

-
이미지를 분류(classification) 한다 = dog, cat, truck 등등의 이미지(lable)에서 원하는 이미지를 찾는 것
-
이미지를 분류해야 detection, segmentation 등의 작업을 수월히 할 수 있다.

- 이미지는 숫자(0~255)로 이루어진 3D array
- 300 : Height
100 : Width
3 : Color channel - Image를 분류 하는 데 Sementic gap 이 있다 = 사람이 보는 것과 기계가 보는 것의 차이가 존재한다.
- 사람은 고양이라고 생각하는데 형태, 명암, 자세, 배경과의 구분에 따라 기계가 이미지 구분에 어려움을 겪는다
Sementic gap : 보는 관점(각도)에 따른 변화
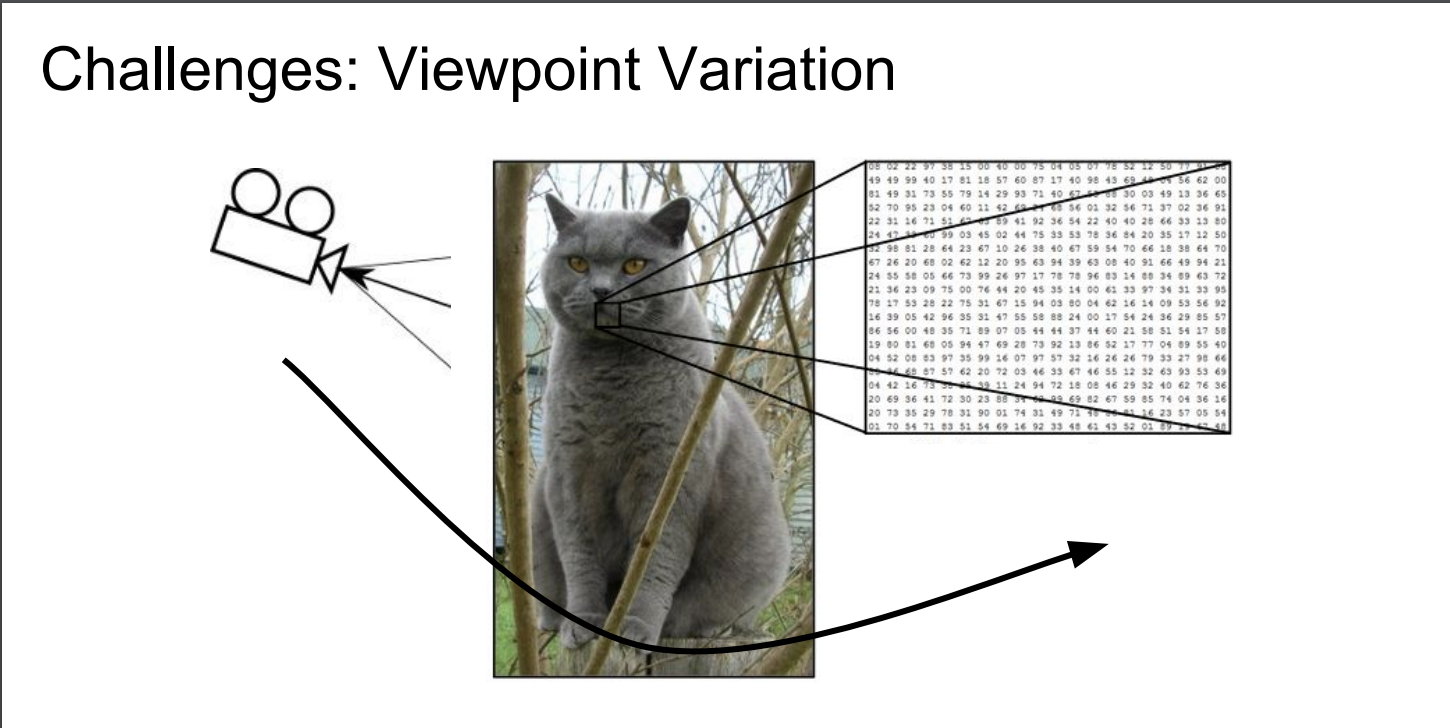
Sementic gap : 명암에 따른 차이

Sementic gap : 형태의 변형에 따른 차이

3. 기본적 이미지 분류 vs 효율적 이미지 분류접근 방법 (데이터 기반 접근)
✅ 이미지 분류 기본 함수

입력 : 구분할 이미지
출력 : 객체의 label (구분된 객체 이름)
한계 : 이미지를 클래스로 분류할 수 있는 확실한 알고리즘은 없음
✅ 개선된 데이터 기반 접근 방법

- 분류할 이미지와 label 데이터셋을 수집한다.
- 기계를 이용한 학습을 통해 분류할 분류기(classifier) 모델을 만든다.
- test 이미지를 통해 classifier를 평가
4. Nearest Neighbor Classifier
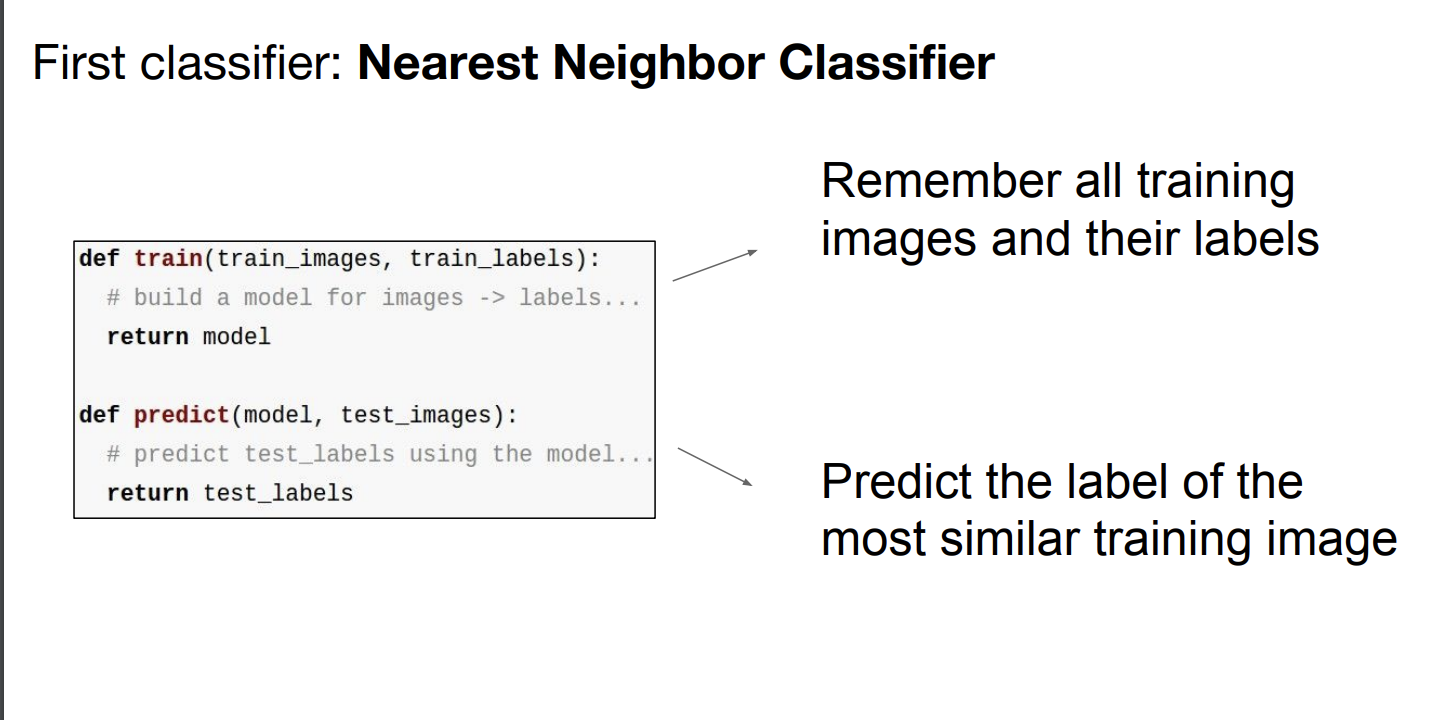
- 메모리에 모든 image와 lable를 저장
- test image를 모든 train image와 비교 후 가장 비슷한 train image를 test image라고 판단

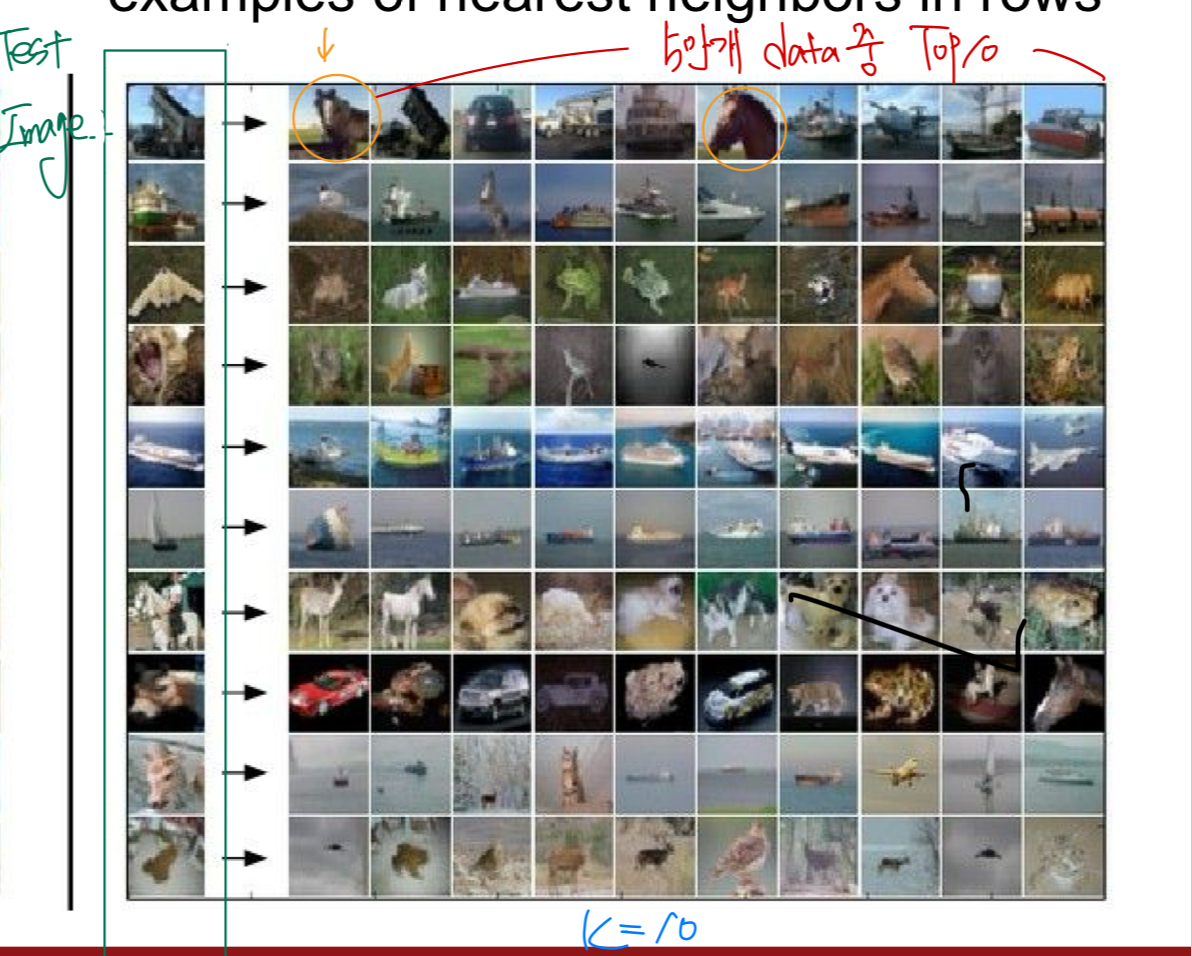
- 50,000개의 train data를 Nearest Neighbor 를 통해 구현하면 다음과 같은 test image에서 정확도에 따라 Top10을 보여준다
- 자세의 유사함에 따라 부정확한 image를 분류한다
🔔 NN classifier는 분류단계에서 어떤 기준으로 데이터를 비교할까? ➡️ 'L1 distance'
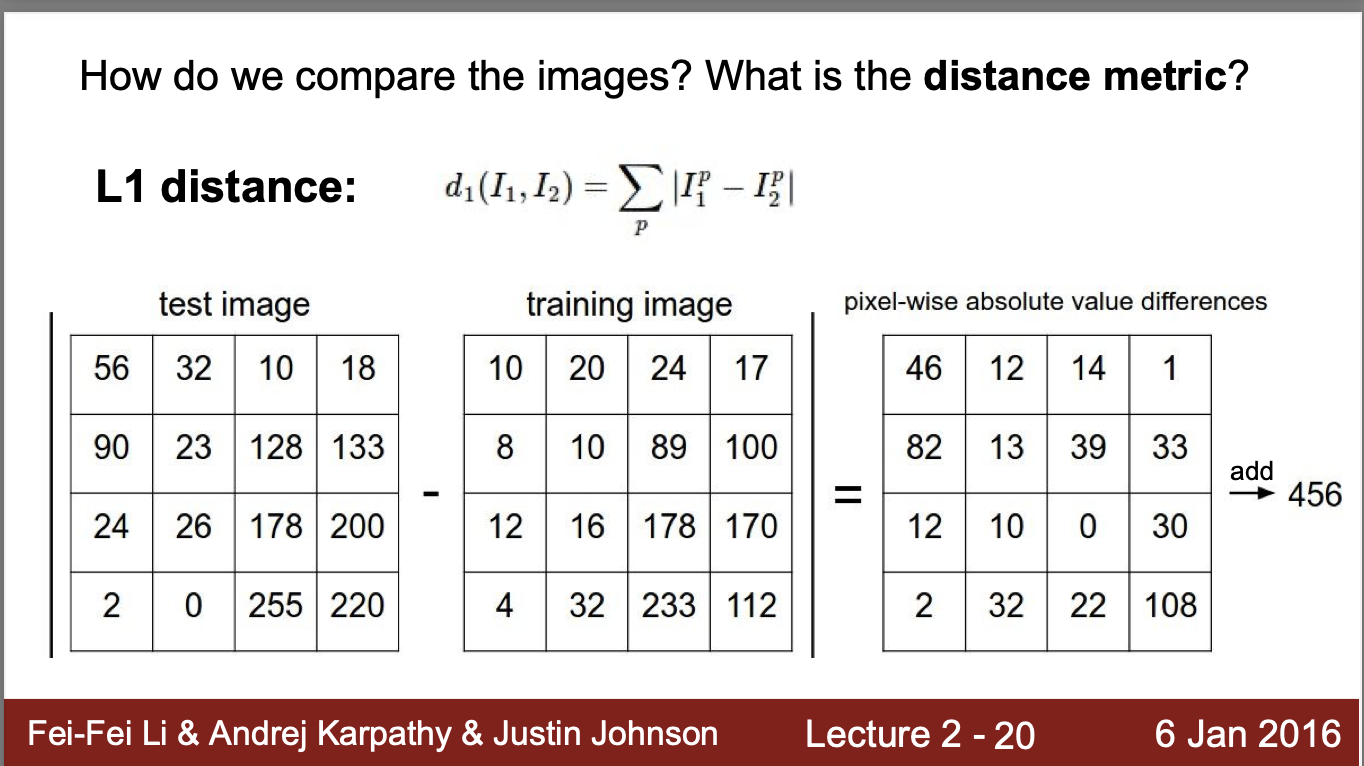
- L1 distance는 image1(test image)과 image2(train image) 사이의 거리를 절대값으로 나타낸 값
- L1 distance = 각 행렬의 차를 구한 후 행렬 원소의 총합
- L1 distance 가 작을수록 유사한 사진
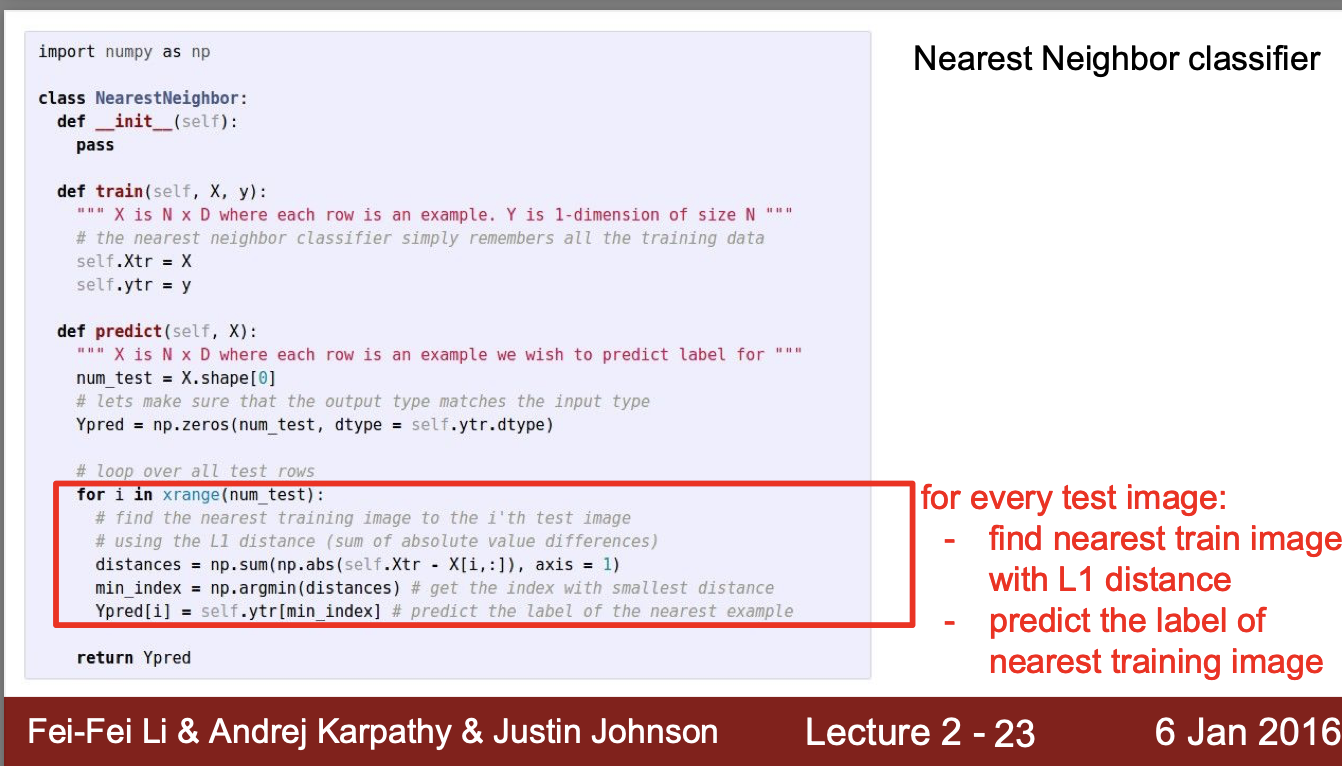
5. NN classifier의 알고리즘

- 모든 train data(X)와 label(y)를 assign의 형태로 메모리에 저장한다
-
50,000개의 train image를 각각 test image(X)와 각각 계산하여 나온 L1 distance가 가장 작은 image를 y pre이라 하고 결과값 도출
-
train data의 size가 커질수록 처리속도는 linear하게 느려짐
6. k-Nearest Neighbor
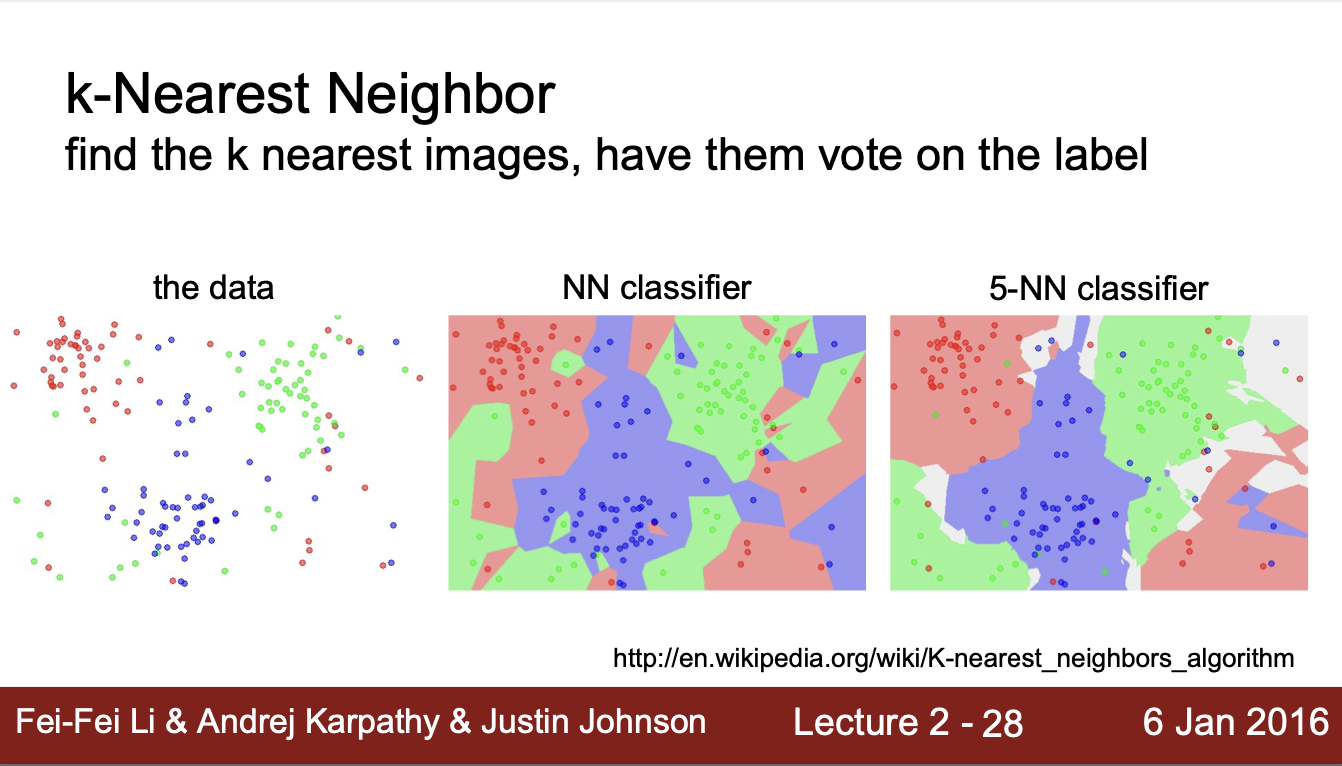
- k개의 가까운 image를 찾고 다수결로 test image가 어떤 train image와 유사한지 분류
NN을 test image말고 train image 상에서 적용한다면?
➡️ 100% 정확도 보임 , 항상 d = 0인 데이터를 찾을 수 있으므로 100% 성능 가짐
KNN을 test image말고 train image 상에서 적용한다면?
➡️ 다수결에 따라 순위가 바뀔 수 있으므로 상황에 따라 달라질 수 있음
💡 주어진 환경에서 각각의 parameter를 실험하여 최적의 정확도를 보이는 parameter(distance, K)를 선정해야됨
7. Train, Test, Validation

- 기본적으로 train data는 성능평가를 위해 hypermarameter를 지속적으로 tuning하면 부정확한 모델이 될 수 있음
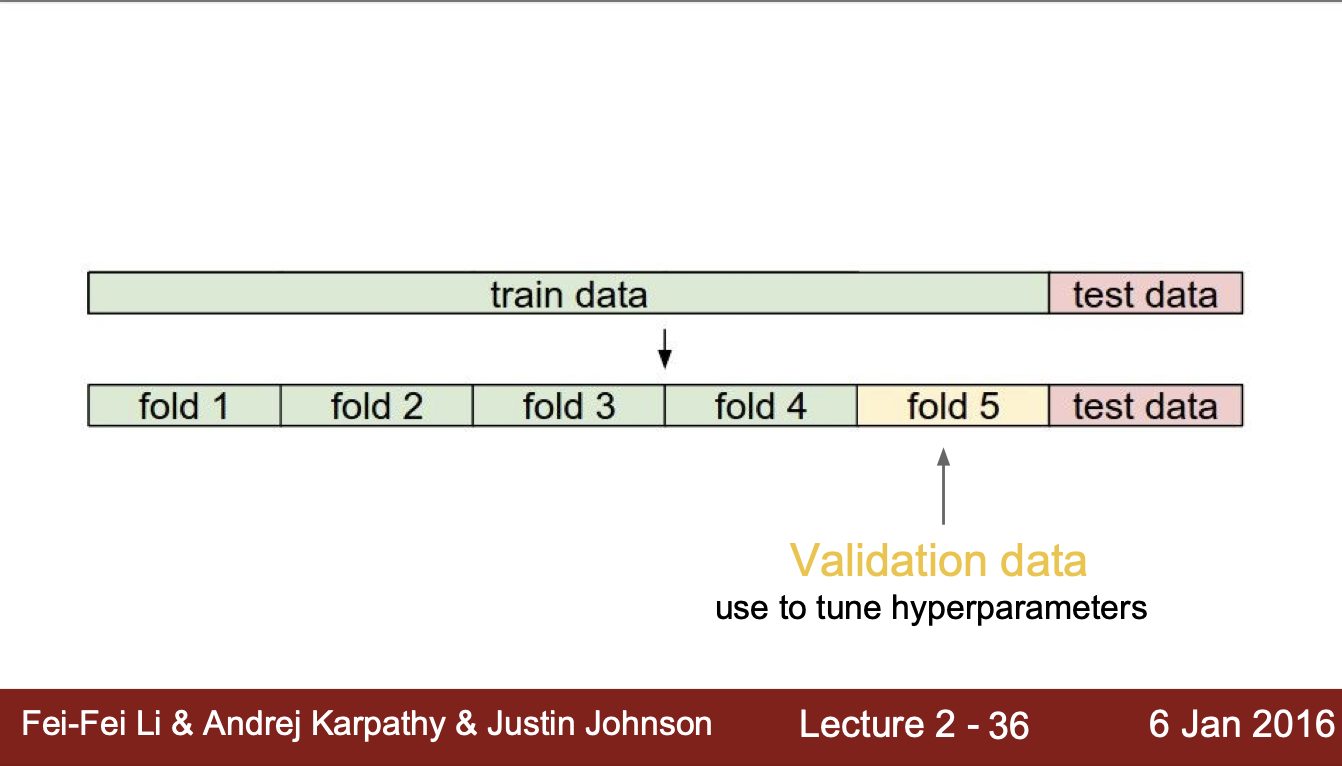
➡️ Validation data에 hyperparameter tuning
- train data 개수가 너무 적어 validation data로 분류하기 힘들다면 Cross validation 방법도 있음
train / train / train / train / val
train / train / train / val / train
train / train / val / train / train
...
val / train / train / train / train
(5번 수행)
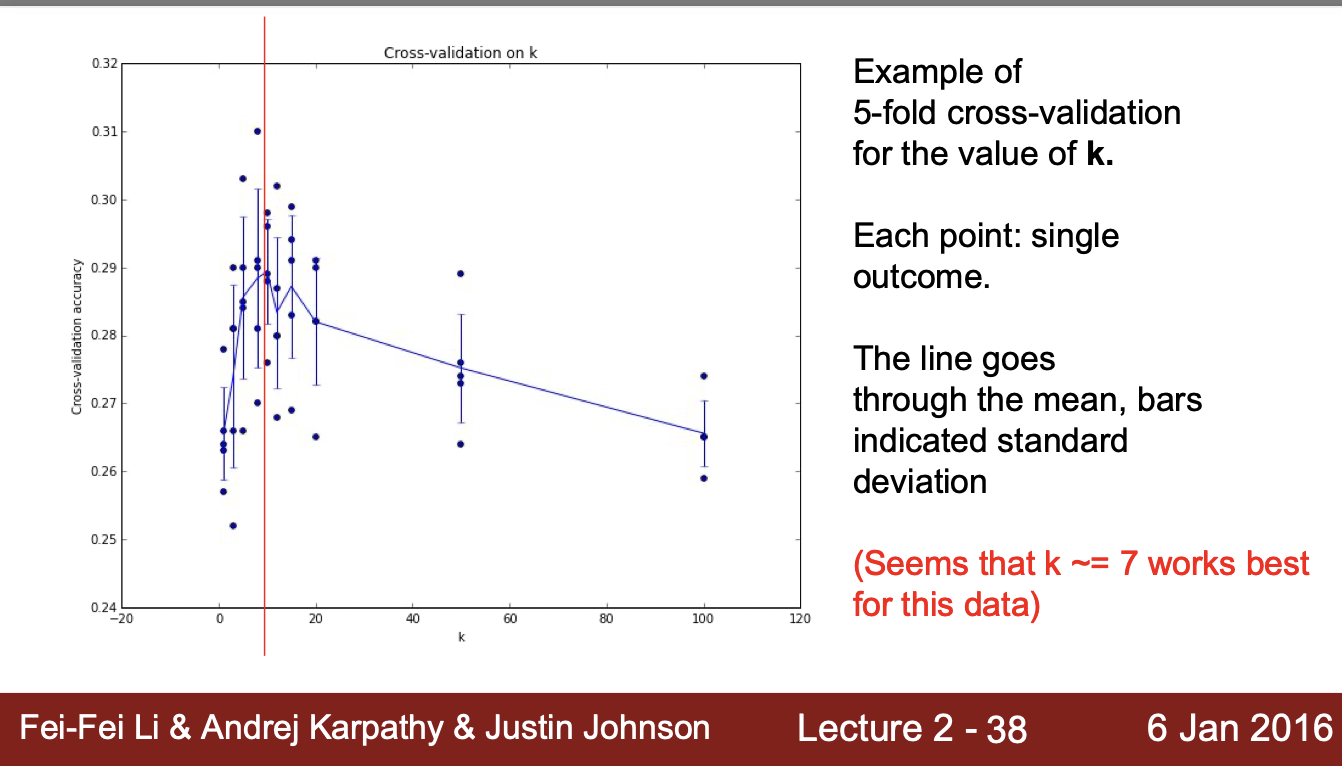
최적 Hyperparameter의 선정
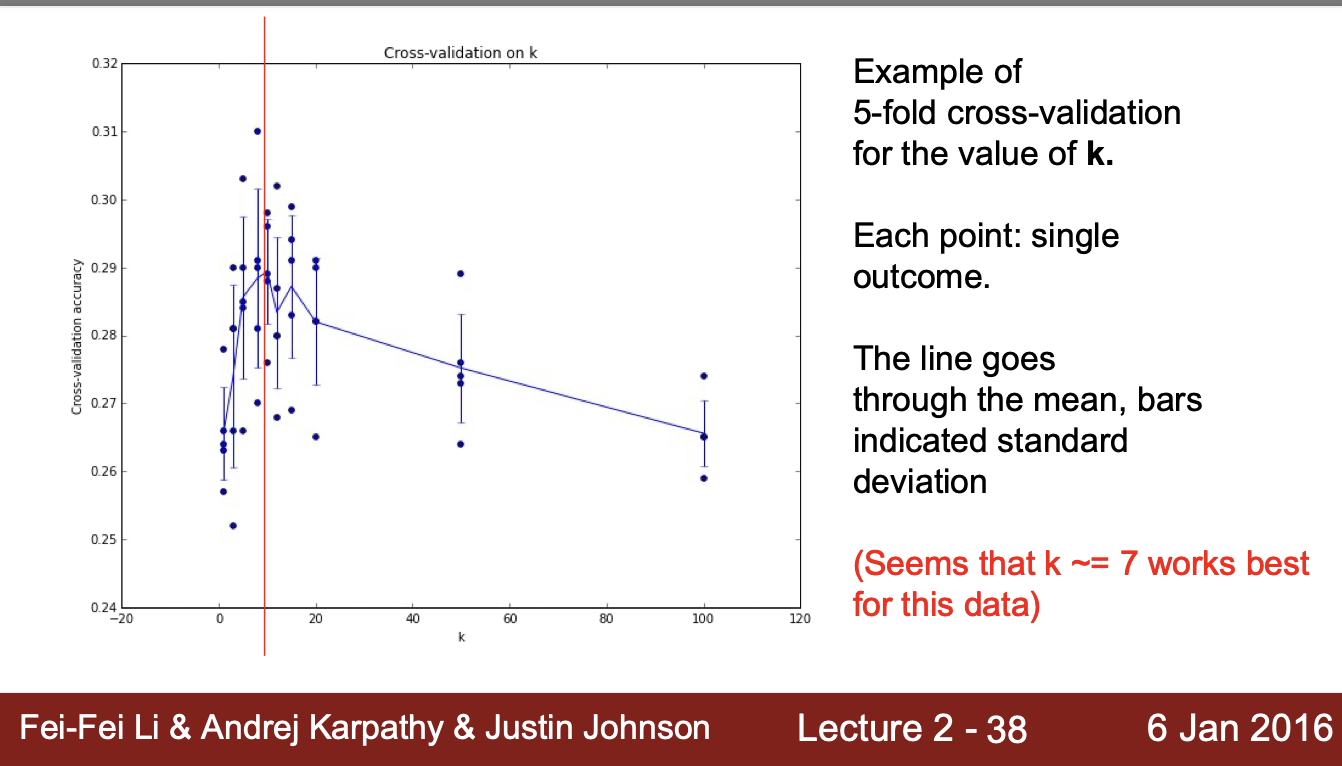
- K = 7에서 가장 높은 정확도를 보이는 것을 확인
8. KNN 한계
- KNN은 현실에선 사용하지 X
- test time에서 안좋은 성능 보임
- distance라는 개념은 현실에선 모호
