오늘은 Xception: Deep Learning with Depthwise Separable Convolutions에 대한 간단한 리뷰이다.
The Inception hypothesis
Inception module을 사용하는 이유는 cross-channel correlations와 spatial correlations를 볼 수 있도록 연산을 분해함으로써 기존 conv layer가 하는 일을 쉽고 효율적으로 만들기 위함이다.
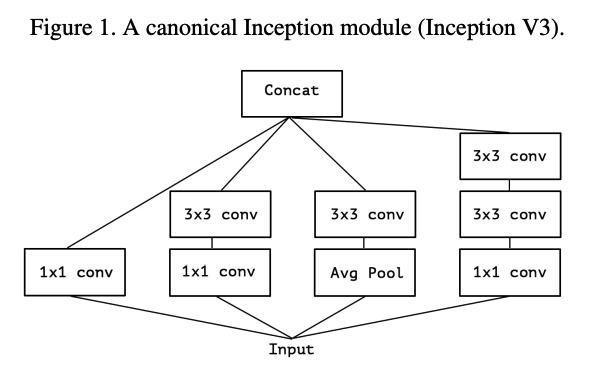
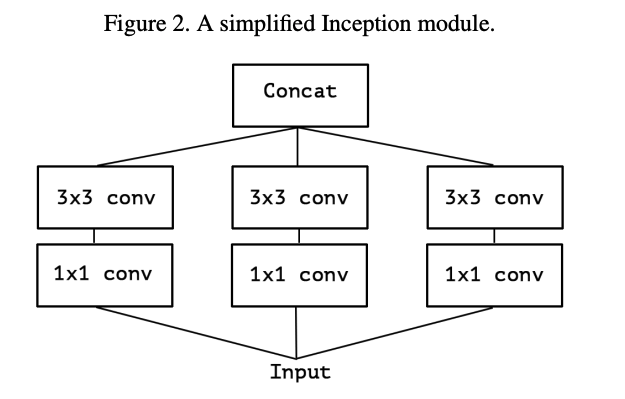
1x1 conv를 통해 cross-channel correlations를 보고, 그것을 3x3 conv를 통해 모든 correlations을 매핑한다.
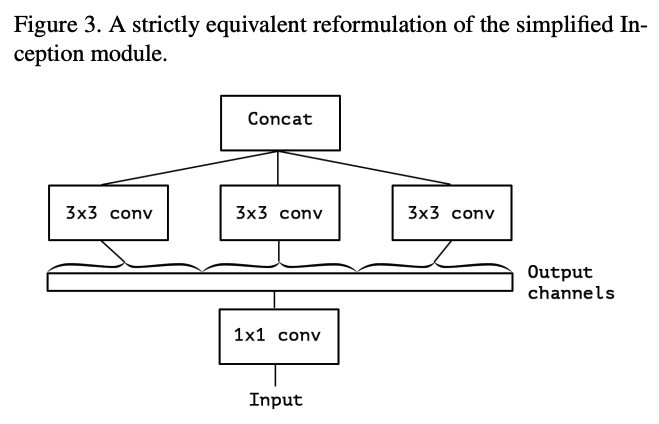
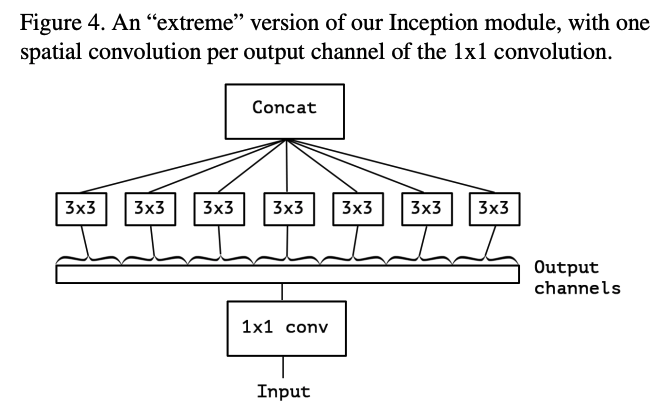
기존의 inception module에서 avg pool을 제외하고, conv를 하나씩만 넣어준다면, 결국 각각의 채널마다 독립적으로 3x3 conv를 하는 것과 동일하다.
The continuum between convolutions and separable convolutions
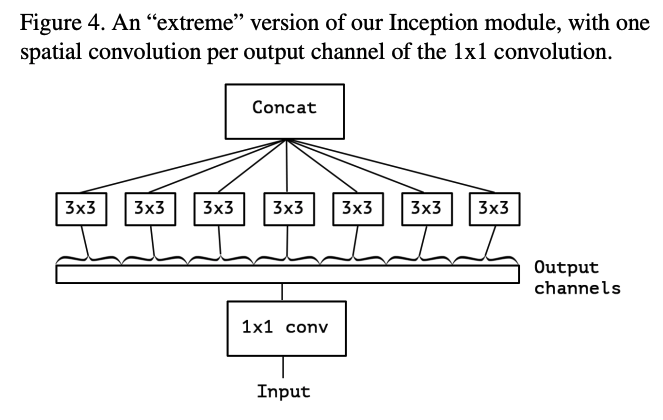
그래서 인풋에 대해 1x1 conv를 적용해 cross-channel correlations를 보고, 각각의 모든 채널에 대해 3x3 conv를 적용하는 extreme version을 구성한다. 그리고 이것은 이전에 사용됐던 depthwise separable convolution과 거의 동일하다.
기존의 Inception module 대신 depthwise separable conv를 쌓으면 더 효율적으로 모델을 구현할 수 있다.
The Xception architecture
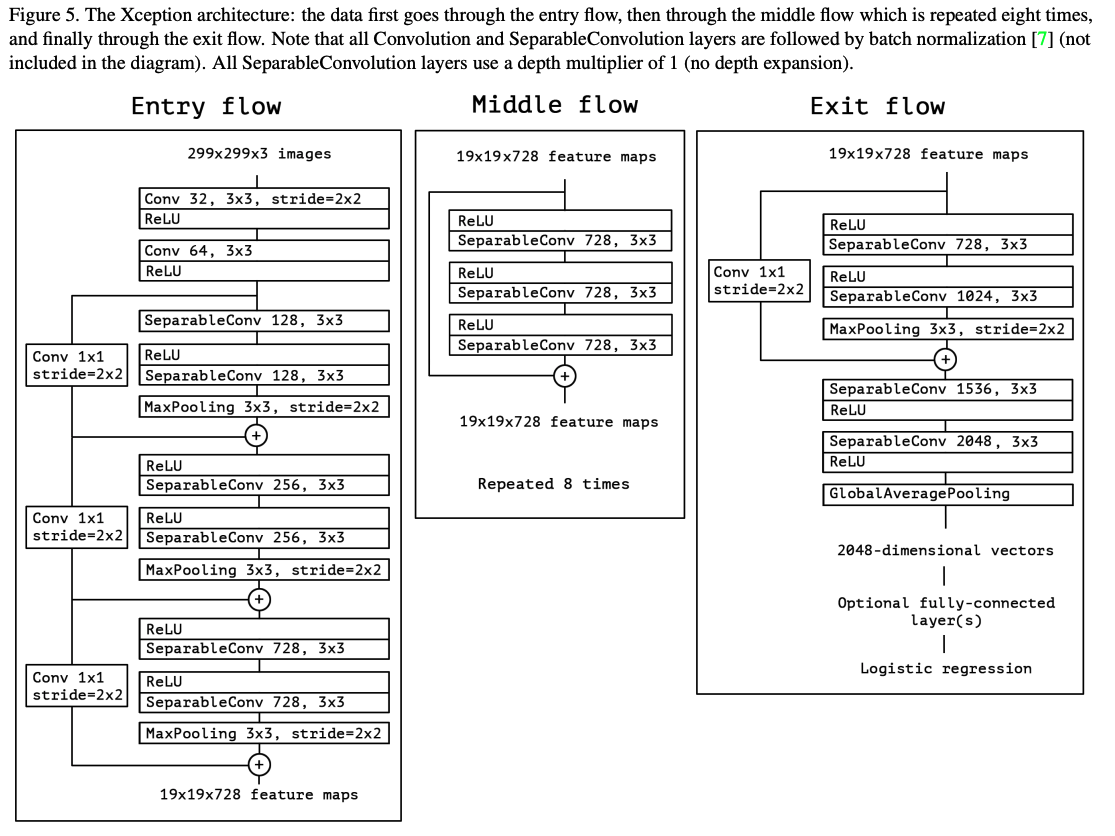
corss-channels correlations와 spatial correlations의 매핑이 각각 완전히 분리될 수 있다는 가정하에 Xception 모델을 만든다.
Experimental evaluation
ImageNet 데이터와 구글 내부 데이터셋인 JFT dataset을 이용해 실험을 진행했다.
Comparison with Inception V3
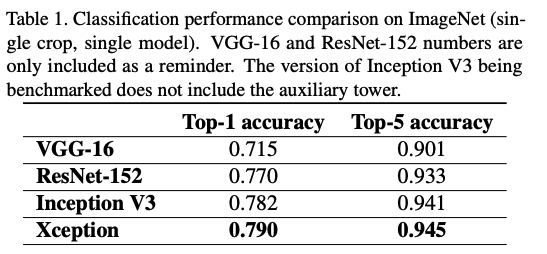
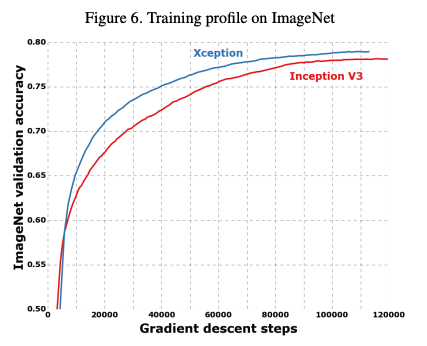

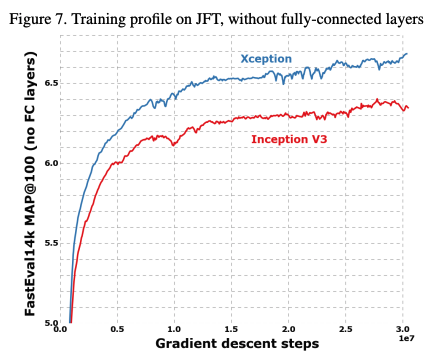
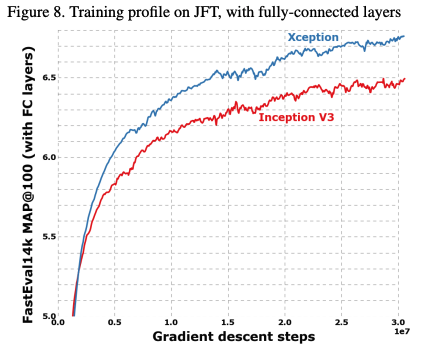
성능은 위와 같이 비슷한 파라미터 수를 가지고 있는 Inception V3와 비교했을 때 좋은 성능을 보여주고 있다.
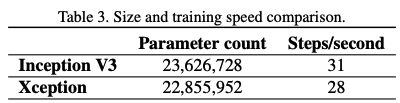
속도 또한 빨라졌다.
Effect of the residual connections
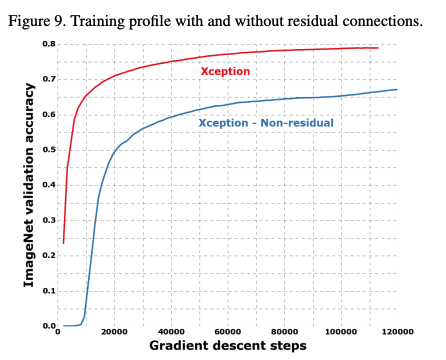
ResNet에서 사용됐던 residual connection을 적용한 것이 더 좋은 성능을 보여준다. 또한 재밌는 것은, VGG-style로 모델을 만들고, 각 레이어를 depthwise separable conv로 쌓았을 때에도 residual connection을 적용한 것이 성능이 높게 나왔다. 즉, 이러한 architecture에는 residual connection이 좋은 성능을 보여준다는 것이다.
Effect of an intermediate activation after pointwise convolutions
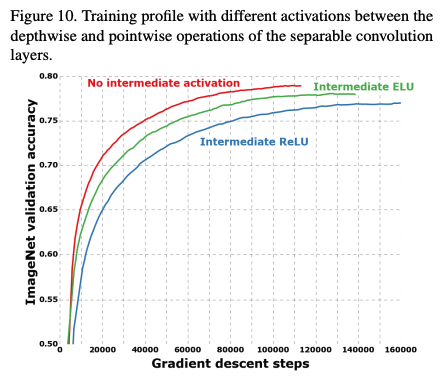
또 재밌는 것은, non-linearity를 위한 activation function을 적용하지 않는 것이 더 좋은 성능을 보여줬다는 것이다. 저자가 생각하기로는, depthwise separable conv는 1 channel이라는 얕은 레이어로 진행하기 때문에, non-linearity를 적용하면 정보의 손실이 있어서 성능이 좋지 않다고 한다.
후기
Inception V2, V3 등의 논문은 따로 읽지 않고 정리한 것만 보고, 바로 Xception 논문을 읽어봤는데, 그래서인가 이해하기 좀 어려웠던 부분이 있었다. Inception module의 철학을 좀 더 확장해서 모든 채널에 대해 conv를 적용하는 점이 인상깊었고, residual connection의 위대함과 얕은 채널에서의 non-linearity activation function의 성능 하락을 알 수 있었던 좋은 논문이었다.
