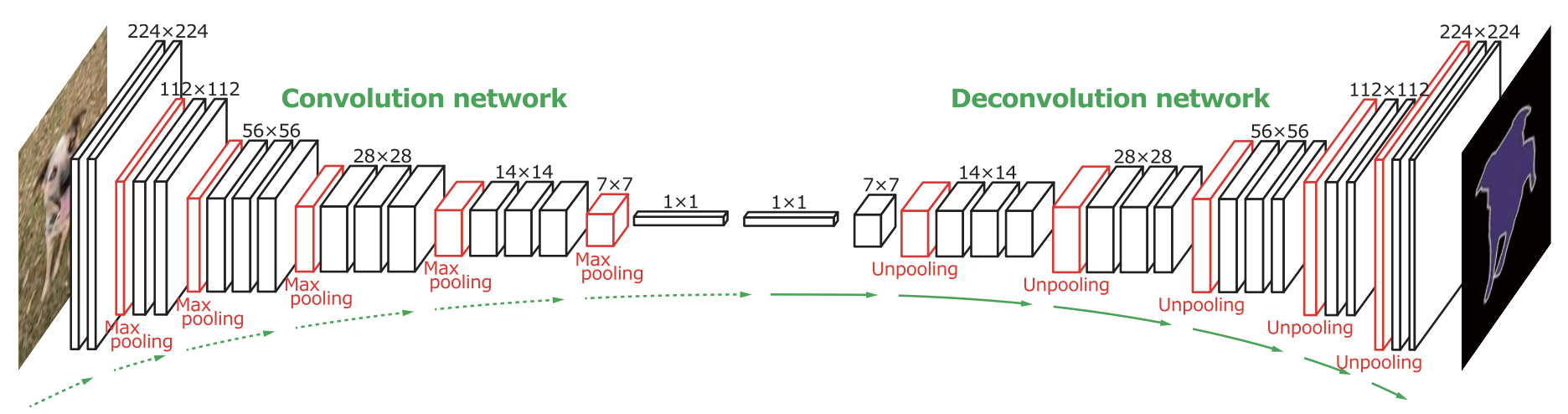
오늘은 Learning Deconvolution Network for Semantic Segmentation에 대한 간단한 리뷰이다.
System Architecture
Architecture
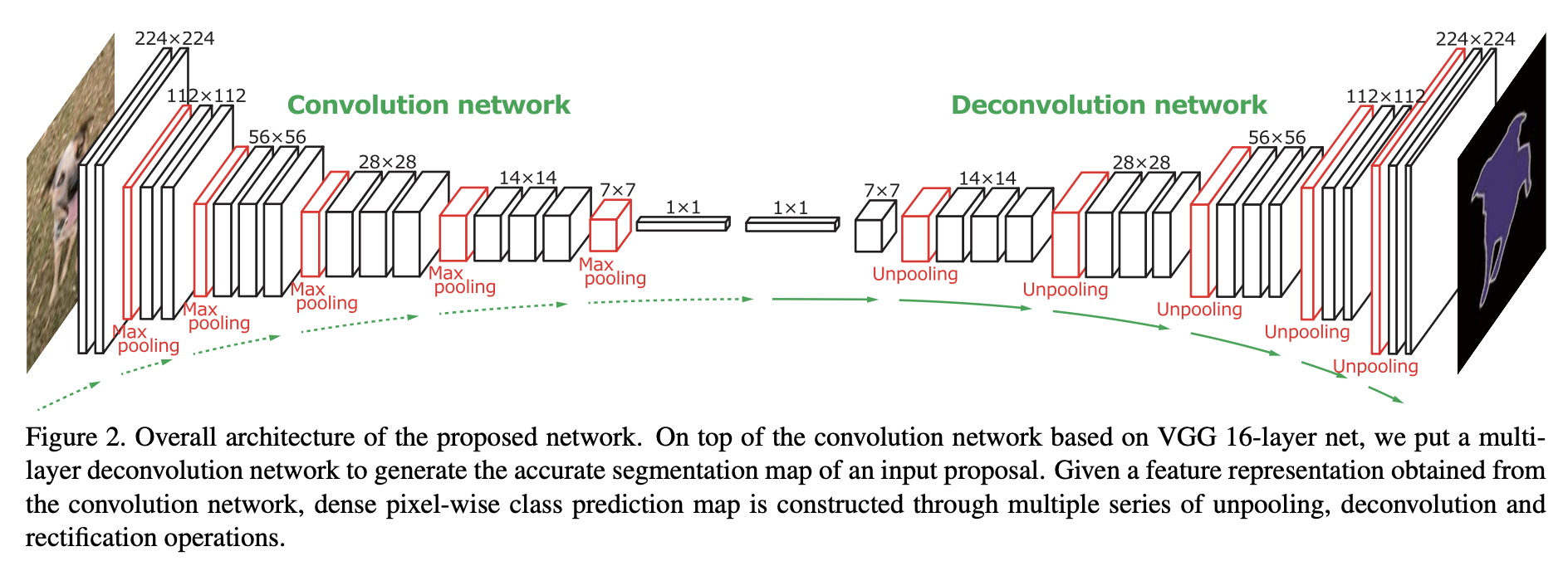
feature extractor 역할을 하는 convolution network와 feature로부터 segmentation을 생성하는 deconvolution network로 이루어져있다.
convolution network는 VGG-16 구조를 사용했다고 한다.
Deconvolution Network for Segmentation
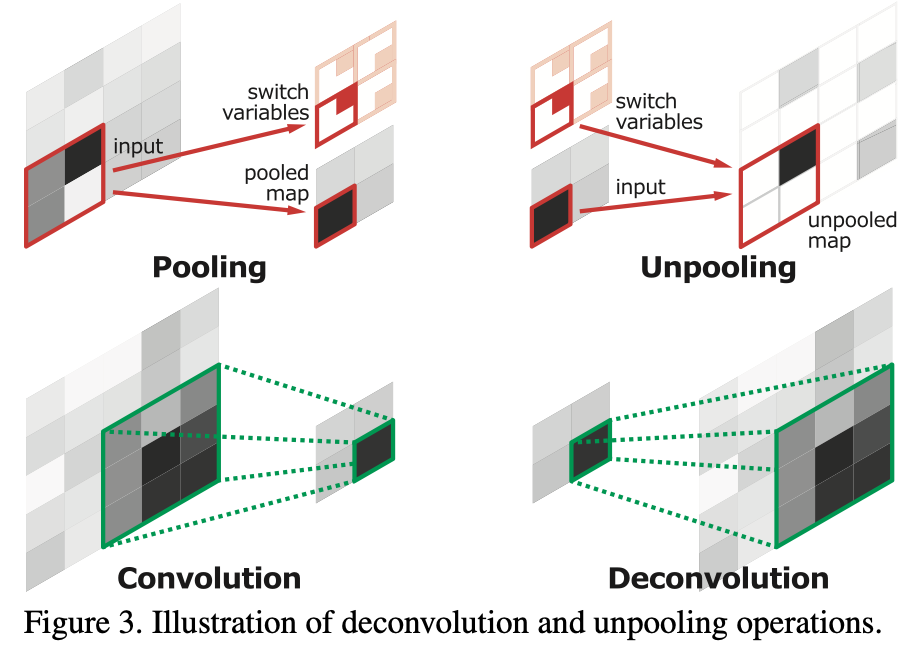
deconvolution network에서는 Unpooling과 deconvolution layer를 사용하였다.
Unpooing의 경우, pooling을 할 때 가져온 값의 위치를 기억해놨다가, unpooling을 할 때 그 위치에 값을 채워넣는 구조이다.
Deconvolution의 경우, unpooling에서 나온 feature map을 좀 더 dense하게 만들어 준다. 또한 learnable하기 때문에 object의 특징을 학습하여 reconstruct하는 역할을 한다.
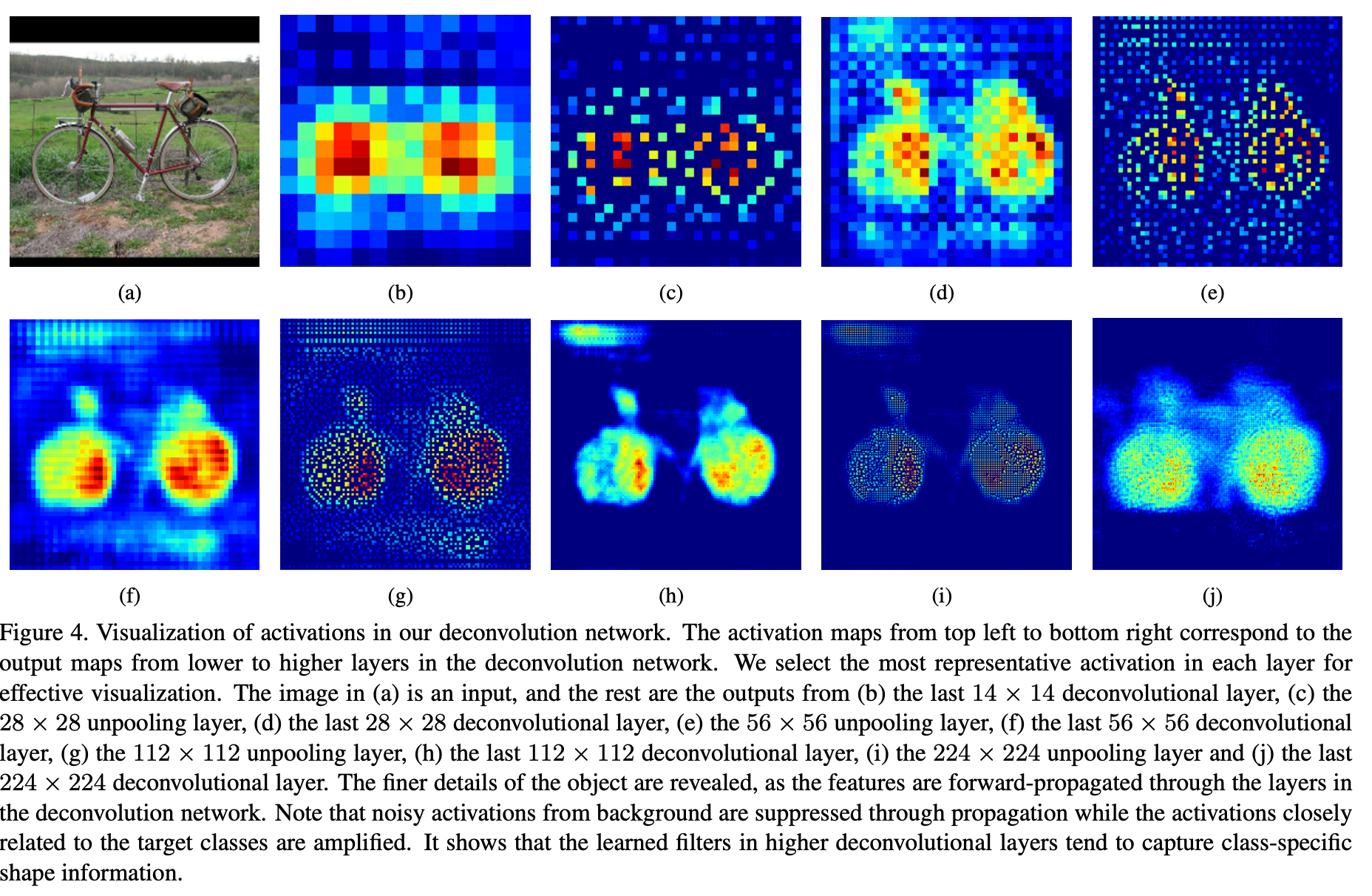
위의 사진은 deconvolution을 시각화한 것인데, lower layer, 즉 인풋에 가까운 layer에서는 좀 더 coarse한 특징을, higher layer에서는 좀 더 복잡한 패턴을 확인할 수 있다.
또한 Unpooling layer에서는 논문에서 표현하기로는 example-specific한 구조, 즉 물체의 세부적인 구조를 reconstruct한다면, Deconvolution layer에서는 class-specific한 구조를 잡으면서 클래스와 관련 있는 부분은 증폭시키고, 노이즈는 압축시켜 제거해버리는 역할을 하고 있다.

FCN과 비교했을 때 확실히 차이가 나는 모습이다.
System Overview
또한 이미지 전체를 받는 것이 아니라, object가 있는 subimage를 받아 추론을 수행하고 합치는 방식으로 실험을 진행하였다. 이렇게 함으로써 다양한 크기의 오브젝트에 대해 대응이 가능하고, 학습의 복잡성과 메모리 requirement를 줄이는 장점을 가져간다.
Training
Batch Normalization
batch norm을 매 레이어마다 추가함으로써 internal-covariate-shift 효과를 줄인다.
Two-stage Training
첫 번째로 object가 중앙에 있는 사진만을 이용하여 학습하고, 이후 candidate proposal이 겹쳐있는 이미지로 학습을 진행하여 robust하게 학습하려고 하였다.
Inference
Inference는 충분한 candidate proposal을 생성하고 그것을 추론한 후, 합치는 방식을 이용했다. 또한 FCN과 모델 앙상블도 진행하였다.
Experiments

성능은 위와 같다. 타 모델과 비교했을 때 괜찮은 성능을 보여주고 있다.
후기
오늘은 DeconvNet이라고 하는, unpooling과 deconvolution으로 이루어져 있는 network를 살펴보았다. unpooling layer와 deconvolution layer의 역할을 알 수 있도록 activation map을 넣어놓은 것이 보는 맛도 있고 굉장히 재밌는 논문이었다. 또한 성능을 높이기 위해 two-stage로 학습을 진행한 것과 각각의 이미지를 추론해서 합친 것이 인상 깊은 부분이었다.
