오늘은 SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation에 대한 간단한 리뷰이다.
Architecture
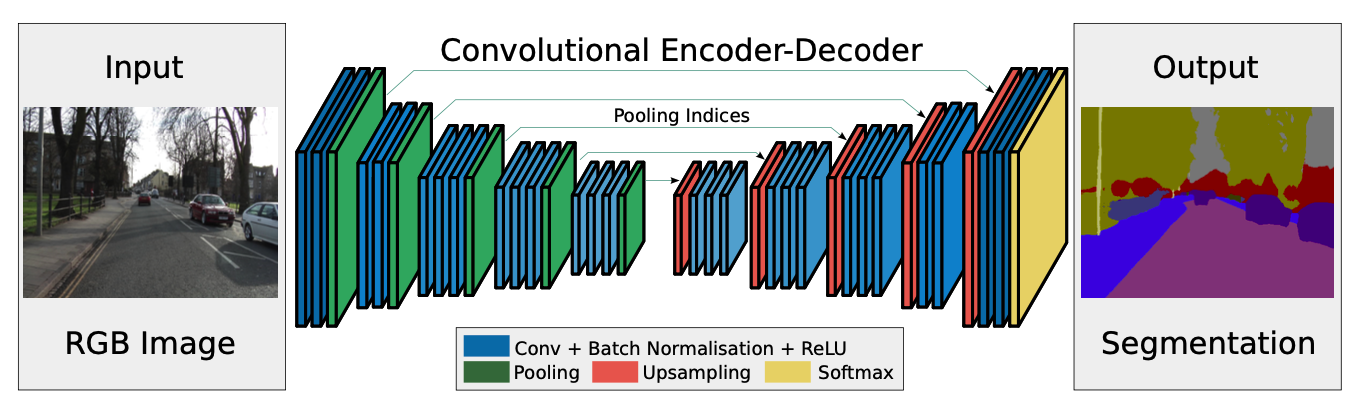
Encoder는 VGG16의 처음 13개 레이어를 사용하였다. 또한 classification으로 학습된 weight에서 시작을 한다. 또한 encoding을 하는 중에 max-pooling의 인덱스를 기억했다가 decoding할 때 사용한다. decoder에서는 upsampling을 통해 이미지 크기를 키워가고, 마지막에 softmax를 취해 segmentation task를 수행한다.
DeconvNet, U-Net과 비슷한 구조를 취하고 있는데, DeconvNet은 파라미터가 많아서 계산량이 많고, U-Net은 VGG의 모든 layer를 encoder로 사용하지 않는다는 점이 다르다.
Decoder Variants
많은 segmentation model이 같은 encoder 구조를 가지고 있기 때문에, decoder의 역할이 중요하다. 따라서 decoder의 성능을 측정하기 위해 SegNet의 축소판인 SegNet-Basic이라는 모델을 만든다. 이후 decoder를 갈아끼운 FCN-Basic도 구성하여 기본적인 모델로 사용한다.
SegNet에서 upsampling을 할 때, 채널을 하나로만 upsample하는 SegNet-Basic-SingleChannelDecoder, FCN의 구조에서 encoder feature map을 더해주는 과정을 제외한 FCN-Basic-NoAddition, fixed bilinear interpolation을 사용하는 Bilinear-Interpolation, decoder의 feature map에 encoder의 feature map을 더해주는 SegNet-Basic-EncoderAddition, FCN에서 dimensionality reduction을 수행하지 않는 FCN-Basic-NoDimReduction 등의 다양한 variation 모델을 사용하여 실험을 진행하였다.
Analysis
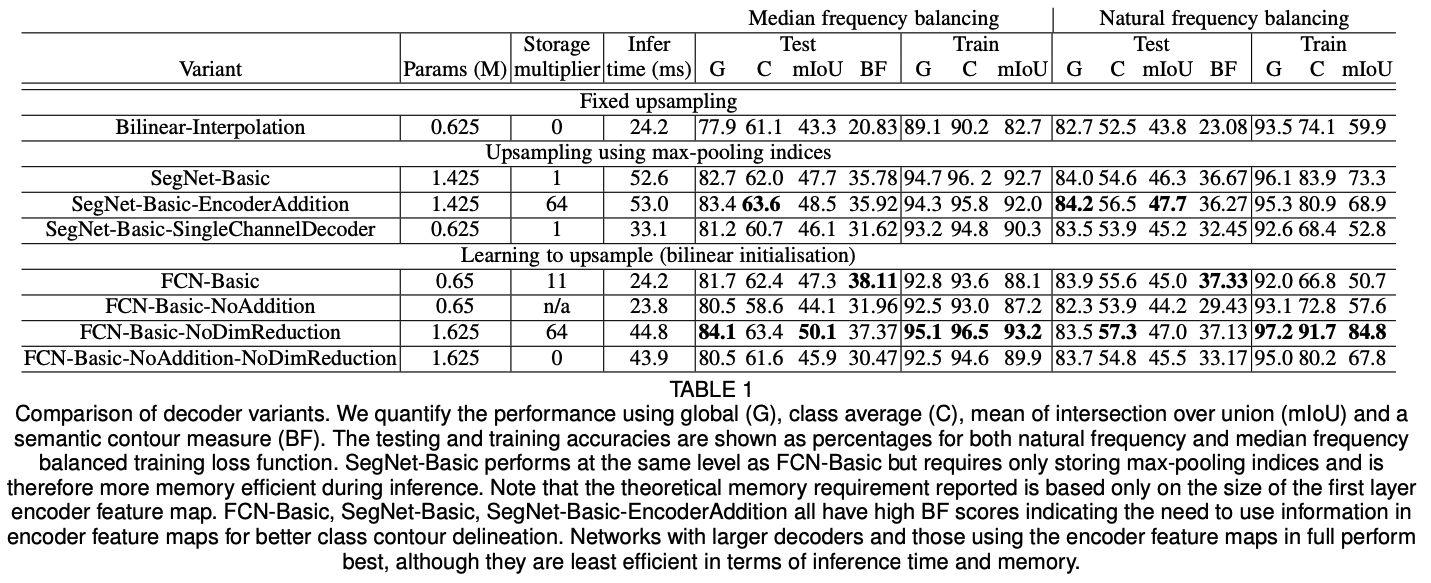
각 모델에 대한 실험 결과는 위와 같다. 각 모델의 성능을 비교하면서 모델 구조의 차이가 성능에 미치는 영향을 확인할 수 있다.
논문에서 요약한 내용은 다음과 같다.
1. encoder feature map을 모두 사용하는 것이 가장 좋은 성능을 달성한다.
2. 메모리가 제한되어있다면, dimensionality reduction이나 max-pooling indices처럼 압축하고 적절한 decoder를 사용하는 것이 성능이 좋다.
3. 더 큰 decoder가 더 좋은 성능을 보여준다.
Benchmarking
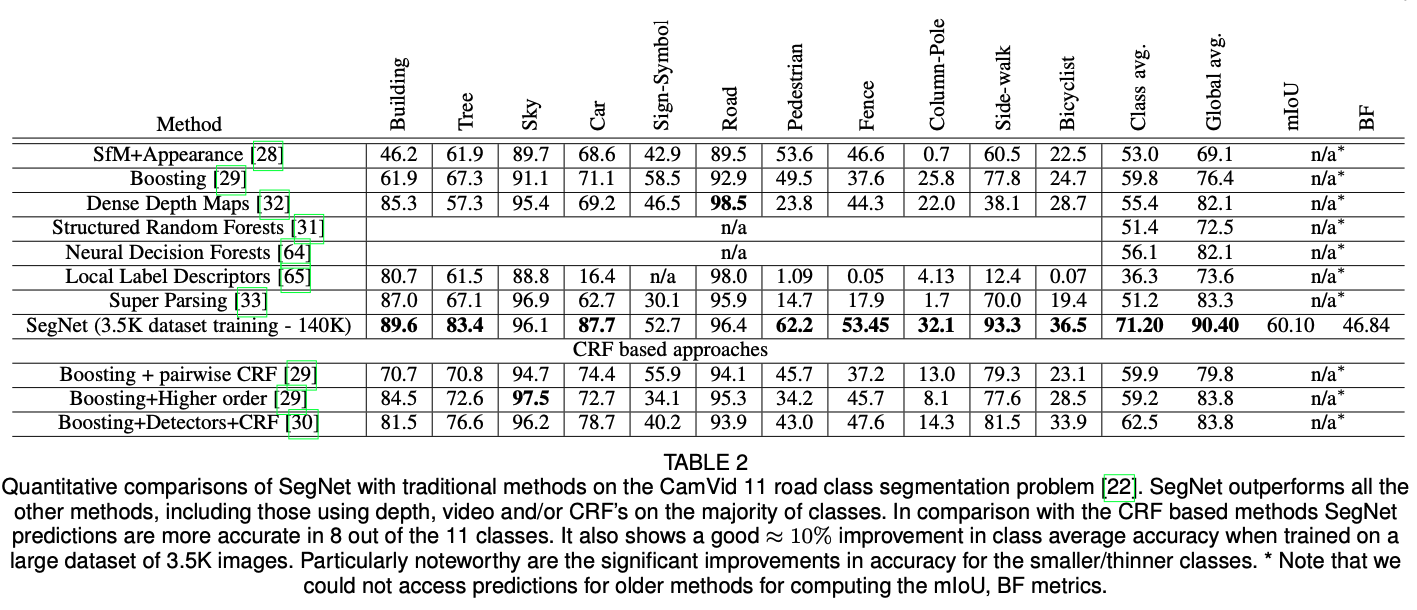
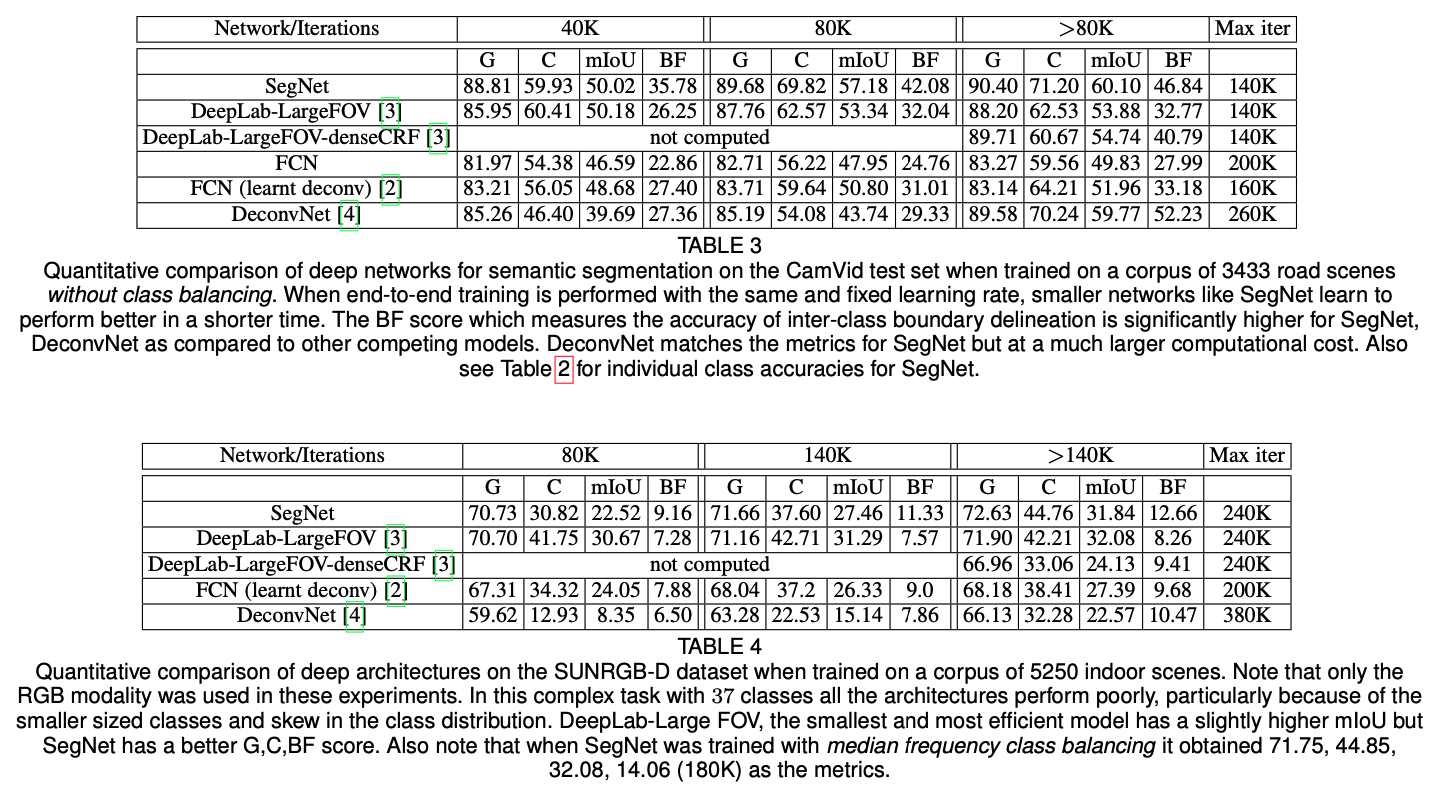
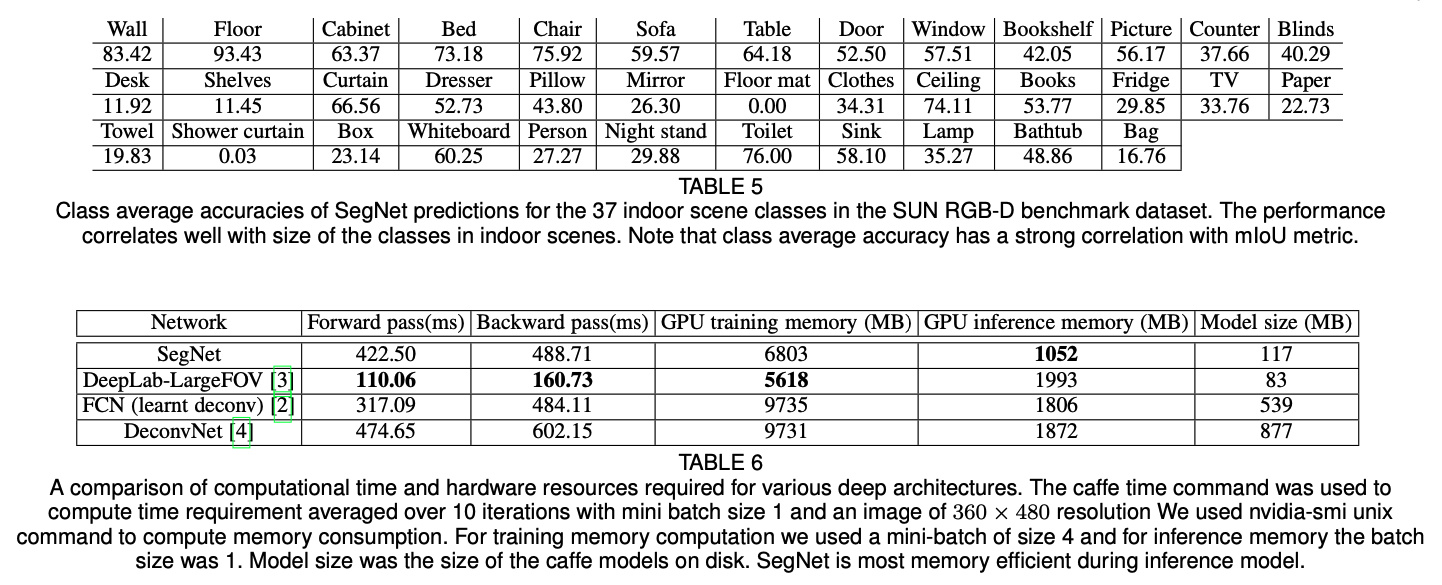
다양한 데이터셋에 대한 성능 비교표이다.
후기
내 입장에서는 상당히 어려운 논문이었다. 여러 모델이 등장하고, 특정 부분을 제거하거나 추가하는 방식으로 실험을 했다보니 그런 것 같다. U-Net과의 성능 비교도 궁금했는데 아무래도 도메인이 다르다보니 없는 것 같다. 실험은 이렇게 해야하는구나를 느낄 수 있었던 논문이었다.
