CS-study
1.1. 컴퓨터 구조 & 운영체제 기초
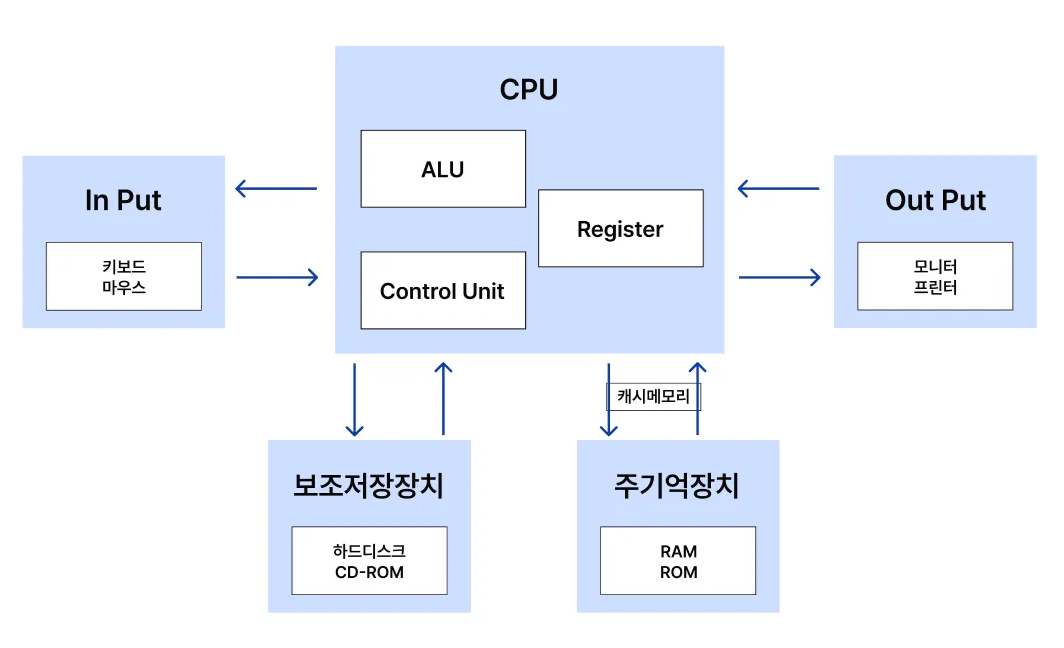
컴퓨터 과학의 기본 원리를 이해하는 것은 단순히 지식을 쌓는 것을 넘어, 문제를 해결하는 사고력을 키워줍니다. 마치 건축가가 건물의 구조를 알아야 튼튼한 집을 짓는 것처럼, 개발자도 컴퓨터의 기본 동작 원리를 알아야 더 효율적이고 안정적인 코드를 작성할 수 있습니다.
2.2. 프로세스 관리

저번 정리에서 프로세스와 스레드의 차이를 간단하게 정리했습니다.이번에는 각 개념이 왜 중요한지, 그리고 현대 운영체제에서 어떻게 활용되는 지에 대해 설명해보려 합니다.프로세스는 단순히 ‘실행 중인 프로그램’을 넘어, 운영체제가 관리하는 독립적인 작업의 단위입니다.각 프
3.3. 메모리 관리
메모리 관리를 알아보기 전 메모리 구조에 대해 아주 간단하게만 정리해보겠습니다.물리 주소: 실제 메모리(RAM) 상의 위치.논리 주소(가상 주소): CPU와 프로그램이 인식하는 주소. OS가 MMU를 통해 물리 주소로 변환.이를 통해 여러 프로세스가 동시에 실행 가능.
4.4. 동기화와 교착상태
컴퓨터에 여러 프로세스(또는 스레드)가 동시에 실행될 때, 이들이 공유된 자원(Shared Resource), 예를 들어 같은 메모리 변수나 파일에 접근하려고 하면 문제가 발생할 수 있습니다. 동기화(Synchronization)는 이러한 문제들을 해결하고 작업 순서를
5.5. 네트워크 기초
네트워크 통신 과정을 이해하기 쉽게 계층별로 나눈 모델이 바로 OSI 7계층과 TCP/IP 4계층입니다. OSI 모델은 통신의 전체 과정을 7단계로 정교하게 나누어 설명하는 개념 모델이며, TCP/IP 모델은 현재 인터넷에서 실제로 사용되는 실용적인 모델입니다.국제표준
6.6. 네트워크 심화
HTTP(HyperText Transfer Protocol)와 HTTPS(HyperText Transfer Protocol Secure)는 모두 웹에서 데이터를 주고받기 위한 프로토콜(규약)입니다. 가장 큰 차이점은 보안입니다.데이터를 암호화하지 않고 '평문(Plain
7.7. 데이터베이스 기초
RDBMS (Relational Database Management System), 즉 관계형 데이터베이스 관리 시스템은 데이터를 테이블(Table)이라는 정해진 형식의 2차원 표에 저장하고 관리하는 시스템입니다.가장 대표적인 예로 MySQL, PostgreSQL, O
8.8. 데이터베이스 심화
데이터베이스를 설계할 때 가장 기본이 되는 개념입니다. 데이터를 어떻게 구성하고 저장할지 결정하는 과정입니다.정의: 데이터의 중복을 최소화하고 데이터 무결성을 보장하기 위해, 관계형 데이터베이스의 테이블을 구조화하고 분해하는 과정입니다. 쉽게 말해, 중복되는 데이터를
9.9. 자료구조 & 알고리즘 필수
데이터를 순차적으로 저장하는 가장 기본적인 두 가지 선형 자료구조입니다. 하지만 메모리상에서의 동작 방식은 완전히 다릅니다.연속된 메모리 공간에 나란히 저장된 데이터의 집합배열은 같은 타입의 데이터가 메모리상에 연속적으로 저장되는 구조입니다.가장 큰 특징은 인덱스(In
10.10. 보안 & 시스템 설계 기초
해시(Hash)입력(메시지)을 고정 길이의 출력(해시값)으로 변환. 같은 입력은 항상 같은 출력, 아주 작은 입력 변경도 출력 크게 변화.단방향 함수: 원래 메시지로 복원할 수 없음(복호화 불가).용도: 비밀번호 저장(솔트와 함께), 무결성 검사(파일 무결성, 서명 전