직접 노드에 있는 path 끼리 마운팅 시켜주면 된다. 이 부분은 사용자가 직접 마운팅을 해줘야하는 부분이 있다.
apiVersion: v1
kind: Pod
metadata:
name: pod-volume-3
spec:
nodeSelector:
kubernetes.io/hostname: k8s-node1
containers:
- name: container
image: kubetm/init
volumeMounts:
- name: host-path
mountPath: /mount1
volumes:
- name : host-path
hostPath:
path: /node-v
type: DirectoryOrCreatePVC/PV
PVC와 PV는 Pod에 영속성 있는 데이터를 제공하기 위한 개념이다. 로컬볼륨도 있지만 외부에 있는 aws, git 처럼 파일 서버가 있는 경우가 있는데 이때 Persistent Volume을 사용하여 연결을 한다. 여기서 파드는 Persistent Volume Claime 을 통해 Persistent Volume에 연결을 한다. 기본적으로 쿠버네티스는 User 영역과 Admin 영역을 나눴는데 Admin 영역에는 PV 와 Volume(aws, git, NFS 등) 이 있고 User 영역에는 Pod와 PVC가 있다. admin 영역은 쿠버네티스 클러스터를 관리하는 관리자의 영역이고 User는 Pod에 서비스를 만들고 배포하는 서비스 담당자의 영역이다. admin이 PV는 다음과 같이 만들수 있다.
apiVersion: V1
kind: PersistentVolume
metadata:
name: pv-01
spec:
nfs:
server: 192.168.0.xxx
path: /sda/data
gitRepo:
repository: github.com...
revision: master
directory: .이런식으로 nfs gitRepo를 연결을하고 이것을 사용하기 위해서 PVC를 만들어야 한다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-01
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1G
storageClassName: ""읽기쓰기 모드가 되고 용량이 1기가 바이트가 되는 볼륨을 할당을 한다. storageClassName은 ""라고 넣으면 현재 만들어진 PV들 중에서 선택이 된다.
그러면 Pod랑 PVC를 연결 시켜줘야 하는데 yaml 파일에 volumes쪽에 pvc를 마운트 시켜주면된다.
apiVersion: v1
kind: Pod
metadata:
name: pod-volume-3
spec:
containers:
- name: container
image: kubetm/init
volumeMounts:
- name: pvc-pv
mountPath: /mount3
volumes:
- name : pvc-pv
persistentVolumeClaim:
claimName: pvc-01정리하면
1. PV를 생성
2. PVC를 생성
3. PVC에서 PV를 연결
4. Pod 생성시 PVC를 마운팅
이런 순서가 된다.
Namespace
Namespace는 기본적으로 Pod Service 와 같은 오브젝트들을 용도별 혹은 목적별로 다르게 구분짓기 위해 있는 오브젝트이다. 예를들어 결제 네임스페이스 commerce 네임스페이스 이런식으로 용도에 맞게 분리를 시켜준다. 여기서 namespace는 물리적으로 직접 분리를 시켜주는게 아니라 논리적으로 분리를 시켜준다. namespace는 쿠버네티스 오브젝트를 묶는 하나의 가상공간 또는 그룹일뿐이다.
하지만 Object를 생성할때 namespace가 nm1 인 곳에 pod1, service1가 있고 nm2인 곳에 pod2, service2 가 있다고 가정 했을때 pod1은 service2에 연결시켜주지 못한다. 왜냐하면 nm1은 nm2와 분리가 되서 관리가 되기 때문이다.
apiVersion: v1
kind: Namespace
metadata:
name: nm-1또는 간단하게 kubectl 로 만들수 있다.
kubectl create namespace nm-1그렇다면 pod를 nm-1 에서 생성을 하려면 어떻게 할까?
apiVersion: v1
kind: Pod
metadata:
name: pod-1
namespace: nm-1
labels:
app: pod
spec:
containers:
- name: container
image: kubetm/app
ports:
- containerPort: 8080service도 마찬가지로 pod 와 같이 namespace를 지정하여 생성할 수 있다.
apiVersion: v1
kind: Service
metadata:
name: svc-1
namespace: nm-1
spec:
selector:
app: pod
ports:
- port: 9000
targetPort: 8080ResourceQuota
ResorceQuota는 namespace의 자원의 한계를 설정할 수 있는 옵션이다.
예를들어 쿠버네티스 클러스터가 CPU가 100, 메모리가 200G인 상황에서 nm-1 네임스페이스 에서 80의 CPU와 180G 의 메모리를 차지하고 있다고 가정을 해보자. 이 때 nm-2 에서 50의 CPU와 50G를 필요로 하는 Pod가 생성이 되야하는 상황인데 이미 CPU 와 메모리가 꽉찬 상황이라 생성을 하지 못한다.
이런 상황을 예방하기 위해 ResourceQuota를 사용하여 각각 namespace의 자원의 생성을 제한을 시켜줄수 있다. 여기서 하나 알아야 할점은 ResourceQuota가 지정된 namespace에 pod를 만들때 Pod의 spec 을 지정해 줘야한다. (메모리와 CPU를 얼마나 쓸지) 그렇지 않으면 Pod가 생성자체가 되지 않는다.
apiVersion: v1
kind: ResourceQuota
metadata:
name: rq-1
namespace: nm-1
spec:
hard:
requests.memory: 1Gi
limits.memory: 1GiLimitRange
LimitRange는 특정 네임스페이스에서 하나의 Pod가 메모리와 CPU를 너무 많이 차지하고 있게되면 Pod가 생성이 안되는데 이를 제한하기 위해 LimitRange가 있다. 예를들어 ResourceQuota에서 네임스페이스 마다 memory와 cpu가 각각 30기가, 200 씩 차지하도록 설정을 했는데 특정 네임스페이스의 한 Pod가 memory 25기가 Cpu 180을 차지하고 있다고 가정을 해보자. 여기서 새로운 Pod 가 추가가 되어야 하는데 이 Pod는 memory 10기가 Cpu 50 을 차지해야 한다고 생각을 해보면 자원이 부족해 Pod가 생성이 되지 않는다. 이를 예방하기 위해 LimitRange를 사용할 수 있다.
apiVersion: v1
kind: LimitRange
metadata:
name: lr-1
namespace: nm-1
spec:
limits:
- type: Container
min:
memory: 0.1Gi
max:
memory: 0.5Gi
maxLimitRequestRatio:
memory: 1
defaultRequest:
memory: 0.5Gi
default:
memory: 0.5Gi여기서 min과 max는 pod를 생성할때 최소, 최대 자원의 값을 설정해주는 것 이다. 만약에 defaultRequest와 default를 명시 해놓으면 pod를 생성할 때 스펙을 따로 명시하지 않으면 default 값으로 pod가 자동적으로 생성이 된다.
